Download presentation
Presentation is loading. Please wait.

1
Multithreaded ingestion of BUFR messages from the IDD John Caron Oct 8, 2008

2
Overview BUFR format IDD HRS BUFR data stream Multithreaded processing of IDD messages Indexing data

3
BUFR data format WMO standard for observational met data –circa 1988: “Table Driven Forms” (TDF) –Improvement over “character oriented codes” (eg metars) –Migration from previous forms still large WMO focus –Today: Edition 4 format, Version 13 of the tables Table driven (12000 entries in global tables) –Each record contains a set of data descriptors (dds) –Global WMO and local tables Simple “Compressed binary” –Packed bits, scale/offset covert to float –Fixed precision, no dynamic range –Difference from reference value
 –Improvement over character oriented codes (eg metars) –Migration from previous forms still large WMO focus –Today: Edition 4 format, Version 13 of the tables Table driven (12000 entries in global tables) –Each record contains a set of data descriptors (dds) –Global WMO and local tables Simple Compressed binary –Packed bits, scale/offset covert to float –Fixed precision, no dynamic range –Difference from reference value")
4
3-1-32 : tableD 3-1-1 : tableD 0-1-1 : WMO_block_number units=Numeric scale=0 refVal=0 nbits=7 0-1-2 : WMO_station_number units=Numeric scale=0 refVal=0 nbits=10 0-2-1 : Type_of_station units=Code table scale=0 refVal=0 nbits=2 3-1-11 : tableD 0-4-1 : Year units=Year scale=0 refVal=0 nbits=12 0-4-2 : Month units=Month scale=0 refVal=0 nbits=4 0-4-3 : Day units=Day scale=0 refVal=0 nbits=6 3-1-12 : tableD 0-4-4 : Hour units=Hour scale=0 refVal=0 nbits=5 0-4-5 : Minute units=Minute scale=0 refVal=0 nbits=6 3-1-24 : tableD 0-5-2 : Latitude units=Degree scale=2 refVal=-9000 nbits=15 0-6-2 : Longitude units=Degree scale=2 refVal=-18000 nbits=16 0-7-1 : Height_of_station units=m scale=0 refVal=-400 nbits=15 0-1-18 : Short_station_or_site_name units=CCITT IA5 nchars=5 0-2-3 : Type_of_measuring_equipment_used units=Code table scale=0 refVal=0 2-1-132 : tableC-operators 2-2-130 : tableC-operators 0-2-121 : Mean_frequency units=Hz scale=-8 refVal=0 nbits=7 2-2-0 : tableC-operators 2-1-0 : tableC-operators 0-8-21 : Time_significance units=Code table scale=0 refVal=0 nbits=5 0-4-26 : Time_period_or_displacement units=Second scale=0 refVal=-4096 nbits=13 1-9-0 : replication 0-31-1 : Delayed_descriptor_replication_factor units=Numeric scale=0 refVal=0 0-7-6 : Height_above_station units=m scale=0 refVal=0 nbits=15 0-25-34 : Wind_profiler_quality_control_test_results units=Flag table scale=0 0-11-1 : Wind_direction units=Degree true scale=0 refVal=0 nbits=9 0-11-2 : Wind_speed units=m s-1 scale=1 refVal=0 nbits=12 2-1-127 : tableC-operators 0-11-50 : Standard_deviation_of_horizontal_wind_speed units=m s-1 scale=1 refVal=0 nbits=12 2-1-0 : tableC-operators 0-11-6 : w-component units=m s-1 scale=2 refVal=-4096 nbits=13 0-11-51 : Standard_deviation_of_vertical_wind_speed units=m s-1 scale=1 refVal=0 nbits=8

5
BUFR problems (1) BUFR format is too complex: Looks like design by committee Specification not exact No coding/decoding reference implementation Mixture of data model / data encoding / standard quantities BUFR format is too simple: Fixed length tables (64 categories, 256 entries) eventually run out Fixed dynamic range (no exponents)
 BUFR format is too complex: Looks like design by committee Specification not exact No coding/decoding reference implementation Mixture of data model / data encoding / standard quantities BUFR format is too simple: Fixed length tables (64 categories, 256 entries) eventually run out Fixed dynamic range (no exponents)")
6
BUFR problems (2) Table-driven parsing is brittle No authoritative registry of local Tables WMO global table is not machine-readable Past versions are not available It seems that: Each provider has their own set of software and tables Often legacy Fortran
 Table-driven parsing is brittle No authoritative registry of local Tables WMO global table is not machine-readable Past versions are not available It seems that: Each provider has their own set of software and tables Often legacy Fortran")
7
BUFR Table mismatch No way to be sure if coder/decoder use the same table If table entry missing, cant decode If wrong table entry is used –Bit size wrong, usually can detect with bit counting –Scale/Factor/Name/Units wrong = “silent failure” (expert/human may detect)
")
8
Table mismatches Each archive center probably has solved this coder/decoder matching internally NCEP encodes the tables in BUFR messages, and stores in the archive files Others???

