Download presentation
Presentation is loading. Please wait.

1
Likelihood Ratio Testing under Non-identifiability: Theory and Biomedical Applications Kung-Yee Liang and Chongzhi Di Department Biostatistics Johns Hopkins University July 9-10, 2009 National Taiwan University

2
Outline Challenges associated with likelihood inference Nuisance parameters absent under null hypothesis –Some biomedical examples –Statistical implications Class I: alternative representation of LR test statistic –Implications Class II –Asymptotic null distribution of LR test statistic –Some alternatives A genetic linkage example Discussion

3
Likelihood Inference Likelihood inference has been successful in a variety of scientific fields LOD score method for genetic linkage –BRCA1 for breast cancer Hall et al. (1990) Science Poisson regression for environmental health –Fine air particle (PM 10 ) for increased mortality in total cause and in cardiovascular and respiratory causes Samet et al. (2000) NEJM ML image reconstruction estimate for nuclear medicine –Diagnoses for myocardial infarction and cancers
 Science Poisson regression for environmental health –Fine air particle (PM 10 ) for increased mortality in total cause and in cardiovascular and respiratory causes Samet et al. (2000) NEJM ML image reconstruction estimate for nuclear medicine –Diagnoses for myocardial infarction and cancers.")
4
Challenges for Likelihood Inference In the absence of sufficient substantive knowledge, likelihood function maybe difficult to fully specify –Genetic linkage for complex traits –Genome-wide association with thousands of SNPs –Gene expression data for tumor cells There is computational issue as well for high- dimensional observations –High throughput data

5
Challenges for Likelihood Inference (con’t) Impacts of nuisance parameters –Inconsistency of MLE with many nuisance parameters (Neyman-Scott problem) –Different scientific conclusions with different nuisance parameter values –Ill-behaved likelihood function Asymptotic approximation not ready
 Impacts of nuisance parameters –Inconsistency of MLE with many nuisance parameters (Neyman-Scott problem) –Different scientific conclusions with different nuisance parameter values –Ill-behaved likelihood function Asymptotic approximation not ready")
8
Challenges for Likelihood Inference (con’t) There are situations where some of the “regularity” conditions may be violated –Boundary issue (variance components, genetic linkage, etc.) Self & Liang (1987) JASA –Discrete parameter space Lindsay & Roeder (1986) JASA –Singular information matrix (admixture model) Rotnitzky et al (2000) Bernoulli
 There are situations where some of the regularity conditions may be violated –Boundary issue (variance components, genetic linkage, etc.) Self & Liang (1987) JASA –Discrete parameter space Lindsay & Roeder (1986) JASA –Singular information matrix (admixture model) Rotnitzky et al (2000) Bernoulli")
9
Nuisance Parameters Absent under Null Ex. I.1 (Polar coordinate for bivariate normal) Under H 0 : δ = 0, γ is absent Davies (1977) Biometrika Andrews and Ploberger (1994) Econometrica
 Under H 0 : δ = 0, γ is absent Davies (1977) Biometrika Andrews and Ploberger (1994) Econometrica.")
10
Examples (con’t) Ex. I.2 (Sterotype model for ordinal categorical response) For Y = 2,.., C, log Pr(Y = j)/Pr(Y = 1) = α j + β j t x, j = 2,..,C = α j + φ j β t x 0 = φ 1 ≤ φ 2 … ≤ φ C = 1 Under H 0 : β = 0, φ j ’s are absent Anderson (1984) JRSSB
 For Y = 2,.., C, log Pr(Y = j)/Pr(Y = 1) = α j + β j t x, j = 2,..,C = α j + φ j β t x 0 = φ 1 ≤ φ 2 … ≤ φ C = 1 Under H 0 : β = 0, φ j ’s are absent Anderson (1984) JRSSB.")
11
Examples (con’t) Ex. I.3 (Variance component models) In certain situations, the covariance matrix of continuous and multivariate observations could be expressed as δM(γ) + λ 1 M 1 + … +λ q M q A hypothesis of interest is H 0 : δ = 0 (γ is absent) Ritz and Skovgaard (2005) Biometrika
 In certain situations, the covariance matrix of continuous and multivariate observations could be expressed as δM(γ) + λ 1 M 1 + … +λ q M q A hypothesis of interest is H 0 : δ = 0 (γ is absent) Ritz and Skovgaard (2005) Biometrika.")
