Download presentation
Presentation is loading. Please wait.

1
The Replication of DNA THE CHEMISTRY OF DNA SYNTHESIS DNA synthesis requires dNTPs and a primer:template junction (Polarity of primer is important)
")
2
The addition of a deoxyribonucleotide to the 3' end of a polynucleotide chain (the primer strand) is the fundamental reaction by which DNA is synthesized. As shown, base-pairing between an incoming deoxyribonucleoside triphosphate and an existing strand of DNA (the template strand) guides the formation of the new strand of DNA and causes it to have a complementary nucleotide sequence (Which p is incorporated into the new chain?)
 guides the formation of the new strand of DNA and causes it to have a complementary nucleotide sequence (Which p is incorporated into the new chain ).")
3
DNA is synthesized by extending the 3’end of the primer Hydrolysis of pyrophosphate is the driving force for DNA Synthesis G= -7 kcal/mole

4
THE MECHANISM OF DNA POLYMERASE DNA polymerases use a single active site to catalyze DNA synthesis Correctly paired bases are required

5
Steric constrains preventing DNA polymerase from using rNTP precursors

7
Incorporation assays can be used to measure DNA synthesis

8
Anticancer and antiviral agents target DNA replications

9
DNA polymerases resemble a hand that grips the primer:template junction

10
Two metal ions bound to DNA polymerase catalyze the nucleotide addition

11
DNA polymerase “grips” the template and the incoming nucleotide when a correct base pair is made

12
The path of the template DNA through the DNA polymerase; note the bend in the template between the first and second bases

13
The thumb helps to maintain a strong association between the DNA polymerase and its substrate DNA polymerases are processive enzymes; thus the rate of DNA synthesis is dramatically increased (~1000 bp/sec)
")
14
Exonucleases proofread newly synthesized DNA

16
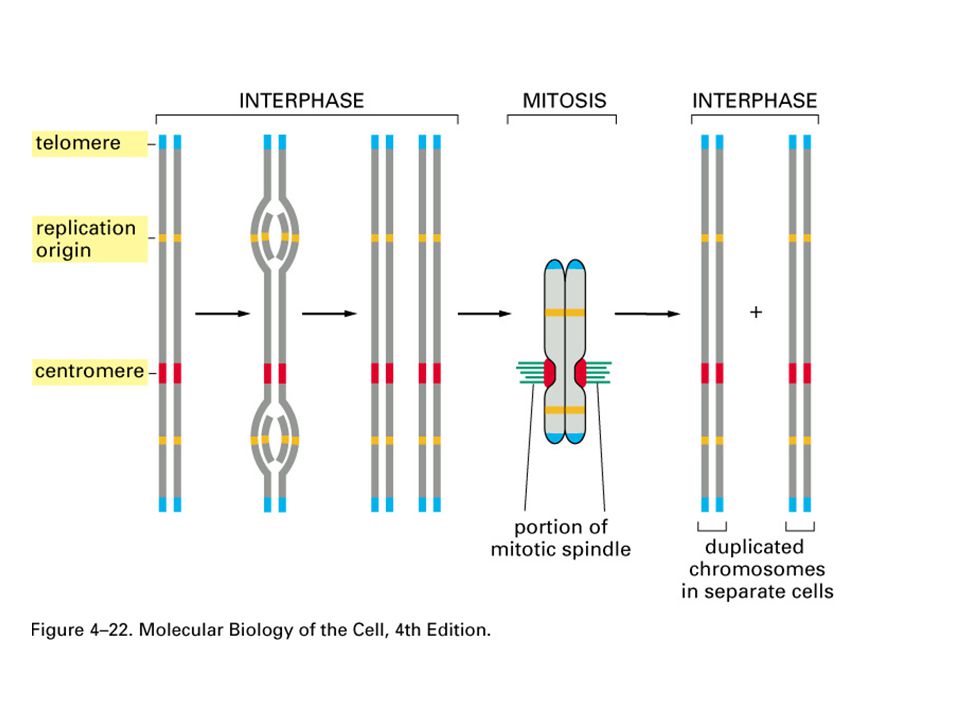
Two replication forks moving in opposite directions on a circular chromosome. An active zone of DNA replication moves progressively along a replicating DNA molecule, creating a Y-shaped DNA structure known as a replication fork: the two arms of each Y are the two daughter DNA molecules, and the stem of the Y is the parental DNA helix. In this diagram, parental strands are orange; newly synthesized strands are red. THE REPLICATION FORK

