Download presentation
Presentation is loading. Please wait.

1
Peter Azzarello April 11, 2012 IB Toronto User Forum WebFOCUS Hyperstage Overview Summit 2012

2
WebFOCUS Higher Adoption & Reuse with Lower TCO Reporting Query & AnalysisDashboards InformationDelivery PerformanceManagement EnterpriseSearch Visualization & Mapping Data Updating PredictiveAnalytics MS Office & e-Publishing Extended BI Core BI Extensions to the WebFOCUS platform allow you to build more application types at a lower cost Business to Business Data Warehouse & ETL Master Data Management Data Profiling & Data Quality Business Activity Monitoring High Performance Data Store MobileApplications

3
Copyright 2007, Information Builders. Slide 3 The Business Challenge Big Data

4
Big Data and Machine Generated Data Data Storage Time Machine- Generated Data Human-Generated Data Today’s Top Data-Management Challenge

5
Source: KEEPING UP WITH EVER-EXPANDING ENTERPRISE DATA ( Joseph McKendrick Unisphere Research October 2010) How Performance Issues are Typically Addressed – by Pace of Data Growth When organizations have long running queries that limit the business, the response is often to spend much more time and money to resolve the problem IT Manager’s try to mitigate these response times …..
 How Performance Issues are Typically Addressed – by Pace of Data Growth When organizations have long running queries that limit the business, the response is often to spend much more time and money to resolve the problem IT Manager’s try to mitigate these response times …..")
6
Copyright 2007, Information Builders. Slide 6 Traditional Data Warehousing Labor intensive, heavy indexing, aggregations and partitioning Hardware intensive: massive storage; big servers Expensive and complex More Data, More Data Sources More Kinds of Output Needed by More Users, More Quickly Limited Resources and Budget 010101010101010101010101010 1 0101010101010101010101010 01010101010101010101 01 1 10 101 10 01 0 1 10 01 1 0 10 1 0 101 1 1 0 0 10 101 10 01 0 1 10 01 1 0 10 1 0 101 01 010 0 1 0 101 01 1 1010 0101 1 01 0 10 101 10 01 0 1 10 01 1 0 10 1 0 101 1 0 010101010101010101010 1010 01010101010101010101010101 01 1 101 10 0 101 1010 10 1 101 010 0 0 10 1 0 01 0 0 Real time data Multiple databases External Sources Data Warehousing Challenges

7
New Demands: Larger transaction volumes driven by the internet Impact of Cloud Computing More -> Faster -> Cheaper Data Warehousing Matures: Near real time updates Integration with master data management Data mining using discrete business transactions Provision of data for business critical applications Early Data Warehouse Characteristics: Integration of internal systems Monthly and weekly loads Heavy use of aggregates Data Warehousing Challenges

8
CUBES/OLAP Classic Approaches to deal with Large Data INDEXES

9
Limitations of Indexes Increased Space requirements Sum of Index Space requirements can exceed the source DB Index Management Increases Load times Building the index Predefines a fixed access path

10
Limitations of OLAP Cube technology has limited scalability Number of dimensions is limited Amount of data is limited Cube technology is difficult to update (add Dimension) Usually requires a complete rebuild Cube builds are typically slow New design results in a new cube
 Usually requires a complete rebuild Cube builds are typically slow New design results in a new cube")
11
Easy Migration to Hyperstage Most cubes will be fed from a relational source Common that relational source is a star schema The source star schema can be migrated directly to Hyperstage WebFOCUS metadata can be used to define hierarchies and drill paths to navigate the star schema

12
Copyright 2007, Information Builders. Slide 12 Pivoting Your Perspective: Columnar Technology ….

13
1. Impediments to business agility: Organizations often must wait for DBAs to create indexes or other tuning structures, thereby delaying access to data. In addition, indexes significantly slow data-loading operations and increase the size of the database, sometimes by a factor of 2x. 2. Loss of data and time fidelity: IT generally performs ETL operations in batch mode during non-business hours. Such transformations delay access to data and often result in mismatches between operational and analytic databases. 3. Limited ad hoc capability: Response times for ad hoc queries increase as the volume of data grows. Unanticipated queries (where DBAs have not tuned the database in advance) can result in unacceptable response times, and may even fail to complete. 4. Unnecessary expenditures: Attempts to improve performance using hardware acceleration and database tuning schemes raise the capital costs of equipment and the operational costs of database administration. Further, the added complexity of managing a large database diverts operational budgets away from more urgent IT projects. These Solutions Contribute to Operational Limitations The Limitation of Rows
 can result in unacceptable response times, and may even fail to complete. 4. Unnecessary expenditures: Attempts to improve performance using hardware acceleration and database tuning schemes raise the capital costs of equipment and the operational costs of database administration. Further, the added complexity of managing a large database diverts operational budgets away from more urgent IT projects. These Solutions Contribute to Operational Limitations The Limitation of Rows.")
14
Row-based databases are ubiquitous because so many of our most important business systems are transactional. Row-oriented databases are well suited for transactional environments, such as a call center where a customer’s entire record is required when their profile is retrieved and/or when fields are frequently updated. The Ubiquity of Rows … But - Disk I/O becomes a substantial limiting factor since a row-oriented design forces the database to retrieve all column data for any query. 30 columns 50 millions Rows The Limitation of Rows