12
Examples (con’t) Ex. I.4 (Gene-gene interactions) Consider the following logistic regression model: logit Pr(Y = 1|S 1, S 2 ) = α + Σ k δ k S 1k + Σ j λ k S 2j + γ Σ k Σ j δ k λ j S 1k S 2j To test genetic association between gene one (S 1 ) by taking into account potential interaction with gene two (S 2 ), the hypothesis of interest is H 0 : δ 1 = … = δ K = 0 (γ is absent) Chatterjee et al. (2005) American Journal of Human Genetics
 Consider the following logistic regression model: logit Pr(Y = 1|S 1, S 2 ) = α + Σ k δ k S 1k + Σ j λ k S 2j + γ Σ k Σ j δ k λ j S 1k S 2j To test genetic association between gene one (S 1 ) by taking into account potential interaction with gene two (S 2 ), the hypothesis of interest is H 0 : δ 1 = … = δ K = 0 (γ is absent) Chatterjee et al. (2005) American Journal of Human Genetics.")
13
Examples (con’t) Ex. II.1 (Admixture models) f(y; δ, γ) = δ p(y; γ) + (1 – δ) p(y; γ 0 ) δ: proportion of linked families γ: recombination fraction (γ 0 = 0.5) Smith (1963) Annals of Human Genetics The null hypothesis of no genetic linkage can be cast as H 0 : δ = 0 (γ is absent) or H 0 : γ = γ 0 (δ is absent)
 f(y; δ, γ) = δ p(y; γ) + (1 – δ) p(y; γ 0 ) δ: proportion of linked families γ: recombination fraction (γ 0 = 0.5) Smith (1963) Annals of Human Genetics The null hypothesis of no genetic linkage can be cast as H 0 : δ = 0 (γ is absent) or H 0 : γ = γ 0 (δ is absent).")
14
Examples (con’t) Ex. II.2 (Change point) logit Pr(Y = 1|x) = β 0 + βx + δ(x – γ) + (x – γ) + = x – γ if x – γ > 0 and 0 if otherwise Alcohol consumption protective for MI when consuming less than γ, but harmful when exceeding the threshold Pastor et al. (1998) American Journal of Epidemiology Hypothesis of no threshold existing can be cast as H 0 : δ = 0 (γ is absent) or H 0 : γ = ∞ (δ is absent)
 logit Pr(Y = 1|x) = β 0 + βx + δ(x – γ) + (x – γ) + = x – γ if x – γ > 0 and 0 if otherwise Alcohol consumption protective for MI when consuming less than γ, but harmful when exceeding the threshold Pastor et al. (1998) American Journal of Epidemiology Hypothesis of no threshold existing can be cast as H 0 : δ = 0 (γ is absent) or H 0 : γ = ∞ (δ is absent).")
15
Examples (con’t) Ex. II.3 (Non-linear alternative) logit Pr(Y = 1|x) = β 0 + βx + δh(x; γ) e.g., h(x; γ) = exp(xγ) – 1 The effect of alcohol consumption on risk, through log odds, of MI is non-linear if γ ≠ 0 The hypothesis of linearity relationship with a specific non-linear alternative can be cast as H 0 : δ = 0 (γ is absent) or H 0 : γ = 0 (δ is absent) Gallant (1977) JASA
 logit Pr(Y = 1|x) = β 0 + βx + δh(x; γ) e.g., h(x; γ) = exp(xγ) – 1 The effect of alcohol consumption on risk, through log odds, of MI is non-linear if γ ≠ 0 The hypothesis of linearity relationship with a specific non-linear alternative can be cast as H 0 : δ = 0 (γ is absent) or H 0 : γ = 0 (δ is absent) Gallant (1977) JASA.")
