Download presentation
Presentation is loading. Please wait.

1
CMPE 478, Parallel Processing
Advanced Hardware Parallel/Distributed Processing High Performance Computing Top 500 list Grid computing picture of ASCI WHITE, the most powerful computer in the world (2001)
")
2
Von Neumann Architecture
CPU RAM Device Device BUS sequential computer

3
History of Computer Architecture
4 Generations (identified by logic technology) Tubes Transistors Integrated Circuits VLSI (very large scale integration)
 Tubes. Transistors. Integrated Circuits. VLSI (very large scale integration)")
4
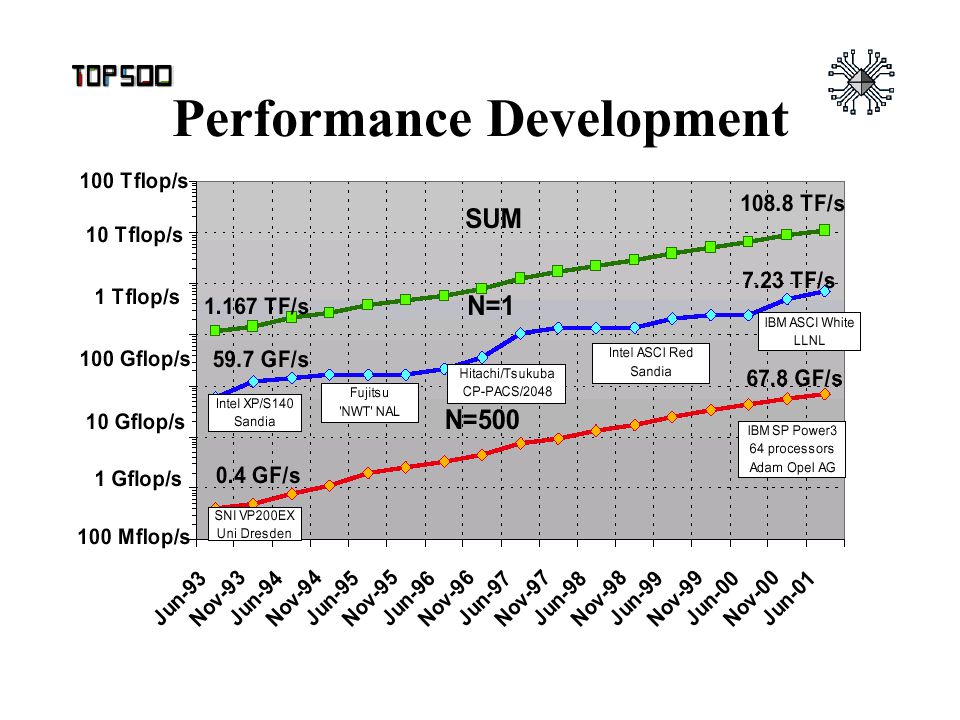
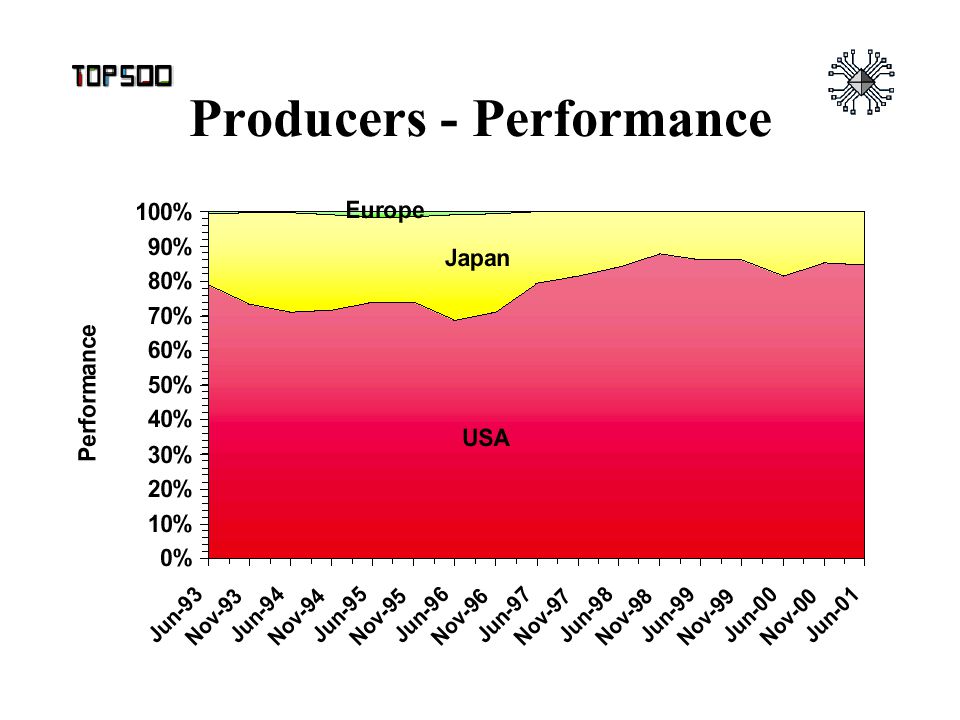
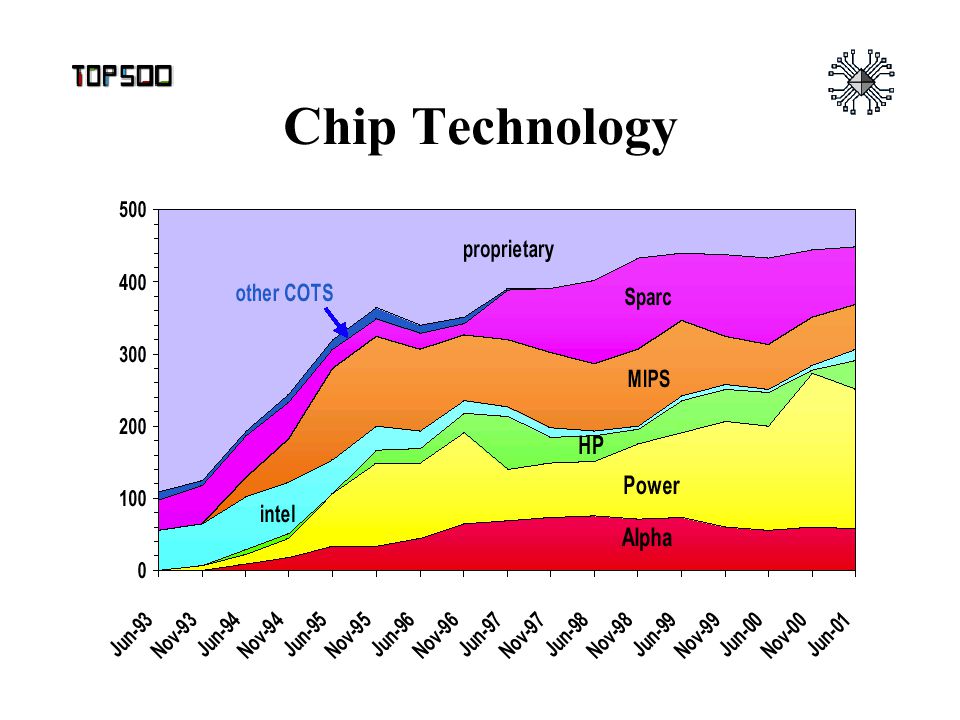
PERFORMANCE TRENDS

