Download presentation
Presentation is loading. Please wait.

1
Supercomputing Challenges at the National Center for Atmospheric Research Dr. Richard Loft Computational Science Section Scientific Computing Division National Center for Atmospheric Research Boulder, CO USA

2
Talk Outline Supercomputing Trends and Constraints Observed NCAR Cluster Performance (Aggregate) Microprocessor efficiency: what is possible? Microprocessor efficiency: recent efforts to improve CAM2 performance. Some RISC/Vector Cluster Comparisons Conclusions

3
The Demand: High Cost of Science Goals Climate scientists project a need for 150x more computing power of the next 5 years. T42->T85. Doubling horizontal resolution increases computational cost eightfold. Many additional constituents will be advected. New physics: computational cost of CAM/CCM, holding resolution constant, has increased 4x since 1996. More coming… Future: introducing super-parameterizations of moist processes would increase physics costs dramatically.

4
Existing Infrastructure Limits at NCAR Cooling Capacity –450 tons (1.58 megawatts) –Most limiting –One P690 node ~ 7.9 KW ~ 2.5 tons –Balance cooling with power Power ~ 1.2 MW without modifications –Second most limiting –Currently NCAR computer room draws 602 KW –About 400 kw from IBM clusters Space ~ 14,000 sq.ft. –P690 ~ 196 W/sq. ft. –Least limiting based on current trends

5
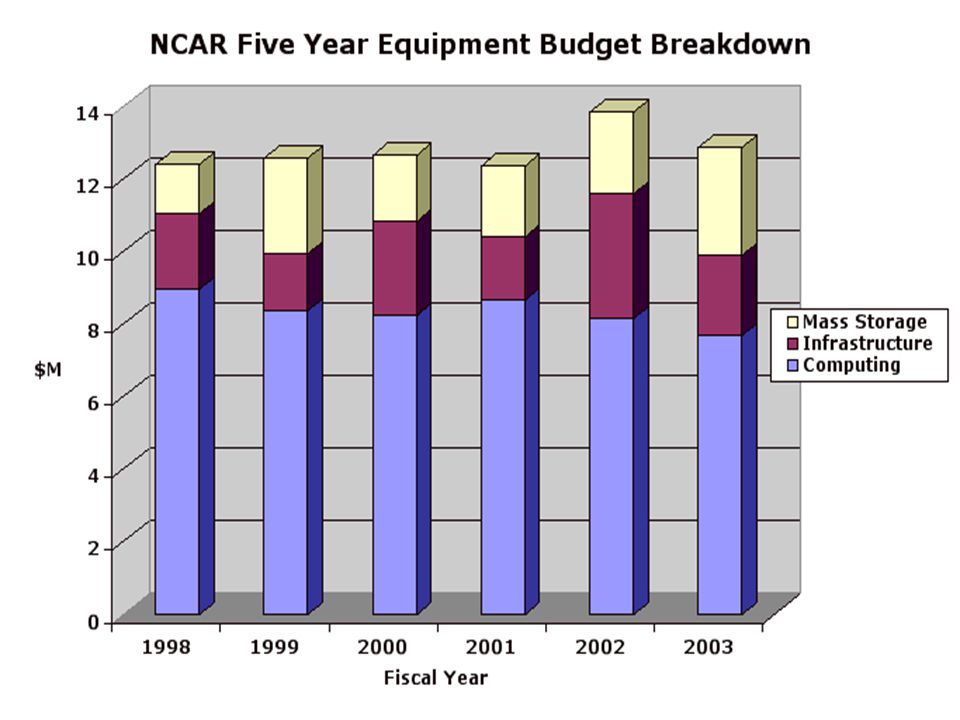
Mass Storage Growth 1.3 Pbytes total Adding ~3 Tbytes/day 5 year doubling times - –Unique files: 2.1 years –File size: 10.4 years –Media performance (GB/$) 1.9 years Alarming trends –MSS growth rate doubling time has accelerated over past year. Now 18 months. –MSS costs are increasing…

9
Observed Cluster Performance (Aggregate)
")
10
IBM Clusters at NCAR Bluesky: 1024 IBM 1.3 GHz Power-4 cluster –32 P690/32 compute servers –736 in 92, 8 way “nodes” (bluesky8) –288 in 9, 32 way “nodes” (bluesky32) –Peak: 5.234 TFlops –Dual “Colony” interconnect Blackforest: IBM 375 MHz Power-3 cluster –283 “winterhawk” 4-way SMP’s –Peak: 1.698 TFlops –TBMX interconnect
 –288 in 9, 32 way nodes (bluesky32) –Peak: TFlops –Dual Colony interconnect Blackforest: IBM 375 MHz Power-3 cluster –283 winterhawk 4-way SMP’s –Peak: TFlops –TBMX interconnect")
11
Observed IBM Cluster Efficiencies SystemApplication efficiency (% of peak) bluesk8 4.1% bluesk32 4.5% blackforest 5.7% Newer systems are less efficient. Larger nodes are more efficient. Max sustained performance: 320.3 GFlops

12
Why is workload efficiency low? Computational character of workload average: –L3 cache miss rate 31% –computational intensity is 0.8 Applications are memory bandwidth limited. –Simple BW model predicts 5.5% for bluesky32. A good metric of efficiency is Flop/cycle. –Factors out dual FPU’s. –Bluesky32: 0.18 Flop/cycle –Blackforest: 0.23 Flop/cycle

13
RISC Cluster Network Comparison IBM Power-4 cluster with dual “Colony” network. IBM Power-3 cluster with single TBMX network. Compaq Alpha cluster with Quadrix network. Bisection Bandwidth –Important for global communications –XPAIR benchmark initiates all to all communication. –Dual Colony P690 local:global BW ratio 50:1 Global Reductions –For P processors these should scale as log(P). –Actually scales linearly.
. –Actually scales linearly..")
14
Cluster Network Performance

