Download presentation
Presentation is loading. Please wait.

1
Domain,tertiary, and quarternary structure of proteins

2
Levels of protein structure organization

3
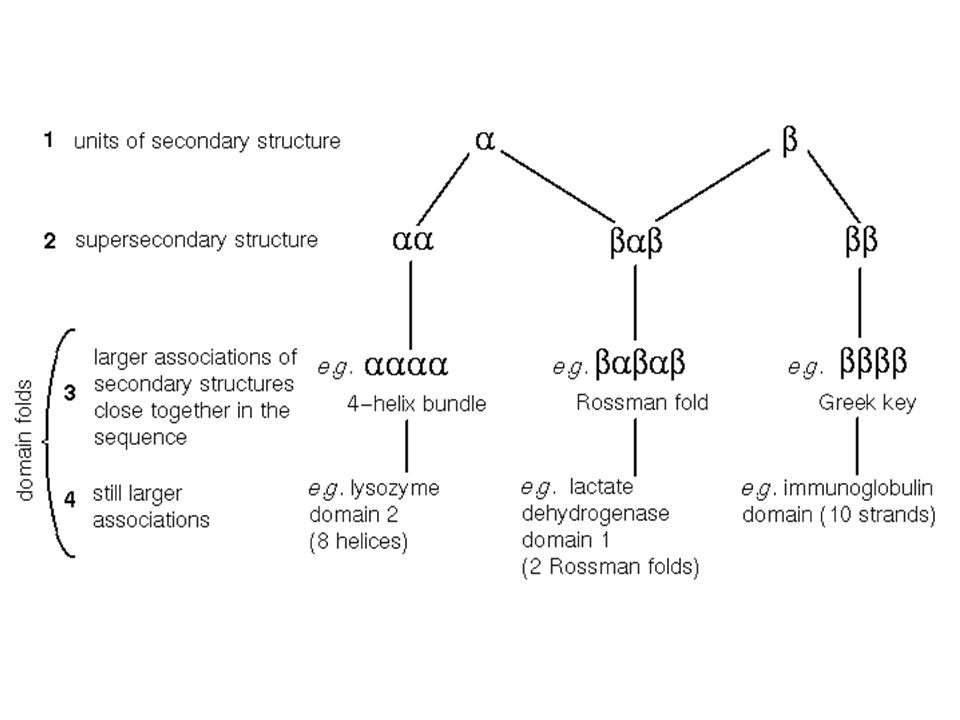
Between secondary and tertiary structure
Supersecondary structure: arrangement of elements of same or different secondary structure into motifs; a motif is usually not stable by itself. Domains: A domain is an independent unit, usually stable by itself; it can comprise the whole protein or a part of the protein.

7
Example of a b-hairpin: tryptophan zipper (1LE0)
")
8
Example of a b-hairpin in bovine pancreatic trypsin inhibitor– BPTI.
Example of a protein with two b-hairpins: erabutoxin from whale.

9
Example of a b-meander: a-spectrin SH3 domain (1BK2)
")
10
Helix Hairpin

11
Alpha alpha corner (L7.24)
")
12
Helix E helix F Troponin C with four EF motifs that bind calcium ions. Because of high content of acidic amino-acid residues with side chains pointing inside the loop, the EF-hand motif constitutes a calcium-binding scaffold in troponin, calmodulin, etc.

