Download presentation
Presentation is loading. Please wait.

1
Chapter 12 Notes, DNA, RNA, and Protein Synthesis

2
By the early 1900's, scientists knew that chromosomes were responsible for traits being inherited from parents to offspring. However, the key component of the chromosomes that actually contained the genetic information remained a mystery. Chemical analysis of chromosomes told them that the genetic material had to be either proteins or nucleic acids (DNA), but they didn't know which one was responsible for carrying the genetic information.
, but they didn t know which one was responsible for carrying the genetic information..")
3
In 1928, British bacteriologist Fredrick Griffith performed an experiment to try to determine what the genetic material was. Griffith injected two different strains of bacteria (Streptococcus pneumoniae) into mice. One strain was covered in a sugar coat and one was not. He called the strain that had the sugar coat the smooth or S strain. He called the strain that lacked the sugar coat the rough or R strain.
 into mice. One strain was covered in a sugar coat and one was not. He called the strain that had the sugar coat the smooth or S strain. He called the strain that lacked the sugar coat the rough or R strain..")
4
The smooth strain was the virulent (disease causing) strain. The rough strain was not. This was the result of his experiments Mice + smooth (virulent) strain = dead mice Mice + rough (nonvirulent) strain = live mice Mice + smooth (virulent) strain after the smooth strain had been killed with heat = live mice Mice + rough (nonvirulent) strain + heat killed smooth (virulent) strain = dead mice
 strain = dead mice Mice + rough (nonvirulent) strain = live mice Mice + smooth (virulent) strain after the smooth strain had been killed with heat = live mice Mice + rough (nonvirulent) strain + heat killed smooth (virulent) strain = dead mice.")
5
Griffith concluded that a disease causing factor was transforming the rough (nonvirulent) strain into the smooth (virulent) strain of bacteria.
 strain into the smooth (virulent) strain of bacteria.")
6
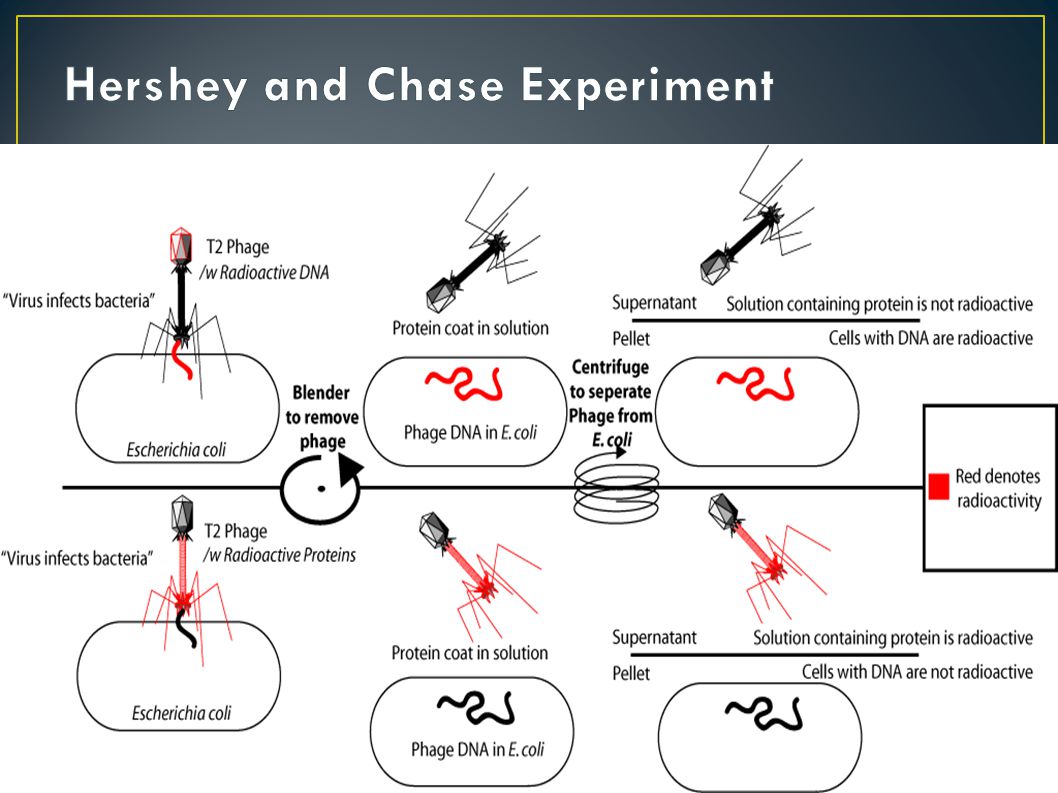
In 1952, a bacteriologist by the name of Alfred Hershey, and a geneticist by the name of Martha Chase provided conclusive evidence that DNA was in fact the transforming factor. Their experiment involved a special type of virus called a bacteriophage. A bacteriophage is a virus that attacks bacteria. The bacteriophage was ideal for this experiment because it was made of the two key components (protein and DNA) which were thought to be possible molecules responsible for inheritance.
 which were thought to be possible molecules responsible for inheritance..")
7
Hershey and Chase used a technique called radioactive labeling to trace both the protein and the DNA of the bacteriophage after it infected the bacteria (E. coli). Once the virus infected the bacteria with its genetic material, they monitored which radioactive material was inherited by the bacteria. This would identify the genetic material as proteins or DNA.
. Once the virus infected the bacteria with its genetic material, they monitored which radioactive material was inherited by the bacteria. This would identify the genetic material as proteins or DNA..")
9
Scientists were now confident that they had discovered what the genetic material was, but questions remained about the structure of DNA and how DNA communicated information. What they discovered is that DNA is made up of nucleotides. A nucleotide is a sugar molecule, a phosphate molecule, and a nitrogenous base.