5
PERFORMANCE TRENDS Traditional mainframe/supercomputer performance 25% increase per year But … microprocessor performance 50% increase per year since mid 80’s.

6
Moore’s Law Moore is co-founder of Intel. 60 % increase per year
“Transistor density doubles every 18 months” Moore is co-founder of Intel. 60 % increase per year Exponential growth PC costs decline. PCs are building bricks of all future systems.

7
VLSI Generation

8
Bit Level Parallelism (upto mid 80’s)
4 bit microprocessors replaced by 8 bit, 16 bit, 32 bit etc. doubling the width of the datapath reduces the number of cycles required to perform a full 32-bit operation mid 80’s reap benefits of this kind of parallelism (full 32-bit word operations combined with the use of caches)
")
9
Instruction Level Parallelism (mid 80’s to mid 90’s)
Basic steps in instruction processing (instruction decode, integer arithmetic, address calculations, could be performed in a single cycle) Pipelined instruction processing Reduced instruction set (RISC) Superscalar execution Branch prediction
 Pipelined instruction processing. Reduced instruction set (RISC) Superscalar execution. Branch prediction.")
10
Thread/Process Level Parallelism (mid 90’s to present)
On average control transfers occur roughly once in five instructions, so exploiting instruction level parallelism at a larger scale is not possible Use multiple independent “threads” or processes Concurrently running threads, processes

11
Sequential vs Parallel Processing
physical limits reached easy to program expensive supercomputers “raw” power unlimited more memory, multiple cache made up of COTS, so cheap difficult to program

12
Amdahl’s Law The serial percentage of a program is fixed. So speed-up obtained by employing parallel processing is bounded. Lead to pessimism in in the parallel processing community and prevented development of parallel machines for a long time. 1 Speedup = 1-s s + P In the limit: Spedup = 1/s s

13
Gustafson’s Law Serial percentage is dependent on the number of processors/input. Broke/disproved Amdahl’s law. Demonstrated achieving more than 1000 fold speedup using 1024 processors. Justified parallel processing

14
Hillis’ Thesis ‘85 Piece of silicon Sequential computer
Parallel computer proposed “The Connection Machine” with massive number of processors each with small memory operating in SIMD mode. CM-1, CM-2 machines from Thinking Machines Corporation (TMC)were examples of this architecture with 32K-128K processors. Unfortunately, TMC went out of business.
were examples of this architecture with 32K-128K processors. Unfortunately, TMC went out of business.")
15
Grand Challenge Applications
Important scientific & engineering problems identified by U.S. High Performance Computing & Communications Program (’92)
")
16
Flynn’s Taxonomy classifies computer architectures according to:
Number of instruction streams it can process at a time Number of data elements on which it can operate simultaneously Data Streams Single Multiple Single SISD SIMD Instruction Streams MISD MIMD Multiple

17
SPMD Model (Single Program Multiple Data)
Each processor executes the same program asynchronously Synchronization takes place only when processors need to exchange data SPMD is extension of SIMD (relax synchronized instruction execution) SPMD is restriction of MIMD (use only one source/object)
 SPMD is restriction of MIMD (use only one source/object)")
18
Parallel Processing Terminology
Embarassingly Parallel: applications which are trivial to parallelize large amounts of independent computation Little communication Data Parallelism: model of parallel computing in which a single operation can be applied to all data elements simultaneously amenable to SIMD or SPMD style of computation Control Parallelism: many different operations may be executed concurrently require MIMD/SPMD style of computation

19
Parallel Processing Terminology
Scalability: If the size of problem is increased, number of processors that can be effectively used can be increased (i.e. there is no limit on parallelism). Cost of scalable algorithm grows slowly as input size and the number of processors are increased. Data parallel algorithms are more scalable than control parallel algorithms Granularity: fine grain machines: employ massive number of weak processors each with small memory coarse grain machines: smaller number of powerful processors each with large amounts of memory
. Cost of scalable algorithm grows slowly as input size and the number of processors are increased. Data parallel algorithms are more scalable than control parallel algorithms. Granularity: fine grain machines: employ massive number of weak processors each with small memory. coarse grain machines: smaller number of powerful processors each with large amounts of memory.")
20
Shared Memory Machines
Shared Address Space process (thread) Memory is globally shared, therefore processes (threads) see single address space Coordination of accesses to locations done by use of locks provided by thread libraries Example Machines: Sequent, Alliant, SUN Ultra, Dual/Quad Board Pentium PC Example Thread Libraries: POSIX threads, Linux threads.
 Memory is globally shared, therefore processes (threads) see single address. space. Coordination of accesses to locations done by use of locks provided by. thread libraries. Example Machines: Sequent, Alliant, SUN Ultra, Dual/Quad Board Pentium PC. Example Thread Libraries: POSIX threads, Linux threads.")
21
Shared Memory Machines
can be classified as: UMA: uniform memory access NUMA: nonuniform memory access based on the amount of time a processor takes to access local and global memory. P M .. P M .. Inter- connection network Inter- connection network M .. P .. Inter- connection network/ or BUS M .. (a) (b) (c)
 (b) (c)")
22
Distributed Memory Machines
Network process M Each processor has its own local memory (not directly accessible by others) Processors communicate by passing messages to each other Example Machines: IBM SP2, Intel Paragon, COWs (cluster of workstations) Example Message Passing Libraries: PVM, MPI
 Processors communicate by passing messages to each other. Example Machines: IBM SP2, Intel Paragon, COWs (cluster of workstations) Example Message Passing Libraries: PVM, MPI.")
23
Beowulf Clusters Use COTS, ordinary PCs and networking equipment
Has the best price/performance ratio PC cluster