13
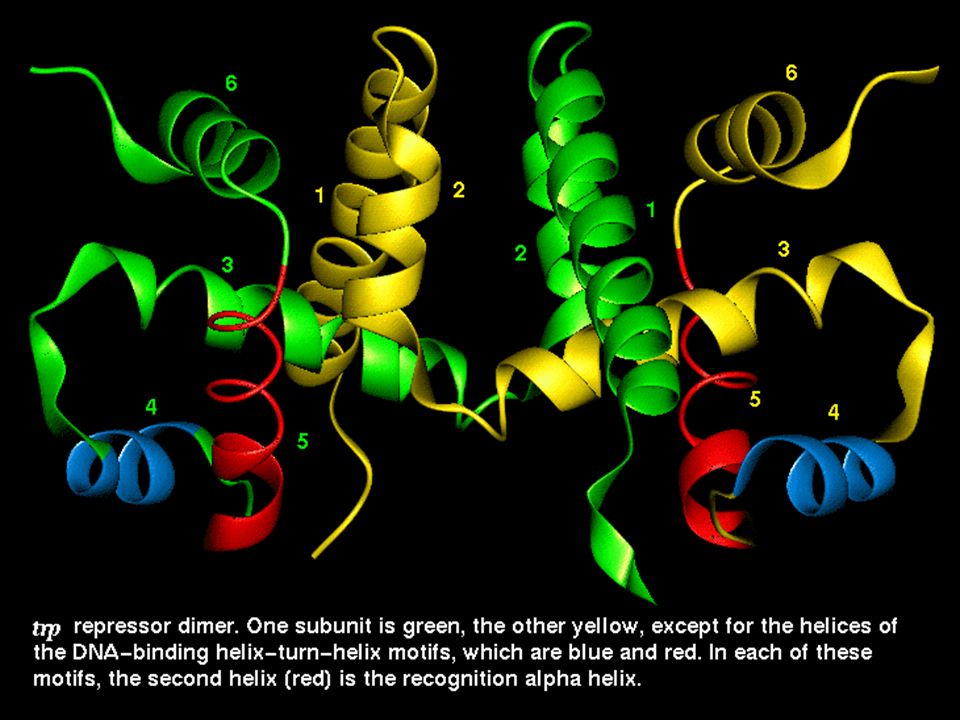
The Helix-Turn-Helix motif
This motif is characteristic of proteins binding to the major DNA grove. The proteins containing this motif recongize palindromic DNA sequences. The second helix is responsible for nucleotide sequence recognition.

14
The Helix-Turn-Helix motif

15
The a-helix-b-hairpin motif (zinc finger)
")
16
b-a-b Motif (very important and very frequent)
Hydrophobic core between a-helix and b-sheet

17
The Greek Key Motif

18
The Greek-key motif as seen in proteins

20
Domains: classification criteria
Functionality (performing a biological function or role in formation and stabilization of globular structure) Solubility: Globular proteins and protien domains (water solubke) Membrane proteins and domains (lipid soluble) Fibrillar protiens (insoluble) Content of secondary structure aa (parallel and antiparallel) bb a/b a+b high disulfide-bridge or metal content.
 Solubility: Globular proteins and protien domains (water solubke) Membrane proteins and domains (lipid soluble) Fibrillar protiens (insoluble) Content of secondary structure. aa (parallel and antiparallel) bb. a/b. a+b. high disulfide-bridge or metal content.")
21
Protein domains Sposób wyróżnienia domeny w cząsteczce białka jest często intuicyjny, ale możliwe jest przypisanie domenom pewnych, wyróżniających je cech: - domena jest potencjalnie niezależną jednostką fałdowania, - domena jest lokalną, zwartą, globularną, półniezaeżną częścią białka, związaną z nim jednak kowalencyjnie, - sekwencją aminokwasów, charakterystyczną dla danej domeny, można spotkać w innych, podobnych domenach tego samego białka (lub w innych białkach), - domenom towarzyszą często specyficzne funkcje (np. wiązanie nukleotydów, sacharydów) - przestrzeń między domenami wyznacza często centrum aktywne białka, - domena reprezentuje zwarty, genetyczny segment (np. domeny w immunoglobulinach, dehydrogenazach, globinach) Pojedyńcza cząsteczka białka może posiadać kilka lub więcej domen ale większość białek należy do grupy białek jednodomenowych.
, - domenom towarzyszą często specyficzne funkcje (np. wiązanie nukleotydów, sacharydów) - przestrzeń między domenami wyznacza często centrum aktywne białka, - domena reprezentuje zwarty, genetyczny segment (np. domeny w immunoglobulinach, dehydrogenazach, globinach) Pojedyńcza cząsteczka białka może posiadać kilka lub więcej domen ale większość białek należy do grupy białek jednodomenowych.")
24
Domains: example For a recent review on domain insertion. Domain swapping between two protomers is not uncommon (for example in the case of diphtheria toxin). Domains of recently evolved proteins are frequently encoded by exons, reflecting gene fusion of simpler modules. For example, in the case of hepatocyte growth factors and plasminogens, a number of kringle domains are present. Domains form an important level in the hierarchical organisation of the three-dimensional structure of globular proteins, although not all proteins can be described as multidomain structures.
. Domains of recently evolved proteins are frequently encoded by exons, reflecting gene fusion of simpler modules. For example, in the case of hepatocyte growth factors and plasminogens, a number of kringle domains are present. Domains form an important level in the hierarchical organisation of the three-dimensional structure of globular proteins, although not all proteins can be described as multidomain structures.")
25
Example if division of a protein into domains: human Hsp70 chaperone

