Download presentation
Presentation is loading. Please wait.

1
Response Regret Martin Zinkevich AAAI Fall Symposium November 5 th, 2005 This work was supported by NSF Career Grant #IIS-0133689.

2
Outline Introduction Repeated Prisoners’ Dilemma Tit-for-Tat Grim Trigger Traditional Regret Response Regret Conclusion

3
The Prisoner’s Dilemma Two prisoners (Alice and Bob) are caught for a small crime. They make a deal not to squeal on each other for a large crime. Then, the authorities meet with each prisoner separately, and offer a pardon for the small crime if the prisoner turns (his/her) partner in for the large crime. Each has two options: Cooperate with (his/her) fellow prisoner, or Defect from the deal.
 partner in for the large crime. Each has two options: Cooperate with (his/her) fellow prisoner, or Defect from the deal..")
4
Bimatrix Game Alice: 5 years Bob: 5 years Alice: 0 years Bob: 6 years Alice Defects Alice: 6 years Bob: 0 years Alice: 1 year Bob: 1 year Alice Cooperates Bob Defects Bob Cooperates

5
Bimatrix Game Bob Cooperates Bob Defects Alice Cooperates -1,-1-6,0 Alice Defects 0,-6-5,-5

6
Nash Equilibrium Bob Cooperates Bob Defects Alice Cooperates -1,-1-6,0 Alice Defects 0,-6-5,-5

7
The Problem Each acting to slightly improve his/her circumstances hurts the other player, such that if they both acted “irrationally”, they would both do better.

8
A Better Model for Real Life Consequences for misbehavior These improve life A better model: Infinitely repeated games

9
The Goal Can we come up with algorithms with performance guarantees in the presence of other intelligent agents which take into account the delayed consequences? Side effect: a goal for reinforcement learning in infinite POMDPs.

10
Regret Versus Standard RL Guarantees of performance during learning. No guarantee for the “final” policy… …for now.

11
A New Measure of Regret Traditional Regret measures immediate consequences Response Regret measures delayed effects

12
Outline Introduction Repeated Prisoners’ Dilemma Tit-for-Tat Grim Trigger Traditional Regret Response Regret Conclusion

13
Outline Introduction Repeated Prisoners’ Dilemma Tit-for-Tat Grim Trigger Traditional Regret Response Regret Conclusion

14
Repeated Bimatrix Game -5,-50,-6 Alice Defects -6,0-1,-1 Alice Cooperates Bob Defects Bob Cooperates

15
Finite State Machine (for Bob) Bob cooperates Bob defects Alice defects Alice defects Alice * Alice cooperates Bob cooperates Alice cooperates
 Bob cooperates Bob defects Alice defects Alice defects Alice * Alice cooperates Bob cooperates Alice cooperates")
16
Grim Trigger Bob cooperates Bob defects Alice defects Alice * Alice cooperates

17
Always Cooperate Bob cooperates Alice *

18
Always Defect Bob defects Alice *

19
Tit-for-Tat Bob cooperates Bob defects Alice defects Alice defects Alice cooperates Alice cooperates

20
Discounted Utility Bob cooperates Bob defects Alice cooperates Alice defects Alice defects Alice cooperates GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP C -1 D 0 C -6 D 0 C -6 GO Pr[ ]=2/3 STOP Pr[ ]=1/3
![Discounted Utility Bob cooperates Bob defects Alice cooperates Alice defects Alice defects Alice cooperates GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP C -1 D 0 C -6 D 0 C -6 GO Pr[ ]=2/3 STOP Pr[ ]=1/3](http://images.slideplayer.com/13/4108373/slides/slide_20.jpg "Discounted Utility Bob cooperates Bob defects Alice cooperates Alice defects Alice defects Alice cooperates GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP GO STOP C -1 D 0 C -6 D 0 C -6 GO Pr[ ]=2/3 STOP Pr[ ]=1/3")
21
Discounted Utility The expected value of that process t=1 1 u t t-1

