Download presentation
Presentation is loading. Please wait.

1
J. Peter Rosenfeld, John Meixner, Michael Winograd, Elena Labkovsky, Alex Sokolovsky, Xiaoxing Hu,Alex Haynes, Northwestern University

2
Karis, Fabiani, & Donchin (1984) demonstrated two important phenomena: 1) A list of words was learned and then a subset of these was presented among a larger set of other, novel words in a later test. It was found that the recalled, previously exposed, familiar words evoked larger P300s than novel words. 2) Some of the old words were initially presented in an unusual (oddball) font size, which made them more memorable.
 Some of the old words were initially presented in an unusual (oddball) font size, which made them more memorable..")
4
PROBE: GUILTY KNOWLEDGE ITEM: $5000 Press non-target button. IRRELEVANT: OTHER AMOUNT: $200 Press non-target button. TARGET: OTHER AMOUNT: $3000 Press target button.

6
80% to 95% correct detection rates….but…. *Rosenfeld et al. (2004) and Mertens, Allen et al. (2008):These methods are vulnerable to Counter-measures (CMs). ( A CM is an attempt to defeat the test)
 and Mertens, Allen et al. (2008):These methods are vulnerable to Counter-measures (CMs). ( A CM is an attempt to defeat the test).")
7
… leads to 2 tasks for each stimulus: 1. implicit probe recognition vs. 2. explicit Target/Non-Target discrimination Possible Result: Mutual Interference more task demand reduced Probe P300 that is not as big as it could be. This is why CMs hurt Old test.

8
When you see a specific irrelevant, SECRETLY make some response, mental/physical. After all, if you can make a special response to TARGET on instruction from operator, you can secretly instruct yourself to do the same thing to other irrelevants. Irrelevant becomes secret target that evokes big P300. If P = I, no diagnosis.

9
Results from Rosenfeld et al. (2004): Farwell-Donchin paradigm (BAD and BCAD are 2 analysis methods.) Diagnoses of Guilty Guilty Group Innocent Group CM Group 9/11(82 %) 1/11(9%) 2/11(18%) Amplitude Difference (BAD) method,p=.1 Cross-Correlation(BC-AD ) Method, p=.1 6/11(54 %) 0/11(0%) 6/11(54 %)
: Farwell-Donchin paradigm (BAD and BCAD are 2 analysis methods.) Diagnoses of Guilty Guilty Group Innocent Group CM Group 9/11(82 %) 1/11(9%) 2/11(18%) Amplitude Difference (BAD) method,p=.1 Cross-Correlation(BC-AD ) Method, p=.1 6/11(54 %) 0/11(0%) 6/11(54 %).")
10
Week BAD* BC-AD* 1: no CM 12/13(.92) 9/13(.69) 2: CM 6/12(.50) 3/12(.25) 3: no CM 7/12(.58) 3/12(.25) *Note: BCD and BAD are 2 kinds of analytic bootstrap procedures.
 9/13(.69) 2: CM 6/12(.50) 3/12(.25) 3: no CM 7/12(.58) 3/12(.25) *Note: BCD and BAD are 2 kinds of analytic bootstrap procedures.")
11
First study to follow… it was based on detection of autobiographical information: birth dates