26
Human cystatin C: domain swapping

27
Domain identification algorithms
Schultz’s method: neighborhood correlation criterion

28
The Go algorithm: interdomain distances are larger than intradomain distances

29
The Rose algorithm: based on the deviation of the long axes of the fragments from protein mean plane; works for continuous domains

30
The Crippen algorithm: based on dissection of residues according to interresidue distances into clusters Ca-Ca distances between secondary structures are represented in the form of average values termed 'proximity indices' and the secondary structural organisation is indicated in the form of dendrograms. An example is shown for the case of calmodulin.

31
Specific nodes in these dendrograms are identified as tertiary structural clusters of the protein; these include supersecondary structures and domains. A ratio of the average proximity indices (ignoring inter-clusteral distances) to the average of all proximity indices, weighted for the aggregation of small sub-clusters and termed the disjoint factor, is employed as a discriminatory parameter to identify automatically clusters representing individual domains. An example of domains identified in glutathione reducatase is shown below :
 to the average of all proximity indices, weighted for the aggregation of small sub-clusters and termed the disjoint factor, is employed as a discriminatory parameter to identify automatically clusters representing individual domains. An example of domains identified in glutathione reducatase is shown below : .")
32
The domains identified by this clustering method may not correspond to the functional domains proposed. The "disjoint factor" gives a measure of the extent of interaction between domains and has been used to classify domains into one of the three types, disjoint, interacting and conjoint. Domains are classified as those with sparse inter-domain interfaces (disjoint), intermediate interactions (interacting) and elaborate interfaces (conjoint) based on the magnitude of the disjoint factor. An example of the three types is shown below :
, intermediate interactions (interacting) and elaborate interfaces (conjoint) based on the magnitude of the disjoint factor. An example of the three types is shown below :")
35
Classification of three-dimensional structures of protein
Richardson’s classification a – a-helices are only or dominant secondary-structure elements (e.g., ferritin, myoglobin) b – b-sheets are only or dominant elements (e.g., lipocain) a/b – contain strongly interacting helices and sheets a+b – contain weakly interacting or separated helices and sheets
 b – b-sheets are only or dominant elements (e.g., lipocain) a/b – contain strongly interacting helices and sheets. a+b – contain weakly interacting or separated helices and sheets.")
36
SCOP classification Structural Classification Of Proteins
This is a hierarchical classification scheme with the following 4 levels: Families – one family is comprised by proteins related structurally, evolutionally, and functionally. Superfamoilies – A superfamily is comprised by families of substantially related by structure and function. Folds – Superfamilies with common topology of the main portion of the chain. Classes - Groups of folds characterized by secondary structure: a (mainly a-helices), b (mainly b-sheets), a/b (a-helices and b-sheets strongly interacting), a+b (a-helices and b-weakly interacting or not interacting), multidomain proteins (non-homologous proteins with vert diverse folds).
, b (mainly b-sheets), a/b (a-helices and b-sheets strongly interacting), a+b (a-helices and b-weakly interacting or not interacting), multidomain proteins (non-homologous proteins with vert diverse folds).")
37
[ http://scop.mrc-lmb.cam.ac.uk/scop/ ]
![[ ]](http://slideplayer.com/slide/425434/1/images/37/%5B+++%5D.jpg "[ ]")
41
Scop Classification Statistics
