Download presentation
Presentation is loading. Please wait.

1
SPH6004 Advanced Biostatistics Part 1: Bayesian Statistics Chapter 1: Introduction to Bayesian Statistics

2
Golden rule: please stop me to ask questions

3
WeekStartingTuesdayFriday 113 JanAlex[Alex] 220 Jan 327 Jan 43 FebAlex[Alex] 510 FebAlex[Alex] 617 FebAlex[Hyungwon] R24 Feb 73 MarHyungwon 810 MarHyungwon 917 MarHyungwon 1024 MarYY 111 AprYY 127 AprYY
![WeekStartingTuesdayFriday 113 JanAlex[Alex] 220 Jan 327 Jan 43 FebAlex[Alex] 510 FebAlex[Alex] 617 FebAlex[Hyungwon] R24 Feb 73 MarHyungwon 810 MarHyungwon 917 MarHyungwon 1024 MarYY 111 AprYY 127 AprYY](http://images.slideplayer.com/13/3616027/slides/slide_3.jpg "WeekStartingTuesdayFriday 113 JanAlex[Alex] 220 Jan 327 Jan 43 FebAlex[Alex] 510 FebAlex[Alex] 617 FebAlex[Hyungwon] R24 Feb 73 MarHyungwon 810 MarHyungwon 917 MarHyungwon 1024 MarYY 111 AprYY 127 AprYY")
4
WeekStartingTuesdayFriday 113 JanIntroduction to Bayesian statistics Importance sampling 220 Jan 327 Jan 43 FebMarkov chain Monte Carlo JAGS and STAN 510 FebHierarchical modelling Variable selection and model checking 617 FebBayesian inference for mathematical models

5
Objectives ● Describe differences between Bayesian and classical statistics ● Develop appropriate Bayesian solutions to non- standard problems, describe the model, fit it, relate analysis to problem ● Describe differences between computational methods used in Bayesian inference, understand how they work, implement them in a programming language ● Understand modelling and data analytic principles

6
Expectations Know already ● Basic and intermediate statistics ● Likelihood function ● Pick up programming in R ● Generalised linear models ● Able to read notes

9
Why the profundity? ● Bayes' rule is THE way to invert conditional probabilities ● ALL probabilities are conditional ● Bayes' rule therefore provides the 'calculus' to manipulate probability, moving from p(A|B) to p(B|A).
 to p(B|A)..")
11
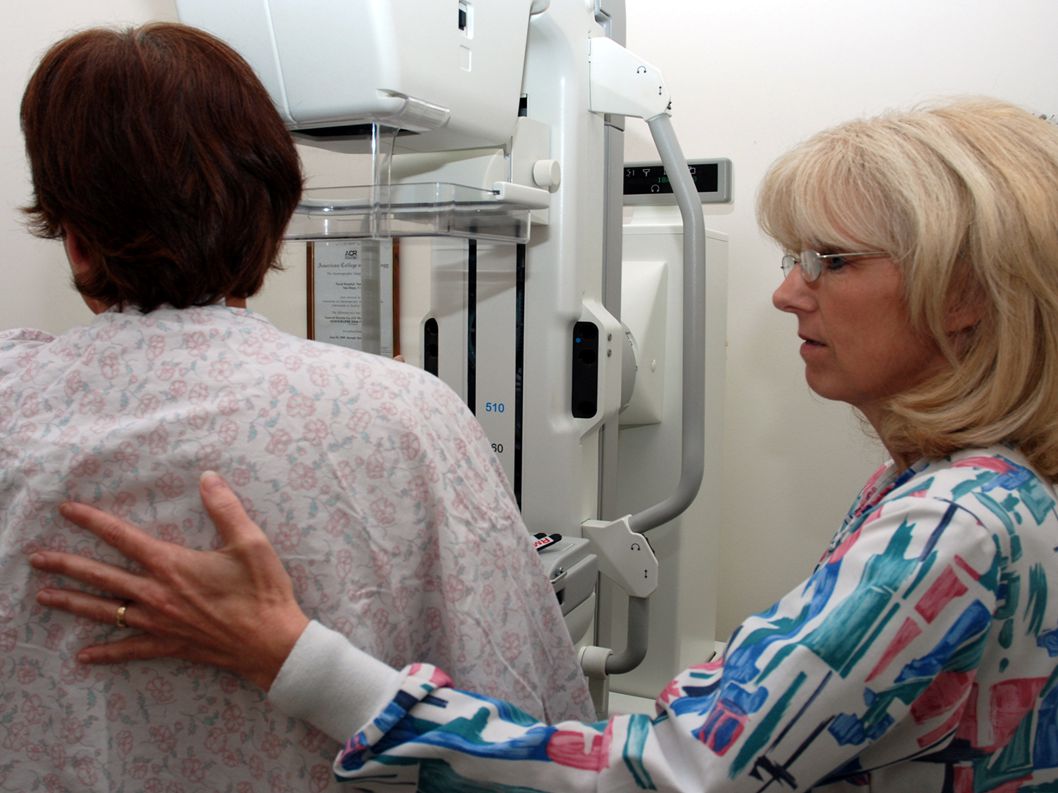
Prof Gerd Gigerenzer The following information is available about asymptomatic women aged 40 to 50 in your region who have mammography screening Imagine you conduct such screening using mammography For early detection of breast cancer, starting at some age, women are encouraged to have routine screening, even if they have no symptoms