12
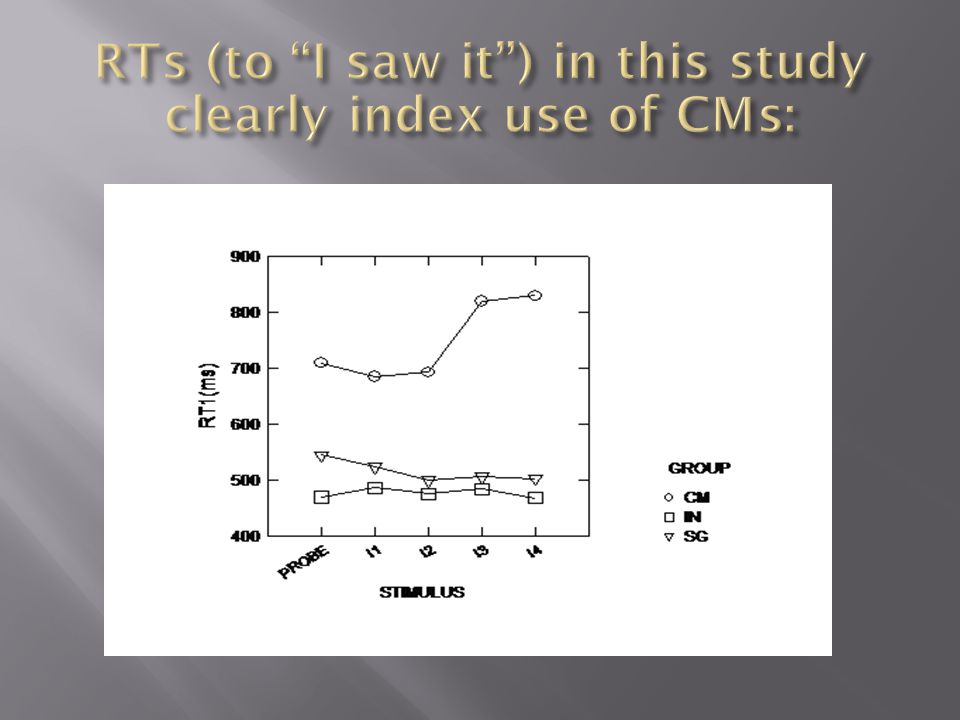
2 stimuli, separated by about 1 s, per trial, S1; Either P or I…..then…..S2 ; either T or NT. *There is no conflicting discrimination task when P is presented, there is simple “I saw it!”… so P300 to probe is expected to be as large as possible due to P’s salience, which should lead to good detection; 90-100 % in Rosenfeld et al.(2008) with autobiographical information. It is also CM resistant. (Delayed T/NT still holds attention.) * “I saw it” response to S1. RT indexes CM use.
 with autobiographical information. It is also CM resistant. (Delayed T/NT still holds attention.) * I saw it response to S1. RT indexes CM use..")
14
WEEK Hit Rate Week 1 (no CM): 11/12* (92%) Week 2 (CM): 10/11* (91%) Week 3 (no CM): 11/12* (92%) Results with innocent (control) group. Confidence=.9 Confidence=.95 Test FPs Hits A’ FPs Hits A’ Iall.08.92.95 0.92.98 Imax 0.92.98 0.92.98

15
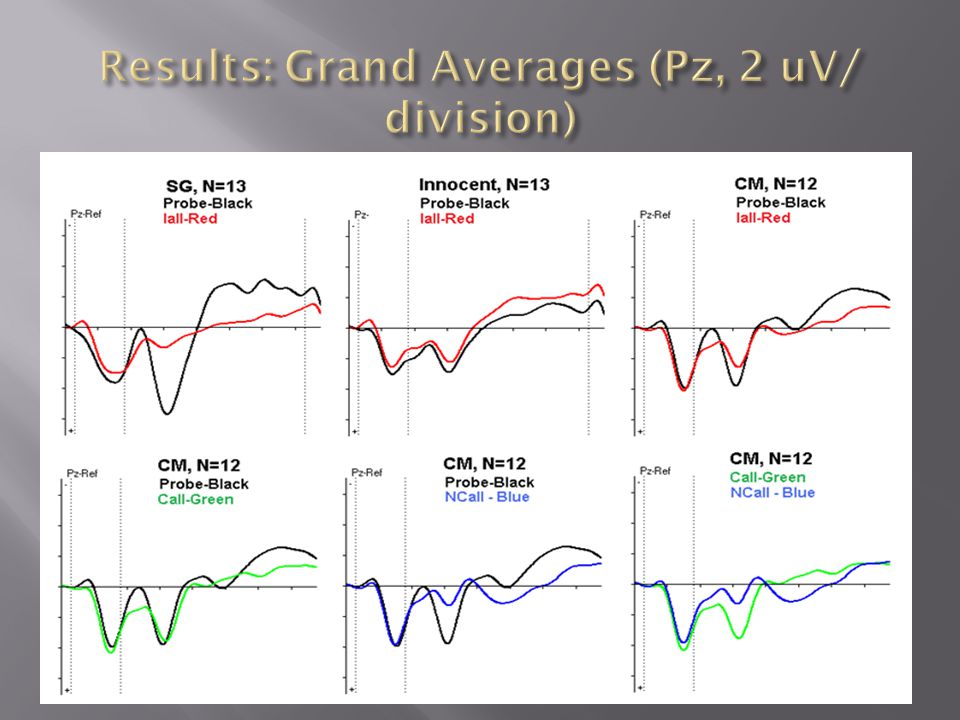
Subjects were divided into three groups (n=12) Simple Guilty (SG), Countermeasure (CM), and Innocent Control (IC) All subjects first participated in a baseline reaction time (RT) test in which they chose a playing card and then completed the CTP using cards as stimuli. SG and CM subjects then committed a mock crime. Subjects stole a ring out of an envelope in a professor’s mailbox. Subjects were never told what the item would be, to ensure any knowledge would be incidentally acquired through the commission of the mock crime. All subjects were then tested for knowledge of the item that was stolen. There were 1 P (the ring) and 6 I( necklace,watch,etc). CM subjects executed covert assigned responses to irrelevant stimuli in an attempt to evoke P300s to these stimuli to try and beat the Probe vs. Irrelevant P300 comparison.
 and 6 I( necklace,watch,etc). CM subjects executed covert assigned responses to irrelevant stimuli in an attempt to evoke P300s to these stimuli to try and beat the Probe vs. Irrelevant P300 comparison..")
18
Condition Detections Percentage SG 10/12 83 CM 12/12 100 IC 1/12 8