SCOP: Structural Classification of Proteins release PDB Entries (23 Feb 2009) Domains. 1 Literature Reference (excluding nucleic acids and theoretical models) Class Number of folds Number of superfamilies Number of families All alpha proteins 284 507 871 All beta proteins 174 354 742 Alpha and beta proteins (a/b) 147 244 803 Alpha and beta proteins (a+b) 376 552 1055 Multi-domain proteins 66 89 Membrane and cell surface proteins 58 110 123 Small proteins 90 129 219 Total 1195 1962 3902
 Domains. 1 Literature Reference (excluding nucleic acids and theoretical models) Class. Number of folds. Number of superfamilies. Number of families. All alpha proteins All beta proteins Alpha and beta proteins (a/b) Alpha and beta proteins (a+b) Multi-domain proteins Membrane and cell surface proteins Small proteins Total")
42
CATH classification (Class (C), Architecture(A), Topology(T), Homologous superfamily (H))
Four hierarchy levels: Class (Level C): according to the content of secondary structure type a, b, a&b (a/b and a+b), weakly or undefined secondary structure. Architecture. (Level A) – Orientation and connection topology between secondary structure elements. Topology. (Level T) – based on fold type. Homoloous superfamilies. (Level H) – high homology indicating a common anscestor: >30% sequence identity OR > 20% sequence identiy and 60% structural homology OR > 60% structural homology and similar domains have similar function.
: according to the content of secondary structure type a, b, a&b (a/b and a+b), weakly or undefined secondary structure. Architecture. (Level A) – Orientation and connection topology between secondary structure elements. Topology. (Level T) – based on fold type. Homoloous superfamilies. (Level H) – high homology indicating a common anscestor: >30% sequence identity OR. > 20% sequence identiy and 60% structural homology OR. > 60% structural homology and similar domains have similar function.")
43
Homologous superfamily (H)
Class(C) derived from secondary structure content is assigned automatically Architecture(A) describes the gross orientation of secondary structures, independent of connectivity. Topology(T) clusters structures according to their topological connections and numbers of secondary structures Homologous superfamily (H) [ ]
 derived from secondary structure content is assigned automatically. Architecture(A) describes the gross orientation of secondary structures, independent of connectivity. Topology(T) clusters structures according to their topological connections and numbers of secondary structures. Homologous superfamily (H) [ ]")
45
A „periodic table” of protein structures
W. Taylor, Nature, 416, 6881, (2002)
")
47
„Menagerie” of known protein folds

48
ROP: two packed helices
a-helical structures ROP: two packed helices 1rop - RASMOL

49
Antiparallel four-a-helix bundle
15o twist of helix axes

50
Example: ferritin 1fha - RASMOL

51
2mhr - RASMOL 1fha - RASMOL

53
The heme binding sites are located between the a-helices

55
G-protein coupled receptors: antiparallel 7-helix bundles
Bacteriorhodopsin: theoretical model Bakteriorodopsyna – model teoretyczny 1bac, 1brd - RASMOL Each helix is about 20 residue long

56
Photosynthetic reaction center
Bakteriorodopsyna – model teoretyczny 1bac, 1brd - RASMOL 1prc - RASMOL

57
a-helical structures with the Greek key topology
Tego typu domeny spotykane są przede wszystkim w białkach globinowych. Zbudowane są z dwóch warstw a-helis. Kierunki helis obu wartsw są często prawie prostopadłe (upakowanie helisy metodą ortogonalną) Domena przypomina nieco cylinder utworzony z helis skręconych w stosunku do jego osi o kąt od 0 do 45o Najczęściej spotykanym typem połączeń między helisami jest sekwencja +3, -1, -1, -1, spotykana w motywie klucza greckiego 1mba - RASMOL
 Domena przypomina nieco cylinder utworzony z helis skręconych w stosunku do jego osi o kąt od 0 do 45o. Najczęściej spotykanym typem połączeń między helisami jest sekwencja +3, -1, -1, -1, spotykana w motywie klucza greckiego. 1mba - RASMOL.")
58
DNA-binding proteins 1hdd - RASMOL 1lmb - RASMOL

