Download presentation
Presentation is loading. Please wait.

1
1 Greedy Algorithms Bioinformatics Algorithms © Jeff Parker, 2009 Why should I care about posterity? What's posterity ever done for me? - Gourcho Marx

2
2 Question from Last Week What are we supposed to take away from the discussion of Motif Finding? Objectives Understand the Motif Problem Understand Exhaustive Search Understand that some Exhaustive search is less exhausting than others Understand Branch and Bound

3
3 Outline Objectives Understand why we cannot use backtracking Understand what a Greedy Algorithm is Understand use of metrics Understand alternatives – BFS, Best First, and A* search Understand the biological problem Understand some algorithms to reverse sort What is a greedy algorithm? Understand why trying for local optimization can distort things Alternatives to Greed

4
4 Backtracking's Limits Backtracking can solve problems like the knights tour, It is not well suited for the 15 puzzle There is no way to characterize a position as a dead end. However, some positions are more promising than others The problem of sorting also has no dead ends

5
5 Definition of Greedy Algorithm Many algorithms make a sequence of choices among alternatives Sorting – which pair should we exchange? Traveling System – which city should we visit next? Greedy algorithms make a locally optimal choice in hopes that it will make a global optimal choice. That is, they look ahead one move. Sometimes a greedy algorithm is optimal. Often it is not.

6
6 Decision Trees We may have a sequence of decisions to make Should I file the short form or the long form? If I file the long form, should I fill out Schedule C? Note that the tree below is not a data structure: it is an expansion of the logic of an algorithm.

7
7 Example Consider a linear search We can view this as a sequence of decisions In searching an array of N items for item x, there are 2N+1 outcomes: the item should be Before the first Same value as the first After the first, but before the second and so on

8
8 Linear Search Linear_search ( int target, int list []) { for (int pos = 0; pos < MAX; pos++) { if ( target >= list[pos] ) break; } // Sort things out… if (pos < MAX) { if (target == list[pos]) update list[pos]; else insert before list[pos]; } else // pos == MAX insert after list[pos]; }
![8 Linear Search Linear_search ( int target, int list []) { for (int pos = 0; pos < MAX; pos++) { if ( target >= list[pos] ) break; } // Sort things out… if (pos < MAX) { if (target == list[pos]) update list[pos]; else insert before list[pos]; } else // pos == MAX insert after list[pos]; }](http://images.slideplayer.com/12/3553911/slides/slide_8.jpg "8 Linear Search Linear_search ( int target, int list []) { for (int pos = 0; pos < MAX; pos++) { if ( target >= list[pos] ) break; } // Sort things out… if (pos < MAX) { if (target == list[pos]) update list[pos]; else insert before list[pos]; } else // pos == MAX insert after list[pos]; }")
9
9 High Level View This gives a scrawny tree. The algorithm is Greedy How many comparisons are needed to reach each possible outcome? 2+2+3+3+4+4+5+5+6+6+5 = 45 We are looking at the sum of the path lengths: gives a measure of the average complexity There are two forms: internal and external. Closely related Greedy algorithms work in phases. In each phase, a decision is made that appears to be good, without regard for future consequences.

10
10 Look at Binary Search Two possible versions of main loop /* Binary 1 - Forgetful Binary Search */ while ( top > bottom ) { middle = ( top + bottom ) / 2; if ( list[middle] < target ) bottom = middle + 1; else top = middle; } // then sort things out… /* Version 2 - Careful Binary Search - check middle entry */ while ( top > bottom ) { middle = ( top + bottom ) / 2; if ( list[middle] == target ) break; if ( list[middle] < target ) bottom = middle + 1; else /* Cut down search space */ top = middle - 1; } // Sort things out…
![10 Look at Binary Search Two possible versions of main loop /* Binary 1 - Forgetful Binary Search */ while ( top > bottom ) { middle = ( top + bottom ) / 2; if ( list[middle] < target ) bottom = middle + 1; else top = middle; } // then sort things out… /* Version 2 - Careful Binary Search - check middle entry */ while ( top > bottom ) { middle = ( top + bottom ) / 2; if ( list[middle] == target ) break; if ( list[middle] < target ) bottom = middle + 1; else /* Cut down search space */ top = middle - 1; } // Sort things out…](http://images.slideplayer.com/12/3553911/slides/slide_10.jpg "10 Look at Binary Search Two possible versions of main loop /* Binary 1 - Forgetful Binary Search */ while ( top > bottom ) { middle = ( top + bottom ) / 2; if ( list[middle] < target ) bottom = middle + 1; else top = middle; } // then sort things out… /* Version 2 - Careful Binary Search - check middle entry */ while ( top > bottom ) { middle = ( top + bottom ) / 2; if ( list[middle] == target ) break; if ( list[middle] < target ) bottom = middle + 1; else /* Cut down search space */ top = middle - 1; } // Sort things out…")
11
11 Which is better? Either version is better than linear search for more than a few items. To compare them, look at the average path length from the root to a decision We sum up the length of all paths again How many decisions to reach all outcomes? First look at Forgetful search 4+4+4+4+3+3+3+3+3+4+4 = 39