12
The probability a woman has breast cancer is 0.8% If she has breast cancer, the probability is 90% that she has a positive mammogram If she does not have breast cancer, the probability is 7% that she still has a positive mammogram The probability a woman has breast cancer is 0.8% If she has breast cancer, the probability is 90% that she has a positive mammogram If she does not have breast cancer, the probability is 7% that she still has a positive mammogram The challenge: Imagine a woman who has a positive mammogram What is the probability she actually has breast cancer? The challenge: Imagine a woman who has a positive mammogram What is the probability she actually has breast cancer?

13
Their answers... I never inform my patients about statistical data. I would tell the patient that mammography is not so exact, and I would in any case perform a biopsy.

14
The probability a woman has breast cancer is 0.8% If she has breast cancer, the probability is 90% that she has a positive mammogram If she does not have breast cancer, the probability is 7% that she still has a positive mammogram The probability a woman has breast cancer is 0.8% If she has breast cancer, the probability is 90% that she has a positive mammogram If she does not have breast cancer, the probability is 7% that she still has a positive mammogram Can we write the above mathematically? The following information is available about asymptomatic women aged 40 to 50 in your region who have mammography screening

16
p(B = 1 | A = 1)---the probability prior to observing the mammogram p(B = 1 | M = 1, A = 1)---the probability after observing it Bayes’ rule provides the way to update the prior probability to reflect the new information to get the posterior probability (Even the prior is a posterior) Key point 1
---the probability prior to observing the mammogram p(B = 1 | M = 1, A = 1)---the probability after observing it Bayes’ rule provides the way to update the prior probability to reflect the new information to get the posterior probability (Even the prior is a posterior) Key point 1")
17
Key point 2 ● Bayes' rule allows you to switch from – pr(something known | something unknown) ● to – pr(something unknown | something known)
 ● to – pr(something unknown | something known)")
18
Bayesians and frequentists Bayes' rule is used to switch to pr(unknowns|knowns) for all situations in which there is uncertainty including parameter estimation Bayes' rule is only used to make probability statements about events, that in principle could be repeatedly observed Parameter estimation is done using methods that perform well under some arbitrary desiderata, such as being unbiased, and uncertainty is quantified by appealing to large samples
 for all situations in which there is uncertainty including parameter estimation Bayes rule is only used to make probability statements about events, that in principle could be repeatedly observed Parameter estimation is done using methods that perform well under some arbitrary desiderata, such as being unbiased, and uncertainty is quantified by appealing to large samples")
20
The Thai AIDS vaccine trial