10
In the DNA there are four different nitrogenous bases Adenine Guanine Cytosine Thymine Uracil (In RNA, replaces Thymine)
")
11
In the 1950s, Erwin Chargaff discovered that in every organism the amount of guanine and cytosine, and the amount of adenine and thymine was nearly equal. This is called Chargaff's rule.

12
In 1951, Rosalind Franklin used X-rays to photograph DNA. Photo 51 showed that the DNA molecule was in the shape of a twisted ladder known as a double helix.

14
James Watson and Francis Crick used data from Chargaff and Franklin's photo to build the first accurate model of DNA.

15
DNA is like a twisted ladder made up of alternating strands of deoxyribose and phosphate. The rails of the ladder are joined by the bases. (adenine, guanine, cytosine, and thymine)
.")
16
Each nitrogen base pairs up with another base in what is known as complementary base pairing. Purine bases pair with pyrimidine bases. Adenine and Guanine are called purines. Cytosine and Thymine are called pyrimidines. Adenine always pairs with Thymine. Guanine always pairs with Cytosine.

19
Another important feature of the DNA structure is the orientation of the DNA strands. The two strands DNA are referred to as antiparrellel, meaning they run parallel to eachother, but in opposite directions. This orientation is important to understand because it explains how DNA replicates. One end of the DNA strand is referred to as the 5' (five-prime) end, and the other end is referred to as the 3' (three-prime) end.
 end, and the other end is referred to as the 3 (three-prime) end..")
20
We will discuss the importance of this orientation later

21
Just one strand of DNA in one chromosome can be up to 245 million base pairs long! And remember humans have 46 chromosomes It has been estimated that if all the DNA from just one cell of a human's body was unwound, it would stretch about 6 ft long! That means the DNA in one cell is about 100,000 times longer than the cell itself! And amazingly, it all fits into the nucleus, which only takes up about 10% of the cell's volume!

22
So how does all that information fit into a cell? DNA coils tightly around small balls of protein called histones. Histones and phosphates from the DNA combine together to form nucleosomes. Nucleosomes combine together to form chromatin fibers, and the chromatin fibers combine together to form the chromosomes.

24
When Watson and Crick created their model of the DNA double helix, they also proposed a possible way that DNA might get replicated. The way they proposed DNA gets replicated is called semiconservative replication. In semiconservative replication, one of the strands always gets copied and the other strand is a copy from the original parent or template strand. The process is similar to how sourdough bread is made. In order to make it you need a starter batch (original template).
..")
25
Semiconservative Replication occurs in three stages: unwinding, base pairing, and joining During unwinding, an enzyme called DNA helicase unwinds or unzips the DNA double helix. After the strands unwind, another enzyme called DNA polymerase, adds nucleotides to the new strand in complementary base pairs.

26
Because the strands are antiparallel, one of the strands can be replicated continuously from one end to the other. This section that is replicated continuously is called the leading strand. The other strand, called the lagging strand, has to be replicated in reverse order in sections of nucleotides. These sections of nucleotides are called Okazaki fragments.