12
12 Careful Binary Search Careful search has fewer recursive calls: each call does twice as much work 1 +3+5+6+6+4+3+4+5+6+6=49 (For larger sets, does better than linear)
")
13
13 Balloon Dog Theorem When you put one outcome close to the root, may push others further away

14
14 Problem Our problem today is to find the smallest number of operations that will lead us from one sequence to another Basic operation is reversing a section of the sequence

15
15 Representation We will represent the sequence with signed integers One sequence (turnip below) is presented in order: goal
 is presented in order: goal")
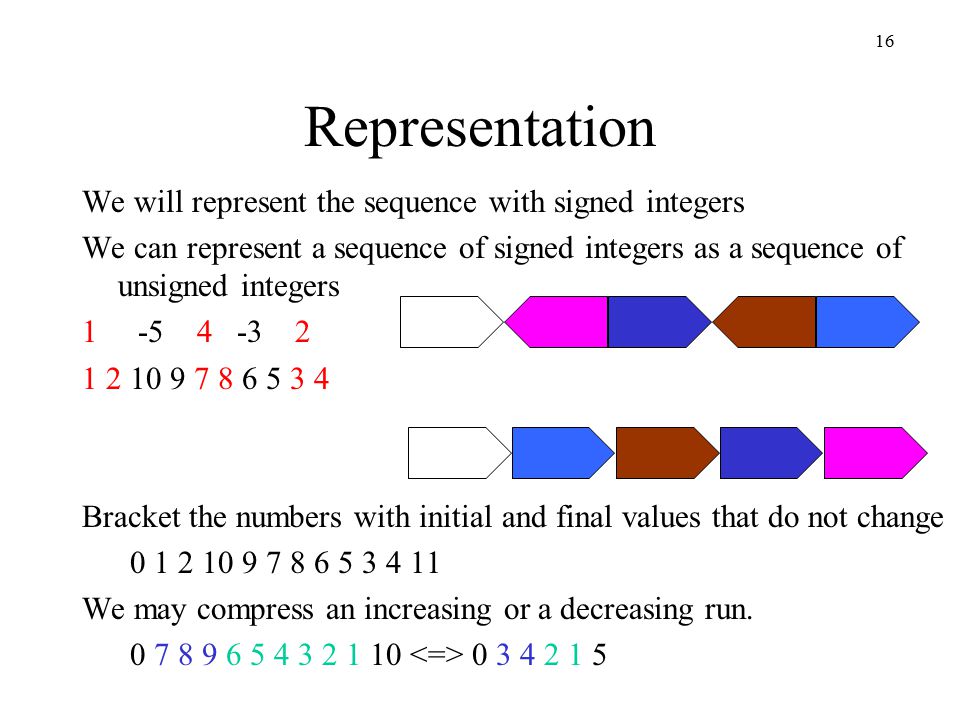
16
16 Representation We will represent the sequence with signed integers We can represent a sequence of signed integers as a sequence of unsigned integers 1 -5 4 -3 2 1 2 10 9 7 8 6 5 3 4 Bracket the numbers with initial and final values that do not change 0 1 2 10 9 7 8 6 5 3 4 11 We may compress an increasing or a decreasing run. 0 7 8 9 6 5 4 3 2 1 10 0 3 4 2 1 5
17
17 Search At each step, we can reverse a subsequence The problem is to minimize the number of steps Exhaustive search would follow all possible outcomes This is simplest to organize as a BFS of the space This is called uninformed search Pay no attention to the contents To compare positions, need a metric

