Download presentation
Presentation is loading. Please wait.

4
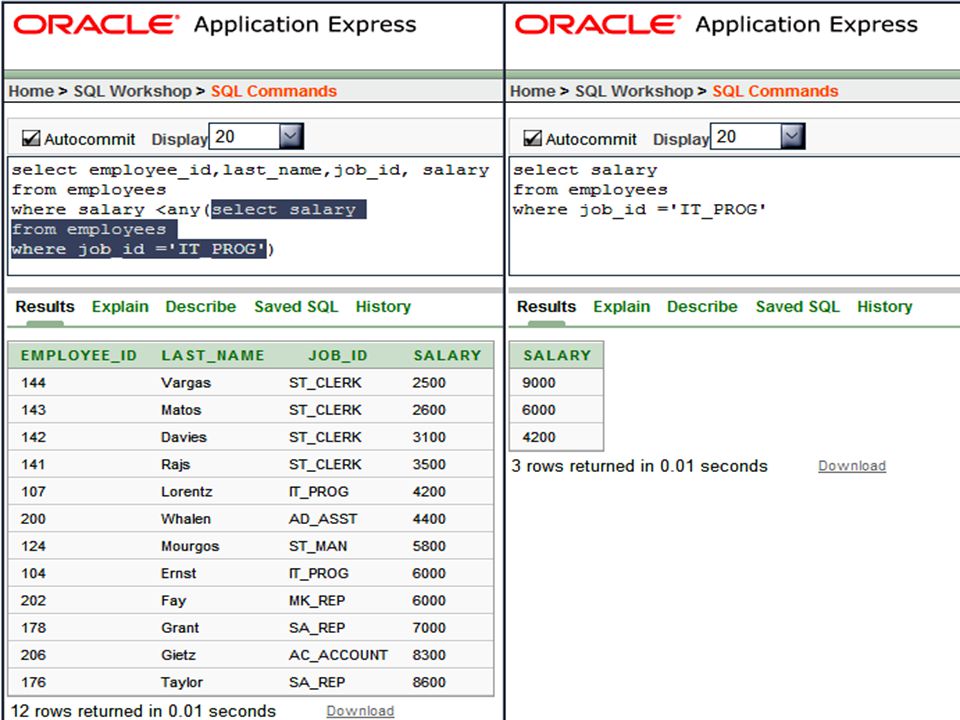
Group functions cannot be used in the WHERE clause:
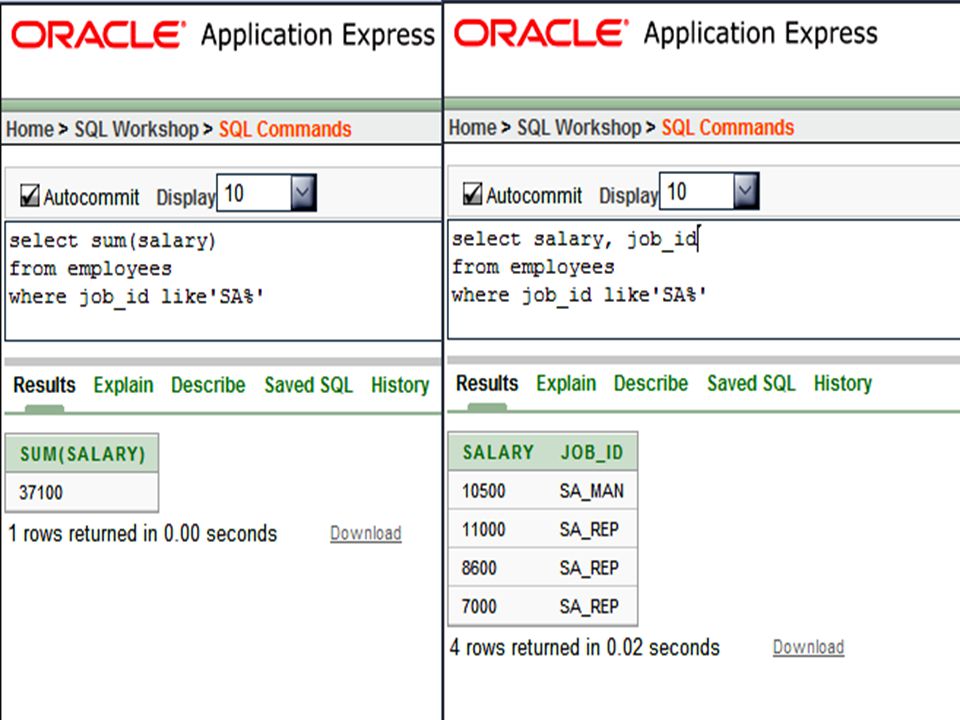
SELECT type_code FROM d_songs WHERE SUM (duration) = 100; (this will give an error) Group functions ignore NULL values. In the example below, the (null) values were not used to find the average overtime rate.