22
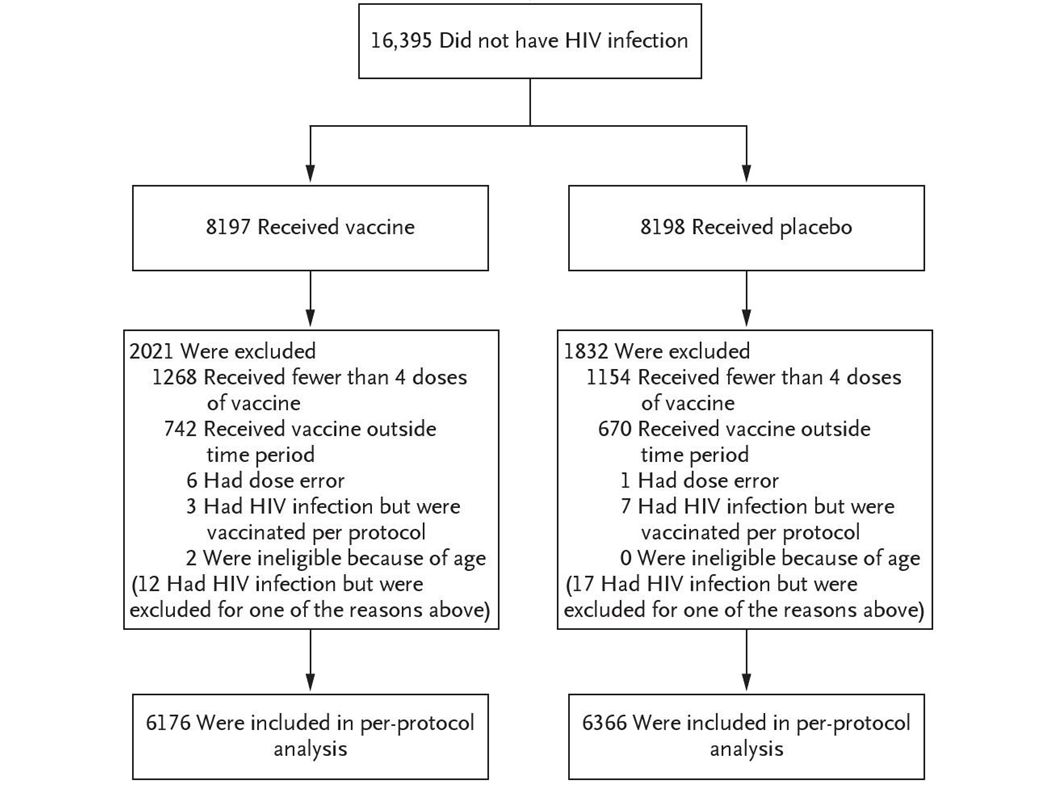
The modified intention to treat analysis Vaccine armPlacebo arm Seroconverted5174 Participated81978198 Q: what is the “underlying” probability p v of infection over this time window for those on the vaccine arm?

23
What does that actually mean? Participants are not randomly selected from the population: they are referred or volunteer Participants must meet eligibility requirements Not representative of Thai population Risk of infection different in Thailand and, eg, Singapore Nebulous: risk of infection in an hypothetical second trial in same group of participants Hope p v /p u has some relevance in other settings

24
Model for data Seems appropriate to assume X v ~ Bin(N v,p v ) X v = 51 = number vaccinees infected N v = 8197 = number vaccinees p v = ? Point estimate to summarise the data Interval estimate to summarise uncertainty (later) measure of evidence that the vaccine is effective
 measure of evidence that the vaccine is effective.")
25
Refresher: frequentist approach Traditional approach to estimate p v : – find the value of p v that maximises the probability of the data given that the hypothetical value were the true value – using calculus – numerically (Newton-Raphson, simulated annealing, cross entropy etc) – EITHER CASE use log likelihood
 – EITHER CASE use log likelihood")
26
Refresher: frequentist approach Differentiating wrt argument we want to max over setting derivative to zero, adding hat, solving, gives which is just the empirical proportion infected

27
Refresher: frequentist approach To quantify the uncertainty might take a 95% interval You probably know (involves cheating: assuming you know p v and assuming the same size is close to infinity--- actually there are better equations for small samples)
")
29
Interpretation The maximum likelihood estimate of p v is not the most likely value of p v Classical statisticians cannot make probabilistic statements about parameters Not a 95% chance p v lies in the interval (0.45,0.79)% 95% of such intervals over your lifetime (with no systematic error, small samples) will contain the true value
% 95% of such intervals over your lifetime (with no systematic error, small samples) will contain the true value")
32
Tackling it Bayesianly Target: point and interval estimate Intermediate: probability of the parameter p v given the data X v and N v, ie Likelihood function is same as before What is the prior? posterior for p v likelihood fn prior for p v dummy variable pi

33
What is the prior? There is no the prior There is a prior: you choose it just as you choose a Binomial model for the data It represents information on the parameter (proportion of vaccinees that would be infected) before the data are in hand Perhaps justifiable to assume all probs between [0,1] are equiprobably before data observed
 before the data are in hand Perhaps justifiable to assume all probs between [0,1] are equiprobably before data observed.")
34
What is the prior? 1{A}=1 if A true and 0 if A false N v can be dropped from the condition as I assume sample size and probability of infection are independent

