Download presentation
Presentation is loading. Please wait.

1
261446 Information Systems Dr. Ken Cosh Lecture 8

2
Key Information Systems ERP SCM CRM What are the 2 objectives? What are the gaps in expectations? Online vs Offline Customer Service 5P’s of Online Customer Service?

3
Decision Support & Artificial Intelligence Brainpower for your Business We’ve discussed Databases Good Data -> Good Information -> Better Decisions -> Competitive Advantage

4
Structured Decisions No ‘feel’ or intuition; Given a set of inputs the ‘right’ decision can be calculated. Unstructured Decisions There could be many ‘right’ answers, and no precise way to select the best

5
Recurring Decisions that need to be made each week or month. Non-Recurring Or Ad hoc. Infrequent or perhaps a one off decision.

6
“Satisfied” & “Sufficient” A choice which meets your needs & is satisfactory without necessarily being the best possible choice. Example Goals: Fair Price Reasonable Profit High Growth (rather than ‘maximum growth’)
.")
7
Insurance company investigates risk exposure when insuring drivers with history of DUI. DSS revealed that married male homeowners in their 40s were rarely repeat offenders – an opportunity to increase market share without increasing risk exposure. A railroad company tests rails to prevent derailments, and uses a DSS to schedule rail testing – reducing its rail caused accidents without increasing costs.

8
Agents act within an environment Some agents perform better than others, which suggests rationality; A rational agent is one that can behave as well as possible. Some environments are more complicated than others, so some agents can naturally be more successful that others.

9
An agent is anything which perceives its environment and acts upon it. Perception is through sensors Action is through actuators Special agent 007 perceives using eyes, ears etc. and acts using arms, guns etc. An automated agent perceives using a camera or temperature monitor and acts using motors or sending network packets.

10
A percept is any inputs received by the agent at any given instant. Hence a percept sequence is a sequence of percepts over time. Generally agents should use their entire percept sequence (complete history of anything the agent has perceived) to make a choice between actions. How do you feel about this?
 to make a choice between actions. How do you feel about this .")
11
A ‘simple’ intelligent agent! There is a problem in Vacuum Cleaner World…. This calls for Vacuum Cleaner Man. Vacuum cleaner world has 2 locations; ‘A’ and ‘B’ - the locations can sometimes be dirty. Vacuum cleaner man can perceive whether he is in location A or location B, and whether the location is dirty or not. Vacuum cleaner man can choose whether to suck dirt, move left, move right or do nothing.

12
AB

13
A simple agent function could be; “If the current square is dirty, suck! Otherwise move to the other square.” Is this a good function? Or bad? Is it an intelligent function? Or stupid?

14
A rational agent should do the right thing every time - when the right thing will cause the agent to be successful. Ergo, we need a way of measuring success, i.e. we need some criteria for what is considered successful. So what is success for Vacuum Cleaner Man?

15
A performance measure is a test for an agents success. We could use a subjective measure - asking the agent how well they ‘think’ they’ve done, but they might be delusional. Instead we use a objective measure imposed by the agent designer. A performance measure for Vacuum Cleaner Man could be “The amount of dirt cleaned in an 8 hour shift” Is this good?

16
Vacuum Cleaner Man could simply clean up dirt and then dump it on the floor again, in order to maximise its performance. As a rule it is better to design a performance measure based on what one wants in an environment, rather than according to how you expect the agent to act. I.e. a more suitable performance measure could be the number of clean squares at each time interval.

17
It is often hard to set performance measures, as even this measure is based on average cleanliness over time. Which is better between: A mediocre agent who works all the time. An energetic agent who takes long breaks. This question really has big implications, compare it to a reckless life of highs and lows vs a safe but boring existence? An economy where everyone lives in moderate poverty, or where some are really rich and others really poor.

18
To decide what is rational at any given point an agent needs to know; The performance measure which defines its success. An agents prior knowledge of the environment (if it is unknown a certain amount of exploration is needed) The actions an agent can perform. The percept sequence to date.
 The actions an agent can perform. The percept sequence to date..")
19
Its worth clarifying that agents aren’t expected to be Omniscient - that would be impossible. As intelligent humans we make mistakes even if we act in an entirely rational manner. Indeed we normally decide on our own actions based on our own percept sequences. Even as intelligent humans there are things beyond our control or knowledge - unexpected interrupts. Rationality maximises expected performance, perfection maximises actual performance.

20
It is rare for an environment to be entirely known when the agent is being designed - such as in the limited vacuum cleaner example. When an agent is initially dumped in an environment, it often (intentionally or not) performs some actions in order to modify future percepts. By this definition an agent would then learn from the things it perceives.
 performs some actions in order to modify future percepts. By this definition an agent would then learn from the things it perceives..")
21
A successful rational agent should learn about its environment to improve its behaviour. An agents computation thus occurs at 3 levels; First, when the agent is designed, the designer performs some. Second, when deciding on its next action the agent performs some. Third, when the agent learns from experience to modify its behaviour.