16
Characteristics of Examples Majority of examples can be characterized as f(y, x; δh y,x (γ, β), β) Class IClass II H 0 : δ = 0H 0 : δ = 0 or γ = γ 0 ( h y,x (γ 0, β) = 0 )
, β) Class IClass II H 0 : δ = 0H 0 : δ = 0 or γ = γ 0 ( h y,x (γ 0, β) = 0 )")
17
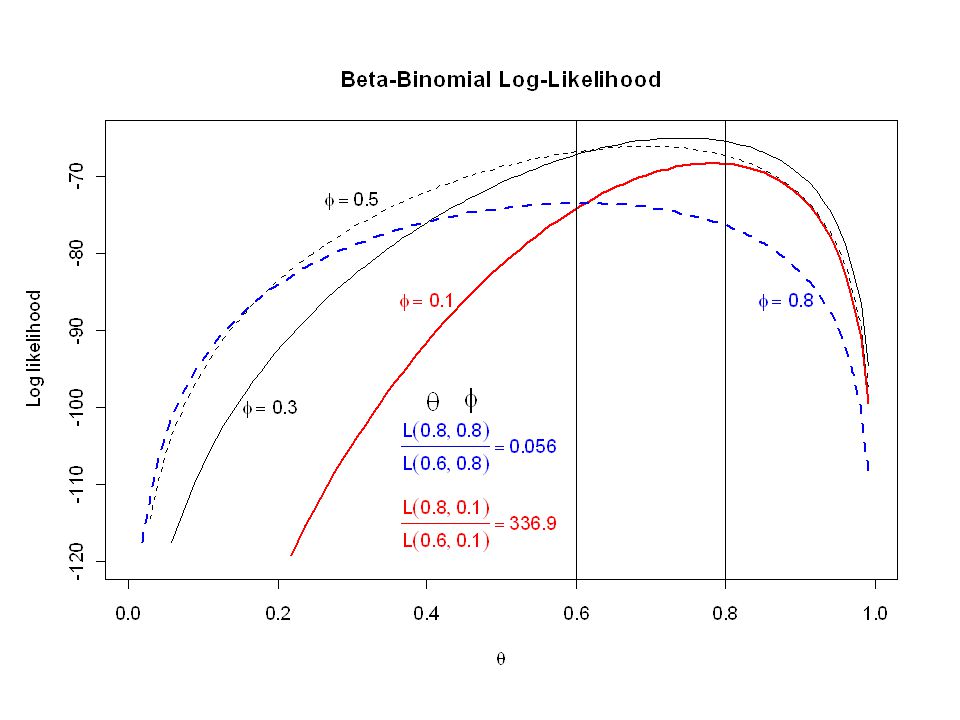
Figure: expected log likelihood function for three cases

18
Class I: Asymptotic For H 0 : δ = 0, 1.LRT = 2{logL( ) – logL(0, )} = sup γ 2{logL(, γ) – logL(0, )} = sup γ LRT(γ) 2. LRT(γ) = S(γ) t I -1 (γ)S(γ) + o p (1) = W 2 (γ) + o p (1), where S(γ) = ∂logL(δ, γ)/∂δ| δ=0, I(γ) = var{S(γ)} W(γ) = I -1/2 (γ) S(γ) and W(γ) is a Gaussian process in γ with mean 0, variance 1 and autocorrelation ρ(γ 1, γ 2 ) = cov{W(γ 1 ), W(γ 2 )}
 = S(γ) t I -1 (γ)S(γ) + o p (1) = W 2 (γ) + o p (1), where S(γ) = ∂logL(δ, γ)/∂δ| δ=0, I(γ) = var{S(γ)} W(γ) = I -1/2 (γ) S(γ) and W(γ) is a Gaussian process in γ with mean 0, variance 1 and autocorrelation ρ(γ 1, γ 2 ) = cov{W(γ 1 ), W(γ 2 )}.")
19
Class I: Asymptotic (con’t) Results were derived previously by Davies (1977, Biometrika) No analytical form available in general Approximation, simulation or resampling methods Kim and Siegmund (1989) Biometrika Zhu and Zhang (2006) JRSSB Q.: Can simplification be taken place for Asymptotic null distribution? Approximating the p-value?

