Download presentation
Presentation is loading. Please wait.

1
Analyzing spatial nonstationarity in multivariate relationships UVM math/stat department lecture, march 31, 2004 By Austin Troy 1 1.University of Vermont, Rubenstein School of Environment and Natural Resources

2
Spatial Nonstationarity The notion that relationships change across space. –That is, the relationship between y and (x 1,x 2.... x n ) is non constant from one location to the next. Can a variable be included in a model that proxies for space? Sometimes this is possible, but very often the factors that make one location different from another are non-quantifiable, or involve extremely complex interactions that cannot be parsimoniously modeled. Especially in social research
 is non constant from one location to the next. Can a variable be included in a model that proxies for space. Sometimes this is possible, but very often the factors that make one location different from another are non-quantifiable, or involve extremely complex interactions that cannot be parsimoniously modeled. Especially in social research.")
3
Approaches to nonstationarity There are several approaches to dealing with this problem. Among them are: 1.Create zones of homogeneity and stratify 2.Allow parameters to vary constantly

4
First Approach 1.Parameterize a global model and look at the residuals to detect patterns

5
First Approach Use patterns in residuals to define patches Specify a separate equation for each patch, or stratum

6
Second Approach ’s vary continuously as a function of location (u,v) at each point i (Fotheringham 2002) 2. Continuous variation: Create measures of statistical relationships that are continuously varying across space, such as GWR

7
GWR Weighted moving window regression method developed by Foterhingham and Brundson (2000, 2002), building on works of Hastie and Tibshirani (1990) and Loader (1999) Expanded form of simple multiple regression equation Coefficients are deterministic functions of location in space Uses weighted least squares approach Fully unbiased estimate of local coefficient is impossible, but estimates with only slight bias are possible
, building on works of Hastie and Tibshirani (1990) and Loader (1999) Expanded form of simple multiple regression equation Coefficients are deterministic functions of location in space Uses weighted least squares approach Fully unbiased estimate of local coefficient is impossible, but estimates with only slight bias are possible")
8
GWR estimation Separate regression is run for each observation, using a spatial kernel that centers on a given point and weights observations subject to a distance decay function. Can used fixed size kernel or adaptive kernel to determine number of local points that will be included in each local regression Adaptive kernels used when data is not evenly distributed

9
GWR kernel From Fotheringham, Brundson and Charlton. 2002. Geographically Weighted Regression GWR with fixed kernelGWR with adaptive kernel Points are weighted based on distance from center of kernel e.g. Gaussian kernel where weighting is given by: w i (g) = exp[-1/2(d ij /b) 2 where b is bandwidth
 = exp[-1/2(d ij /b) 2 where b is bandwidth.")
10
GWR kernel Adaptive kernel width is determined through minimization of the Akaike Information Criterion where tr(S) is the trace of the hat matrix and n is the number of observations
 is the trace of the hat matrix and n is the number of observations")
11
Bias and variance tradeoff Tradeoff between bias and standard error The smaller the bandwidth, the more variance but the lower the bias, the larger the bandwidth, the more bias but the more variance is reduced This is because we assume there are many betas over space and the more it is like a global regression, the more biased it is. AIC minimization provides a way of choosing bandwidth that makes optimal tradeoff between bias and variance.

12
GWR outputs The result is a statistical output showing global summary stats and parameters estimates, local model summary stats and non-stationarity stats for each parameter Also produces a map output of points with parameter estimates, standard errors and “pseudo t statistics” for each variable for each point

13
A simple (?) question we can address with this approach How is proximity to trees and other “green assets” reflected in property values?
 question we can address with this approach How is proximity to trees and other green assets reflected in property values")
14
We can ask this with hedonic analysis Econometric method for disaggregating observed housing prices into a series of unobserved “implicit” prices, reflective of WTP for a given marginal change in attribute Price= fn(structure, lot, location) Has been used extensively for valuing environmental amenities and disamenities
 Has been used extensively for valuing environmental amenities and disamenities")
15
Hedonics and space Hedonic analysis is generally taken to be spatially stationary; that is, it is assumed that marginal WTP for an attribute is fixed within a housing market. Usually these markets are assumed to be quite big and tools for determining these market boundaries are poorly developed (see approach 1, earlier)
.")
16
Case Study:Two Scales of analysis 1.Block group level analysis of median housing price as fn of tree cover, controlling for many other factors 2.Property level analysis of housing prices as a function of tree cover and parks, controlling for structural, locational and environmental attributes (hedonics) Research is part of the Baltimore Ecosystem Study, an NSF-LTER
 Research is part of the Baltimore Ecosystem Study, an NSF-LTER")
17
Block group analysis Initial pattern of housing values tells us what we know intuitively: suburbs are more valuable than central city, but value goes down again as you get too far from city center

18
Block group analysis Average canopy cover by block group, as derived from 2000 USGS 30 m canopy cover analysis

19
Running GWR at the BG level Given the spatial dependence in the data, it is likely that the coefficients of a multivariate relationship will be related to the spatial processes underlying the spatial dependence. Hence, we choose to run GWR and compare it to global regression.