22
The ability to learn sets us, and intelligent agents apart from many low intelligent species. Many species with limited intelligence are unable to learn. A dung beetle picks up a dung ball, carries it to the entrance of its nest and then plugs the hole. If the dung ball is taken from it while on route to the entrance, it continues attempting to plug the hole. An agent which relies on prior knowledge and doesn’t learn from its percepts lacks autonomy.

23
A rational agent should be autonomous. If Vacuum Cleaner Man can learn to foresee where dirt might appear is more successful. However, autonomy needn’t exist from the start. The designer needs to install some existing knowledge of the environment, otherwise the agent would just act randomly.

24
Before moving on to examine how to design agents, lets investigate further the types of environment in which the agent might work.

25
Can the agents sensors gain access to the state of the entire environment at any given point in time? An environment where the agent can observe all relevant aspects in the environment is effectively fully observable too. Vacuum Cleaner Man can only detect dirt in the square he is occupying, I.e. partially observable.

26
An environment is deterministic if its subsequent state is entirely dependent on the current state and the actions of the agent. Stochastic environments are where aspects of the environment can be changed by external influences. An environment which is deterministic except for the actions of other agents is strategic.

27
Episodic environments are where each decision is unaffected by previous decisions, choices must depend solely on the current episode. Examining defects on a production line is episodic, while playing chess is sequential Episodic environments are simpler than sequential, as agents don’t need to plan or think ahead.

28
A dynamic environment is an environment that can change while the agent is making a decision. A static environment waits for the agent to act. In a semidynamic environment the environment doesn’t change while the agent makes a decision, but the agents performance might - for instance where the agent is under time pressure

29
Percepts can be discrete or continuous, actions can be discrete or continuous and the state of the environment could be discrete or continuous. In discrete state environments there are a limited number of actions (for example), in opposed to a continuous range of possibilities.
, in opposed to a continuous range of possibilities..")
30
Obviously a single agent environment is one in which only one agent exists. But for multi agent environments what is considered an agent, and what is a stochastically behaving object? Is the dirt appearing in Vacuum World an agent or not? A competitive multiagent environment is where maximising one agents performance minimises anothers. A cooperative multiagent environment is where maximising one agents performance enhances the performance of another - like avoiding collisions when driving.

31
Examine these environments; Chess with a clock Medical Diagnosis The hardest case would be a partially observable, stochastic, sequential, dynamic, continuous and multiagent. Most real situations need to be treated as stochastic rather than deterministic - why?

32
Agents need to map certain actions onto appropriate percepts. That is initiate appropriate actuators in response to sensor input. Ergo, a simple agent program could involve table look up. Take readings from the sensors and look up the appropriate response. This simple agent structure would do exactly what we require, but, Chess exists in a tiny, well behaved world with known limits, yet the lookup table for chess would need to have 10 150 entries!

33
So, there is a need to translate massive look up tables into short lines of code; there is an analogy of moving from large square root look up tables to 5 lines of code running on a calculator. So, next lets examine 4 basic kinds of agent program; Simple reflex agents Model based reflex agents Goal based agents Utility based agents

34
A simple reflex agent bases actions on the current input only - ignoring the percept sequence. This leads to reflex reactions - if car in front is braking, then brake! The agent code here is simple, but of very limited intelligence. If the environment is not entirely observable in a single instance, decisions can be weak - what if the car in front puts its lights on - is that distinguishable from braking? Infinite loops are also often unavoidable.

35
A model based reflex agent extends the simple reflex agent, by encoding a model of the environment it exists in. For parts of the environment which are unobservable, a model is built based on what is known both about how the environment should be and information gathered from the percept sequence. In this case the new percept is used in a function to update the state of the environment. The agent then reviews this state and its rules to make a decision, rather than just reviewing the new percept.

36
Goal based agents add a further parameter to their decision algorithm - the goal. Whereas reflex agents just react to existing states, goal based agents consider their objectives and how best to move to wards achieving them. Hence a goal based agent uses searching and planning to construct a future, desired state. When the brake lights of the car in front go on, the agent would surmise that in normal environments the car in front will slow down, it would then decide that the best way of achieving its goal (getting to point B) would be to not hit the car in front, and hence decide braking was a good idea.
 would be to not hit the car in front, and hence decide braking was a good idea..")
37
Goals are crude objectives - often a binary distinction between happy and unhappy. Life is more complex than that, so utility attempts to create a better model of success. The car can get to its destination in many ways, through many routes, but some are quicker, safer, more reliable or cheaper than others. Utility creates a model whereby these performance measures are quantified. The car could brake behind the car in front, or it could overtake - one option is quicker, and one option is safer!

38
The agents discussed so far are preprogrammed - given the constraints of the environment, their objectives and the mapping of how to achieve them. A further subset of agents, learning agents, can be set loose in an initially unknown environment and work out their own way of achieving success.

39
Two suspects, A and B, are arrested by the police. The police have insufficient evidence for a conviction, and, having separated both prisoners, visit each of them to offer the same deal: if one testifies for the prosecution against the other and the other remains silent, the betrayer goes free and the silent accomplice receives the full 10-year sentence. If both stay silent, the police can sentence both prisoners to only six months in jail for a minor charge. If each betrays the other, each will receive a two-year sentence. Each prisoner must make the choice of whether to betray the other or to remain silent. However, neither prisoner knows for sure what choice the other prisoner will make. So the question this dilemma poses is: What will happen? How will the prisoners act ?