20
As with autobiographical information, the CTP was found to be highly sensitive at detecting incidentally acquired concealed knowledge in a mock-crime scenario. Detection rates using the CTP compare favorably to similar polygraph CITs. The main advantage of the CTP over the old P300 or polygraph CIT is its resistance to CM use. The traditional covert-response CMs used to defeat past P300 CITs were found to be ineffective against the CTP, and actually led to larger Probe-Irrelevant amplitude differences and detection rates. CM use was also easily identified by a large increase in RT between the baseline and experimental blocks.

21
So now we have a 5-button box for the left hand. The subject is instructed to press, at random *, one of the 5 buttons as the “I saw it” response to S1 on each trial with no repeats. T and NT (S2) stimuli and responses are as previously. We also hoped that this would make CMs harder to do. It didn’t, but we caught the CM users anyway. * We have done other studies with non-random, explicitly assigned responses also.
 stimuli and responses are as previously. We also hoped that this would make CMs harder to do. It didn’t, but we caught the CM users anyway. * We have done other studies with non-random, explicitly assigned responses also..")
22
Autobiographical information (birthdates): One P and 4 I (other, non-meaningful dates). *3 Groups as before: SG,CM, IC. *NEW: mental CMs to only 2 of the 4 Irrelevants: Say to yourself your first name was the CM1, your last name as CM2. These are assigned prior to run. *Why 2 irrels? Meixner &Rosenfeld (2010) showed countering all Irrels, not probe gives probe extra, special significance. We did a study with only irrels (5), one of which was not countered. It had big P300. So doing CMs to all irrels is not a good strategy from perp’s perspective. *Why mental CMs? They should be faster and a bigger challenge for our CTP. Only one block per group (no baseline).
 showed countering all Irrels, not probe gives probe extra, special significance. We did a study with only irrels (5), one of which was not countered. It had big P300. So doing CMs to all irrels is not a good strategy from perp’s perspective. *Why mental CMs. They should be faster and a bigger challenge for our CTP. Only one block per group (no baseline)..")
24
Group BT/Iall.9 BT/Imax.9 SG 13/13 (100%) 13/13 (100%) IC 1/13 (7.6%) 1/13 (7.6%) CM 12/12 (100%) 10/12 (83%)* * These are screened via RT, which still nicely represents CM use within a block.
 13/13 (100%) IC 1/13 (7.6%) 1/13 (7.6%) CM 12/12 (100%) 10/12 (83%)* * These are screened via RT, which still nicely represents CM use within a block.")
27
Elena Labkovsky & Peter Rosenfeld

29
John Meixner & Peter Rosenfeld How do you catch bad guys before crimes are committed, and before you know what was done, where, when?