20
Equation Predictor variables= Median age Percent with income greater than $100k Median household income Percent owner occupied housing Percent vacant buildings Percent single family detached homes Mean tree canopy percentage Median number of rooms per house Median age of housing Percent with mortgage Percent high school educated Percent African American Percent Protected Land

21
Data This was run using census block group data from 2000 for the five counties in the Baltimore Metro Area Observational problem: while population of BGs is relatively constant, size is not, hence may be some form of Modifiable Areal Unit Problem; may be varying levels of heterogeneity within block groups

22
Results: Global Model Global model: highly significant Canopy is significant at α =.05, while percent protected land is not All other control variables are

23
Comparison of Local and Global The ANOVA tests the null hypothesis that the GWR model represents no improvement over a global model and rejects the null Notice also that Coefficient of Determination increases significantly and AIC decreases

24
Local Parameter variabilty We also conduct a Monte Carlo Significance test which finds that almost all variables are spatially non- stationary, although protected land is not

25
How does this testing work? We expect all parameters to have slight spatial variations; is that variation sufficient to reject the null hypothesis that it is globally fixed? If so, then any permutation of regression variable against locations is equally likely, allowing us to model a null distribution of the variance A Monte Carlo approach is adopted to create this distribution in which the geographical coordinates of the observations are randomly permuted aginst the variables n times; results in n values of the variance of the coefficient of interest which we use as an experimental distribution We can then compare the actual value of the variance against these values to obtain the experimental significance level

26
Local R squared shows that model fit varies by locations

27
Notice also how under GWR, there is no pattern to the residuals because it accounts for spatial effects

28
Results show that the city center is where tree canopy cover is valued highest on the margin; this might be because trees are scarcest there

29
However, the pseudo t statistic reveals that not all areas are significant

30
When we blank out the non- significant observations, we see that trees are only significantly reflected in property values in some areas, and it’s negative in Howard County

31
Interpretation In some areas, canopy cover is valued more highly than in others. The degree to which canopy is valued may relate to the scarcity or spatial distribution of trees at multiple scales. It may be negative in Howard county because trees are associated with some other factor, like “ruralness,” which is not properly quantified by the census and which exerts downward influence on housing prices

32
Other variables We’ll ignore protected land, since it’s not non-stationary. However, some of the other control variables are telling. Let’s look at median house age.

33
Pattern makes sense: older homes yield a positive premium in the more affluent suburb, but a negative premium in the poorer central city

34
When we do a cluster analysis (PAM) based on 3 parameter values (canopy, house age and number of rooms), we get something looking like markets
 based on 3 parameter values (canopy, house age and number of rooms), we get something looking like markets")
35
Here’s what it looked like with 6 Note that the silhouette score for the PAM was.55 for the 4 class and.5 for the 6 class— strong structuring

36
Problems with this approach Using block group level data is not ideal for a number of reasons –Modifiable Areal Unit Problem –BG obscures significant within unit heterogeneity –Level of heterogeneity (variance) varies between observations –There may be spatial clustering within BGs –Data is not very accurate at this level –Attribution not great either
 varies between observations –There may be spatial clustering within BGs –Data is not very accurate at this level –Attribution not great either")
37
Property Level Analysis Property level analysis is way of dealing with the local spatial heterogeneity and of getting much better attribution Used Maryland Property View data set for half of Baltimore City Regressed log price against 22 variables, including structural, neighborhood and locational variables, including several environmental variables