27
The Okazaki fragments are then glued together by another enzyme called DNA ligase

30
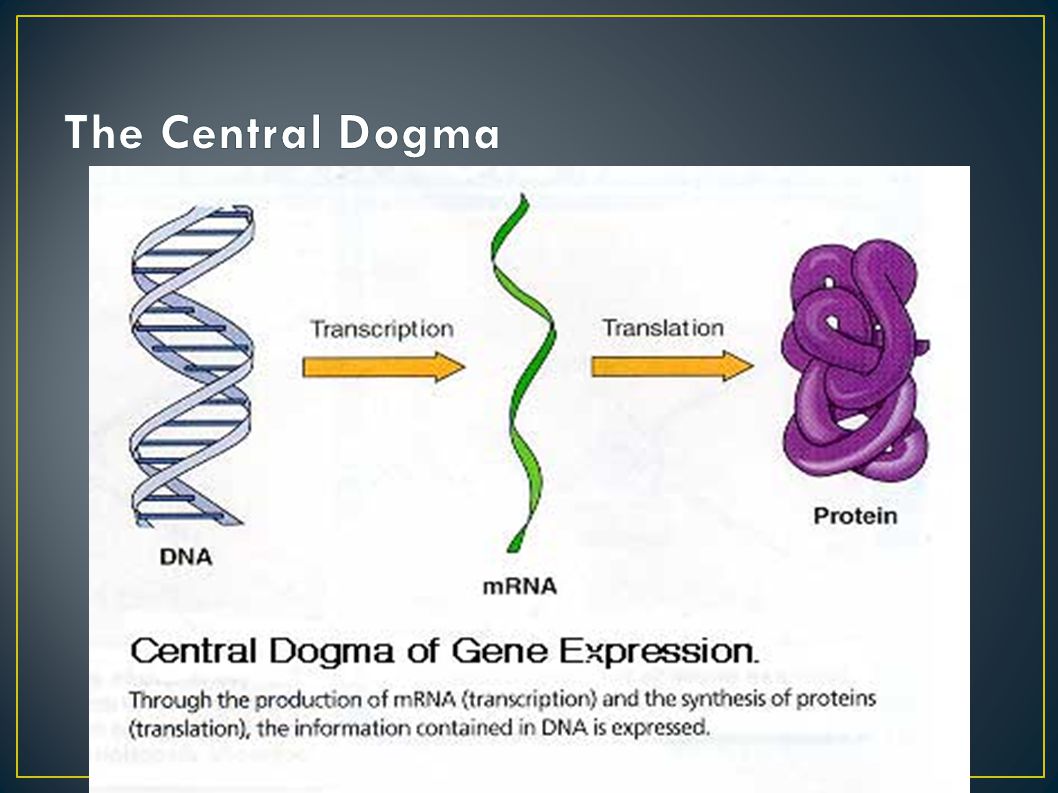
DNA contains a code that is transcribed and translated by another nucleic acid called RNA (ribonucleic acid). RNA guides the synthesis of proteins. This is process is known as the Central Dogma of biology. DNA is transcribed by Messenger RNA. Messenger RNA carries information to the ribosomes. Ribosomes (Ribosomal RNA) and Transfer RNA translate the code to make the proteins. This is how genes are expressed as traits.
 and Transfer RNA translate the code to make the proteins. This is how genes are expressed as traits..")
32
RNA is similar to DNA. Some differences are that RNA contains the sugar ribose instead of deoxyribose. Another difference is that RNA uses the nitrogen base Uracil in place of Thymine. Another difference between RNA and DNA, is that RNA is single-stranded while DNA is double-stranded. There are three main types of RNA that play a role in protein synthesis They are Messenger RNA (mRNA), Ribosomal RNA (rRNA) and Transfer RNA (tRNA).
, Ribosomal RNA (rRNA) and Transfer RNA (tRNA)..")
33
The job or role of mRNA is transcription. Transcription is the process of copying the DNA code. This is the role of messenger RNA (mRNA). Messenger RNA enters the nucleus, a small portion of the DNA strand is copied. Then the messenger RNA leaves the nucleus after copying down a part of the code to make a protein.
. Messenger RNA enters the nucleus, a small portion of the DNA strand is copied. Then the messenger RNA leaves the nucleus after copying down a part of the code to make a protein..")
34
After the DNA is unwound in the nucleus, an enzyme comes along to assist in base pairing, called RNA polymerase. RNA polymerase assists mRNA in recording what information is found on a portion of the DNA strand. Messenger RNA records the code in complementary base pairs, similar to the way DNA bases are paired during replication, except when the base pair Adenine is paired, Adenine pairs with Uracil instead of Thymine.

35
After the mRNA is transcribed, mRNA can leave the nucleus through nuclear pores and enter into the cytoplasm to find transfer RNA (tRNA) and ribosomal RNA (rRNA).
 and ribosomal RNA (rRNA).")
37
After a mRNA finds a ribosomal RNA (rRNA), the code is read and translated by interpreters called transfer RNA. Transfer RNA (tRNA) interprets the code by reading the bases in groups of three called Codons. Transfer RNA molecules each have their own Anticodon that only matches with a specific codon.
 interprets the code by reading the bases in groups of three called Codons. Transfer RNA molecules each have their own Anticodon that only matches with a specific codon..")
39
The DNA code is read as a three-base code system. Each codon matches with a specific anticodon and a specific amino acid. By joining multiple amino acids together, proteins can be assembled.

Similar presentations

























 HW – DNA/RNA coloring wksheet.>")