41
Suppose we need to check in at the airport and need to choose a time to set off. Plan A 60 involves leaving 60 minutes before check-in - we could assume this was a good plan. We can’t say “Plan A 60 will get us to the airport in time”, only “Plan A 60 will get us to the airport in time so long as we have enough gas, and there are no accidents, and the car doesn’t break down, and check-in doesn’t close early, and…” Perhaps Plan B 90 would be better?

42
While Plan B 90 increases the ‘degree of belief’ that we will get to the airport on time, it also introduces a likely long unproductive wait at the airport. To maximise an agents performance, the relative importance of both goals needs to be considered; ‘getting to the airport’ ‘avoiding a long wait’ The rational decision is A 60, but how do we draw that conclusion?

43
Diagnosis is a task aimed at dealing with uncertainty normally using probability theory to construct a degree of belief in various statements. Your car won’t start, so there’s a 80% chance the battery is dead. You’ve got pain in your left calf so there’s a 70% chance you’ve pulled a muscle, and a 2% chance your leg has fallen off. Probability provides a way of summarising the uncertainty that comes from our laziness and ignorance.

44
Probability is based on our percepts of the environment - what we know about the environment. My doctor said golf caused my shoulder injury as soon as he knew I played golf - even though the shoulder injury dates from before I started playing golf. When we pick a card there is a 1/52 chance it is the Ace of Spades, after we look at it, the chance is either 0 or 1. Probabilities can change when more evidence is acquired.

45
Note that while probabilities may change as more evidence is acquired, it is the degree of belief which changes, NOT changes to the actual state of the environment. In a changing environment, similar approaches can be taken with consideration for situations, intervals and events.

46
Utility Theory represents preferences for certain states - the quality of a state being useful; Is it preferable to choose plan C 1440 (leaving for the airport 24 hours early) which has a 99.999% probability of success over plan A 60, which has a 95% probability of success? Given the poor utility of the long wait, perhaps not. Should I stop playing golf to improve my ‘lack of shoulder pain’ utility, and risk lowering my ‘playing golf pleasure’ utility?

47
Decision Theory = Probability Theory + Utility Theory. An agent is rational if they choose the action which yields the highest utility averaged across all possible outcomes of the action. The principle of Maximum Expected Utility (MEU).
..")
48
You’ve just won a tv gameshow… $1,000,000 But do you want to gamble? Toss a coin, if you win you get $3,000,000 – you lose you get $0. Why?

49
A: 80% chance of $4,000 B: 100% chance of $3,000 Why?

50
C: 20% chance of $4,000 D: 25% chance of $3,000 Why?

51
In 1662, French Philosopher Arnauld said; “To judge what one must do to obtain a good or avoid an evil, it is necessary to consider not only the good and the evil in itself, but also the probability that it happens or does not happen: and to view geometrically the proportion that all these things have together.” More recently text move away from ‘good’ and ‘evil’, and talk about utility.

52
Suppose we can calculate the utility of any particular state given a utility function; U(S) In reality this is often cumbersome, but for simplicity lets suppose… Should an agent perform action A, there are a set of different possible outcomes Result i (A). Given the evidence (E), that the agent has about the environment probabilities for each Result can be assigned; P(Result i (A)|Do(A), E)
, that the agent has about the environment probabilities for each Result can be assigned; P(Result i (A)|Do(A), E).")
53
We can then calculate the expected utility for performing that action given the evidence; EU(A|E) = Σ P(Result i (A)|Do(A),E)U(Result i (A)) Maximum Expected Utility (MEU) states that a rational agent should choose the action which maximises the agents expected utility.
 = Σ P(Result i (A)|Do(A),E)U(Result i (A)) Maximum Expected Utility (MEU) states that a rational agent should choose the action which maximises the agents expected utility.")
54
Great! We’ve solved A.I.! All we need to do is calculate the action which is likely to return the maximum expected utility and set our agent loose! Sadly computations are often prohibitive. Knowing the initial state of the world requires perception Computing P(Result i (A)|Do(A),E) requires a complete causal model (NP-Hard reasoning in Bayesian Networks). Computing the Utility of each state (U(Result i (A)) requires searching or planning as an agent can’t assess the utility of a state until it knows where it can go from there.
|Do(A),E) requires a complete causal model (NP-Hard reasoning in Bayesian Networks). Computing the Utility of each state (U(Result i (A)) requires searching or planning as an agent can’t assess the utility of a state until it knows where it can go from there..")
55
Is it the only rational way? Why is maximising average utility so special? Why not minimise the worst possible loss? Couldn’t an agent act rationally by expressing preferences between states without giving them numeric values? Perhaps a rational agent has a preference structure too complex to be captured by a simple number? Why should a suitable utility function exist at all?