22
Optimal Value Functions for FSMs V * (s) discounted utility of OPTIMAL policy from state s V * (s) immediate maximum utility at state s V * ( B ) discounted utility of OPTIMAL policy given belief over states B V * ( B ) immediate maximum utility given belief over states B GO Pr[ ]= STOP Pr[ ]=(1-)
![Optimal Value Functions for FSMs V * (s) discounted utility of OPTIMAL policy from state s V * (s) immediate maximum utility at state s V * ( B ) discounted utility of OPTIMAL policy given belief over states B V * ( B ) immediate maximum utility given belief over states B GO Pr[ ]= STOP Pr[ ]=(1-)](http://images.slideplayer.com/13/4108373/slides/slide_22.jpg "Optimal Value Functions for FSMs V * (s) discounted utility of OPTIMAL policy from state s V * (s) immediate maximum utility at state s V * ( B ) discounted utility of OPTIMAL policy given belief over states B V * ( B ) immediate maximum utility given belief over states B GO Pr[ ]= STOP Pr[ ]=(1-)")
23
Best Responses, Discounted Utility If >1/5, a policy is a best response to grim trigger iff it always cooperates when playing grim trigger. Bob cooperates Bob defects Alice defects Alice * Alice cooperates

24
Best Responses, Discounted Utility Similarly, if >1/5, a policy is a best response to tit-for-tat iff it always cooperates when playing tit-for-tat. Bob cooperates Bob defects Alice defects Alice defects Alice cooperates Alice cooperates

25
Knowing Versus Learning Given a known FSM for the opponent, we can determine the optimal policy (for some ) from an initial state. However, if it is an unknown FSM, by the time we learn what it is, it will be too late to act optimally.

26
Grim Trigger or Always Cooperate? Bob cooperates Bob defects Alice defects Alice * Alice cooperates Bob cooperates Alice * Grim TriggerAlways Cooperate For learning, optimality from the initial state is a bad goal.

27
Deterministic Infinite SMs represent any deterministic policy de-randomization C D C C D D D

28
New Goal Can a measure of regret allow us to play like tit-for-tat in the Infinitely Repeated Prisoner’s Dilemma? In addition, it should be possible for one algorithm to minimize regret against all possible opponents (finite and infinite SMs).
..")
29
Outline Introduction Repeated Prisoners’ Dilemma Tit-for-Tat Grim Trigger Traditional Regret Response Regret Conclusion

30
Traditional Regret: Rock-Paper-Scissors Bob plays Rock Bob plays Paper Bob plays Scissors Alice plays Rock Tie Bob wins $1 Alice wins $1 Alice plays Paper Alice wins $1 Tie Bob wins $1 Alice plays Scissors Bob wins $1 Alice wins $1 Tie

31
Traditional Regret: Rock-Paper-Scissors Bob plays Rock Bob plays Paper Bob plays Scissors Alice plays Rock 0,00,0-1,11,-1 Alice plays Paper 1,-10,00,0-1,1 Alice plays Scissors -1,11,-10,00,0

