Download presentation
Presentation is loading. Please wait.

1
Red, White and What? By Evan Widloski, Blake Griffith, Matt Howard and Brittany Stinnett

2
Group Members Evan Widloski– A lot sampler, tech support, and graphic designs Blake Griffith– C lot sampler and hypothesis tester Matthew Howard– C lot sampler and graphic designs Brittany Stinnet– B lot sampler

3
Data Collection A recent news broadcast claimed that only 40% of cars in America are actually American made. Our group wanted to verify the truth in this claim by examining the proportion of American cars that MHS students drive to school every day. In order to do this, we used the proportion of American cars in a small sample to estimate the total number of American cars at MHS.

4
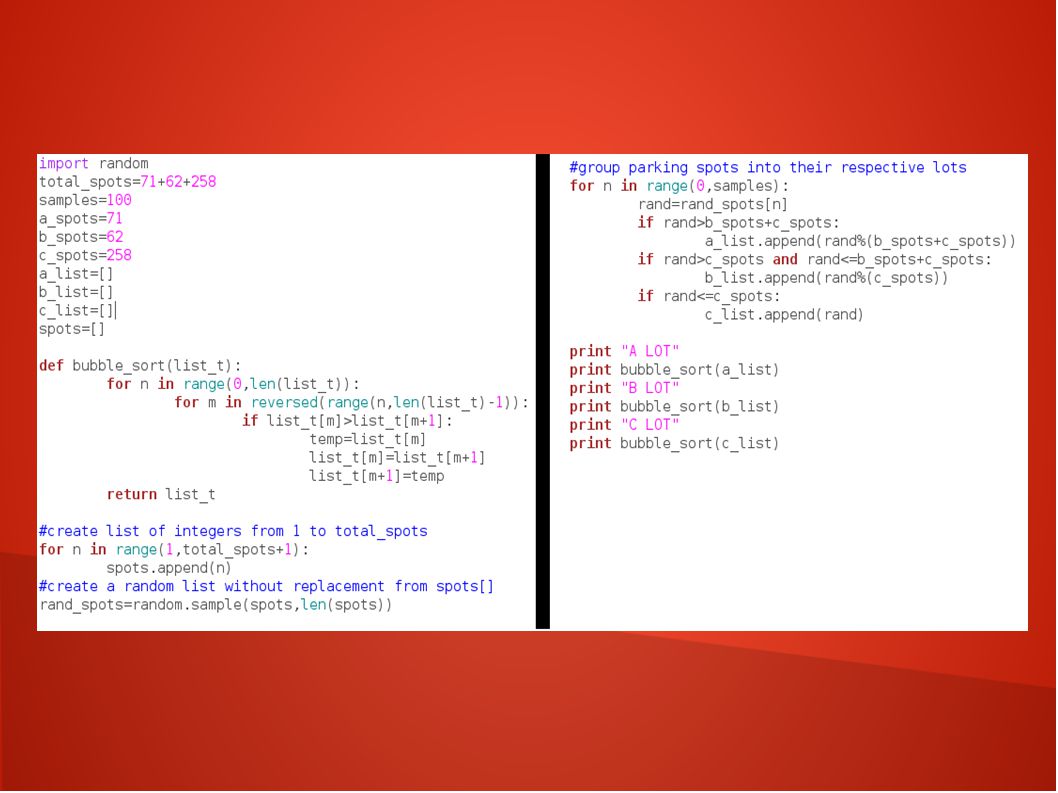
Data Collection In order to aid sampling, Evan used the Python programming language to generate pseudo-random parking spaces numbered 001 to 391. Since sampling each spot individually would require walking between parking lots many times, the program sorts parking spots into their corresponding lots and arranges them in consecutive order.

6
Data Collection Our group met during 4th block to take to take a pilot study to ensure that our sample would meet the conditions of normality. It is worth noting many seniors leave school 4th block for dual enrollment classes, another potential source of bias that cannot be easily accounted for. We split up the selected spaces evenly and began sampling. If a spot was empty, the first occupied space to the right was sampled instead. From this sample, we determined p ̂ and q ̂ to be 43% and 57% respectively which means that a sample of 100 spaces will meet the normality conditions. Our actual sample was taken with the same random sampling program. We simply took an SRS of the 100 from the 391 spots and 15 minutes later our data was recorded and placed into a spread sheet

7
Summary Statistics Pilot Study: p ̂ =.43 q ̂ =.57

8
Summary Statistics Sample: p ̂ =.41 q ̂ =.59

9
Summary Stats As you can see, our pilot study, sample, and hypothesis were all very similar and close.

10
Confidence Interval State: We want to find a confidence interval for the proportion of Maryville High School drivers with parking spots in the three official Maryville High School parking lots that are American made with a 95% confidence level.

