Download presentation
Presentation is loading. Please wait.

1
Statistical Analysis of Single Case Design Serial Dependence Is More than Needing Cheerios for Breakfast

2
Goal of Presentation Review concept of effect size Describe issues in using effect size concept for single case design Describe different traditional approaches to calculating effect size for single case design Illustrate one recent approach

3
Behavioral Intervention Research 3

4
Putting A Coat on Your Dog Before Going For a Walk

5
How We Have Gotten To This Meeting Long history of statistical analysis of SCD Criticism of quality of educational research (Shalvelson & Towne, 2002) Establishment of IES – Initial resistance to SCD Influence of professional groups IES willingness to fund research on statistical analysis
 Establishment of IES – Initial resistance to SCD Influence of professional groups IES willingness to fund research on statistical analysis")
6
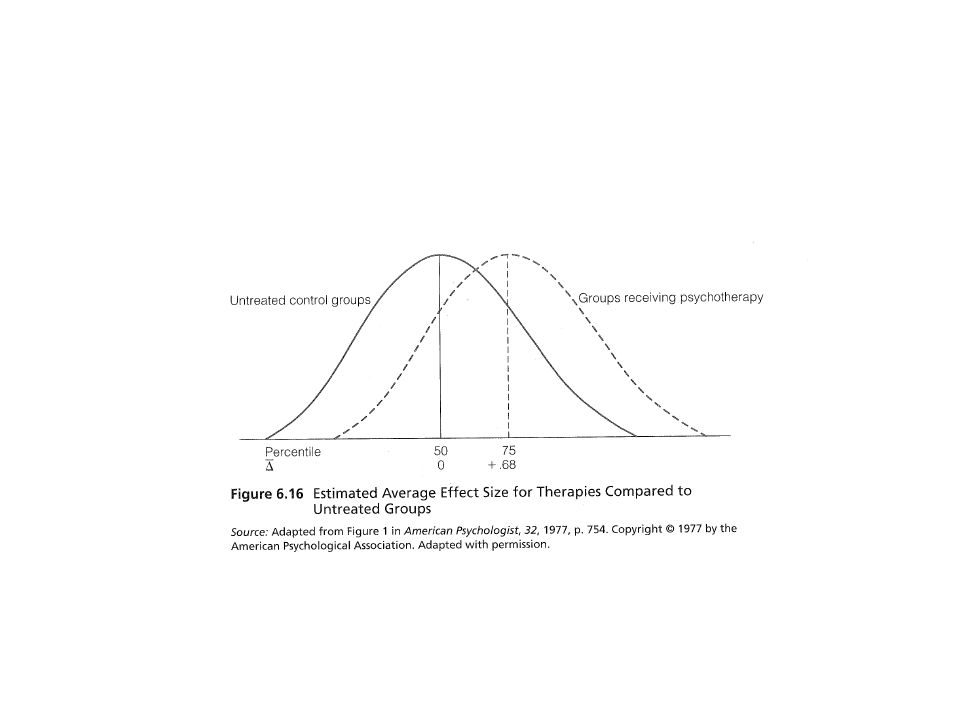
Concept of Effect Size of Study Effect size is a statistic quantifying the extent to which sample statistics diverge from the null hypotheses (Thompson, 2006)
")
7
Types of ESs for Group Design Glass Δ = (Me – Mc) / SDc Cohen’s d = (Me – Mc)/ Sdpooled Interpretation – Small =.20 – Medium =.50 – Large =.80 R 2 Eta 2 = SSeffect/SStotal
 / SDc Cohen’s d = (Me – Mc)/ Sdpooled Interpretation – Small =.20 – Medium =.50 – Large =.80 R 2 Eta 2 = SSeffect/SStotal")
8
Statistical Analysis Antithetical To Single Case Design (SCD)? Original developers believed that socially important treatment effects have to be large enough to be reliably detected by visual inspection of the data.

