Download presentation
Presentation is loading. Please wait.

1
Learning and teaching in games: Statistical models of human play in experiments Colin F. Camerer, Social Sciences Caltech (camerer@hss.caltech.edu) Teck Ho, Berkeley (Haas Business School) Kuan Chong, National Univ Singapore How can bounded rationality be modelled in games? Theory desiderata: Precise, general, useful (game theory), and cognitively plausible, empirically disciplined (cog sci) Three components: –Cognitive hierarchy thinking model (one parameter, creates initial conditions) –Learning model (EWA, fEWA) - Sophisticated teaching’ model (repeated games) - Sophisticated teaching’ model (repeated games) Shameless plug: Camerer, Behavioral Game Theory (Princeton, Feb ’03) or see website hss.caltech.edu/~camerer
 Kuan Chong, National Univ Singapore How can bounded rationality be modelled in games. Theory desiderata: Precise, general, useful (game theory), and cognitively plausible, empirically disciplined (cog sci) Three components: –Cognitive hierarchy thinking model (one parameter, creates initial conditions) –Learning model (EWA, fEWA) - Sophisticated teaching’ model (repeated games) - Sophisticated teaching’ model (repeated games) Shameless plug: Camerer, Behavioral Game Theory (Princeton, Feb ’03) or see website hss.caltech.edu/~camerer.")
2
Behavioral models use some game theory principles, and weaken other principles Principle equilibrium Thinking LearningTeaching concept of a game strategic thinking best response mutual consistency learning strategic foresight

3
(Typical) experimental economics methods Repeated matrix stage game (Markov w/ 1 state) Repeated with “one night stand” (“stranger”) rematching protocol & feedback (to allow learning without repeated-game reputation- building) Game is described abstractly, payoffs are public knowledge (e.g., read out loud) Subjects paid $ according to choices (~$12/hr) Why this style? Basic question is whether S’s can “compute” equiilibrium *, not meant to be realistic Establish regularity across S’s, different game structures Statistical fitting: Parsimonious (1+ parameters) models, fit (in sample) & predict (out of sample) & compute economic value * Question now answered (No): Would be useful to move to low- information MAL designs
 models, fit (in sample) & predict (out of sample) & compute economic value * Question now answered (No): Would be useful to move to low- information MAL designs.")
4
Beauty contest game: Pick numbers [0,100] closest to (2/3)*(average number) wins
![Beauty contest game: Pick numbers [0,100] closest to (2/3)*(average number) wins](http://images.slideplayer.com/14/4247898/slides/slide_4.jpg "Beauty contest game: Pick numbers [0,100] closest to (2/3)*(average number) wins")
5
“Beauty contest” game (Ho, Camerer, Weigelt Amer Ec Rev 98): Pick numbers x i [0,100] Closest to (2/3)*(average number) wins $20
![Beauty contest game (Ho, Camerer, Weigelt Amer Ec Rev 98): Pick numbers x i [0,100] Closest to (2/3)*(average number) wins $20](http://images.slideplayer.com/14/4247898/slides/slide_5.jpg "Beauty contest game (Ho, Camerer, Weigelt Amer Ec Rev 98): Pick numbers x i [0,100] Closest to (2/3)*(average number) wins $20")
8
Table: Data and estimates of in pbc games (equilibrium = 0) datasteps of subjects/gamemeanstd devthinking game theorists1921.83.7 Caltech2311.13.0 newspaper2320.23.0 portfolio mgrs2416.12.8 econ PhD class2718.72.3 Caltech g=32225.71.8 high school3318.61.6 1/2 mean2719.91.5 70 yr olds3717.51.1 Germany3720.01.1 CEOs3818.81.0 game p=0.73924.71.0 Caltech g=22229.90.8 PCC g=34829.00.1 game p=0.94924.30.1 PCC g=25429.20.0 mean1.56 median1.30
 datasteps of subjects/gamemeanstd devthinking game theorists Caltech newspaper portfolio mgrs econ PhD class Caltech g= high school /2 mean yr olds Germany CEOs game p= Caltech g= PCC g= game p= PCC g= mean1.56 median1.30")
10
EWA learning Attraction A i j (t) for strategy j updated by A i j (t) =( A i j (t-1) + i [s i (t),s -i (t)]/ ( (1- )+1) (chosen j) A i j (t) =( A i j (t-1) + i [s i j,s -i (t)]/ ( (1- )+1) (unchosen j) logit response (softmax) P i j (t)=e^{A i j (t)}/[Σ k e^{A i k (t)}] key parameters: imagination (weight on foregone payoffs) decay (forgetting) or change-detection growth rate of attractions ( =0 averages; =1 cumulations; =1 “lock-in” after exploration) “In nature a hybrid [species] is usually sterile, but in science the opposite is often true”-- Francis Crick ’88 Weighted fictitious play ( =1, =0) Simple choice reinforcement ( =0)
![EWA learning Attraction A i j (t) for strategy j updated by A i j (t) =( A i j (t-1) + i [s i (t),s -i (t)]/ ( (1- )+1) (chosen j) A i j (t) =( A i j (t-1) + i [s i j,s -i (t)]/ ( (1- )+1) (unchosen j) logit response (softmax) P i j (t)=e^{A i j (t)}/[Σ k e^{A i k (t)}] key parameters: imagination (weight on foregone payoffs) decay (forgetting) or change-detection growth rate of attractions ( =0 averages; =1 cumulations; =1 lock-in after exploration) In nature a hybrid [species] is usually sterile, but in science the opposite is often true -- Francis Crick ’88 Weighted fictitious play ( =1, =0) Simple choice reinforcement ( =0)](http://images.slideplayer.com/14/4247898/slides/slide_10.jpg "EWA learning Attraction A i j (t) for strategy j updated by A i j (t) =( A i j (t-1) + i [s i (t),s -i (t)]/ ( (1- )+1) (chosen j) A i j (t) =( A i j (t-1) + i [s i j,s -i (t)]/ ( (1- )+1) (unchosen j) logit response (softmax) P i j (t)=e^{A i j (t)}/[Σ k e^{A i k (t)}] key parameters: imagination (weight on foregone payoffs) decay (forgetting) or change-detection growth rate of attractions ( =0 averages; =1 cumulations; =1 lock-in after exploration) In nature a hybrid [species] is usually sterile, but in science the opposite is often true -- Francis Crick ’88 Weighted fictitious play ( =1, =0) Simple choice reinforcement ( =0)")
11
Studies comparing EWA and other learning models

