Download presentation
Presentation is loading. Please wait.

1
Data collection, analysis, modelling, publication ……. and beyond Lessons learned from the analysis of HIV prevalence and incidence data from Zimbabwe. John Hargrove, Brian Williams DAIDD Workshop December 2013U Florida, Gainesville

2
What kinds of data are useful for modeling? How to collect/access data important in modeling disease systems (network data for contact patterns, weather data, disease incidence data, etc)? When is it OK to take data or parameter estimates from other studies and use them in my model? If DAIDD is supposed to be for epidemiology-oriented people who are here to learn about mathematical modeling in order to collaborate with modelers and speak their language, it would be helpful to know how we can actually use our epi methods training to contribute to model development. The thrust of this workshop is an effort to encourage those already invested in (quantitative) medical research to consider ways in which mathematical modelling might add value to their research. One of last year’s DAIDD participants had the following thoughts, which we will bear in mind during this discussion:
. When is it OK to take data or parameter estimates from other studies and use them in my model. If DAIDD is supposed to be for epidemiology-oriented people who are here to learn about mathematical modeling in order to collaborate with modelers and speak their language, it would be helpful to know how we can actually use our epi methods training to contribute to model development. The thrust of this workshop is an effort to encourage those already invested in (quantitative) medical research to consider ways in which mathematical modelling might add value to their research. One of last year’s DAIDD participants had the following thoughts, which we will bear in mind during this discussion:.")
3
Strictly speaking the analysis of such an RCT interests itself solely in deciding whether or not pre-defined null hypotheses can or cannot be rejected. [Some studies even preclude other analyses being applied to the data]. But restricting one’s view in this way can mean that one is wasting valuable information that can shed light on other areas of interest. The Randomised Control Trial is quite rightly regarded as the gold standard for a clinical trial. RCTs are often used to test the efficacy and/or effectiveness of various types of medical intervention within a patient population.

4
14,110 mothers and their babies were recruited within 72 hours of giving birth. The RCT tested for the efficacy of a single large dose of vitamin A in reducing maternal and neonatal mortality among HIV positive and negative cases, HIV incidence in mothers, and mother-to-baby transmission of the virus. Trial suggested following demonstration in India that vitamin A could reduce perinatal mortality even in settings where there was no HIV. The ZVITAMBO (Zimbabwe Vitamin A for Mothers and Babies) study was such an RCT carried out in Harare, Zimbabwe between November 1997 and January 2000.
 study was such an RCT carried out in Harare, Zimbabwe between November 1997 and January")
6
The Trial might thus be viewed as a disappointment – even if it did, at least, provide an unequivocal answer to the research question. But this disappointment was entirely over-ridden by the spin-off, which steadily emerged from the analysis of all of the data collected in the process. The ZVITAMBO study found no effect at all (neither positive nor negative) of vitamin A treatment on any of the six medical outcomes investigated.
 of vitamin A treatment on any of the six medical outcomes investigated..")
7
Demonstrated a marked genetic predisposition to HIV infection among sub-groups of the population. Showed that HIV positive women were at significantly increased risk of dying – regardless of CD4 count. Used to validate the BED assay for application to clade C virus: and currently being similarly used to validate more effective avidity bio-markers to be used in HIV incidence estimation. The study demonstrated unequivocally the importance of exclusive breastfeeding in minimising mother-to-child transmission of HIV and optimising disease free infant survival

8
In order to estimate the effect of Vitamin treatment on HIV acquisition it was necessary to test all mothers and babies for HIV – at recruitment and then at 3-mo intervals for up to two years. As a consequence the Trial produced an interesting pictures of HIV prevalence and incidence as a function of time and of maternal age. In what follows we will try to see what we can learn from such data (first) without using any mathematical modelling. And then try to see what further juice we can get through the use of the mathematical press. None of the above results depended (primarily) on mathematical modelling. We now look at a further example where simple statistical analysis was not sufficient and where modelling was necessary: and useful …
 without using any mathematical modelling. And then try to see what further juice we can get through the use of the mathematical press. None of the above results depended (primarily) on mathematical modelling. We now look at a further example where simple statistical analysis was not sufficient and where modelling was necessary: and useful ….")
9
First law of statistics? Look at your data. Second law of statistics? Play with your data. The thrust of what we are trying to get across in this workshop is that we want to engage with data

10
If it’s good enough for Isaac it’s good enough for me. PLAY with your data. I was like a boy playing on the sea-shore, and diverting myself now and then finding a smoother pebble or a prettier shell than ordinary, whilst the great ocean of truth lay all undiscovered before me.