56
You’ve just won a tv gameshow… $1,000,000 But do you want to gamble? Toss a coin, if you win you get $3,000,000 – you lose you get $0. (0.5*3,000,000)+(0.5*0) = 1,500,000 (1*1,000,000) = 1,000,000 Hence the Expected Monetary Value (EMV) of gambling is higher – so why not gamble?
+(0.5*0) = 1,500,000 (1*1,000,000) = 1,000,000 Hence the Expected Monetary Value (EMV) of gambling is higher – so why not gamble .")
57
The expected utility of accepting and declining the gamble is not quite that straight forward… The utility of winning your first million is very high, in comparison with winning a million if you are already very rich. EU (Accept) = 0.5U(S k ) +0.5(S k+3,000,000 ) EU (Decline) = U(S k+1,000,000 ) Research has shown that the utility of extra money is actually logarithmic rather than linear. If you already have 500,000,000, then gaining another 1,000,000 is worth almost the same as gaining 3,000,000.
 = 0.5U(S k ) +0.5(S k+3,000,000 ) EU (Decline) = U(S k+1,000,000 ) Research has shown that the utility of extra money is actually logarithmic rather than linear. If you already have 500,000,000, then gaining another 1,000,000 is worth almost the same as gaining 3,000,000..")
58
Interestingly the logarithm curve is repeated below the 0 line. – Someone with 10,000,000 debt might accept a gamble on a coin with 10,000,000 gain or 20,000,000 loss.

59
A: 80% chance of $4,000 C: 20% chance of $4,000 B: 100% chance of $3,000 D: 25% chance of $3,000 So what about these choices? A=(0.8*4000)+(0.2*0)= 3200 B=3000*1 = 3000 C=(0.2*4000)+(0.8*0)=800 D=(0.25*3000)+(0.75*0) = 750 (3200/3000)=(800/750) Proportionally they are the same – so why is B more appealing than A, and C more appealing than D. The answer lies in irrational regret.
+(0.2*0)= 3200 B=3000*1 = 3000 C=(0.2*4000)+(0.8*0)=800 D=(0.25*3000)+(0.75*0) = 750 (3200/3000)=(800/750) Proportionally they are the same – so why is B more appealing than A, and C more appealing than D. The answer lies in irrational regret..")
60
Money is a useful introduction to utility, but often preferences are made over several attributes; For example when siting a new airport, we might consider cost, noise disruption, safety issues etc. For each option we can value each attribute to help us decide which is best.

61
An option is strictly dominated by another if it wins in all categories; If airport location A is cheaper, quieter, and safer than B, then it has strict dominance. A B C D In this deterministic example, B is strictly dominant over A, while C and D are not.

62
Air Traffic Litigation Construction Deaths Noise Cost Airport Site U Ovals are Random Variables Rectangles are Decision Nodes Diamonds are results of Utility Function

63
Agents have a performance element, which is what we have focused on so far; But they often also have a learning element, which can modify the performance element to make better decisions.

64
Learning can be; Supervised Unsupervised or Reinforcement Learning

65
Learning a function from examples of its inputs and corresponding outputs. Either input by a teacher or experimenting between actions and resulting percepts E.g. if you are learning to drive, and I shout ‘stop!’ or you experiment with different stopping distances under different conditions.

66
Learning patterns of inputs without specific outputs. An agent could ‘get a feel’ for good and bad situations without labeling them as such E.g. getting a feel for good or bad traffic days without anyone telling you what they are.

67
A lack of arrival at a desired state under certain actions suggests to the agent they are doing something wrong. Every time you drive over 160kmph you get an expensive bill to repair your car… hmmm.. what are you doing wrong?

68
Used for supervised learning Given a set of inputs and corresponding outputs, derive a function that can be used for future approximation. If we have lots of x and f(x), return h(x) to approximate f(x). Here h stands for hypothesis.
, return h(x) to approximate f(x). Here h stands for hypothesis..")
69
Both are consistent hypotheses, but which one should we choose? Ockham’s razor says to prefer the simplest consistent hypothesis.

70
A straight line approximation hypothesis may be more useful than a complex polynomial.

71
One way of deriving an appropriate hypothesis is to use a decision tree. For example the decision as to whether to wait for a table at a restaurant may depend on several inputs; Alternative Choice? Bar? Fri/Sat? Hungry? No. of Patrons Price Raining? Reservation? Type of Food Wait Estimate. To keep things simple we discretise the continuous variables (No. patrons, price, wait estimate)
.")
72
No. Patrons YESNO NoneSome WaitEstimate? Full NO Alternate?Hungry? YES >60 30-6010-30 <10 Fri/Sat?Reservation?Alternate? YES No Yes Bar?Raining? YES NO No Yes YESNO NoYes YESNO NoYes

73
Obviously if we had to ask all those questions the problem space grows very fast. The key is to build the smallest satisfactory decision tree possible. Sadly this is intractable, so we will make do with building a smallish decision tree. A tree is induced by beginning with a set of example cases.

