Download presentation
Presentation is loading. Please wait.

1
Social Bots and Malicious Behavior
Kristina Lerman University of Southern California Access to data allows us to ask new questions, empirically measure effects CS 599: Social Media Analysis University of Southern California

2
A funny thing happened to social interactions

4
Bot presence is growing online
Faking influence Companies, celebrities, politicians buy followers, likes to appear more popular Astroturfing practice of masking the sponsors of a message to give the appearance of grassroots participation. Hashtag overload – “denial of cognitive service” attack In 2012 presidential elections in Mexico, PRI, was accused of using tens of thousands of bots to drown out opposing parties’ messages on Twitter and Facebook Phantom jam Israeli students created bots that caused a phony traffic jam on Waze

5
Sai Kaushik Ponnekanti
Detecting and Tracking the Spread of Astroturf Memes in Microblog Streams Jacob Ratkiewicz Michael Conover Mark Meiss Sneha P Bruno Gonçalves Alessandro F Filippo Menczer Presented by Sai Kaushik Ponnekanti

6
Introduction Microblogs have become a very valuable media to spread information, it is natural for people to find ways to abuse them This paper focuses on tracking political memes on Twitter and help detect astroturfing, smear campaigns and misinformation about US politics Meme ? an idea, belief or belief system, or pattern of behavior that spreads throughout a culture.

7
Introduction Astroturf? Ex :
The deceptive tactic of simulating grassroots support for a product, cause, etc., undertaken by people or organizations with an interest in shaping public opinion Ex : A case of using 9 fake accounts to promote a url to prominence. 9 fake accounts created 930 tweets in 138 mins all having link to a url smearing a candidate for 2009 Massachusetts election. In a few hours, it got promoted to the top of google search for ‘martha coakley’ creating a so called ‘twitter bomb’ This demonstrates how a focused effort can initiate viral spread of information on twitter and the serious consequences this can have.

8
Difference between Spam and Truthy
Truthy – a political astroturf. Truthy is a type of spam, but Spam – make you click url or something Truthy – establish a false group sensus about a particular idea Many of the users involved in propagating the political astroturfs may be legitimate users who themselves have been deceived. So traditional spam detection mechanisms wont work.

9
Features To study information diffusion in Twitter, we need to single out features to identify a specific topic which is propagating. To do so, authors have chosen the below set of features. Hashtags in the tweet Mentions in the tweet URLS mentioned in the tweets Phrases – text of the tweet after the metadata, punctuation and urls have been removed.

10
Truthy Architecture

11
Data Collection Twitter garden hose has been used to collect data about the tweets. All the collected tweets are stored in a file with daily time resolution

12
Meme Detection Go through tweets collected in first step to see which are to be stored in database for further analysis The goal is to collect tweets With content related to the political elections Of sufficiently general interest For (1) , a hand curated list of 2500 keywords relating to 2010 elections have been used Called the Tweet Filter Would result in many many tweets because any hash tag, url or mention is considered
 , a hand curated list of 2500 keywords relating to 2010 elections have been used. Called the Tweet Filter. Would result in many many tweets because any hash tag, url or mention is considered.")
13
Meme Detection (2) – this stage is called meme filtering, goal is to pick out only those tweets which are of general interest If any meme exceeds a rate threshold of five mentions in a given hour it is considered ‘activated’ – stored If a tweet contains an ‘activated’ meme - immediately stored When the mention rate of the meme drops below the threshold – No longer considered This low threshold is chosen because the authors thought that if a meme appeared 5 times in the sample, it is likely mentioned many more times in twitter are large

14
Network Analysis Klatsch – A unified framework which makes it possible to analyze users and diffusion for broad variety of user feeds Due to the diversity among site designs and data models, any tools written for one site are not easily portable to another The Klatsch framework is used for the network analysis and layout for visualization of diffusion patterns in the truthy architecture

15
Network Analysis An example diffusion network,

16
Network Analysis To characterize the diffusion network, we store statistics like number of nodes and edges in the graph, the mean degree and strength of nodes in the graph, mean edge weight Additionally we also store, out degree of the most prolific broadcaster and also the in degree of the most focused upon user.