11
A pre-requisite for a good (data-based) modelling exercise is a good data set. So first clean your data. Data on age is just one example…..

12
Data on parity is another. The cleaning process can be tedious, but it is necessary. “There’s never time to do it right ….”. “but there’s always time to do it over”

13
Now pool on age and see whether there is any relationship between HIV prevalence and calendar date. Is there any trend in the prevalence with date of recruitment??

14
1.Prevalence is increasing 2.Prevalence is decreasing 3.Prevalence is not changing significantly with time 4.Something else is going on 5.The dog ate my homework 6.I have a headache 7.I don’t like you anyway so I’m not going to answer any of your questions Decide between the following possibilities:

15
15 What is the relationship?

16
16 Median Global Temperature During the Past 50 Years

17
What do we now think about the scales in this figure? How quickly would we expect HIV prevalence to change?

18
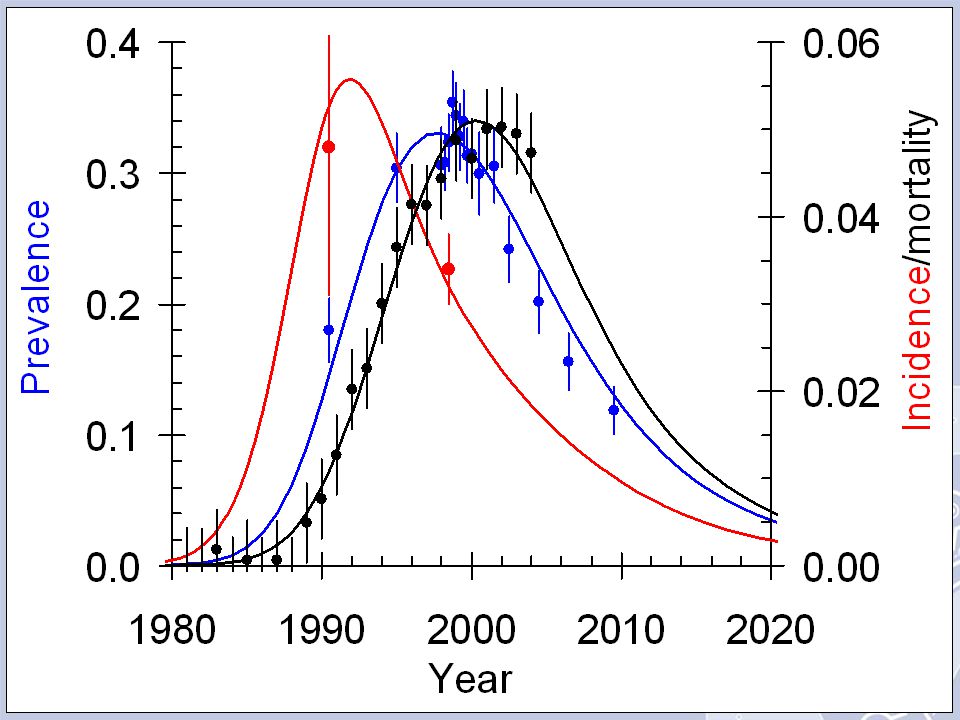
For the ZVITAMBO Trial, HIV prevalence increased significantly during 1998, thereafter it declined significantly. We have fitted a parabola to the data. Is that a good model? What happens for very small, or very large, values of time? What does prevalence pattern actually look like pre/post ZVITAMBO?

19
When the ZVITAMBO data are amalgamated with other data from Harare ANC sites, prevalence appears to have peaked at the end of 1998 and seems to have been declining ever since. Why should this be? Is it a natural consequence of epidemic development? Is it just due to deaths? Do the same changes occur in all age groups? Perhaps older people are dying off, leaving just young women with (relatively) low prevalence? Look at age effects.
 low prevalence. Look at age effects..")
20
HIV prevalence initially increases with age – peaking at a horrendous level of 50% for women aged about 30. Then declines sharply. Why the decline? Is it due to decreasing incidence in older women? Or is it due to deaths? If due to death among older women would expect decline in mean age. Perhaps this fits with declining prevalence over time?

21
Age structure did shift towards younger women. From 1991 to 2002, teenage pregnancies increased from 11% to 23%; >35s decreased from 13% to 3%; mean from 27.4 to 24.6 yrs. But since that time there has been a reversal in the age trend. Need to look at age-specific HIV incidence and prevalence.

22
Only two estimates of age-incidence function. Why so few?? The shape of the two age-incidence graphs are similar and consistent with the idea that risk of HIV infection has, over much of the epidemic, been a decreasing function of age. The women for Mbizvo study were recruited in 1991/2; 7-9 years before ZVITAMBO. Why does the age-incidence curve seem to be so much less variable in the Mbizvo study?