61
Large a-helical proteins
1SLYa - RASMOL

62
a/b horseshoe

63
The jellyroll topology

64
Example of a protein with jellyroll topology: Carbohydrate-Binding Module Family 28 from Clostridium josui Cel5A (3ACI)
")
65
Example of a b-barrel (red fluorescent protein; 3NED)
")
67
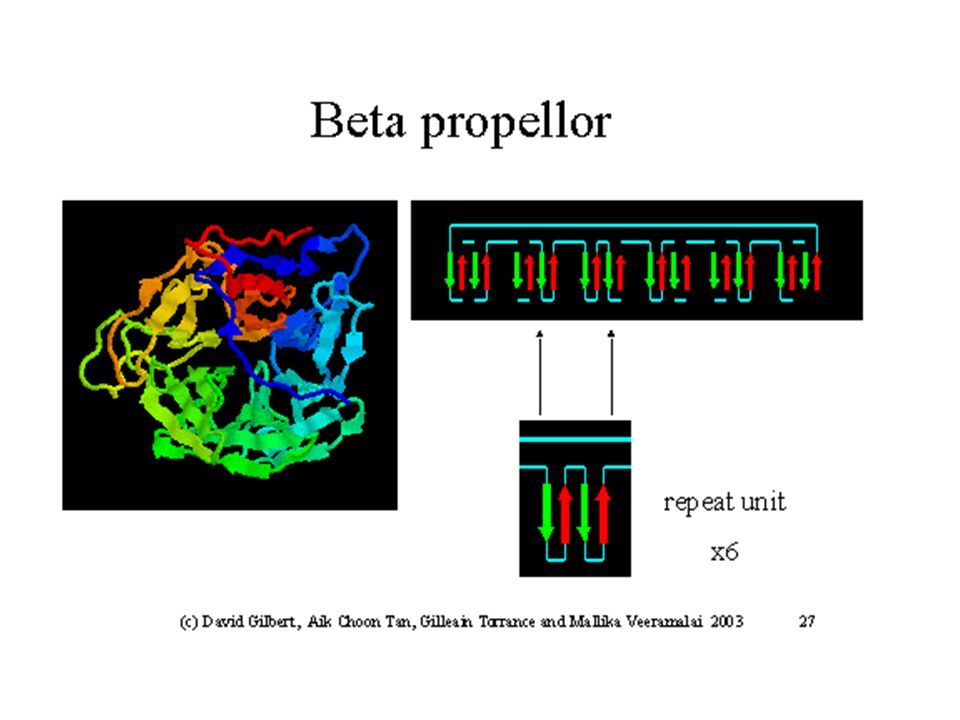
Example of a b-propellor motif : Thermostable PQQ-dependent Soluble Aldose Sugar Dehydrogenase (3DAS)
")
68
The b-helix