 = 100; (this will give an error) Group functions ignore NULL values. In the example below, the (null) values were not used to find the average overtime rate.")
5
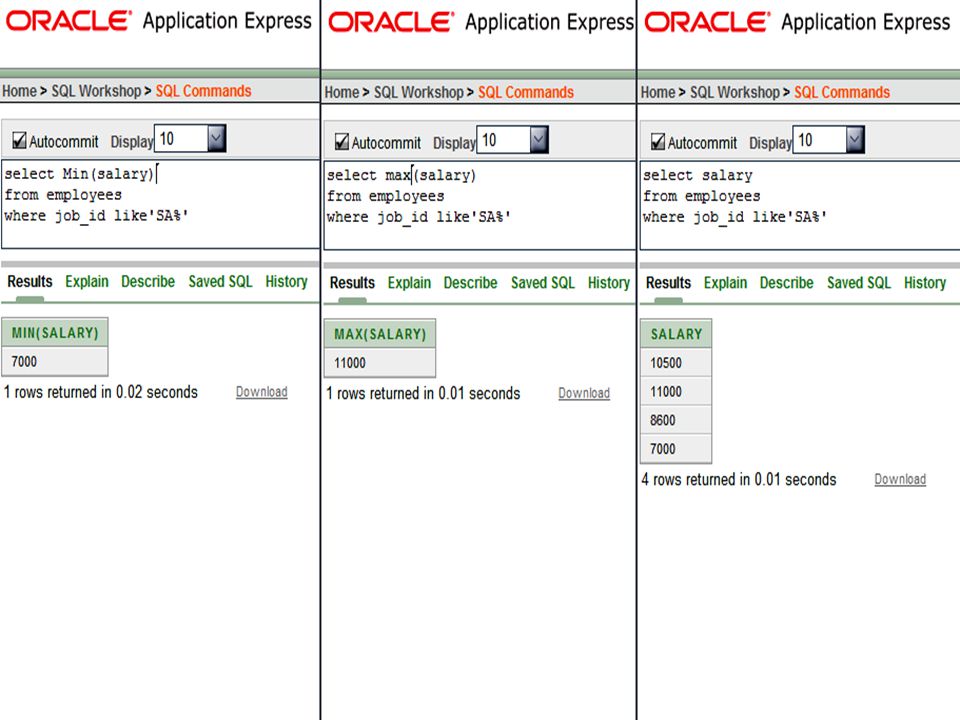
You can have more than one group function in the SELECT clause, on the same or different columns.