32
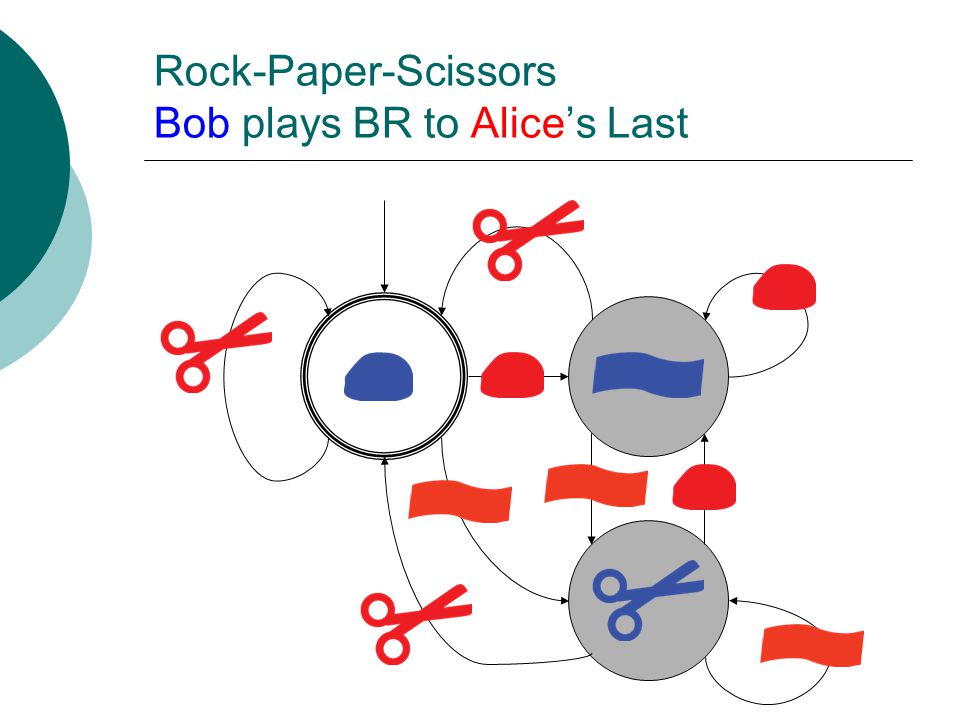
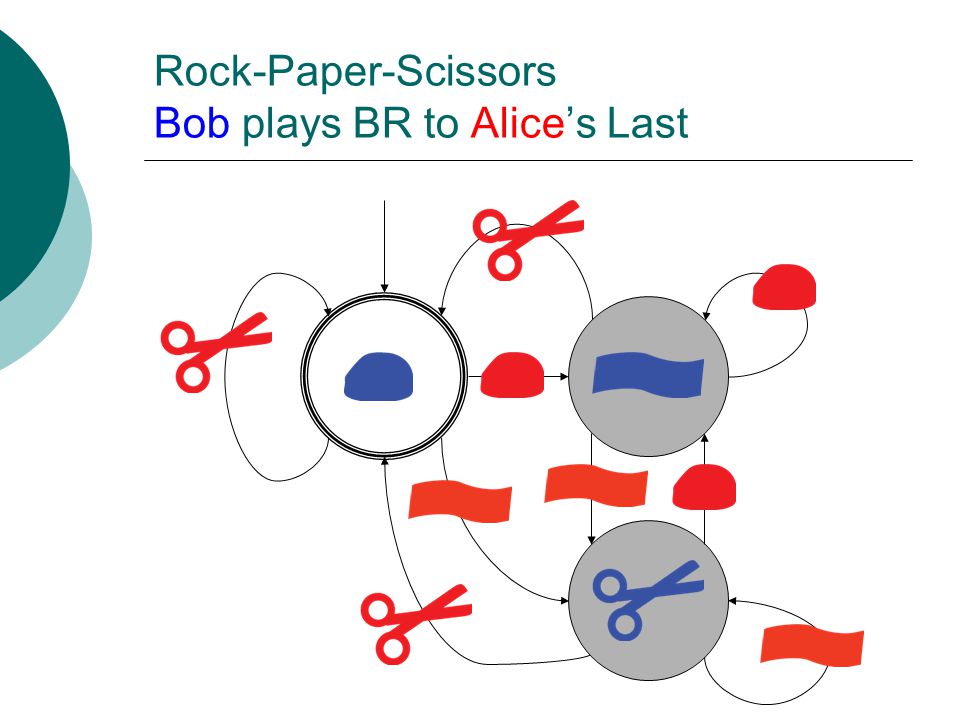
Rock-Paper-Scissors Bob plays BR to Alice’s Last

35
Utility of the Algorithm Define u t to be the utility of ALG at time t. Define u 0 ALG to be: u 0 ALG =(1/T) t=1 T u t Here: u 0 ALG =(1/5)(0+1+(-1)+1+0)=1/5 u 0 ALG =1/5
 t=1 T u t Here: u 0 ALG =(1/5)(0+1+(-1)+1+0)=1/5 u 0 ALG =1/5.")
36
Rock-Paper-Scissors Visit Counts for Bob’s Internal States 3 Visits 1 Visit u 0 ALG =1/5

37
Rock-Paper-Scissors Frequencies 3/5 Visits 1/5 Visits u 0 ALG =1/5

38
Rock-Paper-Scissors Dropped according to Frequencies 3/5 Visits 1/5 Visits 0 2/5 -2/5 u 0 ALG =1/5

39
Traditional Regret Consider B to be the empirical frequency states were visited. Define u 0 ALG to be the average utility of the algorithm. Traditional regret of ALG is: R= V * ( B )-u 0 ALG R=(2/5)-(1/5) u 0 ALG =1/5 0 2/5 -2/5
-u 0 ALG R=(2/5)-(1/5) u 0 ALG =1/5 0 2/5 -2/5.")
40
Traditional Regret Goal: regret approach zero a.s. Exists an algorithm that will do this for all opponents.