17
Both strands of DNA are synthesized together at the replication fork

18
The structure of a DNA replication fork. Because both daughter DNA strands are polymerized in the 5'to-3' direction, the DNA synthesized on the lagging strand must be made initially as a series of short DNA molecules, called Okazaki fragments DNA synthesis proceeds in a 5’ to 3’ direction and is semi-discontinuous.

19
The initiation of a new strand of DNA requires an RNA primer

20
RNA primer synthesis. A schematic view of the reaction catalyzed by DNA primase, the enzyme that synthesizes the short RNA primers made on the lagging strand using DNA as a template. Unlike DNA polymerase, this enzyme can start a new polynucleotide chain by joining two or three nucleoside triphosphates together. The primase synthesizes a short polynucleotide in the 5'-to-3' direction and then stops, making the 3' end of this primer available for the DNA polymerase A Special Nucleotide-Polymerizing Enzyme Synthesizes Short RNA Primer Molecules on the Lagging Strand

21
RNA primers must be removed to complete DNA replication

22
DNA helicases unwind the double helix in advance of replication fork

23
An assay used to test for DNA helicase enzymes. A short DNA fragment is annealed to a long DNA single strand to form a region of DNA double helix. The double helix is melted as the helicase runs along the DNA single strand, releasing the short DNA fragment in a reaction that requires the presence of both the helicase protein and ATP. The rapid step-wise movement of the helicase is powered by its ATP hydrolysis

24
Biochemical assay for DNA helicase activity

25
DNA helicase polarity

26
The structure of a DNA helicase. (A) A schematic diagram of the protein as a hexameric ring. (B) Schematic diagram showing a DNA replication fork and helicase to scale. (C) Detailed structure of the bacteriophage T7 replicative helicase, as determined by x-ray diffraction. Six identical subunits bind and hydrolyze ATP in an ordered fashion to propel this molecule along a DNA single strand that passes through the central hole. Red indicates bound ATP molecules in the structure.
 Schematic diagram showing a DNA replication fork and helicase to scale. (C) Detailed structure of the bacteriophage T7 replicative helicase, as determined by x-ray diffraction. Six identical subunits bind and hydrolyze ATP in an ordered fashion to propel this molecule along a DNA single strand that passes through the central hole. Red indicates bound ATP molecules in the structure..")
27
DNA helicase pulls single-stranded DNA through a central protein pore

28
Single-stranded DNA-binding proteins (SSB) stabilize ssDNA prior to replication
 stabilize ssDNA prior to replication")
29
The effect of single-strand DNA-binding proteins (SSB proteins) on the structure of single- stranded DNA. Because each protein molecule prefers to bind next to a previously bound molecule, long rows of this protein form on a DNA single strand. This cooperative binding straightens out the DNA template and facilitates the DNA polymerization process. The “hairpin helices” shown in the bare, single-stranded DNA result from a chance matching of short regions of complementary nucleotide sequence; they are similar to the short helices that typically form in RNA molecules

30
Topoisomerases remove supercoils produced by DNA unwinding at the replication fork

31
Replication fork enzymes extend the range of DNA polymerase

33
THE SPECILIZATION OF DNA POLYMERASES DNA polymerases are specialized for different roles in the cell

34
DNA polymerase switching during eukaryotic DNA replication

35
Sliding clamps dramatically increase DNA polymerase processivity

37
Sliding clamps of E. coli, T4 and eukaryotic cells

38
Sliding clamps are opened and placed on DNA by clamp loaders

39
DNA SYNTHESIS AT THE REPLICATION FORK Composition of the DNA pol III holoenzyme (E. coli)
")
40
E. Coli replication fork