18
18 Breadth First Search He leapt onto his horse and galloped off madly in all directions. - Stephen Leacock Systematically search each alternative Look at all boards one move away Look at all boards two moves away To implement BFS, use a queue Take the next board from queue Look at all boards one move away Toss duplicates. Insert the rest in the priority queue

19
19 Metrics BFS takes too long for many problems. How do we decide which move is better? To measure progress, we use metrics. Traveling Salesman – cost of tour Bubble Sort – the length of the sorted subarray 15 puzzle – number of tiles that are home Greedy algorithm uses metric

20
20 Informed Search These searches are “informed” by a measure of how close a position is to a solution In so-called “Hill Climbing”, we follow the most promising path we can. While this can quickly lead to a better position, it often leaves us at a local max (min) The hill we climb is not always the highest We cannot always continue to increase (reduce) the metric
 The hill we climb is not always the highest We cannot always continue to increase (reduce) the metric.")
21
21 Our Greedy Strategy Our strategy will be a form of Depth First Search At each stage, we will select the most promising next step Since there are no dead-ends, there is always hope We need a metric. How do we decide which permutation is close to solved?

22
22 Metric 1 First metric: Length of run of items in order 0 1 2 10 9 7 8 6 5 3 4 11 0 1 2 3 5 6 8 7 9 10 4 11 Can increase this at each step 0 1 2 3 4 10 9 7 8 6 5 11 0 1 2 3 4 5 6 8 7 9 10 11 0 1 2 3 4 5 6 7 8 9 10 11 Compare with 0 1 2 10 9 7 8 6 5 3 4 11 0 1 2 10 9 7 8 6 5 4 3 11 0 1 2 10 9 8 7 6 5 4 3 11 0 1 2 3 4 5 6 7 8 9 10 11