17
Sentiment Analysis In addition to the graph based statistics, the authors also do the sentiment analysis using the GPOMS (Google-based Profile of Mood States) GPOMS assigns a six-dimensional vector with bases corresponding to different mood attributes, namely Calm, Alert, Sure, Vital, Kind, and Happy GPOMS relies for vocabulary on POMS. 72 adjectives associated with corresponding mod dimensions
 GPOMS assigns a six-dimensional vector with bases corresponding to different mood attributes, namely Calm, Alert, Sure, Vital, Kind, and Happy. GPOMS relies for vocabulary on POMS. 72 adjectives associated with corresponding mod dimensions.")
18
Sentiment Analysis Using 5 grams like ‘ I feel X and Y’ where X is a POMS vocabulary, GPOMS increased its vocabulary to 964 tokens associated with the 6 dimensions Apply GPOMS to collection of tweets to get the mood vector

19
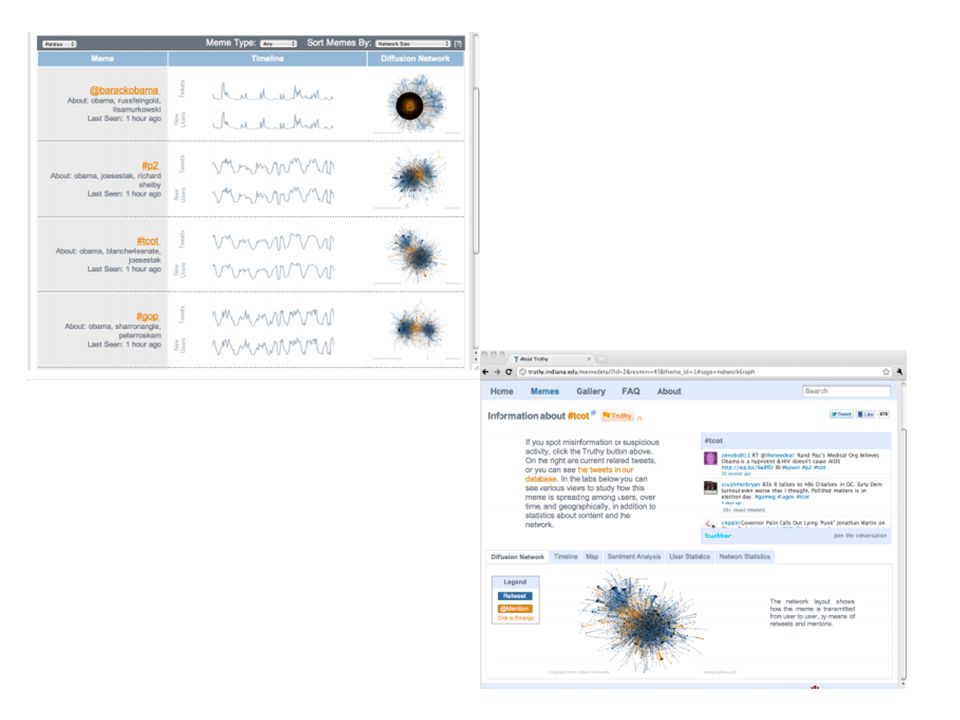
Web Interface The final component of the analytical framework includes a dynamic Web interface to allow users to inspect memes through various views, and annotate those they consider to be truthy

21
Truthiness Classification
A binary classifier trained to automatically label legitimate and truthy memes Training Data : Hand labeled corpus of training examples in 3 classes(truthy, legitimate, remove) is used People were asked to label the memes into the 3 specified categories Truthy – If it may be a political astroturf Legitimate – If it is a natural meme Remove – if it is in foreign language or didn’t belong to politics
 is used. People were asked to label the memes into the 3 specified categories. Truthy – If it may be a political astroturf. Legitimate – If it is a natural meme. Remove – if it is in foreign language or didn’t belong to politics.")
22
Results The initial results showed around 90% accuracy
Examples of truthys uncovered by this model #ampat The #ampat hashtag is used by many conservative users on Twitter. What makes this meme suspicious is that the bursts of activity are driven by two which are controlled by the same user, in an apparent effort to give the impression that more people are tweeting about the same topics. This user posts the same tweets using the two accounts and has generated a total of over 41, 000 tweets in this fashion.

23
Observations The authors observed that the detection of truthys is possible in the initial stages of the meme injection Because once it gains attention of the community, it is very difficult to distinguish between a truthy and a legitimate meme.

24
Thank You

25
Limiting the Spread of Misinformation in Social Networks
Ceren Budak, Divyakant Agrawal, Amr El Abbadi University of California, Santa Barbara Presented by Gouthami Kondakindi

26
Focus of the Research Finding a near-optimal way to spread good information in the network so as to minimize the effects of bad campaigns. How? Limiting Campaigns: Used to counteract the effect of misinformation. This optimization problem is NP-Hard Paper finds greedy approach approximation for the problem; Also finds heuristics(degree centrality, early infectees, largest infectees) that are comparable in performance to Greedy approach.
 that are comparable in performance to Greedy approach.")
27
Related Study Influence maximization problem
Selecting a subset of the network for initial activation so that the information spread is maximum Past studies ignore certain aspects of real social networks like existence of competing campaigns Conclusions from studies similar to this study: Best strategy for first player is to choose high degree nodes(Study competing campaigns as a game problem)
")
28
Need behind the Study Earlier similar studies consider that the two campaigns(good and bad) propagate exactly the same way Earlier studies study influence maximization Present study – Competing campaigns have different acceptance rates. Also, one campaign starts in response to the other. Hence, campaign of last player is started with a delay Present study – Addresses influence limitation as opposed to maximization