41
08_Figure22a.jpg

42
08_Figure22b.jpg

43
08_Figure22c.jpg

44
08_Figure22d.jpg

45
08_Figure22e.jpg

46
Interactions between replication fork proteins from the E. coli replisome

47
INITIATION OF DNA REPLICATION Specific genomic DNA sequences direct the initiation of DNA Replication The replicon model of replication initiation

48
Replicator sequences (origin of replication) include initiator binding sites and easily unwound DNA
 include initiator binding sites and easily unwound DNA")
49
BINDING AND UNWINDING: ORIGIN SELECTION AND ACTIVATION BY THE INITIATOR PROTEIN

50
Two replication forks moving in opposite directions on a circular chromosome. An active zone of DNA replication moves progressively along a replicating DNA molecule, creating a Y-shaped DNA structure known as a replication fork: the two arms of each Y are the two daughter DNA molecules, and the stem of the Y is the parental DNA helix. In this diagram, parental strands are orange; newly synthesized strands are red.

51
The identification of origins of replication Genetic identification of replicators (origins)
")
53
08_UnFigure09.jpg

55
Protein-protein and protein-DNA interactions direct the initiation process Initiation of DNA Replication (E. coli)
.")
56
Eukaryotic chromosomes are replicated exactly once per cell cycle Incomplete replication causes chromosome breakage

57
Replicators are inactivated by DNA replication

58
Prereplicative complex formation is the first step in the initiation of replication in eukaryotes

59
Assembly of the eukaryotic replication fork

60
Pre-RC formation and activation are regulated to allow only a single round of replication during each cell cycle Cdks: cyclin-dependent kinases

61
Cell cycle regulation of Cdk activity and pre-RC formation

62
Similarities between eukaryotic and prokaryotic DNA replication initiation

63
FINISHING REPLICATION Type II topoisomerases are required to separate daughter DNA molecules

64
Lagging-strand synthesis is unable to copy the extreme ends of linear chromosomes

65
One solution of the end problem is to use protein priming

67
Telomerase Replicates the Ends of Eukaryotic Chromosomes The structure of telomerase. The telomerase is a protein– RNA complex that carries an RNA template for synthesizing a repeating, G-rich telomere DNA sequence. Only the part of the telomerase protein homologous to reverse transcriptase is shown here (green). A reverse transcriptase is a special form of polymerase enzyme that uses an RNA template to make a DNA strand; telomerase is unique in carrying its own RNA template with it at all times.
. A reverse transcriptase is a special form of polymerase enzyme that uses an RNA template to make a DNA strand; telomerase is unique in carrying its own RNA template with it at all times..")
68
Replication of telomeres by telamerase

69
Telamerase solves the end problem by extending the 3’ end of the chromosome

70
Telomere-binding proteins regulate telomerase activity and telomere length S. cerevisiae

71
In human, these proteins form a complex called “Shelterin” to shelter telomeres from DNA repair enzymes

72
Telomeres form a looped structure in the cell

73
The Nobel Prize in Physiology or Medicine 2009 "for the discovery of how chromosomes are protected by telomeres and the enzyme telomerase" Elizabeth H. BlackburnCarol W. GreiderJack W. Szostak 1/3 of the prize USA University of California San Francisco, CA, USA Johns Hopkins University School of Medicine Baltimore, MD, USA Harvard Medical School; Massachusetts General Hospital Boston, MA, USA; Howard Hughes Medical Institute b. 1948 (in Hobart, Tasmania, Australia) b. 1961 b. 1952 (in London, United Kingdom)
 b b (in London, United Kingdom).")
74
Scientists reverse some age effects in mice Researchers artificially age rodents by suppressing a gene that helps repair telomeres, then rejuvenate them by turning back on the genetic switch. But the work is far from any use on humans. (Dr. Ronald DePinho, a molecular biologist at the Dana-Farber Cancer Institute at Harvard Medical School), Los Angeles Times Is This The Fountain Of Youth? Scientists Find Way to Partially Reverse Aging in Mice
, Los Angeles Times Is This The Fountain Of Youth. Scientists Find Way to Partially Reverse Aging in Mice.")
75
Telomerase in human Active Down regulated Highly active Telomerase is on during fetal development and remain active in various proliferative cells. - stem cell, germ cell, hair, activated lymphocytes, etc Telomerase is down- regulated but still detectable in many other adult cells. -epithelial -fibroblast -endothelial 90% of human tumors iBioSeminars: Elizabeth Blackburn, June 2008 Active Down regulatedHighly Active