74
Sample cases for the restaurant domain.

75
First we have to choose a starting variable, how about food type? Type? 1 5 French 6 10 Italian 4 2 8 11 Thai 3 7 12 9 Burger

76
Ah, that’s better! Patrons? 1 5 None 6 10 Some 4 2 8 11 3 7 12 9 Full

77
But how do we make it? Patrons? None Some Full YESNO Hungry? YES NO NoYes Type French Italian Thai Burger NOYES Fri/Sat YESNO NoYes

78
Choose the ‘best’ attribute each time, then where nodes aren’t decided choose the next best attribute… Recurse!

79
ChooseAttribute(attributes, examples) How do you choose the best attribute? ‘Patrons’ isn’t perfect, but it’s ‘fairly good’. ‘Type’ is really useless If perfect = 1, and completely useless = 0, how can we measure really useless and fairly good?

80
The best attribute leads to a shallow decision tree, by dividing the set as best it can, ideally a boolean test which splits positives and negatives perfectly. A suitable measure therefore is the expected amount of information provided by the attribute. Using a complex formula we can measure the amount of information required, and predict the amount of information still required after applying the attribute.

81
A good tree can predict unforeseen circumstances accurately, hence it makes sense to test unforeseen cases on a set of test data; 1) Collect large set of Data 2) Divide into 2 disjoint sets (training and test) 3) Apply the algorithm to training set. 4) Measure the percentage of accurate predictions in the test set. 5) Repeat steps 1-4 for different sizes of sets.
 Measure the percentage of accurate predictions in the test set. 5) Repeat steps 1-4 for different sizes of sets..")
82
Unless you are going to have massive amounts of data the results might not be accurate as the algorithm shouldn’t see test data before acting as it might influence its results.

83
What if more than one case has the same inputs but different outputs? Majority rule? Decision tree is then not 100% consistent. It may choose to use irrelevant information just to divide the two sets, suppose if we added the variable colour of shirt?

84
Missing Data How should we deal with cases where not all data is known? Where should they be classified? Multivalued Attributes What about infinitely valued attributes, such as restaurant name? Continuous values for inputs Should you use discretisation? A split point? Continuous output Consider a formulaic response from regression.

85
Let’s consider getting a bit fuzzier! An expert might say; “The Power transformer is slightly overloaded, but I can keep this load for a while.” Experts have no trouble understanding this, but how can an expert system deal with such vagueness? Such ‘Fuzziness’?

86
Fuzzy Logic is NOT Logic that is Fuzzy, but logic used to describe the fuzziness. Fuzzy Logic is the theory of sets to calibrate vagueness. Fuzzy Logic is based on the idea that all things have degrees; Temperature, Height, Speed, Distance, ‘Chairness’ When does a hill become a mountain?

87
Boolean (conventional) logic enforces sharp distinctions, things are either a member of a set, or a non member. Either 0 or 1. Tom is tall, at 181 cm, while Tim is small at 179cm. But this is due to an arbitrary line drawn in the sand at 180cm.

88
A man who is 181cm is ‘possibly’ tall, perhaps we could say with 0.86% possibility? i.e. it is likely that he is tall. Lukasiewicz, a Polish philosopher, produced work in 1930 which led to this inexact reasoning, or possibility theory.

89
A long line of chairs. At one end is a Chippendale. Next to it is a near Chippendale, so near to being a Chippendale that it is indistinguishable from a Chippendale. And so on with chairs becoming slightly less chairlike, until at the other end there is a log. When does a chair become a log? Well, the % of people who would call each element a chair!

90
00110011 0 0.2 0.4 0.6 0.8 1 Boolean Logic Fuzzy Logic

91
“Fuzzy Logic is determined as a set of mathematical principles for knowledge representation based on degrees of membership rather than on crisp membership of classical binary logic” Lofti Zadeh is Master of fuzzy logic.

92
Q: Does the Cretan philosopher tell the truth when he asserts that ‘All Cretan’s lie’? Boolean Logic: Contradiction! Fuzzy Logic: The philosopher does and does not tell the truth.

93
The barber of a village gives a hair cut only to those who do not cut their hair themselves. Who cuts the barber’s hair? Boolean: Contradiction! Fuzzy Logic: The barber cuts and doesn’t cut his own hair!

94
NameHeightDegree of Membership CrispFuzzy Chris20811.00 Mark20511.00 John19810.98 Tom18110.82 David17900.78 Mike17200.24 Bob16700.15 Steven15800.06 Bill15500.01 Peter15200.00

95
1.0 0.8 0.6 0.4 0.2 0.0 Degree of Membership 150160170180190200210 Height (cm) 1.0 0.8 0.6 0.4 0.2 0.0 Degree of Membership 150160170180190200210 Height (cm)
 Degree of Membership Height (cm)")
96
1.0 0.8 0.6 0.4 0.2 0.0 Degree of Membership 150160170180190200210 Height (cm) Short AverageTall
 Short AverageTall")
97
Language carries with it a set of modifiers which can change the shape of a fuzzy set; for instance what is the relationship between ‘tall’ and ‘very tall’? Some perform ‘concentration’, such as ‘very’ some perform ‘dilation’, such as ‘more or less’ The set of very tall men is different from the set of more or less tall men. How about the difference between the set of slightly hot and the set of moderately hot?

