Download presentation
Presentation is loading. Please wait.

1
15.8 Algorithms using more than two passes Presented By: Seungbeom Ma (ID 125) Professor: Dr. T. Y. Lin Computer Science Department San Jose State University

2
Multipass Algorithms Previously, most of algorithms are required two passes. There is a case that we need more than two passes. Case : Data is too big to store in main memory. We have to hash or sort the relation with multipass algorithms.

3
Agenda 1. Multipass Sort-Based Algorithm 2. Multipass Hash-Based Algorithm

4
Multipass sort-based algorithm. M: Number of Memory Buffers R: Relation B(R) : Number of blocks for holding relation. BASIS: 1. If R fits in M block (B (R) <= M). 2. Reading R into main memory. 3. Sorting R in the main memory with any sorting algorithm. 4. Write the sorted relation to disk.
 : Number of blocks for holding relation. BASIS: 1. If R fits in M block (B (R) <= M). 2. Reading R into main memory. 3. Sorting R in the main memory with any sorting algorithm. 4. Write the sorted relation to disk..")
5
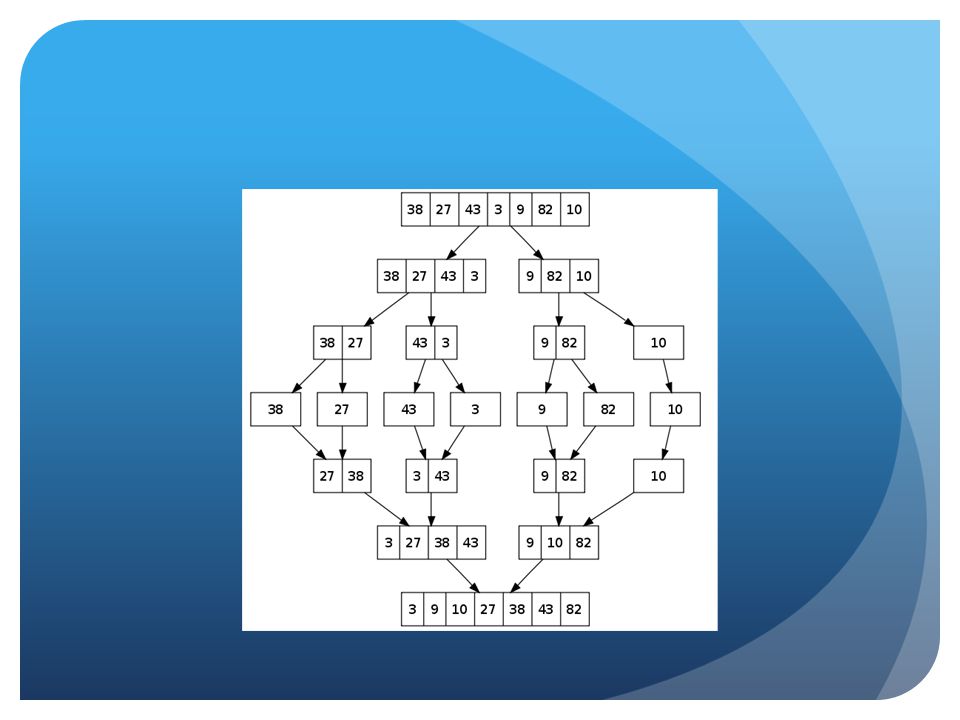
Multipass sort-based algorithm. INDUCTION: (B(R)> M) 1. If R does not fit into main memory then partitioning the blocks hold R into M groups, which call R 1, R 2, …, R M 2.Recursively sorting R i from i =1 to M 3.Once sorting is done, the algorithm merges the M sorted sub- lists.

7
Performance: Multipass Sort-Based Algorithms 1) Each pass of a sorting algorithm: 1.Reading data from the disk. 2. Sorting data with any sorting algorithms 3. Writing data back to the disk. 2-1) (k)-pass sorting algorithm needs 2k B(R) disk I/O’s 2-2)To calculate (Multipass)-pass sorting algorithm needs = > A+ B A: 2(K-1 ) (B(R) + B(S) ) [ disk I/O operation to sort the sublists] B: B(R) + B(S)[ disk I/O operation to read the sorted the sublists in the final pass] Total: (2k-1)(B(R)+B(S)) disk I/O’s
 (k)-pass sorting algorithm needs 2k B(R) disk I/O’s 2-2)To calculate (Multipass)-pass sorting algorithm needs = > A+ B A: 2(K-1 ) (B(R) + B(S) ) [ disk I/O operation to sort the sublists] B: B(R) + B(S)[ disk I/O operation to read the sorted the sublists in the final pass] Total: (2k-1)(B(R)+B(S)) disk I/O’s.")
8
Multipass Hash-Based Algorithms 1. Hashing the relations into M-1 buckets, where M is number of memory buffers. 2. Unary case: It applies the operation to each bucket individually. 1.Duplicate elimination ( δ ) and grouping ( γ ). 1) Grouping: Min, Max, Count, Sum, AVG, which can group the data in the table 2) Duplicate elimination: Distinct Basis: If the relation fits in M memory block, -> Reading relation into memory and perform the operations. 3. Binary case: It applies the operation to each corresponding pair of buckets. Query operations: union, intersection, difference, and join If either relations fits in M-1 memory blocks, -> Reading that relation into main memory M-1 blocks -> Reading next relation to 1 block at a time into the M th block Then performing the operations.
 and grouping ( γ ). 1) Grouping: Min, Max, Count, Sum, AVG, which can group the data in the table 2) Duplicate elimination: Distinct Basis: If the relation fits in M memory block, -> Reading relation into memory and perform the operations. 3. Binary case: It applies the operation to each corresponding pair of buckets. Query operations: union, intersection, difference, and join If either relations fits in M-1 memory blocks, -> Reading that relation into main memory M-1 blocks -> Reading next relation to 1 block at a time into the M th block Then performing the operations..")
9
INDUCTION If Unary and Binary relation does not fit into the main memory buffers. 1.Hashing each relation into M-1 buckets. 2.Recursively performing the operation on each bucket or corresponding pair of buffers. 3.Accumulating the output from each buckets or pair.

10
Hash-Based Algorithms : Unary Operatiors

11
Perfermance: Hash-Based Algorithms R: Realtion. Operations are like δ and γ M: Buffers U(M, k): Number of blocks in largest relation with k-pass hashing algorithm.
: Number of blocks in largest relation with k-pass hashing algorithm..")
12
Performance: Induction Induction: 1. Assuming that the first step divides relation R into M-1 equal buckets. 2. The buckets for the next pass must be small enough to handle in k-1 passes 3.Since R is divided into M-1 buckets, we need to have (M-1)u(M, k-1).
u(M, k-1)..")
13
Sort-Based VS Hash-Based 1. Sort-based can produce output in sorted order. It might be helpful to reduce rotational latency or seek time 2. Hash-based depends on buckets being of equal size. For binary operations, hash-based only limits size of smaller relation. Therefore, hash-based can be faster than sort-based for small size of relation.

14
THANKS

Similar presentations







 APRIL 9 th, 2008 Submittetd To: Dr. T Y Lin Computer Science Department San Jose State University.>")
![Dr. Kalpakis CMSC 661, Principles of Database Systems Query Execution [15]](/15/4560406/big_thumb.jpg "Dr. Kalpakis CMSC 661, Principles of Database Systems Query Execution [15]>")

>")