46
The Future Most Powerful Computer ? (now operational and #1)
")
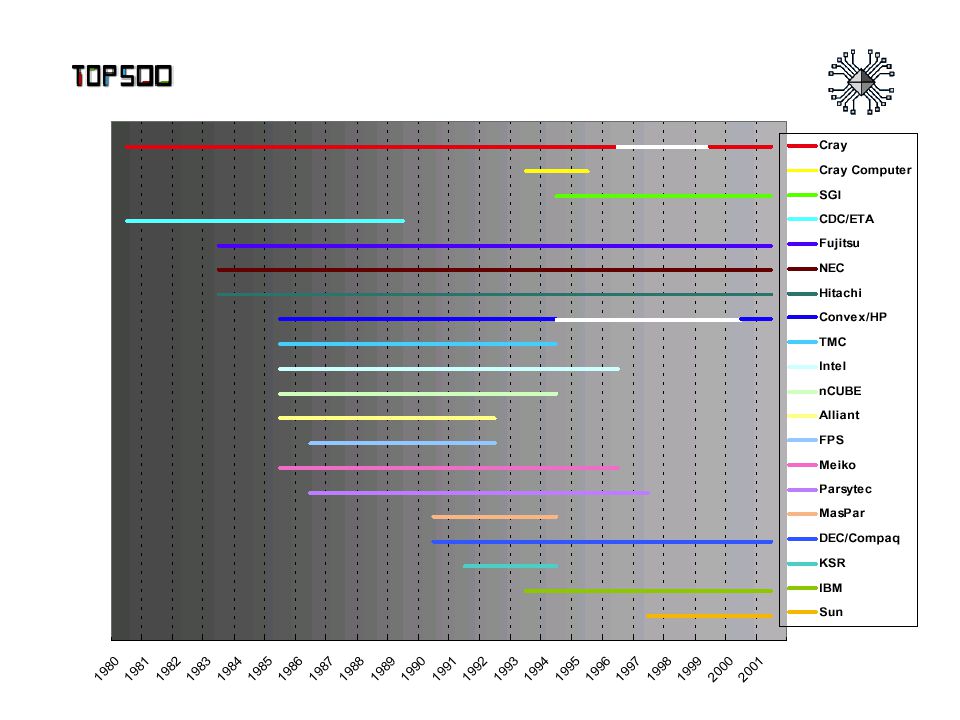
47
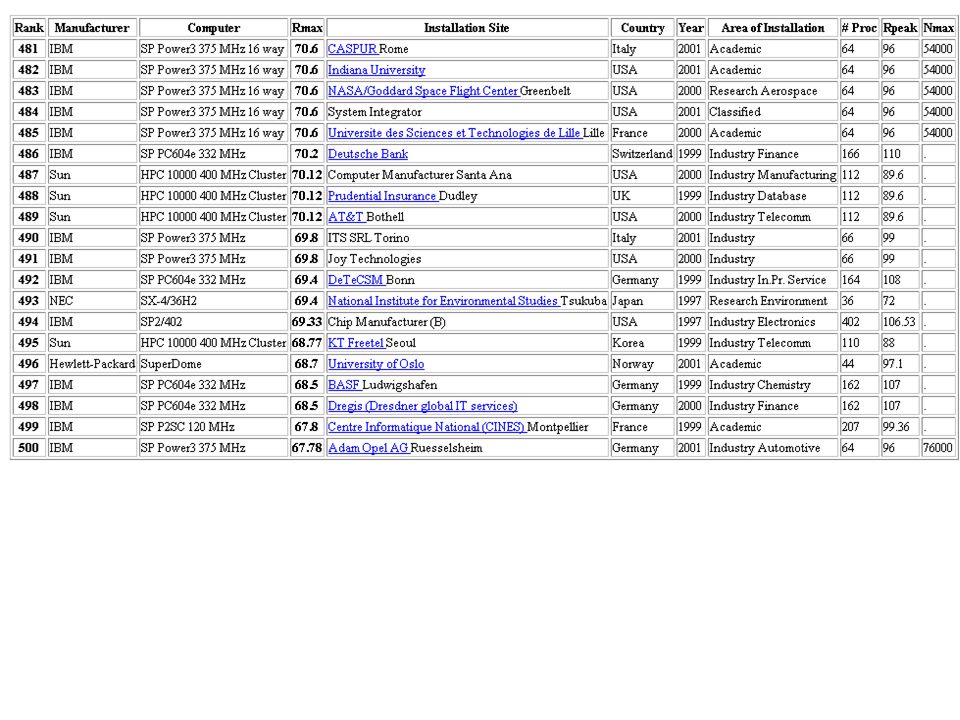
TOP 500 LIST: June 2002