98
1.0 0.8 0.6 0.4 0.2 0.0 Degree of Membership 150160170180190200210 Height (cm) Short AverageTall Very Tall Very Short
 Short AverageTall Very Tall Very Short")
99
So how much is ‘very’? What is the power of the concentration? How about a square; i.e. if Tom has a 0.86 membership of the set ‘tall men’, then he has a 0.86*0.86 = 0.7396 membership of the set ‘very tall men’. Similarly he has 0.86 4 = 0.547 membership of the set ‘very, very tall men’. We can assign the power 3 to ‘extremely’ meaning that Tom has 0.86 3 = 0.6361 membership of the set ‘extremely tall men’.

100
Similarly the dilation modifiers can be made into an equation; ‘More or Less’ is given the formula √, i.e. Tom has √0.86 = 0.9274 membership of the set ‘more or less tall men’.

101
Cantor proposed several operations on traditional sets, but how do they translate to fuzzy sets? Complement Not A A Containment A B Intersection AABB Union

102
Who does not belong to the set? The complement of a set is the opposite of a set. So if we have a set of tall men, the complement is not tall men. With fuzzy logic, if Tom has 0.86 membership of ‘tall men’, then he has 0.14 membership of ‘not tall men’.

103
Which set belongs to other sets? Well, ‘very tall men’ is a subset of ‘tall men’, which in turn is a subset of ‘men’. With fuzzy logic, membership values can change for different sets and subsets.

104
Which elements belong to both sets? We’ve already seen how a man can be a member of ‘tall men’ and ‘average men’, simply by having a membership value for both sets.

105
Which elements belong to either set? Tom belongs to the tall set, so he belongs to the tall or fat set! So, crisp and fuzzy sets hold the same properties, in fact crisp sets can be considered a special case of fuzzy sets.

106
Commutativity A B = B A A B = B A Associativity A ( B C ) = ( A B ) C A ( B C ) = ( A B ) C Distributivity A ( B C ) = ( A B ) ( A C ) A ( B C ) = ( A B ) ( A C ) Idempotency A A = A A A = A
 = ( A B ) C A ( B C ) = ( A B ) C Distributivity A ( B C ) = ( A B ) ( A C ) A ( B C ) = ( A B ) ( A C ) Idempotency A A = A A A = A")
107
Identity A undefined = A A unknown = A A undefined = undefined A unknown = unknown Involution ¬(¬A) = A Transitivity If (A ∈ B) (B ∈ C) then (A ∈ C) De Morgan’s Laws ¬(A B) = ¬A ¬B ¬(A B) = ¬A ¬B
 = A Transitivity If (A ∈ B) (B ∈ C) then (A ∈ C) De Morgan’s Laws ¬(A B) = ¬A ¬B ¬(A B) = ¬A ¬B")
108
The general set rules apply equally to fuzzy sets. The key difference is in degree of membership, while entities are either members or not members for normal sets, they have degrees of membership for fuzzy sets. Set of Prime numbers : 5, 13 etc. Fuzzy set of tall men : degrees of membership.

109
If x is A, then y is B. Where x and y are variables, and A and B are values determined by fuzzy sets. If Speed is >100, Then stopping_distance is long. If Speed is <40, Then stopping_distance is short.

110
If Speed is Fast, then Stopping_Distance is Long. If Speed is Slow, then Stopping_Distance is Short. Here perhaps speed has a numerical range 0-220 kmph, and Stopping_Distance has a numerical range 0-300m, but each has been broken into fuzzy sets (fast/slow) and (long/medium/short).
 and (long/medium/short)..")
111
In classical reasoning, if an antecedent is true, then the consequent is true, but with fuzzy sets; The degree of membership in the antecedent set influences the degree of membership in the consequent set.

112
If Height is Tall, Then Weight is Heavy. From this we can estimate a mans weight dependent on their height. degree of membership 1 1 00 160 180 200 220 24070 80 90 100 110 120 heightweight

113
If Service is Excellent, OR Food is Delicious, then Tip is Generous. If Project_Duration is Long AND Project_Staff is Large AND Project_Fund is Inadequate, then Risk is High. If Temperature is Hot, then Hot_Water is Reduced (AND/OR) Cold_Water is Increased. All of these rules are possible, with a bit more work!
 Cold_Water is Increased. All of these rules are possible, with a bit more work!.")
114
A simple example; 2 Inputs Project_Funding (Fuzzified from crisp percentage input to inadequate, marginal and adequate) Project_Staffing (Fuzzified from crisp percentage input to small and large) 1 Output Risk (high, normal or low)
 Project_Staffing (Fuzzified from crisp percentage input to small and large) 1 Output Risk (high, normal or low)")
115
3 Rules If Project_Funding is Adequate, OR Project_Staffing is Small, Then Risk is Low. If Project_Funding is Marginal AND Project Staffing is Large, Then Risk is Normal. If Project_Funding is Inadequate, Then Risk is High.

116
4 Steps 1) Fuzzification 2) Rule Evaluation 3) Aggregation of Rule Outputs 4) Defuzzification
 Fuzzification 2) Rule Evaluation 3) Aggregation of Rule Outputs 4) Defuzzification")
117
Take crisp inputs and determine their fuzzy set memberships. Normally requires expert judgement. For Example; Project_Funding at 35% has 0.5 membership of inadequate and 0.2 membership of marginal. Project_Staffing at 60% has 0.1 membership of small and 0.7 membership of large.