35
What is the posterior? p v on the range (0,1) C a constant Smart way (later) 1 Dumb way (now) 2
 C a constant Smart way (later) 1 Dumb way (now) 2")
36
The dumb way Grid of values for p v, finely spaced, on sensible range Evaluate log posterior +C Transform to posterior ×C Approximate integral by sum over grid Scale to get rid of C exploiting fact that posterior is a pdf and integrates to 1

37
The dumb way

38
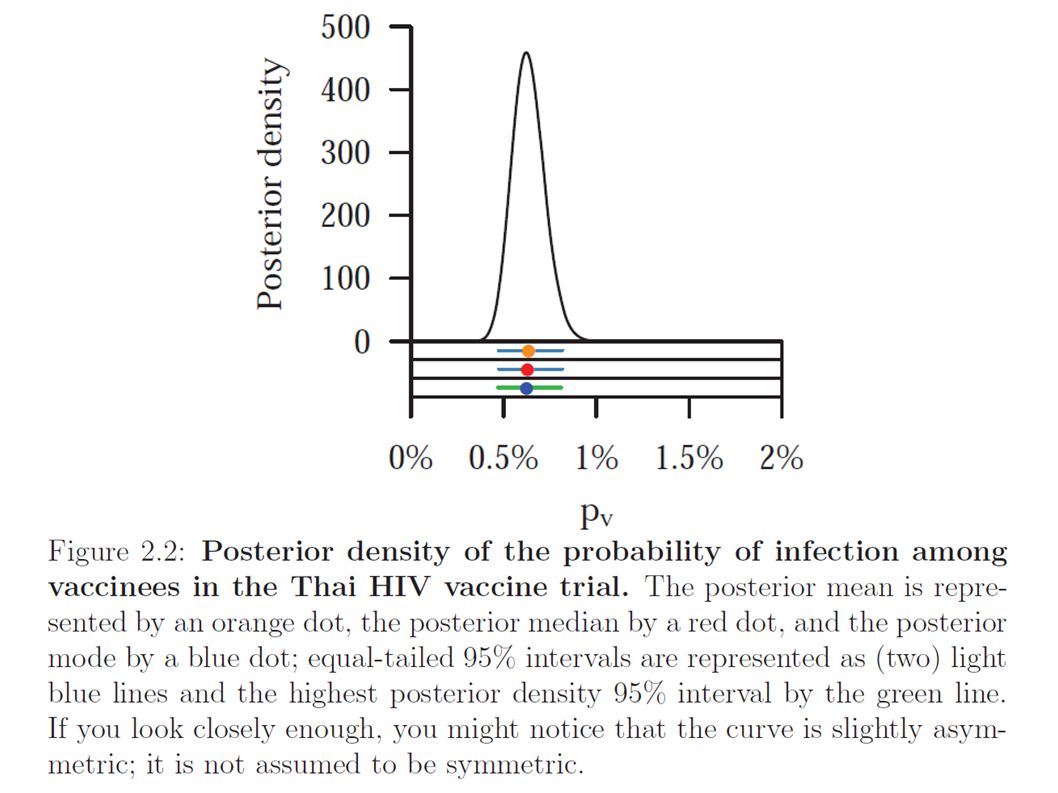
The posterior can take values >1 note asymmetry

39
Point estimates If you have a sample x 1, x 2,... from a distribution, can represent overall location using: – mean – median – mode Similarly can report as point estimate mean, median or mode of posterior

40
In R MethodEstimate Mean0.63% Mode0.63% Median0.62% MLE0.62%

41
Uncertainty Two common methods to get uncertainty interval/credible interval/intervals: – quantiles of the posterior (eg 2.5%ile, 97.5%ile) – highest posterior density interval Since there is a 95% chance if you drew a parameter value from the posterior of it falling in this interval, the interpretation is how many people think of confidence intervals
 – highest posterior density interval Since there is a 95% chance if you drew a parameter value from the posterior of it falling in this interval, the interpretation is how many people think of confidence intervals")
42
Highest posterior density intervals

43
In R (0.47,0.82)% (0.47,0.81)% (0.45,0.79)%
% (0.47,0.81)% (0.45,0.79)%")
45
Important points In some situations it doesn’t really matter if you do a Bayesian or a classical analysis as the results are effectively the same – sample size is large, asymptotic theory justified – no prior/external information for analysis – someone has already developed a classical routine In other situations, Bayesian methods come into their own!