You can also restrict the group function to a subset of the table using a WHERE clause. SELECT MAX(salary), MIN(salary), MIN(employee_id) FROM employees WHERE department_id = 60;
, MIN(salary), MIN(employee_id) FROM employees. WHERE department_id = 60;")
21
19 rows exists in employees table from which only 7 are distinct (not repeated)
")
24
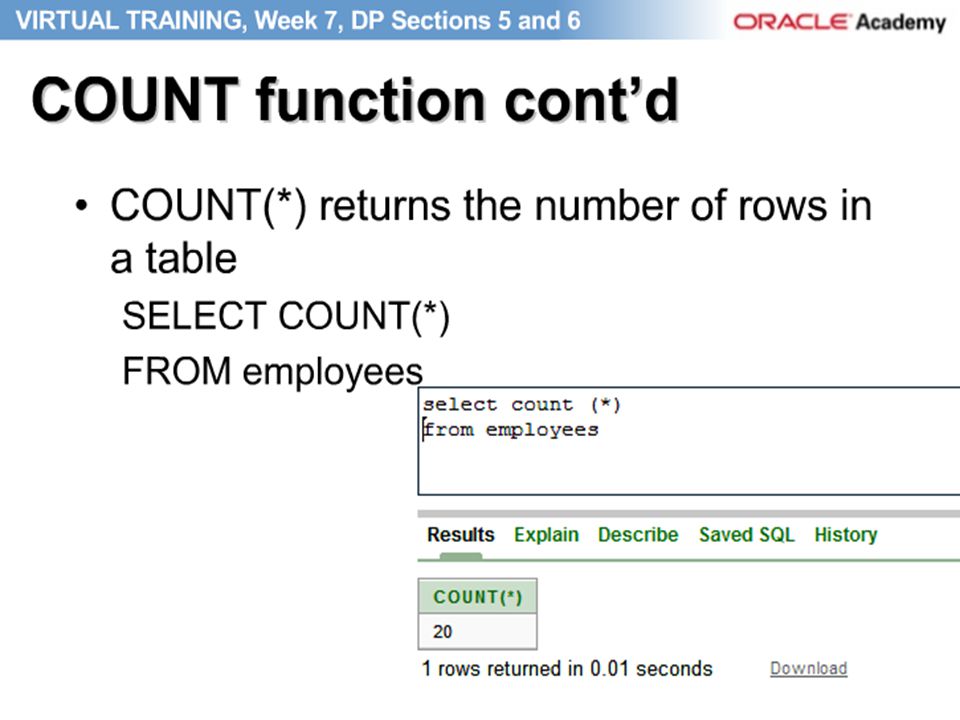
Number of rows in employees table 20 rows while the group function returns 4 rows that is not null values

28
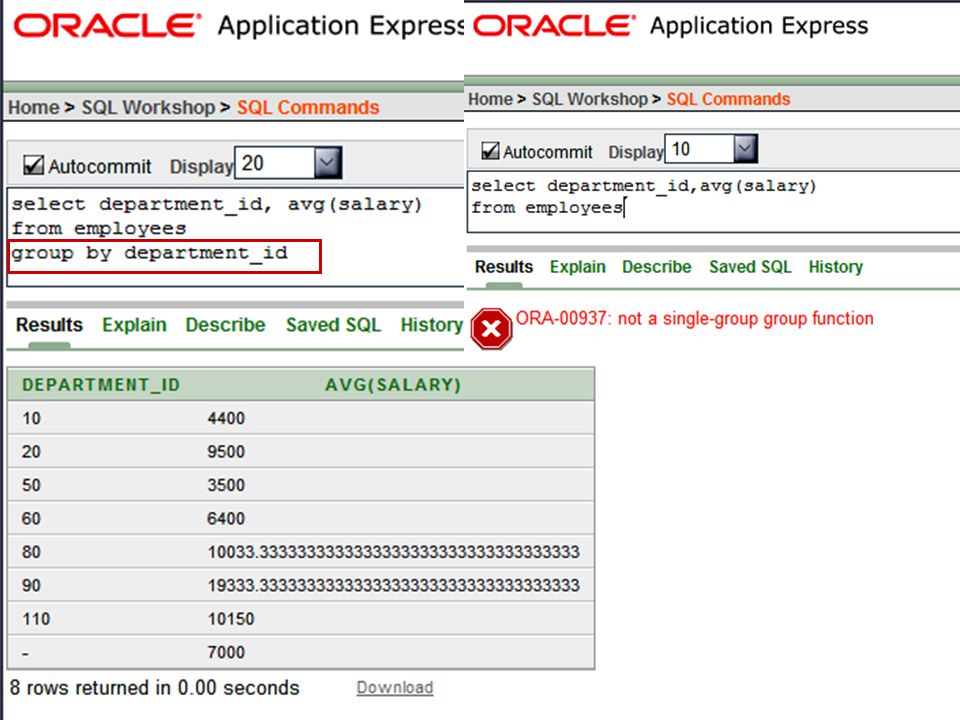
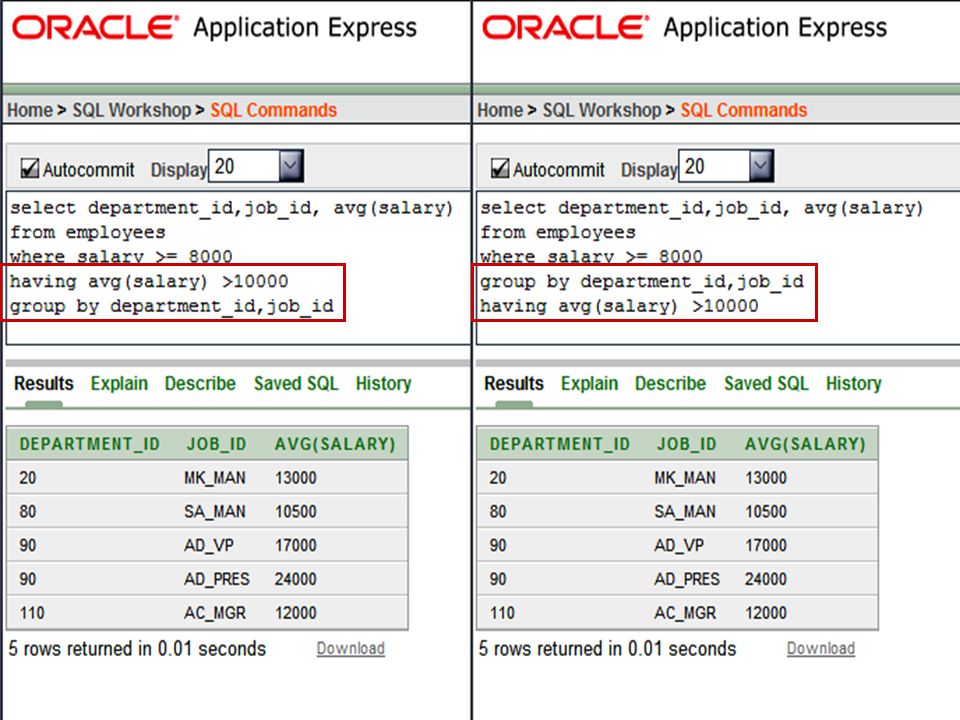
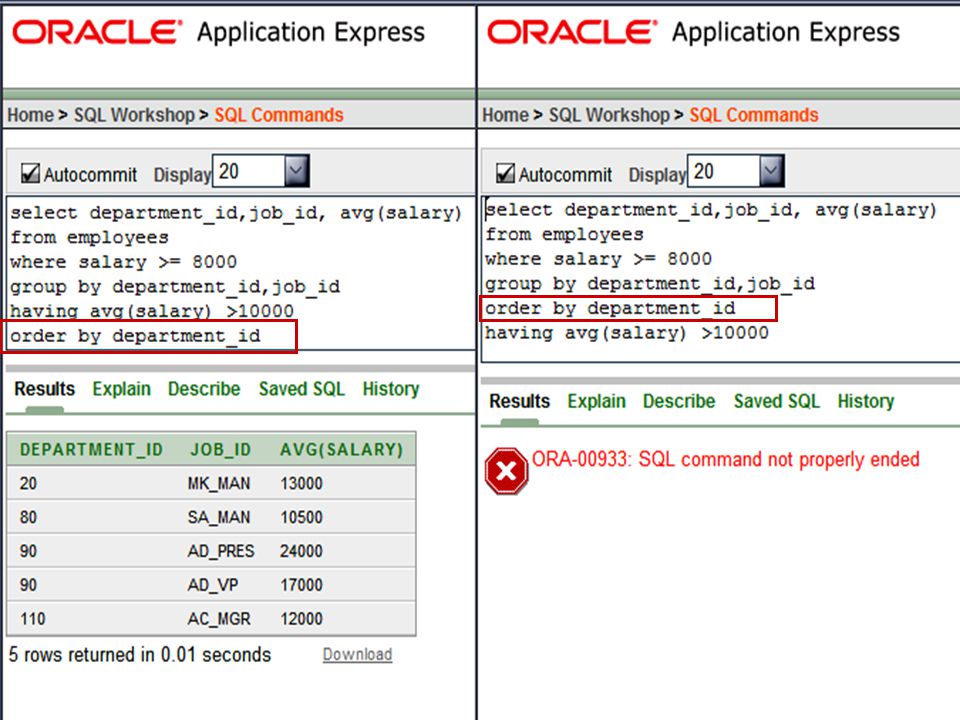
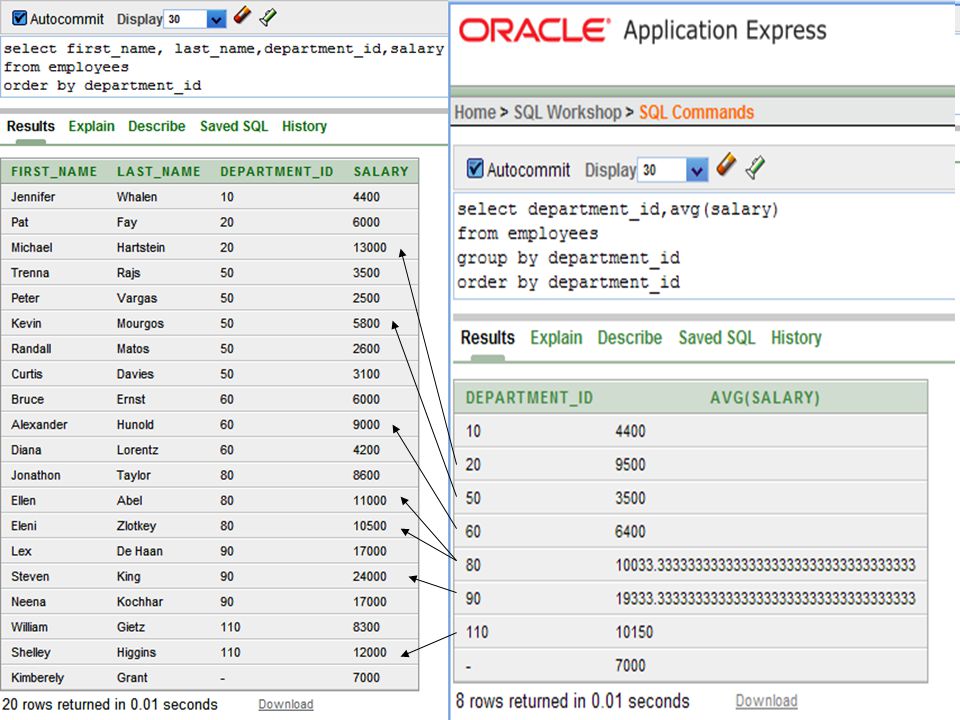
GROUP BY Guidelines Important guidelines to remember when using a GROUP BY clause are: If you include a group function (AVG, SUM, COUNT, MAX, MIN, STDDEV, VARIANCE) in a SELECT clause and any other individual columns, each individual column must also appear in the GROUP BY clause. You cannot use a column alias in the GROUP BY clause. The WHERE clause excludes rows before they are divided into groups.
 in a SELECT clause and any other individual columns, each individual column must also appear in the GROUP BY clause. You cannot use a column alias in the GROUP BY clause. The WHERE clause excludes rows before they are divided into groups.")
29
All column in select clause must be included in group by clause

30
NESTING GROUP FUNCTIONS
Group functions can be nested to a depth of two when GROUP BY is used. SELECT max(avg(salary)) FROM employees GROUP by department_id; How many values will be returned by this query? The answer is one – the query will find the average salary for eachdepartment, and then from that list, select the single largest value.
) FROM employees. GROUP by department_id; How many values will be returned by this query The answer is one – the query will find the average salary for eachdepartment, and then from that list, select the single largest value.")