118
The next step is to apply fuzzy inputs to the rule antecedents. Rule 1: If Project_Funding is Adequate, OR Project_Staffing is Small, Then Risk is Low. P_F is 0 Adequate P_S is 0.1 Small Risk is 0.1 Low.

119
Rule 2: If Project_Funding is Marginal AND Project Staffing is Large, Then Risk is Normal. P_F is 0.2 Marginal P_S is 0.7 Large There is a choice of ways to apply this, but we choose ‘min’. Risk is 0.2 Normal. Rule 3: If Project_Funding is Inadequate, Then Risk is High. P_F is 0.5 Inadequate Risk is 0.5 High.

120
Summary Risk is 0.1 Low. Risk is 0.2 Normal. Risk is 0.5 High. LowNormalHigh 0 10 20 30 40 50 60 70 80 90 100 Risk

121
Calculate the Centre of Gravity. 0 10 20 30 40 50 60 70 80 90 100 Risk ((0+10+20)*0.1+(30+40+50+60)*0.2+(70+80+90+100)*0.5)/0.1+ 0.1+0.1+0.2+0.2+0.2+0.2+0.5+0.5+0.5+0.5 = 67.4 So the project risk is a member of high and normal, but a bigger member of high.
*0.1+( )*0.2+( )*0.5)/ = 67.4 So the project risk is a member of high and normal, but a bigger member of high..")
122
Domain Experts People who know about a domain – we are experts in the University domain. Rule representation We represent what we know about a domain in a set of rules that govern the domain; If XXX then YYY Rules can be Relations, Recommendations, Directives, Strategies or Heuristics.

123
5 key roles; Project Manager Domain Expert Knowledge Engineer Programmer End User

124
A knowledgeable and skilled person capable of solving problems in the specified domain, having the greatest expertise in that domain. This expertise will be captured by the expert system, so they must be able to communicate their knowledge and participate in expert system development. This is the most important role.

125
Someone capable of designing building and testing an expert system. They begin by interviewing the expert to find out how to solve a particular problem. The knowledge engineer is responsible for capturing what reasoning methods are used to handle facts and rules, and then decide how to represent it in the system.

126
Programmer Responsible for coding the domain knowledge in languages such as LISP or Prolog. Project Manager Responsible for keeping the project on track. End User The people who are going to use the system once its complete.

127
Newell and Simon from CMU, developed the production rule system in the early 70’s. Basically humans solve problems by applying their knowledge (or production rules) to specific problem information. Production rules are stored in long term memory, and problem specific information is stored in short term memory.
 to specific problem information. Production rules are stored in long term memory, and problem specific information is stored in short term memory..")
130
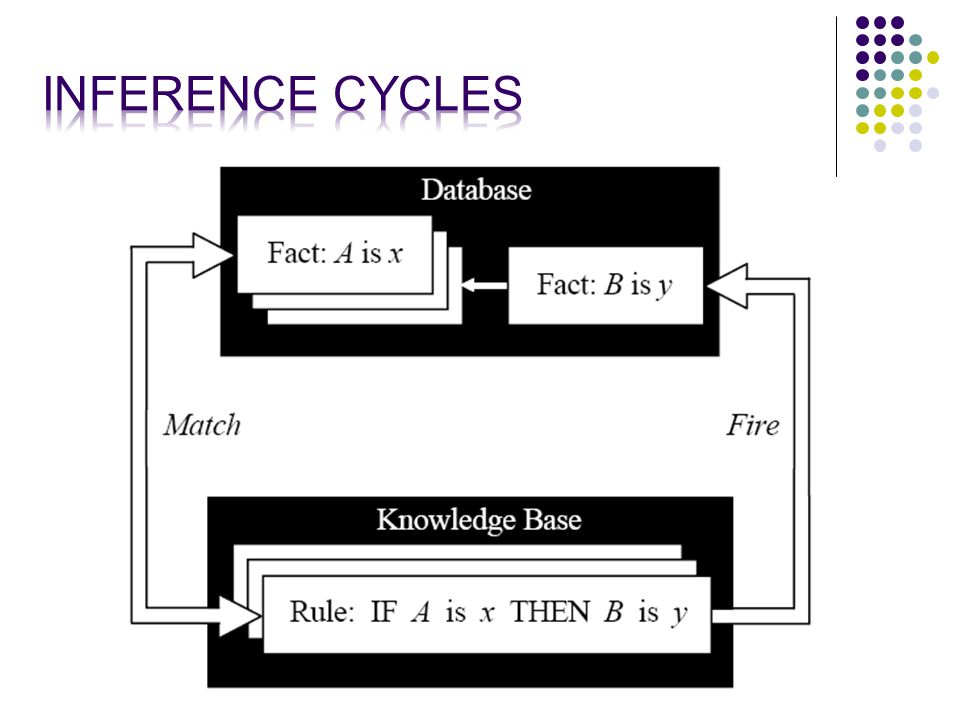
The knowledge base contains the domain knowledge useful for problem solving – represented as rules; Relations, Recommendations, Directives, Strategy, Heuristic. When the conditions of a rule are satisfied then the action part is executed. The database contains the facts which can be matched against the conditions.