20
Class I: Principal Component Representation Principal component decomposition K could be finite or ∞ {ξ 1, …,ξ K } are independent r.v.’s ξ k ~ N(0, λ k ), k = 1,.., K ρ(γ, γ) = Σ k λ k ω k (γ) 2 = 1
, k = 1,.., K ρ(γ, γ) = Σ k λ k ω k (γ) 2 = 1")
21
Class I: Principal Component Representation (con’t) W 2 (γ) = {Σ k ξ k ω k (γ)} 2 ≤ {Σ k ξ k 2 /λ k } {Σ k λ k ω k (γ )2 } = {Σ k ξ k 2 /λ k } Consequently, one has sup γ W 2 (γ) = sup γ {Σ k ξ k ω k (γ)} 2 ≤ {Σ k ξ k 2 /λ k } ~ The asymptotic distribution of LRT under H o is bounded by
 W 2 (γ) = {Σ k ξ k ω k (γ)} 2 ≤ {Σ k ξ k 2 /λ k } {Σ k λ k ω k (γ )2 } = {Σ k ξ k 2 /λ k } Consequently, one has sup γ W 2 (γ) = sup γ {Σ k ξ k ω k (γ)} 2 ≤ {Σ k ξ k 2 /λ k } ~ The asymptotic distribution of LRT under H o is bounded by")
22
Class I: Simplification Simplify to if K < ∞ and for almost every (ξ 1, …, ξ K ), there exists γ such that λ 1 ω 1 (γ)/ξ 1 = ….. = λ K ω K (γ)/ξ K Ex. I.1. (Polar coordinate for bivariate normal) For any, there exists γ ε [0, π) such that LRT ~ instead of H 0 : δ = 0 ↔ H 0 : μ 1 = μ 2
/ξ K Ex. I.1. (Polar coordinate for bivariate normal) For any, there exists γ ε [0, π) such that LRT ~ instead of H 0 : δ = 0 ↔ H 0 : μ 1 = μ 2.")
23
Class I: Simplification (con’t) Simplify to if S(γ) = h(γ) g(Y) –ρ(γ 1, γ 2 ) = 1 Ex.: Modified admixture models γ p(y; δ) + (1 – γ) p(y; δ 0 ), γ ε [a, 1] with a > 0 fixed H 0 : δ = δ 0 (γ is absent) and the score function for δ at δ 0 is S(γ) = γ ∂logp(y; δ 0 )/∂δ Known as restricted LRT for testing H 0 : δ = δ 0 Has been used in genetic linkage studies Lamdeni and Pons (1993) Biometrics Shoukri and Lathrop (1993) Biometrics
![Class I: Simplification (con’t) Simplify to if S(γ) = h(γ) g(Y) –ρ(γ 1, γ 2 ) = 1 Ex.: Modified admixture models γ p(y; δ) + (1 – γ) p(y; δ 0 ), γ ε [a, 1] with a > 0 fixed H 0 : δ = δ 0 (γ is absent) and the score function for δ at δ 0 is S(γ) = γ ∂logp(y; δ 0 )/∂δ Known as restricted LRT for testing H 0 : δ = δ 0 Has been used in genetic linkage studies Lamdeni and Pons (1993) Biometrics Shoukri and Lathrop (1993) Biometrics](http://images.slideplayer.com/13/3992372/slides/slide_23.jpg "Class I: Simplification (con’t) Simplify to if S(γ) = h(γ) g(Y) –ρ(γ 1, γ 2 ) = 1 Ex.: Modified admixture models γ p(y; δ) + (1 – γ) p(y; δ 0 ), γ ε [a, 1] with a > 0 fixed H 0 : δ = δ 0 (γ is absent) and the score function for δ at δ 0 is S(γ) = γ ∂logp(y; δ 0 )/∂δ Known as restricted LRT for testing H 0 : δ = δ 0 Has been used in genetic linkage studies Lamdeni and Pons (1993) Biometrics Shoukri and Lathrop (1993) Biometrics")
24