23
23 Metric 2 Look at breakpoints – places where abs(a i – a i+1 ) != 1 0 1 2 10 9 7 8 6 5 3 4 11 - 5 0 1 2 10 9 8 7 6 5 3 4 11 - 3 0 1 2 10 9 8 7 6 5 4 3 11 - 2 0 1 2 3 4 5 6 7 8 9 10 11 - 0
 !=")
24
24 Finding Breakpoints # Look at breakpoints – places where abs(a i – a i+1 ) != 1 def findBP(ar): """Find the breakpoints in a string of integers""" lst = [] for i in xrange(1, len(ar)): if (abs(ar[i-1] - ar[i]) > 1): lst.append(i) return lst
![24 Finding Breakpoints # Look at breakpoints – places where abs(a i – a i+1 ) != 1 def findBP(ar): Find the breakpoints in a string of integers lst = [] for i in xrange(1, len(ar)): if (abs(ar[i-1] - ar[i]) > 1): lst.append(i) return lst](http://images.slideplayer.com/12/3553911/slides/slide_24.jpg "24 Finding Breakpoints # Look at breakpoints – places where abs(a i – a i+1 ) != 1 def findBP(ar): Find the breakpoints in a string of integers lst = [] for i in xrange(1, len(ar)): if (abs(ar[i-1] - ar[i]) > 1): lst.append(i) return lst")
25
25 Reversing String Segment def reverseSegment(ar, strt, end): """Take an array ar, and reverse the segment ar[strt:end]""" sublst = ar[strt:end] # Now reverse the stack using Python idiom sublst = sublst[::-1] # Print the list as the three components print ar[:strt], sublst, ar[end:], # We print the number of breakpoints in the caller return ar[:strt] + sublst + ar[end:]
![25 Reversing String Segment def reverseSegment(ar, strt, end): Take an array ar, and reverse the segment ar[strt:end] sublst = ar[strt:end] # Now reverse the stack using Python idiom sublst = sublst[::-1] # Print the list as the three components print ar[:strt], sublst, ar[end:], # We print the number of breakpoints in the caller return ar[:strt] + sublst + ar[end:]](http://images.slideplayer.com/12/3553911/slides/slide_25.jpg "25 Reversing String Segment def reverseSegment(ar, strt, end): Take an array ar, and reverse the segment ar[strt:end] sublst = ar[strt:end] # Now reverse the stack using Python idiom sublst = sublst[::-1] # Print the list as the three components print ar[:strt], sublst, ar[end:], # We print the number of breakpoints in the caller return ar[:strt] + sublst + ar[end:]")
26
26 Sorting def sortPermutation(ar): """Greedy algorithm to sort a permutation.""" bp = findBP(ar) while (len(bp) > 0): bpLen = len(bp) bpMin = len(ar) minAr = [] # Look at all possible reversals
![26 Sorting def sortPermutation(ar): Greedy algorithm to sort a permutation. bp = findBP(ar) while (len(bp) > 0): bpLen = len(bp) bpMin = len(ar) minAr = [] # Look at all possible reversals](http://images.slideplayer.com/12/3553911/slides/slide_26.jpg "26 Sorting def sortPermutation(ar): Greedy algorithm to sort a permutation. bp = findBP(ar) while (len(bp) > 0): bpLen = len(bp) bpMin = len(ar) minAr = [] # Look at all possible reversals")
27
27 All possible Reversals for i in xrange(bpLen): for j in xrange(i+1, bpLen): if (bp[i] < bp[j] - 1): cand = reverseSegment(ar, bp[i], bp[j]) candBP = findBP(cand) candBPLen = len(candBP) if (candBPLen < bpMin): bpMin = candBPLen minAr = cand
![27 All possible Reversals for i in xrange(bpLen): for j in xrange(i+1, bpLen): if (bp[i] < bp[j] - 1): cand = reverseSegment(ar, bp[i], bp[j]) candBP = findBP(cand) candBPLen = len(candBP) if (candBPLen < bpMin): bpMin = candBPLen minAr = cand](http://images.slideplayer.com/12/3553911/slides/slide_27.jpg "27 All possible Reversals for i in xrange(bpLen): for j in xrange(i+1, bpLen): if (bp[i] < bp[j] - 1): cand = reverseSegment(ar, bp[i], bp[j]) candBP = findBP(cand) candBPLen = len(candBP) if (candBPLen < bpMin): bpMin = candBPLen minAr = cand")
28
28 Output List [0, 6, 1, 2, 5, 4, 9, 7, 8, 10, 3, 11] BPs [1, 2, 4, 6, 7, 9, 10, 11] 8 [0] [2, 1, 6] [5, 4, 9, 7, 8, 10, 3, 11] w/ breakpoint count 7 [0] [4, 5, 2, 1, 6] [9, 7, 8, 10, 3, 11] w/ breakpoint count 8 … [0, 6] [2, 1] [5, 4, 9, 7, 8, 10, 3, 11] w/ breakpoint count 8 [0, 6] [4, 5, 2, 1] [9, 7, 8, 10, 3, 11] w/ breakpoint count 8 … [0, 6, 1, 2, 5, 4] [3, 10, 8, 7, 9] [11] w/ breakpoint count 7 [0, 6, 1, 2, 5, 4, 9] [8, 7] [10, 3, 11] w/ breakpoint count 7
![28 Output List [0, 6, 1, 2, 5, 4, 9, 7, 8, 10, 3, 11] BPs [1, 2, 4, 6, 7, 9, 10, 11] 8 [0] [2, 1, 6] [5, 4, 9, 7, 8, 10, 3, 11] w/ breakpoint count 7 [0] [4, 5, 2, 1, 6] [9, 7, 8, 10, 3, 11] w/ breakpoint count 8 … [0, 6] [2, 1] [5, 4, 9, 7, 8, 10, 3, 11] w/ breakpoint count 8 [0, 6] [4, 5, 2, 1] [9, 7, 8, 10, 3, 11] w/ breakpoint count 8 … [0, 6, 1, 2, 5, 4] [3, 10, 8, 7, 9] [11] w/ breakpoint count 7 [0, 6, 1, 2, 5, 4, 9] [8, 7] [10, 3, 11] w/ breakpoint count 7](http://images.slideplayer.com/12/3553911/slides/slide_28.jpg "28 Output List [0, 6, 1, 2, 5, 4, 9, 7, 8, 10, 3, 11] BPs [1, 2, 4, 6, 7, 9, 10, 11] 8 [0] [2, 1, 6] [5, 4, 9, 7, 8, 10, 3, 11] w/ breakpoint count 7 [0] [4, 5, 2, 1, 6] [9, 7, 8, 10, 3, 11] w/ breakpoint count 8 … [0, 6] [2, 1] [5, 4, 9, 7, 8, 10, 3, 11] w/ breakpoint count 8 [0, 6] [4, 5, 2, 1] [9, 7, 8, 10, 3, 11] w/ breakpoint count 8 … [0, 6, 1, 2, 5, 4] [3, 10, 8, 7, 9] [11] w/ breakpoint count 7 [0, 6, 1, 2, 5, 4, 9] [8, 7] [10, 3, 11] w/ breakpoint count 7")
29
29 Termination It is not always possible to find a move that lowers the breakcount (Always have some move that leaves it fixed) How do we know that this will terminate?
 How do we know that this will terminate")
30
30 Informed Search: Best First Keep a table of positions we have already seen Insert starting position in PQueue and table While PQueue is not empty Select position from the PQueue While there are moves from here Generate next position If position is not in table Insert in the PQueue We investigate multiple strands at the same time Like breadth first search, but informed by our notion of closeness. By placing the positions in a priority queue, we look at the most promising positions first