29
Methodology and Definitions
Social network can be modeled as a directed graph pv,w = Used to model the direct influence v has on w L – Limiting Campaign; C – Bad Campaign Independent Cascade Model: One of the most basic and well-studied diffusion models When a node v first becomes active in time step t, it has a single chance to activate each currently inactive neighbor w. If v is successful in activation, w becomes active at time step t+1. v cannot make further attempts after time t If w has incoming edges from multiple newly activated nodes, their attempts are sequenced in an arbitrary order

30
Methodology and Definitions
Influence Diffusion Models used in the paper: Model diffusion of two cascades evolving simultaneously in a network. Let L and C be the two campaigns. Multi-Campaign Independent Cascade Model (MCICM) Similar to ICM. If two or more nodes try to activate node w at the same time, at most one of them succeeds with probability pL,v,w (or pC,v,w) Assumption: If good and bad campaigns both reach a node at same time, good is preferred over bad (High Effectiveness Property) Campaign-Oblivious Independent Cascade Model (COICM) Unlike MCICM, no matter what information reaches node v, it forwards it to it’s neighbor w with probability pv,w
 Similar to ICM. If two or more nodes try to activate node w at the same time, at most one of them succeeds with probability pL,v,w (or pC,v,w) Assumption: If good and bad campaigns both reach a node at same time, good is preferred over bad (High Effectiveness Property) Campaign-Oblivious Independent Cascade Model (COICM) Unlike MCICM, no matter what information reaches node v, it forwards it to it’s neighbor w with probability pv,w.")
31
Problem Definition Eventual Influence Limitation problem:
Minimizing the number of nodes that end up adopting campaign C when information cascades from both the campaigns are over. To solve this problem, authors assume MCICM as the model of communication Campaign C starts spreading bad news starting at node n. This is detected with a delay r. Limiting Campaign L is hence initiated after r

32
Eventual Influence Limitation (EIL)
Suppose C starts spreading bad information which is detected after time r. Given a budget k, select AL seeds for initial activation of L such that expected number of nodes adopting C is limited Simplification: Consider only a single source of bad information i.e., | AC |=1. Also, considering high- effectiveness property, pL,v,w = 1 Despite the simplification, problem is still NP-Hard. Authors prove NP-Hardness of the problem by considering Set Cover as a special case of EIL

33
General Influence Spread
In order to save (3), do we need to save both (1) & (2)? NO. If L can reach (3) before C, (3) can never be infected. If L reaches node (1) by r = 1, it will be saved. In this case, L will reach (3) at r = 2 and even if (2) is not saved, that still guarantees that (3) will be saved. Conclusion: Saving nodes along shorter path to target is sufficient to save the target.
, do we need to save both (1) & (2) NO. If L can reach (3) before C, (3) can never be infected. If L reaches node (1) by r = 1, it will be saved. In this case, L will reach (3) at r = 2 and even if (2) is not saved, that still guarantees that (3) will be saved. Conclusion: Saving nodes along shorter path to target is sufficient to save the target.")
34
Solutions for Eventual Influence Limitation
EIL is NP-Hard. Hence, greedy approximation can give a polynomial time solution to EIL But, greedy approach is also too costly in real world network Solution? Consider other alternatives to greedy: Degree Centrality Early Infectees Run a number of simulations of infection spread from S (start node for C) and select nodes infected at time step r in decreasing order Largest Infectees Choose seeds that are expected to infect highest number of nodes if they were infected. Run number of simulations from S and if node I is in path from S to nodes n[k], we increase value of I by k. Return in decreasing order the nodes having highest value.
 and select nodes infected at time step r in decreasing order. Largest Infectees. Choose seeds that are expected to infect highest number of nodes if they were infected. Run number of simulations from S and if node I is in path from S to nodes n[k], we increase value of I by k. Return in decreasing order the nodes having highest value.")
35
Evaluation Performed experiments on 4 regional network graphs from Facebook SB08: 2008 snapshot of Santa Barbara regional network with nodes and edges SB09: 2009 snapshot of same network with nodes and edges (bigger network) MB08: 2008 snapshot of Monterey Bay network with nodes and edges MB09: 2009 snapshot of same network with nodes and edges (bigger network)
 MB08: 2008 snapshot of Monterey Bay network with 6117 nodes and edges. MB09: 2009 snapshot of same network with nodes and edges (bigger network)")
36
Evaluation (with PC,v,w = 0.1)
k = Number of initially activated nodes in campaign L Observation: When L has high effectiveness property, the biggest factor is determining how late the limiting campaign L is started