31
A Mock Terrorism Application of the P300-based Concealed Information Test Department of Psychology, Northwestern University, Evanston, IL 60208-2700

32
IallImaxBlind Imax GuiltyInnocentGuiltyInnocentGuiltyInnocent 1000648985287985603 1000610999416998602 955598889476892649 996611898430893605 99415094617943689 909475698284761547 945600677365702536 997555959250961569 999586908217907565 985 690 888 382886706 912390 667 129698650 903644 837 215842702 966546863289872619 12/120/1212/120/1210/120/12 AUC = 1.0 AUC =.979 Table 1. Individual bootstrap detection rates. Numbers indicate the average number of iterations (across all three blocks) of the bootstrap process in which probe was greater than Iall or Imax. Blind Imax numbers indicate the average number of iterations in which the largest single item (probe or irrelevant) was greater than the second largest single item. Mean values for each column are displayed in bold above detection rates.
 of the bootstrap process in which probe was greater than Iall or Imax. Blind Imax numbers indicate the average number of iterations in which the largest single item (probe or irrelevant) was greater than the second largest single item. Mean values for each column are displayed in bold above detection rates..")
33
CTP is a promising, powerful paradigm, against any number of CMs, mental and/or physical and RT reliably indicates CM use. The new “P900” might also. jp-rosenfeld@northwestern.edu

34
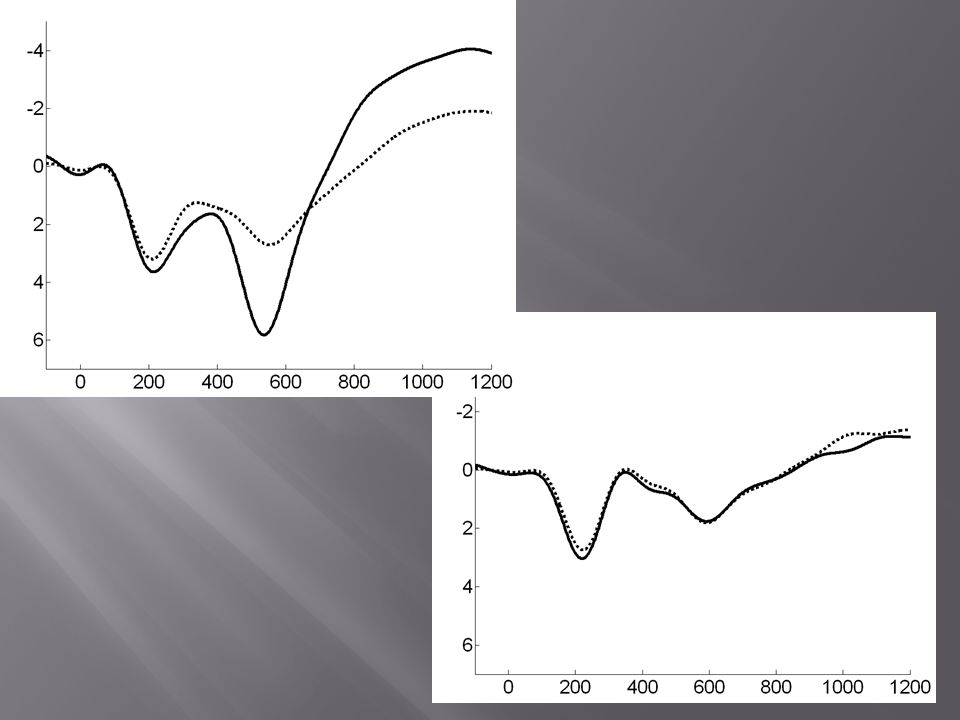
Separated or split away from are called “splitting CMs”. What happens if subjects are instructed to do CM and “I saw it” response at the same time? They lump these acts together. This is called “Lumping CMs.”

36
Xiaoxing Hu to the rescue! (with Dan Hegeman and Elizabeth Landry). He simply increased irrelevants from 4 to 8, which should increase demand and RT…

42
Remember, Allen Hu gave the CMs to Ss in advance and let them rehearse. And his subjects were geniuses, like you all…

43
So we are now working with 10 Irrelevant items… and 3,5,7 CMs.

44
… it is obvious that having to form—on the spot-- and hold 6 CMs for 6 of 8 Irrels in your head –as must happen in the field--is probably too hard for most bad guys to do.

Similar presentations














. Component Processes in Task Switching Cognitive Psychology, 41, 211-253.>")

 Isato.>")


>")