41
What Algorithm? Gradient Ascent With Euclidean Projection (Zinkevich, 2003): (when p i strictly positive)
: (when p i strictly positive).")
42
What Algorithm? Exponential Weighted Experts (Littlestone + Warmuth, 1994): And a close relative:
: And a close relative:.")
43
What Algorithm? Regret Matching:

44
What Algorithm? Lots of them!

45
Extensions to Traditional Regret (Foster and Vohra, 1997) Into the past… Have a short history Optimal against BR to Alice’s Last.
 Into the past… Have a short history Optimal against BR to Alice’s Last.")
46
Extensions to Traditional Regret (Auer et al) Only see u t, not u i,t : Use an unbiased estimator of u i,t :
 Only see u t, not u i,t : Use an unbiased estimator of u i,t :")
47
Outline Introduction Repeated Prisoners’ Dilemma Tit-for-Tat Grim Trigger Traditional Regret Response Regret Conclusion

48
This Talk Do you want to? Even then, is it possible?

49
Traditional Regret: Prisoner’s Dilemma Bob cooperates Bob defects Alice defects Alice defects Alice cooperates Alice cooperates C DCDC D D D D D D D D

50
Traditional Regret: Prisoner’s Dilemma Bob cooperates (0.2) Bob defects (0.8) Alice cooperates Alice defects Alice defects Alice cooperates Alice defects:-4 Alice cooperates:-5
 Bob defects (0.8) Alice cooperates Alice defects Alice defects Alice cooperates Alice defects:-4 Alice cooperates:-5")
51
Traditional Regret Bob Cooperates Bob Defects Alice Cooperates -1,-1-6,0 Alice Defects 0,-6-5,-5

52
The New Dilemma Traditional regret forces greedy, short-sighted behavior. A new concept is needed.

53
A New Measurement of Regret Bob cooperates (0.2) Bob defects (0.8) Alice defects Alice defects Alice cooperates Alice cooperates V*(B)V*(B) instead of V 0 * ( B )
 Bob defects (0.8) Alice defects Alice defects Alice cooperates Alice cooperates V*(B)V*(B) instead of V 0 * ( B )")
54
Response Regret Consider B to be the empirical distribution over states visited. Define u 0 ALG to be the average utility of the algorithm. Traditional regret is: R 0 = V * ( B )-u 0 ALG Response regret is: R = V * ( B )-?
-u 0 ALG Response regret is: R = V * ( B )- .")
55
Averaged Discounted Utility Utility of algorithm at time t’= u t’ Discounted utility from time t= t’=t 1 u t’ t’-t Averaged discounted utility from 1 to T u ALG =(1/T) t=1 T t’=t 1 u t’ t’-t Dropped in at random but play optimally: V*(B)V*(B) Response Regret R = V * ( B )-u ALG
 t=1 T t’=t 1 u t’ t’-t Dropped in at random but play optimally: V*(B)V*(B) Response Regret R = V * ( B )-u ALG")
56
Response Regret Consider B to be the empirical distribution over states visited. Traditional regret is: R 0 = V * ( B )-u 0 ALG Response regret is: R = V * ( B )-u ALG
-u 0 ALG Response regret is: R = V * ( B )-u ALG.")
57
Comparing Regret Measures: when Bob Plays Tit-for-Tat Bob cooperates (0.2) Bob defects (0.8) Alice defects Alice defects Alice cooperates Alice cooperates CCDCDDDDDDDDDDDDDDDDCCDCDDDDDDDDDDDDDDDDDDDDDDD R 0 =1/10 (defect) R 1/5 =0 (any policy) R 2/3 =(203/30) ¼ 6.76 (always cooperate)
 Bob defects (0.8) Alice defects Alice defects Alice cooperates Alice cooperates CCDCDDDDDDDDDDDDDDDDCCDCDDDDDDDDDDDDDDDDDDDDDDD R 0 =1/10 (defect) R 1/5 =0 (any policy) R 2/3 =(203/30) ¼ 6.76 (always cooperate)")
58
Comparing Regret Measures: when Bob Plays Tit-for-Tat Bob cooperates (1.0) Bob defects (0.0) Alice defects Alice defects Alice cooperates Alice cooperates CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC R 0 =1 (defect) R 1/5 =0 (any policy) R 2/3 =0 (always cooperate/tit-for-tat/grim trigger)
 Bob defects (0.0) Alice defects Alice defects Alice cooperates Alice cooperates CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC R 0 =1 (defect) R 1/5 =0 (any policy) R 2/3 =0 (always cooperate/tit-for-tat/grim trigger)")
59
Comparing Regret Measures: when Bob Plays Grim Trigger Bob cooperates (0.2) Bob defects (0.8) Alice defects Alice * Alice cooperates CCDCDDDDDDDDDDDDDDDDCCDCDDDDDDDDDDDDDDDDDDDDDDD R 0 =1/10 (defect) R 1/5 =0 (grim trigger/tit-for-tat/always defect) R 2/3 =11/30 (grim trigger/tit-for-tat)
 Bob defects (0.8) Alice defects Alice * Alice cooperates CCDCDDDDDDDDDDDDDDDDCCDCDDDDDDDDDDDDDDDDDDDDDDD R 0 =1/10 (defect) R 1/5 =0 (grim trigger/tit-for-tat/always defect) R 2/3 =11/30 (grim trigger/tit-for-tat)")
60
Comparing Regret Measures: when Bob Plays Grim Trigger Bob cooperates (1.0) Bob defects (0.0) Alice defects Alice * Alice cooperates CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC R 0 =1 (defect) R 1/5 =0 (always cooperate/always defect/tit-for-tat/grim trigger) R 2/3 =0 (always cooperate/tit-for-tat/grim trigger)
 Bob defects (0.0) Alice defects Alice * Alice cooperates CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC R 0 =1 (defect) R 1/5 =0 (always cooperate/always defect/tit-for-tat/grim trigger) R 2/3 =0 (always cooperate/tit-for-tat/grim trigger)")
61
Regrets vs Tit-for-Tat vs Grim Trigger CDDDDDDDDD CCDDDDDDDD R 0 =0.1 R 1/5 =0 R 2/3 ¼ 6.76 R 0 =0.1 R 1/5 =0 R 2/3 ¼ 0.36 CCCCCCCCCCC R 0 =1 R 1/5 =0 R 2/3 =0 R 0 =1 R 1/5 =0 R 2/3 =0