48
Grid Computing provide access to computing power and various resources just like accessing electrical power from electrical grid Allows coupling of geographically distributed resources Provide inexpensive access to resources irrespective of their physical location or access point Internet & dedicated networks can be used to interconnect distributed computational resources and present them as a single unified resource Resources: supercomputers, clusters, storage systems, data resources, special devices

49
Grid Computing the GRID is, in effect, a set of software tools, which when combined with hardware, would let users tap processing power off the Internet as easily as the electrical power can be drawn from the electricty grid. Examples of Grid projects: - : search for extraterrestial intelligence - Entropia : company to broker processing power of idle computers, about 30,000 volunteer computers and total processing power 1 Tflop. : sifts astronomical data for pulsars - : protein folding - : population dynamics

50
Seti@home Project Screen-saver program
Sifts through signals recorded by the giant Arecibo radio telescope in Puerto Rico 3 million people downloaded screen saver and run it. Program periodically prompts its host to retrieve a new chunk of data from the Internet and sends latest processed results back to SETI. Equivalent of more than 600,000 years of PC processing time has already clocked up.

51
More Grid Projects GriPhyN: grid developed by consortium of American labs for physics projects Earth System Grid: make huge climate simulations spanning hundreds of years. Earthquake Engineering Simulation Grid: Particle Physics Data Grid: Information Power Grid: supported by NASA for massive engineering calculations DataGrid : European, coordinated by CERN. Aim is to develop middleware for research projects in biological sciences, earth observation and high energy physics.

52
Gordon Bell & Jim Gray on “What’s next in High Performance Computing”
Beowulf ’s economics and sociology are poised to kill off the other architectural lines Computational Grid can federate systems into supercomputers far beyond the power of any current computing center The centers will become super-data and super-application centers Clusters (currently) perform poorly on applications that require large shared memory
 perform poorly on applications that require large shared memory.")
53
Gordon Bell & Jim Gray on “What’s next in High Performance Computing”
Now individuals and laboratories can assemble and incrementally grow any-size super-computer anywhere in the world. By 2010, the cluster is likely to be the principal computing structure. does not run Linpack, so does not qualify in the top500 list. But avarages 13 Tflops making it more powerful than the top 3 of top500 machines combined. GRID and P2P computing using the Internet is likely to remain the world’s most powerful supercomputer.

54
Gordon Bell & Jim Gray on “What’s next in High Performance Computing”
Concerned that traditional supercomputer architecture is dead and a supercomputer mono-culture is being born. Recommend increased investment in peta-scale distributed databases. By 2010, the cluster is likely to be the principal computing structure. Research programs that stimulate cluster understanding and training are a good investment for laboratories that depend on highest performance machines.

Similar presentations



























 Single Instruction stream, Single Data stream (SISD) –Conventional uniprocessor.>")





What is parallel processing (2)Classification of parallel.>")