Class I: Approximation for P-values When simplification fails: Step 1: Calculate W(γ) and ρ(γ 1, γ 2 ) Step 2: Estimate eigenvalues {λ 1, …, λ K } and eigenfunctions {ω 1, …, ω K }, where K is chosen so that first K components explain more than 95% variation Step 3: Choose a set of dense grid {γ 1, …, γ M } and for i = 1, …, N, repeat the following steps: –Simulate ξ ik ~ N(0, λ k ) for k = 1, …, K –Calculate W i (γ m ) = {Σ k ξ ik ω k (γ m )} 2 for each m –Find the maximum of {W i (γ 1 ), …, W i (γ M )}, R i say {R 1, …, R N } approximates the null distribution of LRT
 and ρ(γ 1, γ 2 ) Step 2: Estimate eigenvalues {λ 1, …, λ K } and eigenfunctions {ω 1, …, ω K }, where K is chosen so that first K components explain more than 95% variation Step 3: Choose a set of dense grid {γ 1, …, γ M } and for i = 1, …, N, repeat the following steps: –Simulate ξ ik ~ N(0, λ k ) for k = 1, …, K –Calculate W i (γ m ) = {Σ k ξ ik ω k (γ m )} 2 for each m –Find the maximum of {W i (γ 1 ), …, W i (γ M )}, R i say {R 1, …, R N } approximates the null distribution of LRT")
25
Class II: Some New Results Consider the class of family f(y, x; δh y,x (γ, β), β), where h y,x (γ 0, β) = 0 for all y and x H 0 : δ = 0 or γ = γ 0 Tasks: 1. Derive asymptotic distribution of LRT under H 0 2. Present alternative approaches Illustrate through Ex. II.1 (Admixture models) δ Binom (m, γ) + (1 – δ) Binom (m, γ 0 ) δ ε [0, 1] and γ ε [0, 0.5], h y,x (γ, β) = p(y; γ) – p(y; γ 0 ) –For simplicity, assuming β is absent
 δ Binom (m, γ) + (1 – δ) Binom (m, γ 0 ) δ ε [0, 1] and γ ε [0, 0.5], h y,x (γ, β) = p(y; γ) – p(y; γ 0 ) –For simplicity, assuming β is absent.")
26
Class II: LRT Representation Under H 0, f(y, x; δ, γ) = f(y, x; 0, ) = f(y, x;, γ 0 ), LRT = sup δ,γ 2{logL(δ, γ) – logL(0, )} = sup δ,γ LRT(δ, γ) = max {sup 1,4 LRT(a), sup 2,4 LRT(b), sup 3 LRT(a, b)}, here for fixed a, b > 0 and γ 0 = 0.5: Region 1: δ ε [a, 1], γ ε [0.5 – b, 0.5] Region 2: δ ε [0, a], γ ε [0, 0.5 – b] Region 3: δ ε [0, a], γ ε [0.5 – b, 0.5] Region 4: δ ε [a, 1], γ ε [0, 0.5 – b]
![Class II: LRT Representation Under H 0, f(y, x; δ, γ) = f(y, x; 0, ) = f(y, x;, γ 0 ), LRT = sup δ,γ 2{logL(δ, γ) – logL(0, )} = sup δ,γ LRT(δ, γ) = max {sup 1,4 LRT(a), sup 2,4 LRT(b), sup 3 LRT(a, b)}, here for fixed a, b > 0 and γ 0 = 0.5: Region 1: δ ε [a, 1], γ ε [0.5 – b, 0.5] Region 2: δ ε [0, a], γ ε [0, 0.5 – b] Region 3: δ ε [0, a], γ ε [0.5 – b, 0.5] Region 4: δ ε [a, 1], γ ε [0, 0.5 – b]](http://images.slideplayer.com/13/3992372/slides/slide_26.jpg "Class II: LRT Representation Under H 0, f(y, x; δ, γ) = f(y, x; 0, ) = f(y, x;, γ 0 ), LRT = sup δ,γ 2{logL(δ, γ) – logL(0, )} = sup δ,γ LRT(δ, γ) = max {sup 1,4 LRT(a), sup 2,4 LRT(b), sup 3 LRT(a, b)}, here for fixed a, b > 0 and γ 0 = 0.5: Region 1: δ ε [a, 1], γ ε [0.5 – b, 0.5] Region 2: δ ε [0, a], γ ε [0, 0.5 – b] Region 3: δ ε [0, a], γ ε [0.5 – b, 0.5] Region 4: δ ε [a, 1], γ ε [0, 0.5 – b]")