9
BUFR progress As of 9/2008, WMO decided –Will make tables available in Microsoft Access format –Clarified versioning (sort of) Progress in detecting/fixing encoding errors Unidata nudge: email group, validation web site BritMet effort to map BUFR to ISO, define XML version of tables
 Progress in detecting/fixing encoding errors Unidata nudge: group, validation web site BritMet effort to map BUFR to ISO, define XML version of tables")
10
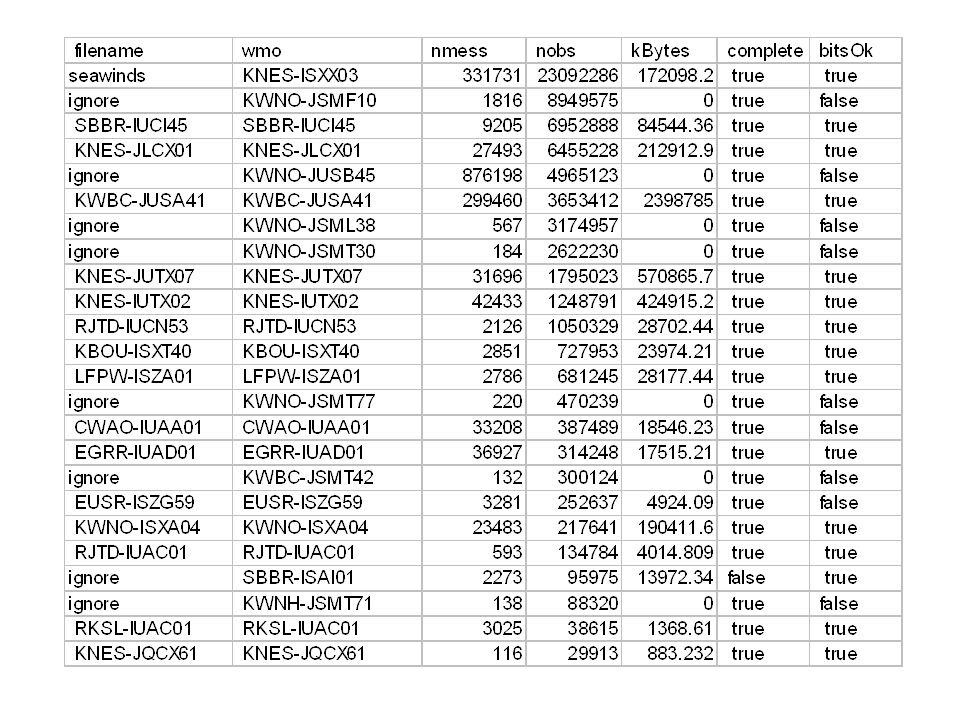
BUFR data on IDD 177 K messages / day 6.7 M observations / day 1.2 Gbytes / day Avg message size = 7227 bytes Avg obs/message = 37 Unique wmo Headers = 555 Unique dds = 125 wmoHeaders with multiple dds = 61

11
Originating Stations CWAO Montreal EDZW Offenbach (RSMC) (78.0) EGRR UK Meteorological Office Bracknell (RSMC) (74.0) EKMI Copenhagen (94.0), EUMG EUMETSAT Operation Centre (254.0) EUSR KBOU The NOAA Forecast Systems Laboratory (59.0) KKCI US National Weather Service (NCEP) (7.0) KNES US NOAA/NESDIS (160.0) KWBC US National Weather Service (NCEP) (7.0) KWNH US National Weather Service (NCEP) KWNO NCEP / Central Operations (7.3) LFPW Toulouse (RSMC) (85.0), RJTD Tokyo (RSMC), Japan Meteorological Agency (34.0) RKSL Seoul 40.0 SBBR Brazilian Space Agency ? INPE (46.0) VHHH Hong-Kong 110.0
 VHHH Hong-Kong")
12
Data heterogeneity Each BUFR record in principle could have its own data schema : 2M database schemas! In reality, there are much smaller number of groups of homogenous records –WMO headers are not sufficient –Can’t use pqact FILE by matching the header –Only the dds itself is reliable –So must crack the message to reliably group the records

14
Multithreaded Processing of IDD Messages

15
Overview Get messages from LDM pipe Process in memory, write out to disk Must be very fast, no blocking I/O Use java.util.concurrent library for multithreading