15
Row Oriented ( 1, Smith, New York, 50000; 2, Jones, New York, 65000; 3, Fraser, Boston, 40000; 4, Fraser, Boston, 70000 ) Works well if all the columns are needed for every query. Efficient for transactional processing if all the data for the row is available Works well with aggregate results (sum, count, avg. ) Only columns that are relevant need to be touched Consistent performance with any database design Allows for very efficient compression Column Oriented ( 1, 2, 3, 4; Smith, Jones, Fraser, Fraser; New York, New York, Boston, Boston, 50000, 65000, 40000, 70000 ) Pivoting Your Perspective: Columnar Technology Employee Id 1 2 3 Name Smith Jones Fraser Location New York Boston Sales 50,000 65,000 40,000 4FraserBoston70,000
 Only columns that are relevant need to be touched Consistent performance with any database design Allows for very efficient compression Column Oriented ( 1, 2, 3, 4; Smith, Jones, Fraser, Fraser; New York, New York, Boston, Boston, 50000, 65000, 40000, ) Pivoting Your Perspective: Columnar Technology Employee Id Name Smith Jones Fraser Location New York Boston Sales 50,000 65,000 40,000 4FraserBoston70,000.")
16
Employee Id 1 2 3 Name Smith Jones Fraser Location New York Boston Sales 50,000 65,000 40,000 1SmithNew York50,000 2JonesNew York65,000 3FraserBoston40,000 1 2 3 SmithNew York50,000 JonesNew York65,000 Data stored in rows FraserBoston40,000 Data stored in columns Pivoting Your Perspective: Columnar Technology 4FraserBoston70,000 4FraserBoston70,0004FraserBoston70,000

17
Copyright 2007, Information Builders. Slide 17 Introducing WebFOCUS Hyperstage

18
The Hyperstage Mission Improve database performance for WebFOCUS applications with less hardware, no database tuning and easy migration.

19
The WebFOCUS Hyperstage high performance analytic data store is designed to handle business-driven queries on large volumes of data—without IT intervention. Easy to implement and manage, Hyperstage provides the answers to your business users need at a price you can afford. Introducing WebFOCUS Hyperstage …. What is it?

20
Hyperstage combines a columnar database with intelligence we call the Knowledge Grid to deliver fast query responses.. Introducing WebFOCUS Hyperstage …. How is it architected? Hyperstage Engine Knowledge Grid Compressor Bulk Loader Unmatched Administrative Simplicity No Indexes No data partitioning No Manual tuning

21
Self-managing: 90% less administrative effort Low-cost: More than 50% less than alternative solutions Scalable, high-performance: Up to 50 TB using a single industry standard server Fast queries: Ad-hoc queries are as fast as anticipated queries, so users have total flexibility Compression: Data compression of 10:1 to 40:1 that means a lot less storage is needed, it might mean you can get the entire database in memory! Introducing WebFOCUS Hyperstage …. What does this mean for Customers?

22
Create Information (Metadata) about the data, and, upon Load, automatically … Create Information (Metadata) about the data, and, upon Load, automatically … Uses the metadata when Processing a query to Eliminate / reduce need to access data Uses the metadata when Processing a query to Eliminate / reduce need to access data Architecture Benefits o Stores it in the Knowledge Grid (KG) o KG Is loaded into Memory o Less than 1% of compressed data Size o The less data that needs to be accessed, the faster the response o Sub-second responses when answered by KG o No Need to partition data, create/maintain indexes projections, or tune for performance o Ad hoc queries are as fast as static queries, so users have total flexibility Introducing WebFOCUS Hyperstage …. How does it work?

23
WebFOCUS Hyperstage Runtime Architecture Hypercopy Hyperstage Server Hyperstage Engine MySQL WebFOCUS Server WebFOCUS Pro Server Hyperstage Adapter Knowledge Grid Compressor Bulk Loader Hypercopy Hyperstage Server Hyperstage Engine WebFOCUS Server WebFOCUS Hyperstage Adapter Knowledge Grid Compressor Bulk Loader

24
Smarter Architecture No maintenance No query planning No partition schemes No DBA Data Packs – data stored in manageably sized, highly compressed data packs Knowledge Grid – statistics and metadata “describing” the super-compressed data Column Orientation WebFOCUS Hyperstage Engine Data compressed using algorithms tailored to data type How does it work?

25
Knowledge Grid – Consists of knowledge nodes that are generated as the data is loaded and dynamic knowledge nodes that are created during query execution. Not Manually Created - Unlike the indexes required for traditional databases, the knowledge grid is automatically generated does not require ongoing care and maintenance. Limited Overhead - Knowledge Grid provides a high level view of the entire content of the database with a minimal overhead of approximately 1% of the compressed data. (By contrast, classic indexes may represent as much as 200% of the size of the original data.) Data Organization and the Knowledge Grid ….
 Data Organization and the Knowledge Grid …..")
26
Copyright 2007, Information Builders. Slide 26 Summary

27
Copyright 2007, Information Builders. Slide 27 Business Intelligence – Meeting Requirements

28
WebFOCUS Hyperstage The Big Deal… No indexes No partitions No views No materialized aggregates Value proposition Low IT overhead Allows for autonomy from IT Ease of implementation Fast time to market Less Hardware Lower TCO No DBA Required!