27
Class II: Four Sub-Regions of Parameter Spaces

28
Class II: Regions 1 & 4 With δ ε [a, 1], this reduces to Class I, and sup 1,4 LRT(a)= sup δ { + o p (1)} W 1 (δ) = I 1 -½ (δ)S 1 (δ) S 1 (δ) = ∂logL(δ, γ)/∂γ| γ = γ 0, I 1 (δ) = var(S 1 (δ)) For the admixture models, S 1 (δ) = δ ∂log p(y; γ 0 )}/∂γ, which is proportional to δ is independent of δ
![Class II: Regions 1 & 4 With δ ε [a, 1], this reduces to Class I, and sup 1,4 LRT(a)= sup δ { + o p (1)} W 1 (δ) = I 1 -½ (δ)S 1 (δ) S 1 (δ) = ∂logL(δ, γ)/∂γ| γ = γ 0, I 1 (δ) = var(S 1 (δ)) For the admixture models, S 1 (δ) = δ ∂log p(y; γ 0 )}/∂γ, which is proportional to δ is independent of δ](http://images.slideplayer.com/13/3992372/slides/slide_28.jpg "Class II: Regions 1 & 4 With δ ε [a, 1], this reduces to Class I, and sup 1,4 LRT(a)= sup δ { + o p (1)} W 1 (δ) = I 1 -½ (δ)S 1 (δ) S 1 (δ) = ∂logL(δ, γ)/∂γ| γ = γ 0, I 1 (δ) = var(S 1 (δ)) For the admixture models, S 1 (δ) = δ ∂log p(y; γ 0 )}/∂γ, which is proportional to δ is independent of δ")
29
Class II: Regions 2 & 4 With γ ε [0, γ 0 – b], this reduces to Class I, and sup 2,4 LRT(b)= sup γ { + o p (1)} W 2 (γ) = I 2 -½ (γ)S 2 (γ) S 2 (γ) = ∂logL(δ, γ)/∂δ| δ = 0, I 2 (γ) = var(S 2 (γ)) For the admixture models, S 2 (γ) = {p(y; γ) – p(y; γ 0 )}/p(y; γ 0 ) W 2 (γ) → ∂log p(y; γ 0 )}/∂γ = W 1 as γ → γ 0 (or b → 0)
![Class II: Regions 2 & 4 With γ ε [0, γ 0 – b], this reduces to Class I, and sup 2,4 LRT(b)= sup γ { + o p (1)} W 2 (γ) = I 2 -½ (γ)S 2 (γ) S 2 (γ) = ∂logL(δ, γ)/∂δ| δ = 0, I 2 (γ) = var(S 2 (γ)) For the admixture models, S 2 (γ) = {p(y; γ) – p(y; γ 0 )}/p(y; γ 0 ) W 2 (γ) → ∂log p(y; γ 0 )}/∂γ = W 1 as γ → γ 0 (or b → 0)](http://images.slideplayer.com/13/3992372/slides/slide_29.jpg "Class II: Regions 2 & 4 With γ ε [0, γ 0 – b], this reduces to Class I, and sup 2,4 LRT(b)= sup γ { + o p (1)} W 2 (γ) = I 2 -½ (γ)S 2 (γ) S 2 (γ) = ∂logL(δ, γ)/∂δ| δ = 0, I 2 (γ) = var(S 2 (γ)) For the admixture models, S 2 (γ) = {p(y; γ) – p(y; γ 0 )}/p(y; γ 0 ) W 2 (γ) → ∂log p(y; γ 0 )}/∂γ = W 1 as γ → γ 0 (or b → 0)")
30
Class II: Region 3 With δ ε [0, a], γ ε [0.5 – b, 0.5], expand at [0, 0.5] sup 3 LRT(a, b) = sup δ,γ { + o p (1)} W 3 = I 3 -½ S 3 S 3 = ∂ 2 logp(y; 0, 0.5)/∂δ∂γ, I 3 = var(S 3 ) For the admixture models, S 3 = ∂log p(y; γ 0 )}/∂γ and W 3 = W 1
![Class II: Region 3 With δ ε [0, a], γ ε [0.5 – b, 0.5], expand at [0, 0.5] sup 3 LRT(a, b) = sup δ,γ { + o p (1)} W 3 = I 3 -½ S 3 S 3 = ∂ 2 logp(y; 0, 0.5)/∂δ∂γ, I 3 = var(S 3 ) For the admixture models, S 3 = ∂log p(y; γ 0 )}/∂γ and W 3 = W 1](http://images.slideplayer.com/13/3992372/slides/slide_30.jpg "Class II: Region 3 With δ ε [0, a], γ ε [0.5 – b, 0.5], expand at [0, 0.5] sup 3 LRT(a, b) = sup δ,γ { + o p (1)} W 3 = I 3 -½ S 3 S 3 = ∂ 2 logp(y; 0, 0.5)/∂δ∂γ, I 3 = var(S 3 ) For the admixture models, S 3 = ∂log p(y; γ 0 )}/∂γ and W 3 = W 1")