37
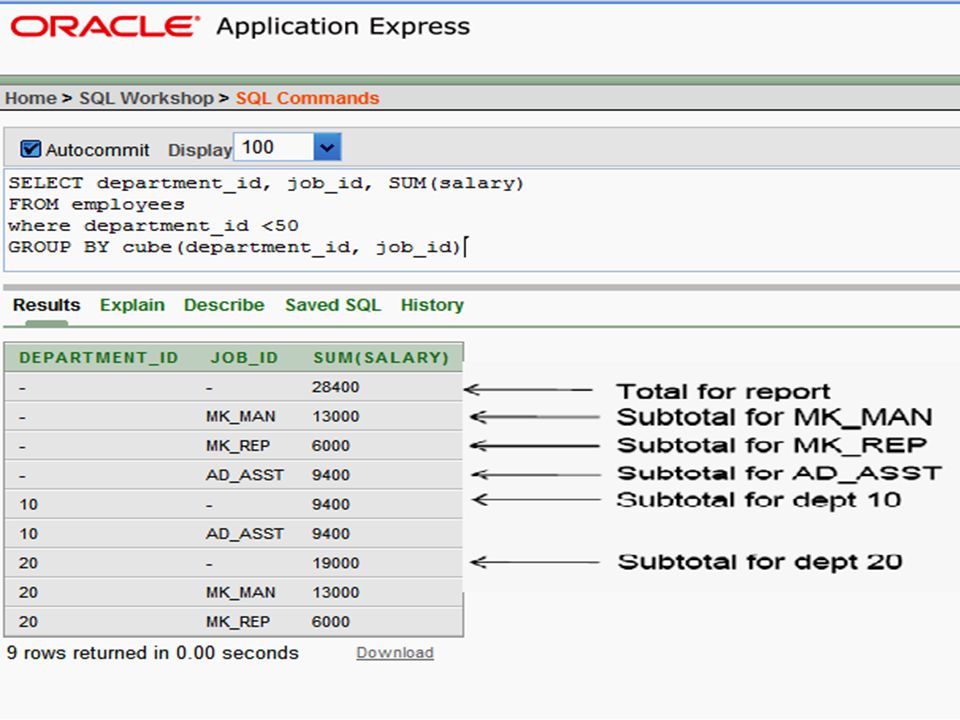
ROLLUP In GROUP BY queries you are quite often required to produce subtotals and totals, and the ROLLUP operation can do that for you. The action of ROLLUP is straightforward: it creates subtotals that roll up from the most detailed level to a grand total, following a grouping list specified in the ROLLUP clause. ROLLUP takes as its argument an ordered list of grouping columns. First, it calculates the standard aggregate values specified in the GROUP BY clause. Then, it creates progressively higher-level subtotals, moving from right to left through the list of grouping columns. Finally, it creates a grand total.

38
Rollup for total departments
Rollup for department 10 Rollup for department 20 Rollup for department 50 Rollup for department 60 Rollup for department 80 Rollup for total departments in query Rollup for department 90

39
SELECT department_id, job_id, SUM(salary) FROM employees
CUBE CUBE is an extension to the GROUP BY clause like ROLLUP. It produces cross-tabulation reports. It can be applied to all aggregate functions including AVG, SUM, MIN, MAX and COUNT. CUBE In the following statement the rows in red are generated by the CUBE operation: SELECT department_id, job_id, SUM(salary) FROM employees WHERE department_id < 50 GROUP BY CUBE (department_id, job_id)
 FROM employees. WHERE department_id < 50. GROUP BY CUBE (department_id, job_id)")
42
GROUPING SETS The point of GROUPING SETS is that if you want to see data from the EMPLOYEES table grouped by (department_id, job_id , manager_id), but also by (department_id, manager_id) and also by (job_id, manager_id) then you would normally have to write 3 different select statements with the only difference being the GROUP BY clauses. For the database this means retrieving the same data in this case 3 times, and that can be quite a big overhead. Imagine if your company had 3,000,000 employees. Then you are asking the database to retrieve 9 million rows instead of just 3 million rows, quite a big difference. So GROUPING SETS are much more efficient when writing complex reports.
, but also by (department_id, manager_id) and also by. (job_id, manager_id) then you would normally have to write 3 different select statements with the only difference being the GROUP BY clauses. For the database this means retrieving the same data in this case 3 times, and that can be quite a big overhead. Imagine if your company had 3,000,000 employees. Then you are asking the database to retrieve 9 million rows instead of just 3 million rows, quite a big difference. So GROUPING SETS are much more efficient when writing complex reports.")
43
GROUPING SETS In the following statement the rows in red are generated by the GROUPING SETS operation: SELECT department_id, job_id, manager_id, SUM(salary) FROM employees WHERE department_id < 50 GROUP BY GROUPING SETS ((job_id, manager_id), (department_id, job_id), (department_id, manager_id))
 FROM employees. WHERE department_id < 50. GROUP BY GROUPING SETS. ((job_id, manager_id), (department_id, job_id), (department_id, manager_id))")
46
Subquary can retrieve data from more than one table

57
IN Compares if value is in the list of all values returned by the subquery.

65
MULTIPLE-COLUMN SUBQUERIES
Subqueries can use one or more columns. A multiple-column subquery can be either pair-wise comparisons or non-pair-wise comparisons. pair-wise comparisons SELECT employee_id, manager_id, department_id FROM employees WHERE (manager_id,department_id) IN (SELECT manager_id,department_id WHERE employee_id IN (149,174)) AND employee_id NOT IN (149,174) The query is listing the employees whose manager and departments are the same as the manager and department of employees 149 or 174.