12
20 estimates of learning model parameters 20 estimates of learning model parameters

13
Functional EWA learning (“EWA Lite”) Use functions of experience to create parameter values (only free parameter ) i (t) is a change detector: i (t) is a change detector: i (t)=1-.5[ k ( s -i k (t) - =1 t s s -i k ( )/t ) 2 ] i (t)=1-.5[ k ( s -i k (t) - =1 t s s -i k ( )/t ) 2 ] Compares average of past freq’s s -i (1), s -i (2)…with s -i (t) Decay old experience (low ) if change is detected =1 when other players always repeat strategies =1 when other players always repeat strategies falls after a “surprise” falls after a “surprise” falls more if others have been highly variable falls less if others have been consistent = /( of Nash strategies) (creates low in mixed games) = /( of Nash strategies) (creates low in mixed games)Questions: (now) Do functional values pick up differences across games? (Yes.) (later) Can function changes create sensible, rapid switching in stochastic games?
![Functional EWA learning ( EWA Lite ) Use functions of experience to create parameter values (only free parameter ) i (t) is a change detector: i (t) is a change detector: i (t)=1-.5[ k ( s -i k (t) - =1 t s s -i k ( )/t ) 2 ] i (t)=1-.5[ k ( s -i k (t) - =1 t s s -i k ( )/t ) 2 ] Compares average of past freq’s s -i (1), s -i (2)…with s -i (t) Decay old experience (low ) if change is detected =1 when other players always repeat strategies =1 when other players always repeat strategies falls after a surprise falls after a surprise falls more if others have been highly variable falls less if others have been consistent = /( of Nash strategies) (creates low in mixed games) = /( of Nash strategies) (creates low in mixed games)Questions: (now) Do functional values pick up differences across games.](http://images.slideplayer.com/14/4247898/slides/slide_13.jpg "(Yes.) (later) Can function changes create sensible, rapid switching in stochastic games .")
15
Example: Price matching with loyalty rewards (Capra, Goeree, Gomez, Holt AER ‘99) Players 1, 2 pick prices [80,200] ¢ Price is P=min(P 1,,P 2 ) Low price firm earns P+R High price firm earns P-R What happens? (e.g., R=50)
![Example: Price matching with loyalty rewards (Capra, Goeree, Gomez, Holt AER ‘99) Players 1, 2 pick prices [80,200] ¢ Price is P=min(P 1,,P 2 ) Low price firm earns P+R High price firm earns P-R What happens.](http://images.slideplayer.com/14/4247898/slides/slide_15.jpg "(e.g., R=50).")
18
Teaching in repeated (partner) games Finitely-repeated trust game (Camerer & Weigelt Econometrica ‘88) borrower action repaydefault lenderloan40,60-100,150 no loan 10,10 1 borrower plays against 8 lenders A fraction (p(honest)) borrowers prefer to repay (controlled by experimenter)
 games Finitely-repeated trust game (Camerer & Weigelt Econometrica ‘88) borrower action repaydefault lenderloan40,60-100,150 no loan 10,10 1 borrower plays against 8 lenders A fraction (p(honest)) borrowers prefer to repay (controlled by experimenter)")