31
Class II: Asymptotic Distribution of LRT Combining three regions and let a, b → 0, LRT = max {sup 1,4 LRT(a), sup 2,4 LRT(b), sup 3 LRT(a,b)} = max {, sup [W 2 (γ)] 2, } → sup {W 2 (γ)} 2, where The asymptotic null distribution of LRT is supremum of squared Gaussian process w.r.t. γ Simplification (null distribution and approximation to p- values) can be adopted from Class I
![Class II: Asymptotic Distribution of LRT Combining three regions and let a, b → 0, LRT = max {sup 1,4 LRT(a), sup 2,4 LRT(b), sup 3 LRT(a,b)} = max {, sup [W 2 (γ)] 2, } → sup {W 2 (γ)} 2, where The asymptotic null distribution of LRT is supremum of squared Gaussian process w.r.t.](http://images.slideplayer.com/13/3992372/slides/slide_31.jpg "γ Simplification (null distribution and approximation to p- values) can be adopted from Class I.")
32
Class II: Alternatives Question: Can one find alternatives test statistics with conventional asymptotic null distributions? 1.Restricted LRT: limit range for δ to [a, 1] with a > 0 (Region 1 and 4) T R (a) = sup 1,4 LRT(a) = T R (a) decreases in a How to choose a? –Smaller the a, the better –Chi-square approximation maybe in doubt
 T R (a) = sup 1,4 LRT(a) = T R (a) decreases in a How to choose a. –Smaller the a, the better –Chi-square approximation maybe in doubt.")
33
Class II: Alternatives (con’t) 2. Smooth version (penalized LRT) Instead of excluding (δ, γ) values in Regions 2 & 3, they are “penalized” toward δ = 0 by considering penalized log-likelihood: PL(δ, γ; c) = log L(δ, γ) + c g(δ), where g(δ) ≤ 0 is a smooth penalty with, maximized at δ 0 and c > 0 controlling the magnitude of penalty Bayesian interpretation –g(δ) could be “prior” on δ
 Instead of excluding (δ, γ) values in Regions 2 & 3, they are penalized toward δ = 0 by considering penalized log-likelihood: PL(δ, γ; c) = log L(δ, γ) + c g(δ), where g(δ) ≤ 0 is a smooth penalty with, maximized at δ 0 and c > 0 controlling the magnitude of penalty Bayesian interpretation –g(δ) could be prior on δ.")
34
Class II: Penalized likelihood Define the penalized LR test statistic for H 0 : γ = γ 0 PLRT(c) = 2 {sup PL(δ, γ; c) – PL(δ 0, γ 0 ; c)} Under H 0 : PLRT(c) → as n → ∞ Proof is more demanding* Similar concerns to restricted LRT –Decreasing in c –Chi-square approximation maybe invalid with small c –Lose power if δ is small (linked families is small in proportion) *Different approach for mixture/admixture model was provided by by Chen et al. (2001, 2004) and Fu et al. (2006)
 and Fu et al. (2006).")