76
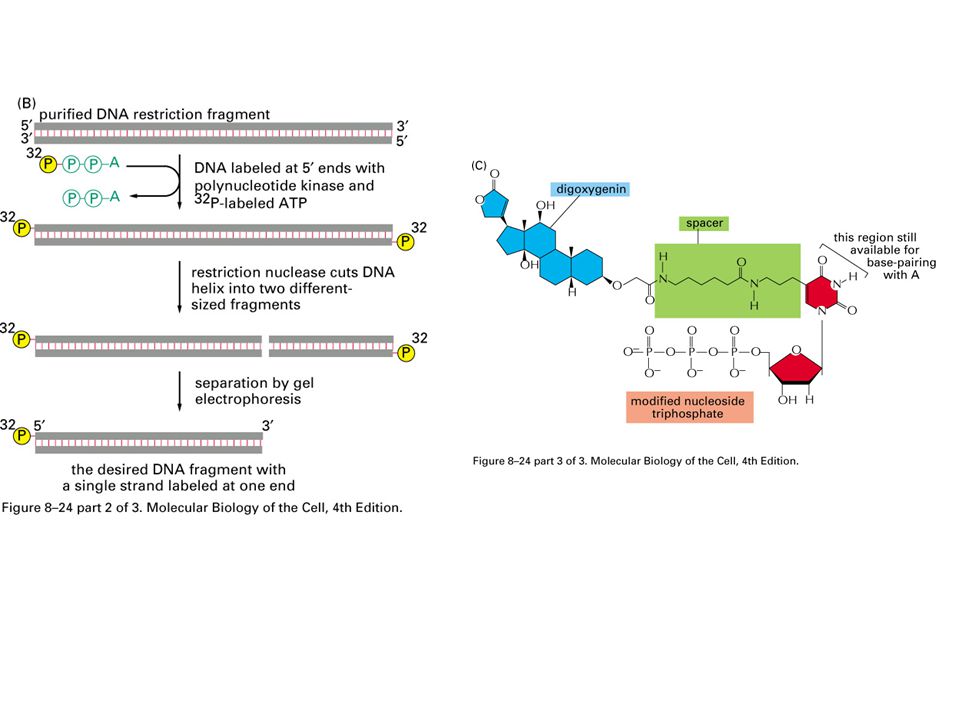
Methods for labeling DNA molecules in vitro. (A) A purified DNA polymerase enzyme labels all the nucleotides in a DNA molecule and can thereby produce highly radioactive DNA probes. (B) Polynucleotide kinase labels only the 5' ends of DNA strands; therefore, when labeling is followed by restriction nuclease cleavage, as shown, DNA molecules containing a single 5'-end-labeled strand can be readily obtained. (C) The method in (A) is also used to produce nonradioactive DNA molecules that carry a specific chemical marker that can be detected with an appropriate antibody. The modified nucleotide shown can be incorporated into DNA by DNA polymerase so as to allow the DNA molecule to serve as a probe that can be readily detected. The base on the nucleoside triphosphate shown is an analog of thymine in which the methyl group on T has been replaced by a spacer arm linked to the plant steroid digoxigenin. To visualize the probe, the digoxigenin is detected by a specific antibody coupled to a visible marker such as a fluorescent dye. Other chemical labels such as biotin can be attached to nucleotides and used in essentially the same way. Purified DNA can be labeled with radioactive or chemical markers
 A purified DNA polymerase enzyme labels all the nucleotides in a DNA molecule and can thereby produce highly radioactive DNA probes. (B) Polynucleotide kinase labels only the 5 ends of DNA strands; therefore, when labeling is followed by restriction nuclease cleavage, as shown, DNA molecules containing a single 5 -end-labeled strand can be readily obtained. (C) The method in (A) is also used to produce nonradioactive DNA molecules that carry a specific chemical marker that can be detected with an appropriate antibody. The modified nucleotide shown can be incorporated into DNA by DNA polymerase so as to allow the DNA molecule to serve as a probe that can be readily detected. The base on the nucleoside triphosphate shown is an analog of thymine in which the methyl group on T has been replaced by a spacer arm linked to the plant steroid digoxigenin. To visualize the probe, the digoxigenin is detected by a specific antibody coupled to a visible marker such as a fluorescent dye. Other chemical labels such as biotin can be attached to nucleotides and used in essentially the same way. Purified DNA can be labeled with radioactive or chemical markers.")
78
In situ hybridization to locate specific genes on chromosomes. Here, six different DNA probes have been used to mark the location of their respective nucleotide sequences on human chromosome 5 at metaphase. The probes have been chemically labeled and detected with fluorescent antibodies. Both copies of chromosome 5 are shown, aligned side by side. Each probe produces two dots on each chromosome, since a metaphase chromosome has replicated its DNA and therefore contains two identical DNA helices. DNA hybridization can be used to identify specific DNA molecules