31
31 Best First algorithm in action Take the best position from priority queue Look at all boards one move away For each position, check to see if we have seen it before If not, insert in the priority queue Rank boards by their distance from a solution We don't know how far it really is: We use our estimate h*(b)
")
32
32 Best First in action Start with the center position (1) Generate all outcomes: discard boards we have seen before Place remaining outcomes in the priority queue We select one of the cheapest (2) Generate outcomes: toss duplicates Select the new cheapest (3) Note that 1, 2, 3 do not form a legal sequence of moves
 Generate all outcomes: discard boards we have seen before Place remaining outcomes in the priority queue We select one of the cheapest (2) Generate outcomes: toss duplicates Select the new cheapest (3) Note that 1, 2, 3 do not form a legal sequence of moves")
33
33 A* Search BFS finds the minimal solution, but it takes a long time. Best First uses function h*(b). Faster, but solution may not be the best. A* is an informed search that will find an optimal solution. One way to improve things it to improve h*(b). Often difficult Define a new priority function f*, where f*(b) = g*(b) + h*(b) where g*(b) is the best estimate of the number of steps required to reach this position. Breadth First Search amounts to f*(b) = g*(b) and Best First Search amounts to f*(b) = h*(b)
. Faster, but solution may not be the best. A* is an informed search that will find an optimal solution. One way to improve things it to improve h*(b). Often difficult Define a new priority function f*, where f*(b) = g*(b) + h*(b) where g*(b) is the best estimate of the number of steps required to reach this position. Breadth First Search amounts to f*(b) = g*(b) and Best First Search amounts to f*(b) = h*(b).")
34
34 A* Search Use our new priority function f*, where f*(b) = g*(b) + h*(b) where g*(b) is the best estimate of the number of steps required to reach this position. Why do we need to estimate g*(b)? Don't we know how long it took? Shortcuts: You may find you can reach a position that took you 20 steps through another path that only takes 16 steps. When you find a better path, update the stored board to point to the new, better, solution. (Though this will happen with A* search, it will never happen with BFS. Why?) Requeue the board at the new priority Not all implementations of PQ have an easy way to update costs But it turns out there is no harm done if you have multiple copies of a board in the PQ.
. Don t we know how long it took. Shortcuts: You may find you can reach a position that took you 20 steps through another path that only takes 16 steps. When you find a better path, update the stored board to point to the new, better, solution. (Though this will happen with A* search, it will never happen with BFS. Why ) Requeue the board at the new priority Not all implementations of PQ have an easy way to update costs But it turns out there is no harm done if you have multiple copies of a board in the PQ..")
Similar presentations








>")
![§7 Quicksort -- the fastest known sorting algorithm in practice 1. The Algorithm void Quicksort ( ElementType A[ ], int N ) { if ( N < 2 ) return; pivot.](/13/3980333/big_thumb.jpg "§7 Quicksort -- the fastest known sorting algorithm in practice 1. The Algorithm void Quicksort ( ElementType A[ ], int N ) { if ( N < 2 ) return; pivot.>")