38
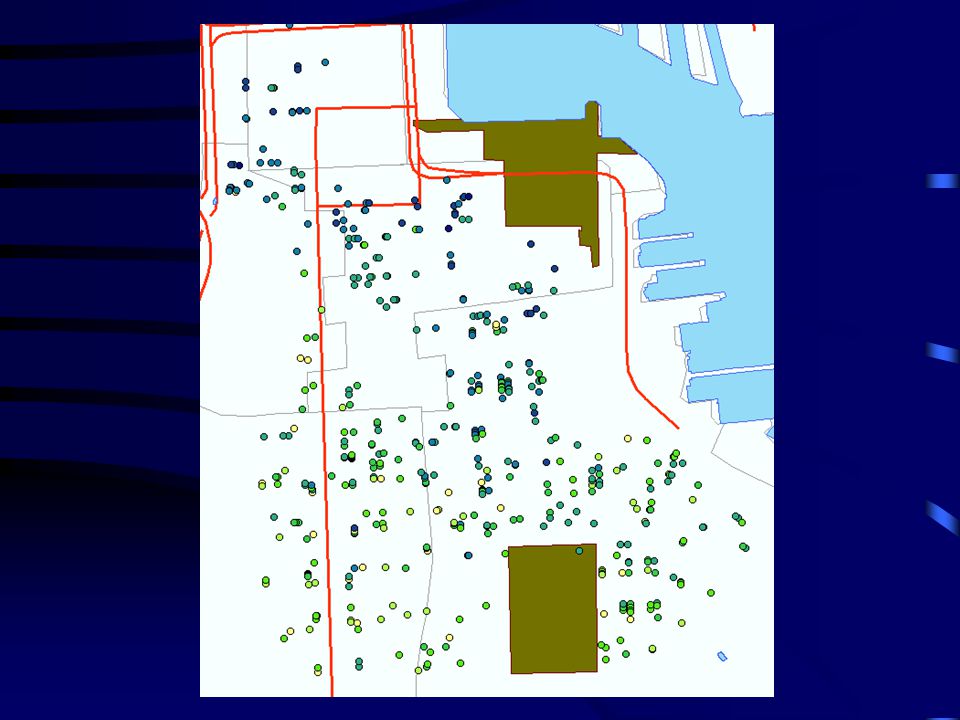
Simple plot of log price shows that while there are slight patterns, there is still considerable heterogeneity over space and no clear patches are emergent Moreover, price is only one factor and social patches are defined on a number of factors

40
Plotting out log price normalized by square footage gives a similarly heterogeneous result Other plots of other variables also show similar heterogeneity

41
Overall results Local model was a considerable improvement over the global model

42
Non-stationarity of parameters Monte Carlo significance test used to determine whether parameters are significantly non-stationary All but 4 were at the =.05 significance level

43
Plotting out Parameter Estimates and T values

44
Parameter on dummy variable for trees within 20 meters

45
T value on tree dummy variable The only real significant relationship is on east side of study area Note that 1458 out of 2350 observations had a “1” for this value. A better approach for future would be tree density index

46
Parameter value on distance to nearest park

47
T value on Distance to nearest park Areas where parks are highly valued in the real estate market

48
Number of Baths Parameter values show clear patchiness Here an additional bathroom adds 6- 9% to home value Here it adds 1.5 to 3%

49
T value of parameter on number of bathrooms shows that number of bathrooms only significantly related to price in northern neighborhoods (small dots are observations where parameter estimate is insignificant)
")
50
Parameter value on dummy for single family home

51
T value on SFH dummy Note that even though there are SFHs in the south, SFH status only appears to add value in the North

52
Parameter values on Age of Structure Shows clear patchiness

53
T values on Age of Structure Shows age is most significantly related to price near center of town. Only in northeast is it positively related, suggest that older homes have “historic” value there but not elsewhere

54
Generating fuzzy Surfaces With this data, surfaces can be interpolated showing the change in parameter values over space Unfortunately, this only works well where most points have significant parameter estimates

55
Surface Example: Parameter on Distance to park Interpolation allows us to much more clearly see “patches” because it smoothes out some of the within-group heterogeneity

56
Surface Example: Parameter on structure age

57
T Value on structure age Note that interpolation of t value looks almost the same

58
Combining interpolated layers In a preliminary attempt we took four interpolated layers for dummy variables (hence all on the same scale), including structure age>80, trees w/in 20 meter, SFH and brick and added them together to get a test composite layer; the more layers we add, the more we begin to see clear differentiations between neighborhoods
, including structure age>80, trees w/in 20 meter, SFH and brick and added them together to get a test composite layer; the more layers we add, the more we begin to see clear differentiations between neighborhoods")
59
Patch Classification This can then be used to classify areas into distinct patches or zones These zone boundaries are based on a vector of parameters from the multivariate equation This is extremely preliminary—an example for display

60
Conclusion GWR offers an excellent way to define meaningful socio-economic boundaries It allows us to look at the spatial arrangement of the relationship between y and z, controlling for all other variation In particular, it offers an excellent way to look at the spatial variability of social phenomena, which are often mediated by spatial processes that cannot be quantified, like trying to stay friendly with your neighbors and neighborhood association Suggests that preferences do vary over space and that future analyses must take this into account

Similar presentations













 Chapter 14 Introduction to Multiple Regression.>")




>")