23
Look how height and timing of peak prevalence changes with age. How do we explain these changes? What is the significance of prevalence changes in teenage mothers? What about in older women?

24
where is the initial rate of increase in prevalence to a peak level proportional to a, and where prevalence converges, at rate , to b 0 for large t; is an offset parameter which decides the timing of the peak in prevalence. Changes in prevalence with time – whether pooled or stratified on age – are very nicely fitted using a “double logistic” function.

25
So, now we have a nice fit to all of the available data on ANC HIV data in Harare – both for pooled and age-distributed data. So should we go right ahead and publish? Why might we not want to do that …. Or at least not just yet? What does the statistical model tell us about changes in HIV incidence? What does it tell us about the mechanisms behind the observed changes in HIV prevalence? It’s becoming difficult to understand, explain and describe (in words) what is going on. Perhaps we are (finally) at the point where we NEED a dynamic (mathematical) model?
 what is going on. Perhaps we are (finally) at the point where we NEED a dynamic (mathematical) model .")
26
Mortality in Harare. With the end of the war in Zimbabwe in 1980 there was a large influx of foreign aid, jobs were created, and health and education services were improved. Mortality in Harare declined – until the effects of the HIV- AIDS epidemic made themselves felt.

27
We keep the population constant. And have AIDS mortality modelled as a Weibull function. We start with as very simple “box car” model where the probability of infection is a constant for all ages of women and at all times

28
= birth rate N = S + I = infection rate I = Weibull mortality S I I N S I /N I S Normal (Weibull 2) Exponential (Weibull 1)
 Exponential (Weibull 1) ")
30
= birth rate N = population = e – P I = Weibull mort. ~ ~ S I I N S I /N I S –P–P e Heterogeneity in sexual behaviour

32
~ S I I N S I /N I S ~ = birth rate N = population = C(t) I = mortality ~ ~ C(t)C(t) Including control
 I = mortality ~ ~ C(t)C(t) Including control")
34
~ S I I N S I /N I S * = birth rate N = population = e I = mortality ~ * –M–M –M–M e Mortality leads to behaviour change

38
So things seem to have been changing for the better, on the HIV front at least, in Zimbabwe. Why? Natural consequence of epidemic development? Economic melt down? Emigration? Better educated population? Greater proportion of people married? Greater awareness leading to behaviour change?

39
The number of condoms distributed in Zimbabwe has risen steadily since 1994 – as has the proportion purchased rather than donated.

40
Before we get TOO excited and self-satisfied…. Recall that we have fitted prevalence data for age-pooled situation. Why do you think that might be?

41
What kinds of data are useful for modeling? Data from well-designed, well-executed trials/experiments How to collect/access data important in modeling disease systems (network data for contact patterns, weather data, disease incidence data, etc)? When is it OK to take data or parameter estimates from other studies and use them in my model? In the approach here we have stood this question on its head. We did NOT start with a model and then look for data. We started with the data set: we played with it, we thought about it, we interpreted it and then, and only then, we derived a model. Because we NEEDED a model. If DAIDD is supposed to be for epidemiology-oriented people who are here to learn about mathematical modeling in order to collaborate with modelers and speak their language, it would be helpful to know how we can actually use our epi methods training to contribute to model development. This presentation has tried to show how the use of standard “classical “ epidemiological techniques was critical to getting a basic understanding of what was going on. This then suggested the kind of model that was required to improve that understanding.
. When is it OK to take data or parameter estimates from other studies and use them in my model. In the approach here we have stood this question on its head. We did NOT start with a model and then look for data. We started with the data set: we played with it, we thought about it, we interpreted it and then, and only then, we derived a model. Because we NEEDED a model. If DAIDD is supposed to be for epidemiology-oriented people who are here to learn about mathematical modeling in order to collaborate with modelers and speak their language, it would be helpful to know how we can actually use our epi methods training to contribute to model development. This presentation has tried to show how the use of standard classical epidemiological techniques was critical to getting a basic understanding of what was going on. This then suggested the kind of model that was required to improve that understanding..")
Similar presentations







>")

 Oklahoma.>")

 Public Health England London,>")



![Thoughts on Simplifying the Estimation of HIV Incidence John Hargrove, Alex Welte, Paul Mostert [and others]](/16/5147976/big_thumb.jpg "Thoughts on Simplifying the Estimation of HIV Incidence John Hargrove, Alex Welte, Paul Mostert [and others]>")
: Outliers Fall, 2008.>")






 National Centre for Epidemiology and Population Health.>")