11
Confidence Interval Plan: We should use a one-sample z interval for p if the conditions are satisfied. We must check the 3 conditions: Random: This condition is met because the parking spots were numbered from 000- 390 and randomly selected using a random number generator. Independent: This condition is not met because there are not more than 100(10)=1,000 parking spots at Maryville High School, so we must apply the Finite Population Correction Factor (sqrt((N-n)/(N-1))) in order to proceed in the testing. Normal: This condition is met because: np ̂ =(100)(.41)=41≥10 Andn(1-p ̂ )=(100)(.59)=59≥10
=1,000 parking spots at Maryville High School, so we must apply the Finite Population Correction Factor (sqrt((N-n)/(N-1))) in order to proceed in the testing. Normal: This condition is met because: np ̂ =(100)(.41)=41≥10 Andn(1-p ̂ )=(100)(.59)=59≥10.")
12
Confidence Interval Do: A 95% confidence interval for p is given by p ̂ ±z*(sqrt((p ̂ (1- p ̂ )/n)))(sqrt((N-n)/(N-1))).41±1.96(sqrt((.41(.59)/100)))(sqrt((391-100)/(391-1))).41±1.96(.049183)(.863802).41±.083269 (.326731,.493269)
/n)))(sqrt((N-n)/(N-1))).41±1.96(sqrt((.41(.59)/100)))(sqrt(( )/(391-1))).41±1.96( )( ).41± ( , )")
13
Confidence Interval Conclude: We are 95% confidence from.326731 to.493269 captures the true proportion of American made cars driven by Maryville High School students with a spot in one of the three Maryville High School parking lots.

14
Hypothesis Test State: We want to perform a test at the α=0.05 significance level of H o : p=.40 H a : p≠.40 Where p is the actual proportion of cars driven by Maryville High School students with parking passes for a Maryville High School lot.

15
Hypothesis Test Plan: If conditions are met, we should do a one-sample z test for the population proportion p. We must check the 3 conditions: Random: This condition is met because the parking spots were numbered from 000-390 and randomly selected using a random number generator. Independent: This condition is not met because there are not more than 100(10)=1,000 parking spots at Maryville High School, so we must apply the Finite Population Correction Factor (sqrt((N-n)/(N-1))) in order to proceed in the testing. Normal: This condition is met because: np o =(100)(.40)=40≥10 Andn(1-p o )=(100)(.60)=60≥10
=1,000 parking spots at Maryville High School, so we must apply the Finite Population Correction Factor (sqrt((N-n)/(N-1))) in order to proceed in the testing. Normal: This condition is met because: np o =(100)(.40)=40≥10 Andn(1-p o )=(100)(.60)=60≥10.")
16
Hypothesis Test Do: The sample proportion of American-made cars in the Maryville High School student parking lots is p ̂ =0.41 Test statistic: z=( p ̂ -p o )/((sqrt(p o (1- p o )/n)*(sqrt((N-n)/(N-1)) z=(.41-.40)/((sqrt(.40(1-.40)/100)*(sqrt((391-100)/(391-1)) z=.01/((.048990)*(.863801)) z=.2363 Because this z-score does not fall into our rejection regions (z≤-1.96 or z≥1.96) we fail to reject the null hypothesis.
/((sqrt(p o (1- p o )/n)*(sqrt((N-n)/(N-1)) z=( )/((sqrt(.40(1-.40)/100)*(sqrt(( )/(391-1)) z=.01/(( )*( )) z=.2363 Because this z-score does not fall into our rejection regions (z≤-1.96 or z≥1.96) we fail to reject the null hypothesis.")
17
Hypothesis Test Conclude: Since our z-score of.2363 does not fall into our rejection regions at z≤-1.96 or z≥1.96, we do not have sufficient evidence to reject H o. We cannot conclude that the proportion of student-driven vehicles that are parked in one of the official school lots that are American-made differs from the hypothesis of.40.

19
Conclusion From our experiment we can conclude that the true proportion of American made cars that are parked at our school is approximately.4. We are surprised at how close to the news broadcast that the proportion at Maryville High School actually was. There were very few sources of possible error since parking spots at Maryville High School are assigned to each student. The most possible source of error is that a car was parked in the wrong spot or that a student did not attend school that day. We did not experience this issue however and our experiment was a success.

20
Future Ideas Future experiments could include taking samples of much larger areas or by randomly selecting driveways in Maryville. An area that we did not observe, but could be very interesting would be to find the proportion of each make and see how this compares to national and local sales of each brand of car. Other experiments could also be based off of this study such as grades as compared to car makes. Another interesting experiment would be to find the correlation between first cars and future income.

21
Raw Data

Similar presentations