69
Quaternary structure is the result of subunit associations
Fig. 5-15

70
1RLZ (leucine zipper)
")
71
1G6U: artificial homodimer (three-helix bundle)
")
72
Homo-multimers It is far more common to find copies of the same tertiary domain associating non-covalently. Such complexes are usually, though not always symmetrical. Because proteins are inherently asymmetrical objects, the multimers almost always exhibit rotational symmetry about one or more axes. The majority of the enzymes of the metabolic pathways seem to aggregate in this way, forming dimers, trimers, tetramers, pentamers, hexamers, octamers, decamers, dodecamers, (or even tetradecamers in the case of the chaperonin GroEL).
.")
75
Hetero-multimers In this case we see different tertiary domains aggregating together to form a unit. The photoreaction centre is a good example.
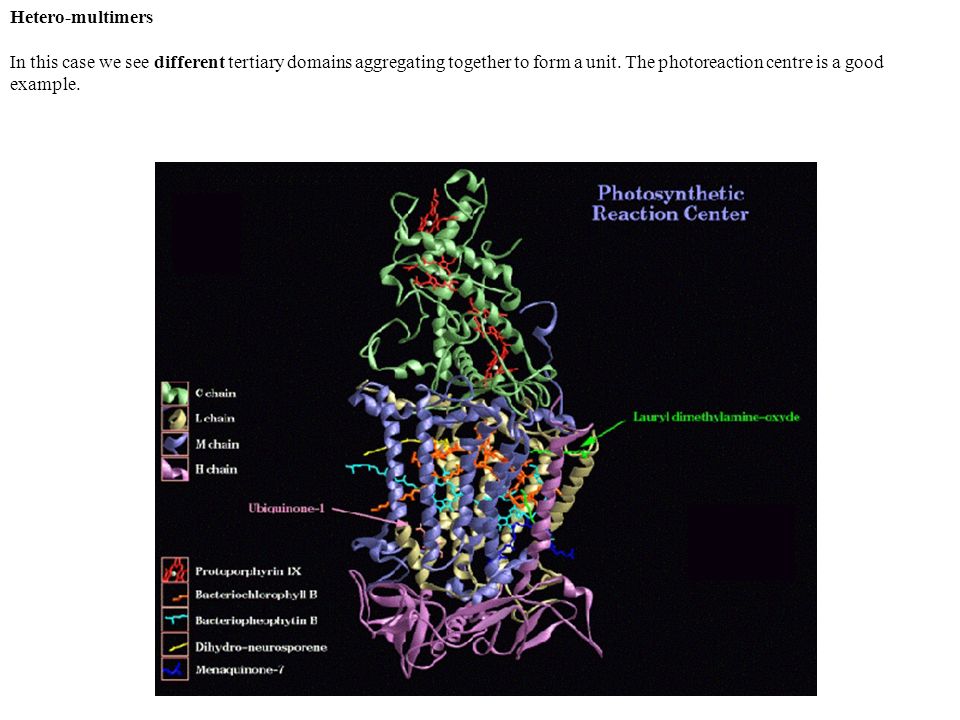
76
Sometimes, we find that several domains are found in a single enzyme complex, either in a single polypeptide chain, or as an association of separate chains. Often the domains have related functions, for instance, where one domain will be responsible for binding, another for regulation, and a third for enzymatic activity. Cellobiohydrolase provides anexample of such a protein. It is not uncommon to find more than once the same chain in a protein complex. A good example is the F-1 ATPase.

77
Two (further) steps in the biosynthetic pathway of tryptophan (in S
Two (further) steps in the biosynthetic pathway of tryptophan (in S.typhimirium) are catalysed by tryptophan synthase which consists of two separate chains, designated a and b, each of which is effectively a distinct enzyme.
 steps in the biosynthetic pathway of tryptophan (in S.typhimirium) are catalysed by tryptophan synthase which consists of two separate chains, designated a and b, each of which is effectively a distinct enzyme.")
78
The biologically active unit is a hetero-tetramer comprised of 2 a and 2 b units.
We sometimes find slightly different versions of the same protein associating. Thus, haemoglobin has both an A-chain and a B-chain, which come together to form a hetero-dimer. Two copies of this then associate to form the normal haemoglobin tetramer. Which is equivalent to an A-dimer associating with a B-dimer. Also, it can happen that two different chains associate to form a bigger secondary structure. It is the case of the pea lectin, where a very large b-sheet is nade out of strands coming from different protein chains:

79
Amyloid fibril formed from the Abeta peptide

Similar presentations






























 Dr. Ahmed Mujamammi Dr. Sumbul Fatma>")