131
The inference engine performs this reasoning, as we shall see, to reach as solution, linking rules to facts. The explanation facilities crucially explain how the expert system reached its conclusions, to justify its advice. The user interface is, well a user interface!

132
Expert Systems are designed to perform in the same way as an expert, therefore the primary concern is accuracy – it doesn’t matter how fast the system comes up with a wrong answer! However, in many cases speed of reaching a solution is important – accurate decisions are not that useful if it is too late to apply the decisions.

133
Of course Human Experts are sometimes wrong, and yet we still trust them! Likewise, the expert systems solutions may be wrong, but should we trust it?

136
Often the action part of a rule, creates a new fact to add to the database; If X is good, then Y is bad. This would add ‘Y is bad’ to the facts in the database. This matching can create inference chains, which illustrates how a conclusion is reached.

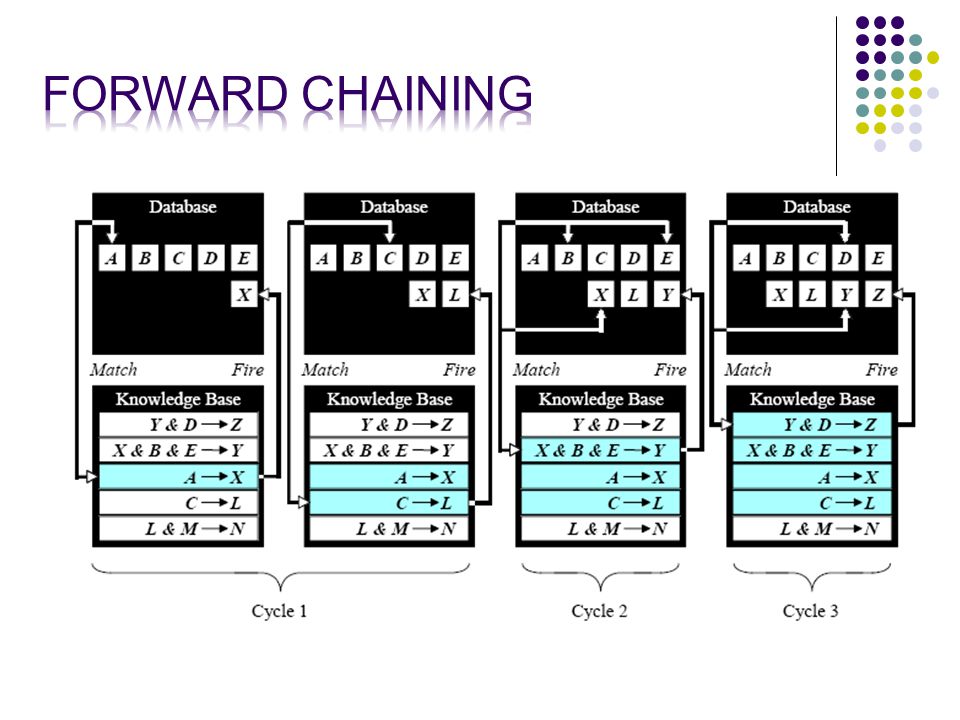
139
Or, “Data Driven Reasoning”. This is where we start from known data and proceed forward. When a rule is fired new info is added to the database, until no further rules can be fired.

141
Technique for gathering information and inferring whatever can be inferred from it. In forward chaining many rules are executed which may have nothing to do with the goal. So if the goal is to infer a particular fact, forward chaining is inefficient.

142
Or “Goal Driven Reasoning” The expert system begins with a goal, and the expert system attempts to find the evidence to prove it. First the knowledge base is searched to find rules that might have the desired solution (the then part), and then rules that can start those are searched for, with each rule being added to a stack.
, and then rules that can start those are searched for, with each rule being added to a stack..")
144
Which is best? Consider if trying to find the murderer on CSI? or the disease on House? or deciding strategy on Survivor?

145
What happens when rules contradict each other? Highest Priority first? Assuming rules can be placed in priority. Most Specific Rule? The longest matching strategy, a specific rule processes more information than a general one, so one with more antecedents is likely to be more useful. Most Recent Rule? The rule which has been fired most recently, i.e. whose antecedent uses the most recently added data.

146
Deciding which strategy to use is stored in the metaknowledge – knowledge about knowledge. And the rule is a metarule. Rules supplied by experts have higher priority than those from novices. Rules governing the rescue of human life have highest priority.

147
Natural Knowledge Representation Everything is stored in easy to read and understand natural language. Uniform Structure The syntax can be used in many different situations. Knowledge / Processing Separation Knowledge is separated from the inference engine, so different systems can be developed from the same knowledge. Incomplete and uncertain knowledge Can easily be dealt with by an expert system.

148
Opaque relations between rules. It is difficult to see how individual rules affect the whole system. Ineffective searching Searches are exhaustive – looking through all rules everytime, which can make it slow. Learning Expert systems can not learn, they can’t decide when to break the rules, or when to add a rule or modify one, as a human expert could.

Similar presentations


























 Lisp: Some questions that came up in lab Resume intelligent agents after Lisp issues.>")