 IN (SELECT manager_id,department_id. WHERE employee_id IN (149,174)) AND employee_id NOT IN (149,174) The query is listing the employees. whose manager and departments are the same as the manager and. department of employees 149 or 174.")
66
non-pair-wise multiple-column subquery
A non-pair-wise multiple-column subquery also uses more than one column in the subquery, but it compares them one at a time, so the comparisons take place in different subqueries. You will need to write one subquery per column you want to compare against when performing non-pair-wise multiple column subqueries. SELECT employee_id, manager_id, department_id FROM employees WHERE manager_id IN (SELECT manager_id WHERE employee_id IN (174,199)) AND department_id IN (SELECT department_id AND employee_id NOT IN(174,199);
) AND department_id IN. (SELECT department_id. AND employee_id NOT IN(174,199);")
67
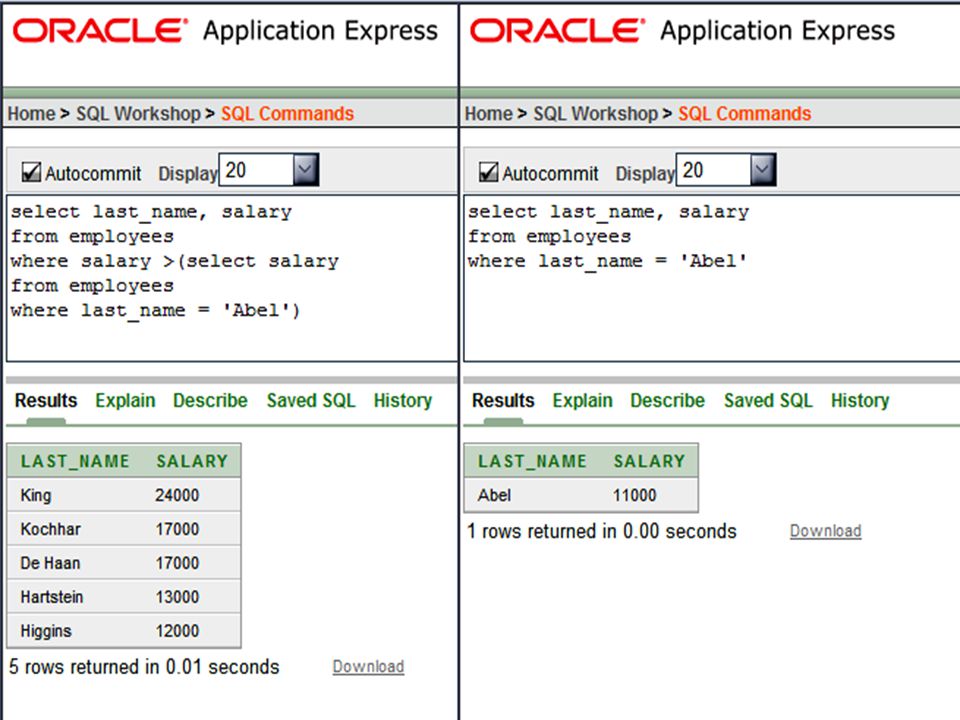
Correlated Subqueries
The Oracle server performs a correlated subquery when the subquery references a column from a table referred to in the parent statement. A correlated subquery is evaluated once for each row processed by the parent statement. The parent statement can be a SELECT, UPDATE or DELETE statement. A correlated subquery, however, executes once for each candidate row considered by the outer query. In other words, the inner query is driven by the outer query. The part that makes this example a correlated subquery is marked in red. SELECT o.first_name, o.last_name, o.salary FROM employees o WHERE o.salary > (SELECT AVG(i.salary) FROM employees i WHERE i.department_id = o.department_id);
 FROM employees i. WHERE i.department_id = o.department_id);")
69
Correlated subquery and WITH clause
The WITH clause retrieves the results of one or more query blocks and stores those results for the user who runs the query. The WITH clause improves performance. The WITH clause makes the query easier to read. The with clause is used to write a very complex query with joins and aggregations used many times WITH clause The syntax for the WITH clause is as follows: WITH subquery-name AS (subquery), subquery-name AS (subquery) SELECT column-list FROM {table | subquery-name | view} WHERE condition is true;
, subquery-name AS (subquery) SELECT column-list. FROM {table | subquery-name | view} WHERE condition is true;")
70
WITH dept_costs AS (SELECT d.department_name, SUM(e.salary) AS dept_total FROM employees e JOIN departments d ON e.department_id = d.department_id GROUP BY d.department_name), avg_cost AS (SELECT SUM(dept_total)/COUNT(*) AS dept_avg FROM dept_costs) SELECT * FROM dept_costs WHERE dept_total > (SELECT dept_avg FROM avg_cost) ORDER BY department_name; Display the department name and total salaries for those departments whose total salary is greater than the average salary across departments.