79
Hybridization probes can identify electrophoretically separated DNA and RNAs

80
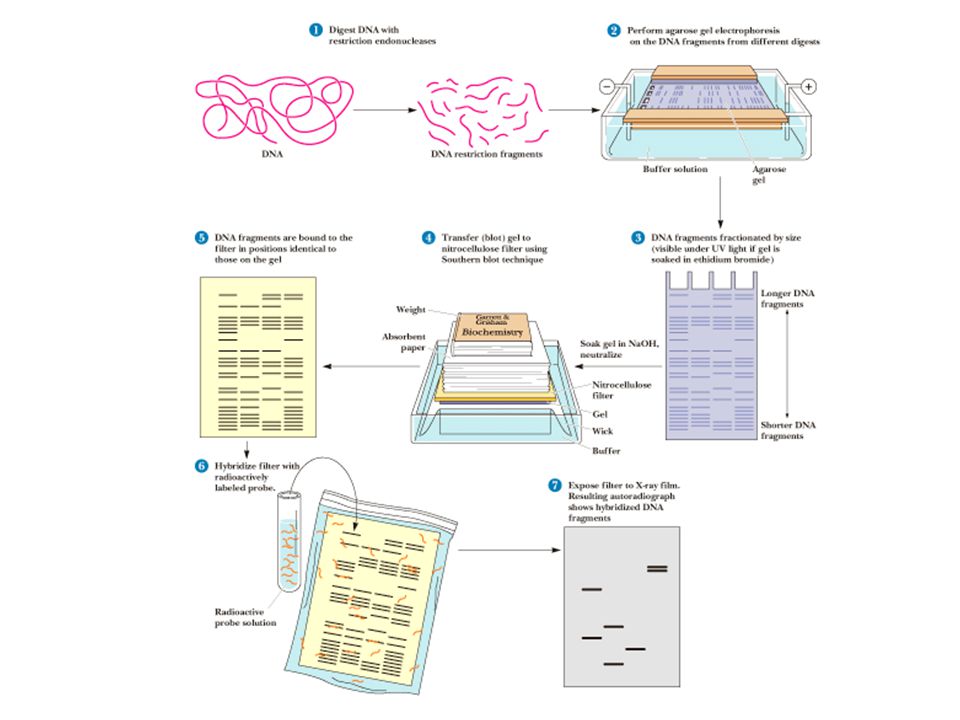
Southern Blots Another way to find desired fragments Subject the DNA library to agarose gel electrophoresis Soak gel in NaOH to convert dsDNA to ssDNA Neutralize and blot gel with nitrocellulose sheet Nitrocellulose immobilizes ssDNA Incubate sheet with labeled oligonucleotide probes Autoradiography should show location of desired fragment(s) Northern and Southern blotting facilitate hybridization with electrophoretically separated nucleic acid molecules
 Northern and Southern blotting facilitate hybridization with electrophoretically separated nucleic acid molecules")
82
PCR (polymerase chain reaction) amplifies DNAs by repeated rounds of DNA replication in vitro
 amplifies DNAs by repeated rounds of DNA replication in vitro")
84
Gene can be selectively amplified by PCR