35
Application: Genetic Linkage for Schizophrenia Conducted by Ann Pulver at Hopkins 486 individuals from 54 multiplex families Interested in marker D22S942 in chromosome 22 Schizophrenia is relatively high in prevalence with strong evidence of genetic heterogeneity To take into account of this phenomenon, consider δ Binom (m, γ) + (1 – δ) Binom (m, γ 0 ), where δ ε [0, 1], γ ε [0, 0.5] with γ 0 = 0.5
![Application: Genetic Linkage for Schizophrenia Conducted by Ann Pulver at Hopkins 486 individuals from 54 multiplex families Interested in marker D22S942 in chromosome 22 Schizophrenia is relatively high in prevalence with strong evidence of genetic heterogeneity To take into account of this phenomenon, consider δ Binom (m, γ) + (1 – δ) Binom (m, γ 0 ), where δ ε [0, 1], γ ε [0, 0.5] with γ 0 = 0.5](http://images.slideplayer.com/13/3992372/slides/slide_35.jpg "Application: Genetic Linkage for Schizophrenia Conducted by Ann Pulver at Hopkins 486 individuals from 54 multiplex families Interested in marker D22S942 in chromosome 22 Schizophrenia is relatively high in prevalence with strong evidence of genetic heterogeneity To take into account of this phenomenon, consider δ Binom (m, γ) + (1 – δ) Binom (m, γ 0 ), where δ ε [0, 1], γ ε [0, 0.5] with γ 0 = 0.5")
36
Genetic Linkage Study of Schizophrenia (con’t) With this admixture model considered, LRT = 6.86, p-value = 0.007 PLRT with –PLRT(3.0) = 5.36, p-value = 0.010 –PLRT(0.5) = 5.49, p-value = 0.009 –PLRT(0.01) = 6.84, p-value = 0.004 Which p-value do we trust better?
 With this admixture model considered, LRT = 6.86, p-value = PLRT with –PLRT(3.0) = 5.36, p-value = –PLRT(0.5) = 5.49, p-value = –PLRT(0.01) = 6.84, p-value = Which p-value do we trust better")
37
Figure: asymptotic vs empirical distribution of the LRT for genetic linkage example

38
Discussion Issue considered, namely, nuisance parameters absent under null, is common in practice Examples can be classified into Class I and II –Class I: H 0 can only be specified through δ (= 0) –Class II: H 0 can specified either in δ (= 0) or γ (= γ 0 ) For Class I, asymptotic distribution of LRT is well known, and through principal component representation –Deriving sufficient conditions for simple null distribution – Proposing a means to approximate p-values
 –Class II: H 0 can specified either in δ (= 0) or γ (= γ 0 ) For Class I, asymptotic distribution of LRT is well known, and through principal component representation –Deriving sufficient conditions for simple null distribution – Proposing a means to approximate p-values")
39
Discussion (con’t) For Class II, less well developed –Deriving asymptotic null distribution of LRT Through this derivation, we observe –Connection with Class I –Connection with RLRT and PLRT Proof on asymptotic of PLRT non-trivial Shedding light on why penalty applied to δ not to γ? Pointing out some peculiar features and shortcoming of these two approaches A genetic linkage example on schizophrenia was presented for illustration

40
Discussion (con’t) Some future work: Constructing confidence intervals/regions Generalizing to partial/conditional likelihood –Cox PH model with change point (nuisance function) Extending to estimating function approach in the absence of likelihood function to work with –Linkage study of IBD sharing for affected sibpairs E(S(t)) = 1 + (1 - 2θ t,γ ) 2 E(S(γ)) = 1 + (1 - 2θ t,γ ) 2 δ θ t,γ = (1 – exp(–0.02|t – γ|)/2
 Some future work: Constructing confidence intervals/regions Generalizing to partial/conditional likelihood –Cox PH model with change point (nuisance function) Extending to estimating function approach in the absence of likelihood function to work with –Linkage study of IBD sharing for affected sibpairs E(S(t)) = 1 + (1 - 2θ t,γ ) 2 E(S(γ)) = 1 + (1 - 2θ t,γ ) 2 δ θ t,γ = (1 – exp(–0.02|t – γ|)/2")
Similar presentations








>")


 values must be estimated before.>")




 and likelihood ratio (LR) test>")
 by R. O. Duda, P. E. Hart and D. G. Stork, John.>")