9
Kazdin (2011) proposes Visual inspection less trustworthy when effects at not crystal clear Serial dependence may obscure visual analysis Detection of small effects may lead to understanding that could in turn lead to large effects Statistical analysis may generate ESs that allow one to answer more precise questions Effects for different types of individuals Experimenter effects
 proposes Visual inspection less trustworthy when effects at not crystal clear Serial dependence may obscure visual analysis Detection of small effects may lead to understanding that could in turn lead to large effects Statistical analysis may generate ESs that allow one to answer more precise questions Effects for different types of individuals Experimenter effects")
10
Example: PRT and Meta-Analysis (Shadish, 2012) Pivotal Response Training (PRT) for Childhood Autism 18 studies containing 91 SCD’s. For this example, to meet the assumptions of the method, the preliminary analysis: – Used only the 14 studies with at least 3 cases (66 SCDs). – Kept only the first baseline and PRT treatment phases, eliminating studies with no baseline After computing 14 effect sizes (one for each study), he used standard random effects meta- analytic methods to summarize results:
. – Kept only the first baseline and PRT treatment phases, eliminating studies with no baseline After computing 14 effect sizes (one for each study), he used standard random effects meta- analytic methods to summarize results:.")
11
Results ------- Distribution Description --------------------------------- N Min ES Max ES Wghtd SD 14.000.181 2.087.374 ------- Fixed & Random Effects Model ----------------------------- Mean ES -95%CI +95%CI SE Z P Fixed.4878.3719.6037.0591 8.2485.0000 Random.6630.4257.9002.1210 5.4774.0000 ------- Random Effects Variance Component ------------------------ v =.112554 ------- Homogeneity Analysis ------------------------------------- Q df p 39.9398 13.0000.0001 Random effects v estimated via noniterative method of moments. The results are of the order of magnitude that we commonly see in meta-analyses of between groups studies I 2 = 67.5%

12
Studies done at UCSB (=0) or elsewhere (=1) ------- Analog ANOVA table (Homogeneity Q) ------- Q df p Between 3.8550 1.0000.0496 Within 16.8138 12.0000.1567 Total 20.6688 13.0000.0797 ------- Q by Group ------- Group Qw df p.0000 1.9192 3.0000.5894 1.0000 14.8947 9.0000.0939 ------- Effect Size Results Total ------- Mean ES SE -95%CI +95%CI Z P k Total.6197.0980.4277.8118 6.3253.0000 14.0000 ------- Effect Size Results by Group ------- Group Mean ES SE -95%CI +95%CI Z P k.0000 1.0228.2275.5769 1.4686 4.4965.0000 4.0000 1.0000.5279.1086.3151.7407 4.8627.0000 10.0000 ------- Maximum Likelihood Random Effects Variance Component ------- v =.05453 se(v) =.04455 Of course, we have no idea why studies done at UCSB produce larger effects: different kinds of patients? different kinds of outcomes? But the analysis does illustrate one way to explore heterogeneity

13
Search for the Holy Grail of Effect Size Estimators No single approach agreed upon: (40+ have been identified, Swaminathan et al., 2008) Classes of approaches – Computational approaches – Randomization test – Regression approaches – Tau-U (Parker et al., 2011) as combined approach
 Classes of approaches – Computational approaches – Randomization test – Regression approaches – Tau-U (Parker et al., 2011) as combined approach")
14
Computational Approaches Percentage of Nonoverlapping Datapoints (PND) (Scruggs, Mastropieri, & Casto, 1987) Percentage of Zero Data (Campbell, 2004) Improvement Rate Difference (Parker, Vannest, & Brown, 2009)
 (Scruggs, Mastropieri, & Casto, 1987) Percentage of Zero Data (Campbell, 2004) Improvement Rate Difference (Parker, Vannest, & Brown, 2009)")
15
ABAB 6 Level of Experimental Control No Exp Control Publishable Strong Exp Control 1 2 3 4 5 6 7

16
ABAB 7 Level of Experimental Control No Exp Control Publishable Strong Exp Control 1 2 3 4 5 6 7 Evaluate for LEVEL Evaluate for TREND Evaluate for LEVEL Evaluate for TREND

17
Problem with phases

18
Randomization Test Edgington (1975, 1980) advocated strongly for use of nonparametric randomization tests. – Involves selection of comparison points in the baseline and treatment conditions – Requires random start day for participants (could be random assignment of participants in MB design, Wampold & Worsham, 1986) Criticized for SDC – Large Type I Error rate (Haardofer & Gagne, 2010) – Not robust to independence assumption and sensitivity low for data series < 30 to 40 datapoints (Manolov & Solanas, 2009)
 Criticized for SDC – Large Type I Error rate (Haardofer & Gagne, 2010) – Not robust to independence assumption and sensitivity low for data series < 30 to 40 datapoints (Manolov & Solanas, 2009).")
19
ABAB 7 Level of Experimental Control No Exp Control Publishable Strong Exp Control 1 2 3 4 5 6 7 Evaluate for LEVEL Evaluate for TREND Evaluate for LEVEL Evaluate for TREND