29
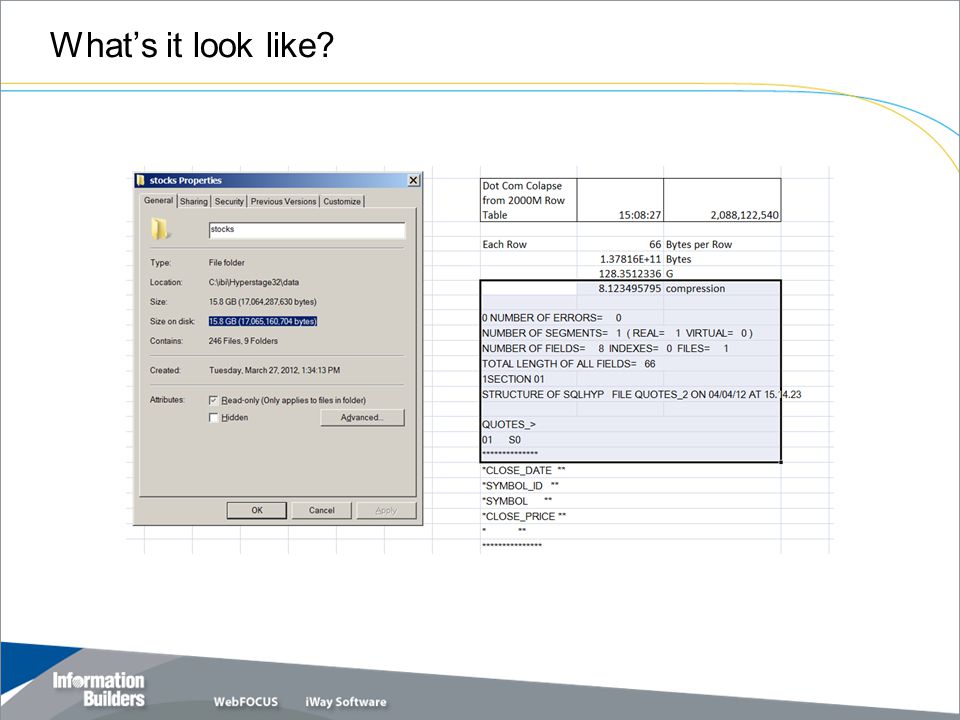
What’s it look like?

31
Pay no attention to that man behind the curtain. CREATE FILE baseapp/pa_inventory_ind_t DROP -RUN BULKLOAD baseapp/pa_inventory_ind_t FOR SQLINLD INV_CODE; TYPE; CATEGORY; NAME; MODEL; MEASURE1_INV; MEASURE2_INV; MEASURE3_INV; JOIN SYMBOLS.SYMBOLS.SYMBOL IN SYMBOLS TO MULTIPLE QUOTES_2B.QUOTES_2B.SYMBOL IN QUOTES_2B TAG J0 AS J0 END TABLE FILE SYMBOLS PRINT SYMBOL CLOSE_DATE CLOSE_PRICE VOLUME OPEN_PRICE WHERE ( SYMBOL EQ '&SYMBOL.( ).SYMBOL.' ) AND ( CLOSE_DATE GT '&START_DATE.( ).yyyy-mm-dd.' ) AND ( CLOSE_DATE LT '&END_DATE.( ).yyyy-mm-dd.' ); ON TABLE SET PAGE-NUM NOLEAD ON TABLE NOTOTAL ON TABLE PCHOLD FORMAT HTML ON TABLE SET HTMLCSS ON ON TABLE SET STYLE * INCLUDE = endeflt, $ ENDSTYLE END
.SYMBOL. ) AND ( CLOSE_DATE GT &START_DATE.( ).yyyy-mm-dd. ) AND ( CLOSE_DATE LT &END_DATE.( ).yyyy-mm-dd. ); ON TABLE SET PAGE-NUM NOLEAD ON TABLE NOTOTAL ON TABLE PCHOLD FORMAT HTML ON TABLE SET HTMLCSS ON ON TABLE SET STYLE * INCLUDE = endeflt, $ ENDSTYLE END.")
32
Example – Focus to Hyperstage Compression 243639 Rows

33
Q&A Copyright 2007, Information Builders. Slide 33

35
STAR SCHEMA CONSIDERATIONS

36
Leverage the Knowledge Grid Do constrain the fact table directly Do use sub-selects instead of joins Do use date based constraints as much as possible Do add additional columns to create useful knowledge nodes Everyone wants to be a Star Adding as many WHERE conditions as you can to your SQL increases the chance that knowledge grid statistics can be used to increase the performance of your queries.

Similar presentations








>")