62
What it Measures: constant opportunities high response regret a few drastic mistakes low response regret convergence implies Nash Equilibrium of the repeated game

63
Philosophy Response regret cannot be known without knowing the opponent. Response regret can be estimated while playing the opponent, so that the estimate in the limit will be exact a.s.

64
Determining Utility of a Policy in a State If I want to know the discounted utility of using a policy P from the third state visited… Use the policy P from the third time step ad infinitum, and take the discounted reward. S1S1 S2S2 S3S3 S4S4 S5S5

65
Determining Utility of a Policy in a State in Finite Time Start using the policy P from the third time step: with probability , continue using P. Take the total reward over time steps P was used. In EXPECTATION, the same as before. S1S1 S2S2 S3S3 S4S4 S5S5

66
Determining Utility of a Policy in a State in Finite Time Without ALWAYS Using It With a probability, start using the policy P from the third time step: with probability , continue using P. Take the total reward over time steps P was used and multiply it by 1/. In EXPECTATION, the same as before. Can estimate any finite number of policies at the same time this way. S1S1 S2S2 S3S3 S4S4 S5S5

67
Traditional Regret Goal: regret approach zero a.s. Exists an algorithm for all opponents.

68
Response Regret Goal: regret approach zero a.s. Exists an algorithm for all opponents.

69
A Hard Environment: The Combination Lock Problem BdBd BdBd Ad Ac BdBd BdBd BcBc Ad A* Ad Ac

70
SPEED! Response regret takes time to minimize (combination lock problem). Current work: restricting the adversary’s choice of policies. In particular, if the number of policies is N, then the regret is linear in N and polynomial in 1/(1-).
..")
71
Related Work Other work De Farias and Meggido 2004 Browning, Bowling, and Veloso 2004 Bowling and McCracken 2005 Episodic solutions: similar problems to Finitely Repeated Prisoner’s Dilemma.

72
What is in a Name? Why not Consequence Regret?

73
Questions? Thanks to: Avrim Blum (CMU) Michael Bowling (U Alberta) Amy Greenwald (Brown) Michael Littman (Rutgers) Rich Sutton (U Alberta)
 Michael Bowling (U Alberta) Amy Greenwald (Brown) Michael Littman (Rutgers) Rich Sutton (U Alberta).")
74
Always Cooperate Bob cooperates Alice * CCDCDDDDDDDDDDDDDDDDCCDCDDDDDDDDDDDDDDDDDDDDDDD R 0 =1/10 R 1/5 =1/10 R 2/3 =1/10

75
Practice Using these estimation techniques, it is possible to minimize response regret (make it approach zero almost surely in the limit in an ARBITRARY environment). Similar to the Folk Theorems, it is also possible to converge to the socially optimal behavior if is close enough to 1.(???)
.")
76
Traditional Regret: Prisoner’s Dilemma Bob cooperates Bob defects Alice defects Alice defects Alice cooperates Alice cooperates

77
Possible Outcomes Alice cooperates, Bob cooperates: Alice: 1 year Bob: 1 year Alice defects, Bob cooperates: Alice: 0 years Bob: 6 years Alice cooperates, Bob defects: Alice: 6 years Bob: 0 years Alice defects, Bob defects: Alice: 5 years Bob: 5 years

78
Bimatrix Game Bob Cooperates Bob Defects Alice Cooperates Alice: 1 year Bob: 1 year Alice: 6 years Bob: 0 years Alice Defects Alice: 0 years Bob: 6 years Alice: 5 years Bob: 5 years

79
Repeated Bimatrix Game The same one-shot game is played repeatedly. Either average reward or discounted reward is considered.