37
Evaluation (with Pv,w = 0.1)
COICM => No high effectiveness Observation: Compare 3(a) and 4(a). 3(a) has high effectiveness and hence could save 95% of population with 10 seeds. 4(a) could save only 72%. If 4(b), campaign C has start node with degree 40. None of the methods are able to save more nodes because by the time campaign L starts, C has already affected large no of nodes
 and 4(a). 3(a) has high effectiveness and hence could save 95% of population with 10 seeds. 4(a) could save only 72%. If 4(b), campaign C has start node with degree 40. None of the methods are able to save more nodes because by the time campaign L starts, C has already affected large no of nodes")
38
Evaluation Bigger dataset and no high effectiveness. Observation: Compare 5(b) with 3(a). Even if L does not have high effectiveness, if it is dominant than C, it is still able to save a large population. Greedy approach was not considered because it is computationally very expensive for bigger dataset and without the high effectiveness optimization.
 with 3(a). Even if L does not have high effectiveness, if it is dominant than C, it is still able to save a large population. Greedy approach was not considered because it is computationally very expensive for bigger dataset and without the high effectiveness optimization.")
39
Crucial Observations In almost all cases, largest infectees performs comparable with greedy approach and is far less computationally expensive than greedy Parameters such as delay of L, connectedness of adversary campaign C’s start node(i.e., it’s degree) are crucial to determining which method to use. Eg: Degree centrality is a good option when delay is small but a bad choice when delay is large Having sufficient information about such parameters can help identify the best method for EIL
 are crucial to determining which method to use. Eg: Degree centrality is a good option when delay is small but a bad choice when delay is large. Having sufficient information about such parameters can help identify the best method for EIL.")
40
Further Extensions The authors so far considered the scenario where number of nodes affected by bad campaign C, number of nodes still inactive(unaffected) are all known. But in real world networks, such information is difficult to obtain They discuss a solution for Eventual Influence Limitation with incomplete data using their algorithm Predictive Hill Climbing Approach (PHCA) - Beyond the scope of this discussion. Involves high level mathematical concepts. Please refer to the paper for more information.
 are all known. But in real world networks, such information is difficult to obtain. They discuss a solution for Eventual Influence Limitation with incomplete data using their algorithm Predictive Hill Climbing Approach (PHCA) - Beyond the scope of this discussion. Involves high level mathematical concepts. Please refer to the paper for more information.")
41
Conclusion Investigated efficient solution to:
Given a social network where a (bad) information campaign is spreading, who are the k “influential” people to start a counter- campaign if our goal is to minimize the effect of the bad campaign? – Eventual Influence Limitation problem Proved that EIL is NP-Hard. Stated 3 heuristics comparable in performance to greedy approach and good approximation for EIL Explored different aspects of the problem such as effect of starting the limiting campaign early/late, properties or adversary and how prone the population is to accepting either one of the campaigns Also studied EIL in presence of missing information with PHCA (not discussed here)
 information campaign is spreading, who are the k influential people to start a counter- campaign if our goal is to minimize the effect of the bad campaign – Eventual Influence Limitation problem. Proved that EIL is NP-Hard. Stated 3 heuristics comparable in performance to greedy approach and good approximation for EIL. Explored different aspects of the problem such as effect of starting the limiting campaign early/late, properties or adversary and how prone the population is to accepting either one of the campaigns. Also studied EIL in presence of missing information with PHCA (not discussed here)")
42
The rise of social bots (Ferrara et al.)
Bots have been around for years Now, the boundary between human and bot is fuzzier. Bots have Real sounding names Keep human hours (stop at night) Engage in social behavior Share photos Use emoticons, LOL Converse with each other Create realistic social networks Can we spot bots?
 Engage in social behavior. Share photos. Use emoticons, LOL. Converse with each other. Create realistic social networks. Can we spot bots")
43
Bot or not? Automatically classify Twitter accounts as human or bot based on ~1000 different features

44
Classes of features extracted by Bot or Not?

45
Classification performance

46
Features discriminating social bots from humans

47
Example classifications

48
Open questions How many social bots are there?
Who creates and controls them? For what purpose? What share of content can be attributed to bots? As we build better detection systems, we expect an arms race similar to that observed for spam in the past “The race will be over only when the increased cost of deception will no longer be justified due to the effectiveness of early detection.”

Similar presentations



















 FaisalAlam(2011MCS2608) DETECTING SPAMMERS ON SOCIAL NETWORKS.>")
 Helena Ahonen-Myka Spring 2006.>")