46
Philosophical points If you really love frequentism and hate Bayesianism, you can pragmatically use Bayesian approaches and interpret them like classical ones If vice versa, you can – use classical estimates from literature as if Bayesian – arguably interpret classical point/interval estimates the way you want to

48
Priors and posteriors A prior probability of BC reflects the information you have before observing the mammogram: all you know is the risk class the patient sits in The posterior probability of BC reflects the information after observing the mammogram A prior probability density function for p v reflects the information you have before the study results are known The posterior probability density function reflects the information after the study, including anything known before and everything from the study itself How much knowledge, how much uncertainty

49
Justification Statistician, Ms A, is analysing some data. She comes up with a model for the data based on some simplifying assumptions. She must justify this choice if others are to believe her Bayesian statistician, Mr B, is analysing some data. He must come up with a model for the data and for the parameters. He too must justify his choice. For instance, Ms A wants to do a logistic regression on the following data outcome:got infected by H1N1 as measured by serology predictors:age, gender, recent overseas travel, number of children in household,... There is no reason why the effect of age on the risk of infection should be linear in the logit of risk. There is no reason why each predictor’s effect is additive on the logit of risk. There is no reason why individuals should be taken to be independent. These are choices made by the statistician

50
Support Each parameter of a model has a support The prior should match this All a bit silly:

51
Priors for multiple parameters You must specify a joint prior for all parameters, eg p(a,b, σ ) Often easiest to assume the parameters are a priori independent, ie eg p(a,b, σ ) = p(a) p(b) p( σ ) (note this does not force them to be independent a posteriori) But you can incorporate dependency if appropriate, eg if you analyse dataset 1 and use its posterior as a prior for dataset 2
 Often easiest to assume the parameters are a priori independent, ie eg p(a,b, σ ) = p(a) p(b) p( σ ) (note this does not force them to be independent a posteriori) But you can incorporate dependency if appropriate, eg if you analyse dataset 1 and use its posterior as a prior for dataset 2")
52
Aim for this part Look at different classes of priors: – informative, non-informative – proper, improper – conjugate

53
Informative and noninformative priors InformativeNon-informative Encapsulates information beyond that available solely in the data directly at hand For instance, if someone has previously estimated the risk of infection by HIV in Thai adults and reported point and interval estimates, you could take those and convert into an appropriate prior distribution Opposite: a distribution that is flat or approximately flat over the range of parameter values with high likelihood values Eg p v ~ U(0,1) is non-informative as it is flat over the range 0.5-- 1.5% where the data tell you p v should be Eg mu~U(-1000000,1000000) might be non-informative for a parameter on the real line; as might N(0,1000 2 )
 is non-informative as it is flat over the range % where the data tell you p v should be Eg mu~U( , ) might be non-informative for a parameter on the real line; as might N(0, )")
55
When to choose which? Use a non-informative prior if:Use an informative prior if: Your primary data set has so much information in it you can estimate the parameter with no problems Your primary data set doesn’t give enough information to estimate all unknowns well (see next chapter for an example) You only have one data setYou have multiple data sets and can best analyse them one at a time You have no really solid estimates from the literature that you can supplement the information from your primary data You have really good estimates from the literature that everyone accepts You want to approximate a frequentist analysis You are analysing the data for your own benefit, to make a decision, say, and do not need the acceptance of others
 You only have one data setYou have multiple data sets and can best analyse them one at a time You have no really solid estimates from the literature that you can supplement the information from your primary data You have really good estimates from the literature that everyone accepts You want to approximate a frequentist analysis You are analysing the data for your own benefit, to make a decision, say, and do not need the acceptance of others.")
56
Q: I’ve decided I want a non- informative prior. But what form? Parameter support Possible non-informative prior [0,1]U(0,1), Be(1,1), Be(1/2,1/2) Positive part of real line U(0, ∞), U(0,big number), exp(big mean), gamma(big variance?), log N(mean 1, big variance?), truncated N(0, big variance) Real lineU(−∞, ∞), U(−big number, big number), N(0,big variance) Exact choice rarely makes a difference
, Be(1,1), Be(1/2,1/2) Positive part of real line U(0, ∞), U(0,big number), exp(big mean), gamma(big variance ), log N(mean 1, big variance ), truncated N(0, big variance) Real lineU(−∞, ∞), U(−big number, big number), N(0,big variance) Exact choice rarely makes a difference.")
57
Q: I’ve decided I want an informative prior and have found an estimate in the literature. So, how?