16
Microprocessor efficiency: What is possible?

17
Example: 3-D FFT Performance Hand tuned multithreaded, 3-D FFT (STK) Three 1-D FFT on each axis with transpositions FFTs are memory bandwidth intensive –Both loads and Flop’s scale like N*log(N) The FFT is not multiply-add dominated The FFT butterfly is a non local, strided calculation. Gets more non local as size of FFT increases 1024^3 Transforms on P690 (IBM Power-4)
.")
21
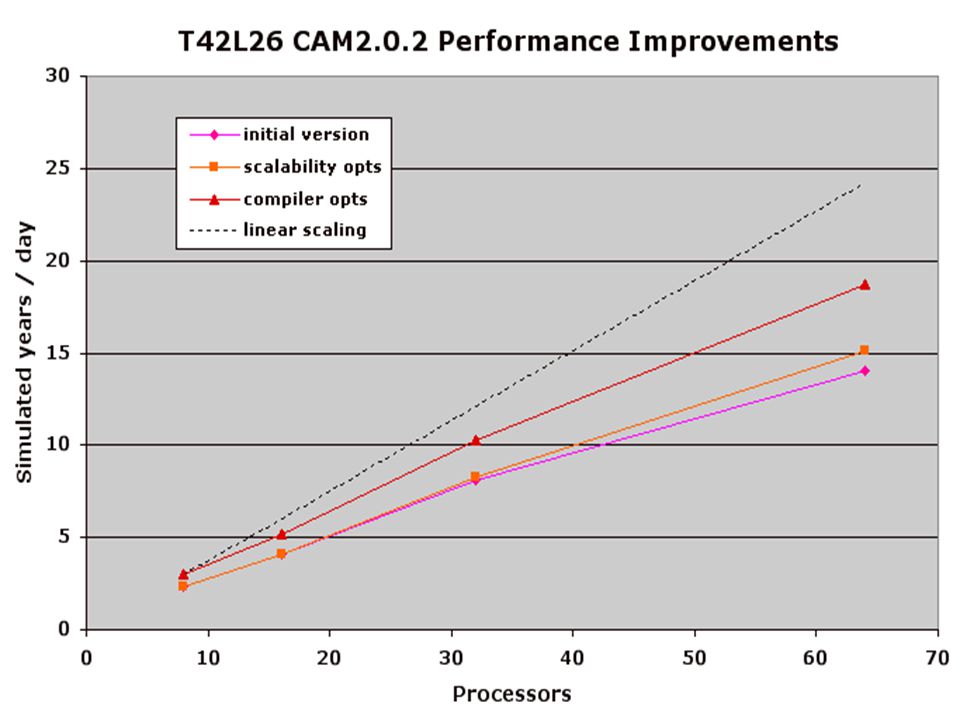
Microprocessor efficiency: Recent efforts to improve CAM2 performance…

22
CCM Benchmark Performance on Existing Multiprocessor Clusters

26
Some RISC/Vector Cluster Comparisons…

27
Processor Comparison Power 4 (2 cores) Pentiu m 4 Itanium IISX-6 Process.18 µ Cu/7l.13 µ Cu 0.18 µ Al/ 6l 0.15 µ Cu/ 9l Mhz130028001000500/1000 Peak GF5.22.8/5.64.08.0 Die area400 mm 2 145 mm 2 421 mm 2 420 mm 2 Trans.170 M 55 M221 M57 M On-Chip cache 1.77MB512 KB3.3 MB On-Chip bandwidth 41 GB/s (per core) 89.6 GB/s 64 GB/s Memory Bandwidth 5.8 GB/s4.3 GB/s 6.4 GB/s32 GB/s
 Pentiu m 4 Itanium IISX-6 Process.18 µ Cu/7l.13 µ Cu 0.18 µ Al/ 6l 0.15 µ Cu/ 9l Mhz /1000 Peak GF5.22.8/ Die area400 mm mm mm mm 2 Trans.170 M 55 M221 M57 M On-Chip cache 1.77MB512 KB3.3 MB On-Chip bandwidth 41 GB/s (per core) 89.6 GB/s 64 GB/s Memory Bandwidth 5.8 GB/s4.3 GB/s 6.4 GB/s32 GB/s")
28
IBM P690 Cluster 5.3 TFlops peak 1024 processors (32, 32 way P690 nodes) 5.2 Gflops/processor Observed 4.1-4.5% of peak on NCAR codes Max sustained on workload: 213.5 GFlops Est. Peak Price Performance: $2.6/MFlops Sustained Price Performance: $59/MFlops Sustained Power Performance: 0.7 Gflops/KW

29
Earth Simulator 40.96 Tflops peak 5120 Processors (640, 8 processor GS40 nodes) 8 Gflops/processor Estimate 30% of peak on NCAR codes Est. Max sustained on workload: 12,200 GFlops Est. Peak Price Performance: $8.5/MFlops Est. Sustained Price Performance: $28/MFlops Est. Sustained Power Performance: 1.525 Gflops/KW

30
Power 4 die floor plan

31
Power 4 cache/CPU area comparison

32
Conclusions Infrastructure (power, cooling, space) are becoming critical constraints. NCAR IBM clusters sustain 4.1%-4.5% of peak. Workload is memory bandwidth limited. RISC cluster interconnects are not great. We’re making steady progress learning how to program around these limitations. At this point, vector systems appear to be about 2x more cost effective in both price and power performance.

33
Pentium-4 die floor plan

34
Pentium-4 cache/CPU comparison

35
Itanium II die floor plan

36
Itanium II CPU/cache area comparison

Similar presentations














>")











>")