80
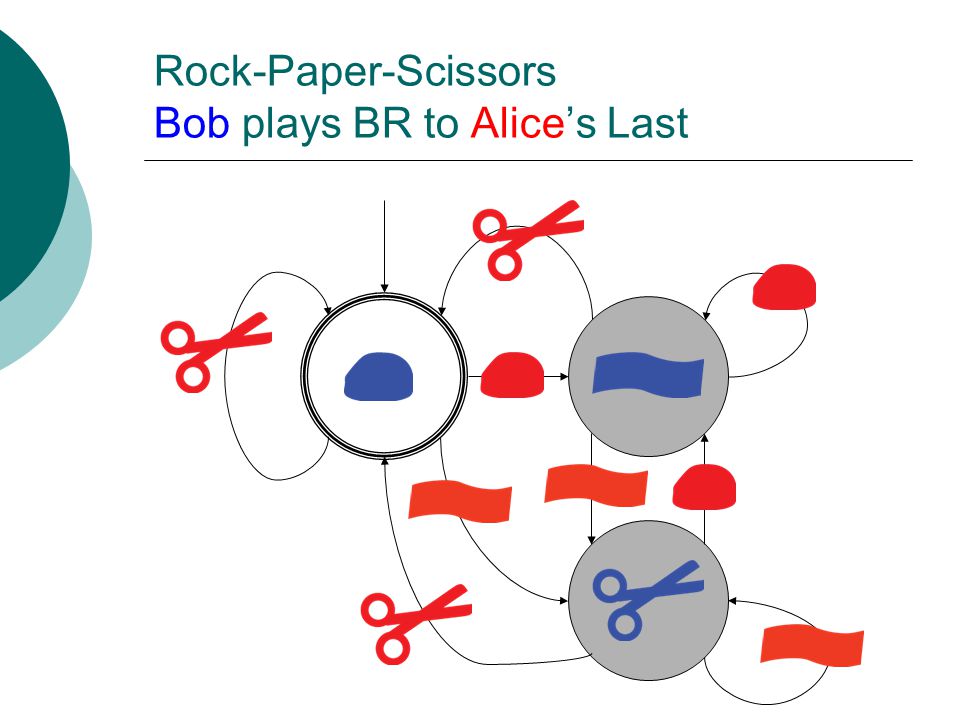
Rock-Paper-Scissors Bob plays BR to Alice’s Last

85
One Slide Summary Problem: Prisoner’s Dilemma Solution: Infinitely Repeated Prisoner’s Dilemma Same Problem: Traditional Regret Solution: Response Regret

86
Formalism for FSMs (S,A, ,O,u,T) States S Finite actions A Finite observations Observation function O:S ! Utility function u:S £ A ! R (or u:S £ O ! R) Transition function T:S £ A ! S V * (s)=max a 2 A [u(s,a)+V * (T(s,a))]
 Transition function T:S £ A . S V * (s)=max a 2 A [u(s,a)+V * (T(s,a))].")
87
Beliefs Suppose S is a set of states. T(s,a) state O(s) observation u(s,a) value V * (s)=max a 2 A [u(s,a)+ V * (T(s,a))] Suppose B is a distribution over states. T( B,a,o) belief O( B,o) probability u( B,a) expected value V * ( B )=max a 2 A [u( B,a)+ o 2 O( B,o)V * (T( B,a,o))]
 state O(s) observation u(s,a) value V * (s)=max a 2 A [u(s,a)+ V * (T(s,a))] Suppose B is a distribution over states. T( B,a,o) belief O( B,o) probability u( B,a) expected value V * ( B )=max a 2 A [u( B,a)+ o 2 O( B,o)V * (T( B,a,o))].")
Similar presentations






: Every finite game (finite number of players, finite number of pure strategies) has at least one mixed-strategy Nash.>")




 - Russian Proverb (Ronald Reagan) Topic 5 Repeated Games.>")








 (deals with outcomes) Fundamental.>")