85
DNA fingerprinting

86
The Nobel Prize in Chemistry 1993 was awarded "for contributions to the developments of methods within DNA-based chemistry" jointly with one half to Kary B. Mullis "for his invention of the polymerase chain reaction (PCR) method"and with one half to Michael Smith "for his fundamental contributions to the establishment of oligonucleotide-based, site-directed mutagenesis and its development for protein studies".
 method and with one half to Michael Smith for his fundamental contributions to the establishment of oligonucleotide-based, site-directed mutagenesis and its development for protein studies ..")
87
How to determine DNA sequences? ddNTPs used in DNA sequencing

88
Chain termination in the presence of ddNTPs

89
DNA sequencing by chain-termination method

91
DNA sequencing gel

92
Automated DNA sequencing. Shown here is a tiny part of the data from an automated DNA-sequencing run as it appears on the computer screen. Each colored peak represents a nucleotide in the DNA sequence—a clear stretch of nucleotide sequence can be read here between positions 173 and 194 from the start of the sequence. This particular example is taken from the international project that determined the complete nucleotide sequence of the genome of the plant Arabidopsis.

93
The Nobel Prize in Chemistry 1980 was divided, one half awarded to Paul Berg "for his fundamental studies of the biochemistry of nucleic acids, with particular regard to recombinant-DNA",the other half jointly to Walter Gilbert and Frederick Sanger "for their contributions concerning the determination of base sequences in nucleic acids". Photos: Copyright © The Nobel Foundation

94
Genomic sequences provide the ultimate genetic libraries The human genomic project strategy

95
Shotgun sequencing a bacterial genome then a partial assembly of large genome sequences

96
Contigs are linked by sequencing the ends of large DNA fragments

97
The pair-end strategy permits the assembly of large-genome scaffolds

99
The Human Genome Project, which unveiled its landmark results a decade ago, relied on the laborious Sanger sequencing method. This involves building complementary DNA strands to match the original sample, until nucleotides labelled with a fluorescent dye are added to halt the process. The copied fragments are then sorted by size to determine the sequence of the original strand.

100
More recently, faster 'next generation' techniques were developed to read a DNA sequence by tracking the construction of a complementary strand as it actually happens. Most methods use fluorescent labelling to identify individual nucleotides as they are added. But these reagents are expensive — each sequencing run can cost thousands of dollars, and may still take more than a week to complete.

101
Each Ion Torrent chip sports 1.2 million DNA-testing wells Ion Personal Genome Machine (PGM) The $500 human genome is within reach Ion Torrent's device instead uses cheaper, natural nucleotides, and senses the hydrogen ions (protons) that are released as each nucleotide is incorporated onto the complementary DNA.
 The $500 human genome is within reach Ion Torrent s device instead uses cheaper, natural nucleotides, and senses the hydrogen ions (protons) that are released as each nucleotide is incorporated onto the complementary DNA.")
102
Microscopic beads carrying fragments of DNA are first loaded into 1.2 million 3.5- micrometre-wide wells covering a small chip that cost $99. The chip is then flooded with washes of different nucleotides bearing the four bases that make up DNA, one after another. The wells are cleaned between each wash. If a nucleotide is complementary to the next unpaired base on the bead, it binds and gives off a hydrogen ion, changing the pH inside the well. This produces an electrical signal, indicating that the base in that particular wash is the next letter of the sequence. Each step takes less than five seconds, enabling a single chip to read about 25 million bases in a single two-hour run, and for just a few hundred dollars. (Nature 475: 348-352, 2011)
.")
Similar presentations