20
Regression (Least Squares Approaches) ITSACORR (Crosbie, 1993) – Interrupted time series analysis – Criticized for not being correlated with other methods White, Rusch, Kazdin, & Hartmann (1989) Last day of Treatment Comparison (LDT) – Compares two LDT for baseline and treatment – Power weak because of lengthy predictions
 ITSACORR (Crosbie, 1993) – Interrupted time series analysis – Criticized for not being correlated with other methods White, Rusch, Kazdin, & Hartmann (1989) Last day of Treatment Comparison (LDT) – Compares two LDT for baseline and treatment – Power weak because of lengthy predictions")
22
Regression Analyses Mean shift and mean-plus-trend model (Center, Skiba, & Casey; 1985-86) Ordinary least squares regression analysis (Allison & Gorman, 1993) – Both approaches attempt to control for trends in baseline when examining the performances in treatment d-Estimator (Shadish, Hedges, Rinscoff, 2012) GLS with removal of autocorrelaiton (Swaminathan, Horner, Rogers, & Sugai, 2012)
 Ordinary least squares regression analysis (Allison & Gorman, 1993) – Both approaches attempt to control for trends in baseline when examining the performances in treatment d-Estimator (Shadish, Hedges, Rinscoff, 2012) GLS with removal of autocorrelaiton (Swaminathan, Horner, Rogers, & Sugai, 2012)")
23
Tau-U (Parker, Vannest, Javis, & Sauber, 2011) Mann-Whitney U a nonparametric that compares individual data point in groups (AB comparisons) Kendal’s Tau does these same thing for trend within groups Tau-U – Tests and control for trend in A phase – Test for differences in A and B phases – Test and adjust for tend in B phase
 Mann-Whitney U a nonparametric that compares individual data point in groups (AB comparisons) Kendal’s Tau does these same thing for trend within groups Tau-U – Tests and control for trend in A phase – Test for differences in A and B phases – Test and adjust for tend in B phase")
24
ABAB 7 Level of Experimental Control No Exp Control Publishable Strong Exp Control 1 2 3 4 5 6 7 Evaluate for LEVEL Evaluate for TREND Evaluate for LEVEL Evaluate for TREND

25
Tau-U Calculator http://www.singlecaseresearch.org/ Vannest, K.J., Parker, R.I., & Gonen, O. (2011). Single Case Research: web based calculators for SCR analysis. (Version 1.0) [Web-based application]. College Station, TX: Texas A&M University. Retrieved Sunday 15th July 2012. http://www.singlecaseresearch.org/ Combines nonoverlap between phases with trend from within intervention phases – Will detect and allow researcher to control for undesirable trend in baseline phase Data are easily entered on free website Generates a d for effects with trend withdrawn when necessary
. Single Case Research: web based calculators for SCR analysis. (Version 1.0) [Web-based application]. College Station, TX: Texas A&M University. Retrieved Sunday 15th July Combines nonoverlap between phases with trend from within intervention phases – Will detect and allow researcher to control for undesirable trend in baseline phase Data are easily entered on free website Generates a d for effects with trend withdrawn when necessary.")
26
Themes: An accessible and feasible effect size estimator As end users, SCD researchers need a tool that we can use without having to consult our statisticians – Utility of the hand calculated trend line analysis – Example of feasible tool, but criticized (ITSACORR< Crosbie, 1993). Parker, Vannest, Davis, & Sauber (2011) – Tau-U calculator
 – Tau-U calculator.")
27
Theme: What is an effect—a d that detect treatment or/and level effect If a single effect size is going to be generated for an AB comparison: should the d be reported separately for level (intercept) or trend (slope)? – If so, problematic for meta-analysis ES estimators here appear to provide a combined effect for slope and intercept Parker et al. (2011) incorporate both
 incorporate both.")
28
Theme: What comparisons get included in the meta-analysis Should we only use the initial AB comparison in ABAB Designs?

29
Theme: What comparisons get included in the meta-analysis Should we only include points at which functional relationship is established?

30
Theme: How many effects sizes per study? 30 Study Study 1 Study 2 … Study K Subject Subj 1 Subj 2 Subj 1 Subj 1 Subj 2 Subj 3 Subj4 Moments m mm m m m m m m mm mm m