58
Aim for this part Look at different classes of priors: – informative, non-informative – proper, improper – conjugate

59
Proper and improper priors Recall: Distributions are supposed to integrate to 1 Prior distributions really should, too A prior that integrates to 1 is proper One that doesn’t is improper p( )
")
60
Proper and improper posteriors An improper posterior is a bad outcome! PriorPosterior Proper ImproperProper Improper

61
Bad likelihoods If the likelihood is ‘badly behaved’ then not only do you need a proper prior, you need an informative prior, as there is insufficient information in the data to estimate that parameter (or those parameters)
")
62
Aim for this part Look at different classes of priors: – informative, non-informative – proper, improper – conjugate

63
Conjugate priors So, with our binomial model, we moved – from a prior for p v that was beta – to a posterior for p v that was beta We therefore say that the beta is conjugate to the binomial

64
( )
")
65
Conjugate priors There are a handful of other data models with conjugate priors May encounter some later in the course Most real problems do not have conjugate priors though If it does, it makes sense to exploit it Eg for the Thai vaccine, once you realise p v is beta a posteriori can summarise the posterior directly

66
Summarising a posterior directly /(2+nv)
")
67
Different kinds of priors Non-informative Informative Improper Proper Conjugate Non-conjugate

68
Different kinds of priors Non-informative Informative Improper Proper Conjugate Non-conjugate

69
Different kinds of priors Non-informative Informative Improper Proper Conjugate Non-conjugate

71
Information to Bayesians prior dataposterior

72
Information to Bayesians prior data 1posterior 1 data 2posterior 2

73
Information to Bayesians prior data 1posterior 1 data 2posterior 2 ?

74
A Gedanken Consider experiments to estimate a probability p given a series of Bernoulli trials, x i, with y i = Σ j=1:i x j Use a Be(α,β) prior for p Experimentor 1, instead of waiting for all the data to come in, recalculates the posterior from scratch based on y i and (α,β) each time a data point comes in Experimentor 2, uses his last posterior and x i to recalculate the posterior
 prior for p Experimentor 1, instead of waiting for all the data to come in, recalculates the posterior from scratch based on y i and (α,β) each time a data point comes in Experimentor 2, uses his last posterior and x i to recalculate the posterior")
75
Experimentor 1

76
Experimentor 2

77
The two experimentors, using the same prior and same data, end with the same posterior Experimentor 1 started afresh each time with the original prior and all data Experimentor 2 updated the old posterior with the new datum

78
Implications If data come to you piecemeal, it doesn’t matter if you analyse them once at the end, or at each intermediate point and update your prior (In practice one or the other may be convenient: eg if posterior is not analytic, makes sense to estimate/approximate once, rather than once per datum) You can always treat an old posterior obtained elsewhere as a prior You can take estimates from the literature and convert them into priors You can always treat an old posterior obtained elsewhere as a prior You can take estimates from the literature and convert them into priors
 You can always treat an old posterior obtained elsewhere as a prior You can take estimates from the literature and convert them into priors You can always treat an old posterior obtained elsewhere as a prior You can take estimates from the literature and convert them into priors")
79
What did we learn in chapter 1? Bayes rule Applied to probability of a state of nature (BC) given evidence (MG) and background risk (age) Refresher on frequentist estimation Estimating a proportion given x, n Saw how Bayes rule could be used to derive posterior probability density of parameter given data Priors Accumulation of evidence
 given evidence (MG) and background risk (age) Refresher on frequentist estimation Estimating a proportion given x, n Saw how Bayes rule could be used to derive posterior probability density of parameter given data Priors Accumulation of evidence.")
80
What did we learn in chapter 1? Don’t know how to do Bayesian inference for problems with >1 parameter! Chapter 2 & 3: computing posteriors Importance sampling Markov chain Monte Carlo

Similar presentations













 is sufficient for >")






 and likelihood ratio (LR) test>")



 and likelihood ratio (LR) test>")