, avg_cost. AS (SELECT SUM(dept_total)/COUNT(*) AS dept_avg. FROM dept_costs) SELECT * FROM dept_costs. WHERE dept_total > (SELECT dept_avg. FROM avg_cost) ORDER BY department_name; Display the department name and total salaries for those departments whose total salary is greater than the average salary across departments.")
71
SET Operators Set operators are used to combine the results from different SELECT statements into one single result output. SET operators can return the rows found in both statements, the rows that are in one table and not the other, or the rows common to both statements.

72
Guidelines for set operators
•The number of columns and the data types of the columns being selected by the SELECT statements in the queries, must be identical in all the SELECT statements used in the query. •The names of the columns need not be identical. •Column names in the output are taken from the column names in the first SELECT statement. So any column aliases should be entered in the first statement as you would want to see them in the finished report.

73
the following two lists will be used throughout this lesson:
A = {1, 2, 3, 4, 5} B = {4, 5, 6, 7, 8} Or in reality: two tables, one called A and one called B. UNION The UNION operator returns all rows from both tables, after eliminating duplicates. SELECT a_id FROM a UNION SELECT b_id FROM b; The result of listing all elements in A and B eliminating duplicates is {1, 2, 3, 4, 5, 6, 7, 8}. If you joined A and B you would get only {4, 5}. You would have to perform a full outer join to get the same list as above. (similar to full outer join)
")
74
UNION ALL The UNION ALL operator returns all rows from both
tables, without eliminating duplicates. SELECT a_id FROM a UNION ALL SELECT b_id FROM b; The result of listing all elements in A and B without eliminating duplicates is {1, 2, 3, 4, 5, 4, 5, 6, 7, 8}. Observe the difference between UNION and UNION ALL

75
INTERSECT The INTERSECT operator returns all rows common to both tables. SELECT a_id FROM a INTERSECT SELECT b_id FROM b; The result of listing all elements found in both A and B is {4, 5}.

76
MINUS The MINUS operator returns all rows found in one
table but not the other. SELECT a_id FROM a MINUS SELECT b_id FROM b; The result of listing all elements found in A but not B is {1, 2, 3}, and B MINUS A would give {6, 7, 8}.

77
TO_CHAR(null) – matching the select list
SELECT location_id, department_name "Department", TO_CHAR(NULL) "Warehouse" FROM departments UNION SELECT location_id, TO_CHAR(NULL) "Department", warehouse_name FROM warehouses; This query will SELECT the location_id and the department_name from the departments table and it includes a reference to a NULL value as a “stand-in” for a column in the warehouses table. The column in the warehouses table is a varchar2 column, to a call to the TO_CHAR function is used to ensure the datatypes of all columns in the two statements match. A similar reference has been made to a column in the SELECT from warehouses clause. The result can be seen on the next slide.
 Warehouse FROM departments. UNION. SELECT location_id, TO_CHAR(NULL) Department , warehouse_name. FROM warehouses; This query will SELECT the location_id and the department_name from the. departments table and it includes a reference to a NULL value as a stand-in for a column in the warehouses table. The column in the warehouses table is. a varchar2 column, to a call to the TO_CHAR function is used to ensure the. datatypes of all columns in the two statements match. A similar reference has. been made to a column in the SELECT from warehouses clause. The result. can be seen on the next slide.")
78
SELECT location_id, department_name "Department", TO_CHAR(NULL) "Warehouse"
FROM departments UNION SELECT location_id, TO_CHAR(NULL) "Department", warehouse_name FROM warehouses;
 Department , warehouse_name. FROM warehouses;")
79
SEE YOU NEXT MEETING Raafat Rashad GOOD LUCK raafat_rashad@yahoo.co.uk

Similar presentations