16
LDM pqact # Get all BUFR messages from HRS HRS ^[IJ] PIPE –metadata java –jar ldm.jar
![LDM pqact # Get all BUFR messages from HRS HRS ^[IJ] PIPE –metadata java –jar ldm.jar](http://images.slideplayer.com/14/4228736/slides/slide_16.jpg "LDM pqact # Get all BUFR messages from HRS HRS ^[IJ] PIPE –metadata java –jar ldm.jar")
17
Read contents Classify type by dds LDM stream Break into Separate messages Message Queue pipe pipeReadingThread (1) (io) ArrayBlockingQueue 1.extract messageThread (1?) (cpu) blocking take MessType processor MessType processor MessType processor 2.dispatch Step 1 and 2 Extract and dispatch
 (io) ArrayBlockingQueue 1.extract messageThread (1 ) (cpu) blocking take MessType processor MessType processor MessType processor 2.dispatch Step 1 and 2 Extract and dispatch")
18
messageThread (1) (cpu) MessType processor Executor CompletionService MessageWriter implements Callable ConcurrentLinkedQueue Owns file eg 2008-09-11.bufr submit dispatch threadPool (n) (io) MessageWriter implements Callable Result call() { write message(s) } 3.write Step 3 Write message
 (cpu) MessType processor Executor CompletionService MessageWriter implements Callable ConcurrentLinkedQueue Owns file eg bufr submit dispatch threadPool (n) (io) MessageWriter implements Callable Result call() { write message(s) } 3.write Step 3 Write message")
19
indexThread (1?) (io) Executor Queue > MessageWriter implements Callable IndexTask call() { write message(s) } Step 4 Index Write message Return IndexerTask Add to Index blocking take
 (io) Executor Queue > MessageWriter implements Callable IndexTask call() { write message(s) } Step 4 Index Write message Return IndexerTask Add to Index blocking take")
20
messageThread (1) (cpu) MessType processor Executor CompletionService MessageWriter implements Callable ConcurrentLinkedQueue Owns file 2008-09-11.bufr submit dispatch Step 5 cleanup cleanupThread (1) (io) Close files Concurrent hashMap ?
 (cpu) MessType processor Executor CompletionService MessageWriter implements Callable ConcurrentLinkedQueue Owns file bufr submit dispatch Step 5 cleanup cleanupThread (1) (io) Close files Concurrent hashMap")
21
indexThread (1?) (io) Executor Queue > Step 6 Scour Add to Index blocking take Remove from Index Delete file scourThread (1) (io)
 (io) Executor Queue > Step 6 Scour Add to Index blocking take Remove from Index Delete file scourThread (1) (io)")
22
Why isnt Scouring part of LDM? LDM is message oriented – doesn’t know contents Decoders know about the contents of the messages Put scouring into the decoders

23
Threads 1.Read from LDM pipe 2.Read message content and dispatch 3.Write Messages to files 4.Index 5.Cleanup / close MessageWriters 6.Scour

24
(Thought) Experiments with Indexing
 Experiments with Indexing")
25
Design prejudices Keep data in original format –Data reliability Aggregate homogeneous data into files –Data locality Create external indices, with pointers into the files –Data recovery Scour entire files, not parts of a file

26
Indexing Need 1D indexes (B-trees) Want 2D indices for spatial data –Rtree (areas) –Quadtree (points) Index selectivity: seek vs. scan –Sequential access ~100x faster than random access –Index must select < 1% data to be useful

27
Possible Open Source Indexers Berkeley DB Java edition –Btree, very fast, no SQL –Dual GPL/commercial license Relational databases “SQL on Btrees” –Java (Derby, H2, many others) –C (MySQL, Postgres) Object databases –Db4o (dual GPL/commercial license)
 –C (MySQL, Postgres) Object databases –Db4o (dual GPL/commercial license)")
28
High performance Embeddable in the decoder –Same process space –Not client/server Access from server answering queries –Multiprocess access or client/server –Bdb must sync periodically (perf?) Transactions probably too slow –Need recovery strategy
 Transactions probably too slow –Need recovery strategy")
29
Test Assumptions Process IDD messages in memory (vs) write to file then postprocess Store in files – add external indexing (vs) store data in database One database vs many? Embedded vs client/server SQL vs specific queries –SQL allows ad-hoc queries - performance? 2D indexing

30
Conclusions Test/time various indexing strategies and technologies –Production –scouring Eventually part of IDD/TDS –Must be easy to maintain (Java) –Scale to large archives / data volumes
 –Scale to large archives / data volumes")
Similar presentations







 NetCDF-Java (aka CDM) has lots of functionality, but only available in Java – NcML Aggregation – Access.>")











 Priscilla Caplan FCLA.>")