31
Challenge: How do you handle zero baselines or treatment phases?

32
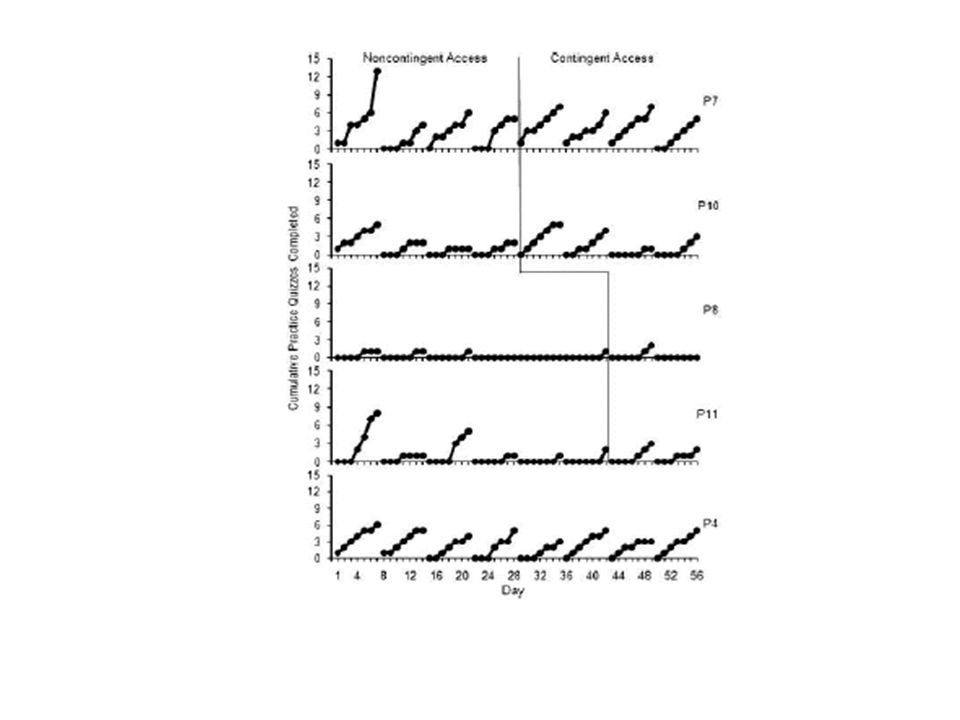
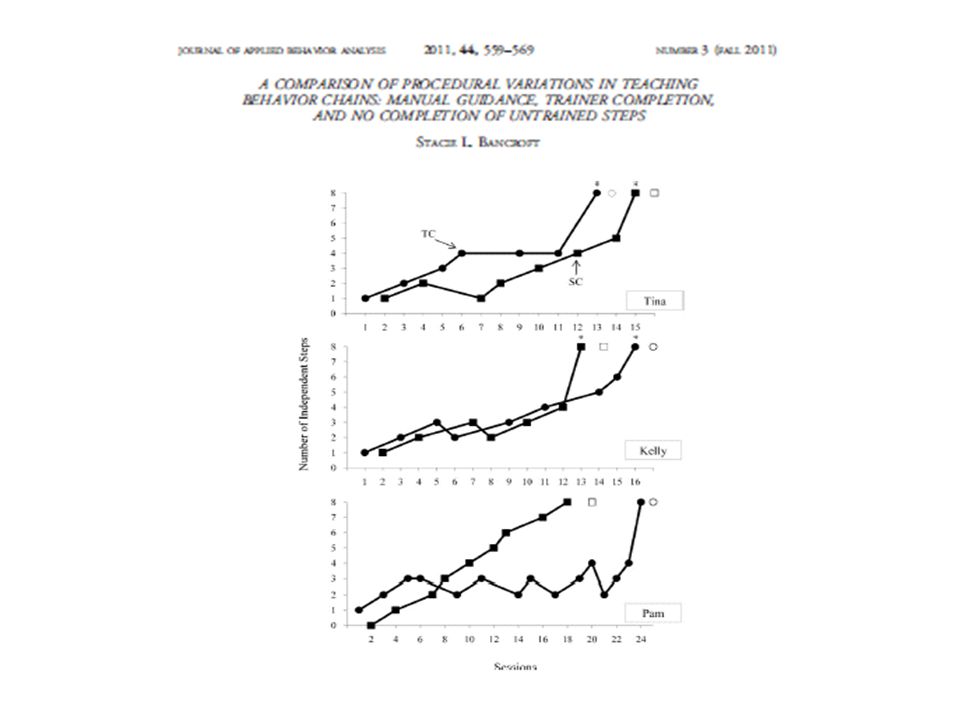
Heterogeneity In SCD: A reality SCD Researchers used a range of different designs and design combinations A look at current designs – Fall, 2011 Issue of Journal of Applied Behavior Analysis

39
Comparison of SDC and Group Design ESs: The Apples and Oranges Issues Logic of casual inferences different – Groups: Means differences between groups – SCD: Replication of effects either within or across all “participants” – Generally d represents different comparison Data collected to document an effect different – Group designs collect data before treatment and after treatment – SCDs collect data throughout treatment phase, so for treatments that build performance across time, they may appear less efficacious because they are including “acquisition” phase effects in analysis

40
ABAB 4 Level of Experimental Control No Exp Control Publishable Strong Exp Control 1 2 3 4 5 6 7

42
Conclusions I learned a lot Sophistication of analyses is increasing Feasibility of using statistical analysis is improving Can use statistical analysis as supplement to visual inspection (Kazdin, 2011) Statistical analysis may not be for everybody, but it is going to foster acceptability in the larger education research community, and for that reason SCD researchers should consider it.
 Statistical analysis may not be for everybody, but it is going to foster acceptability in the larger education research community, and for that reason SCD researchers should consider it.")
Similar presentations





 Oklahoma.>")












 for a given population different from.>")