19
Empirical results (conditional frequencies of no loan and default)
")
20
Teaching in repeated trust games (Camerer, Ho, Chong J Ec Theory 02) Some ( =89%) borrowers know lenders learn by fEWA Actions in t “teach” lenders what to expect in t+1 (=.93) is “peripheral vision” weight E.g. entering period 4 of sequence 17 Seq.period 16 1 2 3 4 5 6 7 8 Repay Repay Repay Default..... Repay Repay Repay Default..... look “peripherally” ( weight) look “peripherally” ( weight) 17 1 2 3 look back Repay No loan Repay Teaching: Strategies have reputations Bayesian-Nash equilibrium: Borrowers have reputations (types)
 look peripherally ( weight) look back Repay No loan Repay Teaching: Strategies have reputations Bayesian-Nash equilibrium: Borrowers have reputations (types).")
21
Heart of the model: Attraction of sophisticated Borrower strategy j after sequence k before period t J t+1 is possible sequence of choices by borrower First term is expected (myopic) payoff from strategy j Second term is summation of expected payoffs in the future (undiscounted) given effect of j and optimal planned future choices (J t+1 )
 payoff from strategy j Second term is summation of expected payoffs in the future (undiscounted) given effect of j and optimal planned future choices (J t+1 )")
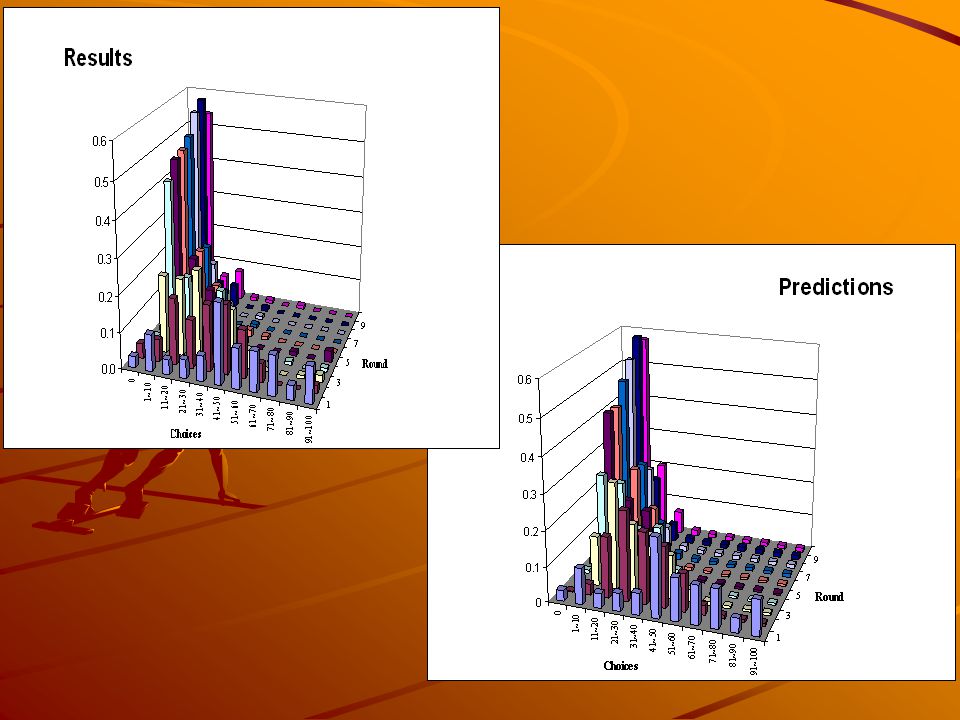
22
Empirical results (top) and teaching model (bottom)
 and teaching model (bottom)")
23
Conclusions Learning ( response sensitivity) Hybrid fits & predicts well (20+ games) One-parameter fEWA fits well, easy to estimate Well-suited to Markov games because Φ means players can “relearn” if new state is quite different? Teaching ( fraction of teaching) Retains strategic foresight in repeated games with partner matching Fits trust, entry deterrence better than softmax Bayesian-Nash (aka QRE) Next? Field applications, explore low-information Markov domains…
 Retains strategic foresight in repeated games with partner matching Fits trust, entry deterrence better than softmax Bayesian-Nash (aka QRE) Next. Field applications, explore low-information Markov domains….")
24
Parametric EWA learning (E’metrica ‘99) free parameters , , , , N(0) Functional EWA learning functions for parameters parameter ( ) Strategic teaching (JEcTheory ‘02) Reputation-building w/o “types” Two parameters ( , ) Thinking steps (parameter )
 free parameters , , , , N(0) Functional EWA learning functions for parameters parameter ( ) Strategic teaching (JEcTheory ‘02) Reputation-building w/o types Two parameters ( , ) Thinking steps (parameter )")
Similar presentations





 2001 by Harcourt, Inc. All rights reserved. Strategic Behavior Game Theory –Players –Strategies –Payoff.>")


 to divide a fixed amount between them. P1 (proposer) offers a division of the “pie” P2 (responder) decides.>")
: Every finite game (finite number of players, finite number of pure strategies) has at least one mixed-strategy Nash.>")









 Learning in Games: Camerer and.>")


>")

