Download presentation
Presentation is loading. Please wait.

1
Psychometric Aspects of Linking Tests to the CEF Norman Verhelst National Institute for Educational Measurement (Cito) Arnhem – The Netherlands
 Arnhem – The Netherlands")
2
Overview What is the problem –CEF –Psychometric problems Internal validation –Reliability –Dimensionality Linking –Test equating –Standard setting

3
Problem 1: What is the CEF? (descriptive) Classification system of linguistic acts (in a foreign language (?)) –Basic building blocks: can do statements –Multifaceted skills (listening, reading,... table 2, p.26-27) qualitative aspects (range, coherence, table 3, p. 28) contexts (personal, educational, table 5, p. 48)
 Classification system of linguistic acts (in a foreign language ( )) –Basic building blocks: can do statements –Multifaceted skills (listening, reading,... table 2, p.26-27) qualitative aspects (range, coherence, table 3, p. 28) contexts (personal, educational, table 5, p. 48).")
4
Solution 1: What could we do if the CEF were nothing else than a descritpive system? Determination problem: is a concrete performance (linguistic act) an exemplar of a can do statement? We place a check mark along the can do statement that is exempified by the performance, forming thus a complicated high-dimensional profile Probably we would encounter problems of consistency (e.g. being successful in only one of two exemplars of the same can do statement)
 an exemplar of a can do statement. We place a check mark along the can do statement that is exempified by the performance, forming thus a complicated high-dimensional profile Probably we would encounter problems of consistency (e.g. being successful in only one of two exemplars of the same can do statement).")
5
Problem 2: The CEF is also a hierarchic system Three main classicications: Basic, Independent and Proficient (A, B and C) Further subdivisions: A1, A2, B1, B2, C1 and C2 (cumulative and therefore ordered) Implications –Language proficiency is measurable using this system –It implies a (rudimental) theory of language acquisition
 Further subdivisions: A1, A2, B1, B2, C1 and C2 (cumulative and therefore ordered) Implications –Language proficiency is measurable using this system –It implies a (rudimental) theory of language acquisition")
6
The Linking Problem Devise a structured observation of linguistic acts (a test) Assign a person to one of the levels A1,...,C2 –using his/her test performance –using ‘objective’ rules –in such a way that the assigned level ‘B1’ corresponds to the ‘real’ level B1 as defined in the CEF The ‘Manual’ tells you how to proceed.
 Assign a person to one of the levels A1,...,C2 –using his/her test performance –using ‘objective’ rules –in such a way that the assigned level ‘B1’ corresponds to the ‘real’ level B1 as defined in the CEF The ‘Manual’ tells you how to proceed.")
7
Internal validation Restriction to itemized tests ‘Universal simplification’: test performance is summarized by a single number, the test score Typical result: a score (on my test) in the range 21 to 32 corresponds to a B1 Why should one have confidence in your test?
 in the range 21 to 32 corresponds to a B1 Why should one have confidence in your test")
8
Reliability Every measurement contains an error True score is the average score over a (huge) number of similar test administrations True scores and measurement errors are not ‘knowable’ in particular cases One can know something ‘in general’ Basic notion: Reliability coefficient
 number of similar test administrations True scores and measurement errors are not ‘knowable’ in particular cases One can know something ‘in general’ Basic notion: Reliability coefficient")
9
Reliability coefficient (Rel) Rel is the correlation between the scores on two parallel tests. It lies in [0,1] Reliability is a characteristic of the test in some population We do not compute Rel (in the population) but (in a sample): estimation error Establishing the reliability with a single test administration is very hard (Cronbach’s )
 but (in a sample): estimation error Establishing the reliability with a single test administration is very hard (Cronbach’s ).")
10
Rel should be high(ish)?
")
11
Example continued (SEM = 3)
")
12
Dimensionality Can do at level B1 Can recognise significant points in straightforward newspaper articles on familiar subjects Can do at level B1 Can understand clearly written, straightforward instructions for a piece of equipment

13
Associated Problems Is a test consisting of 20 exemplars (items) of the ‘black’ can do equivalent to a test consisting of 20 exemplars of the ‘blue’ can do? –If ‘Yes’: How do we know this? –If ‘No’: What is the justification of placing the two can do’s at the same level (B1)? Maybe the score on the ‘blue test’ is partly determined by the trait ‘technical insight’. The previous hypothesis can be tested empirically
. Maybe the score on the ‘blue test’ is partly determined by the trait ‘technical insight’. The previous hypothesis can be tested empirically.")
15
Multidimensionality: techniques If two tests measure the same concept, they will generally not perfectly correlate, because of measurement error. Correction for attenuation:

16
Factor Analysis Is the basic technique to reveal the dimensionality structure of a test battery Has a lot of variants, some technically very complicated The basic notions should be mastered by every scholar in language testing Reference: Section F of the Reference Supplement to the Manual.

17
Transition (1) The concepts discussed so far refer to internal validation, but also to external validation –The blue test of the example must not be a test of technical insight –An informative factor analysis will include other than pure language tests (or subtests) Provisional conclusion: my test is professionally constructed and measures proficiency in the sense described by the CEF –The items are well devised exemplars of can do statements –There is a well defined balance across qualitative aspects deemed important in the CEF In this sense, the test is linked to the CEF.
 The concepts discussed so far refer to internal validation, but also to external validation –The blue test of the example must not be a test of technical insight –An informative factor analysis will include other than pure language tests (or subtests) Provisional conclusion: my test is professionally constructed and measures proficiency in the sense described by the CEF –The items are well devised exemplars of can do statements –There is a well defined balance across qualitative aspects deemed important in the CEF In this sense, the test is linked to the CEF.")
18
Transition (2) But we want more –Assignment to a CEF-level, using only test scores, e.g., –less than 55 ‘level A2 or lower’ –55 or more ‘level B1 or higher’ –73 or more ‘level B2 or higher’ –By implication [55,72] assigns to B1 –55 and 73 are called cutting points (or cut-off scores) Two classes of techniques –Test Equating –Standard Setting
![Transition (2) But we want more –Assignment to a CEF-level, using only test scores, e.g., –less than 55 ‘level A2 or lower’ –55 or more ‘level B1 or higher’ –73 or more ‘level B2 or higher’ –By implication [55,72] assigns to B1 –55 and 73 are called cutting points (or cut-off scores) Two classes of techniques –Test Equating –Standard Setting](http://images.slideplayer.com/12/3399101/slides/slide_18.jpg "Transition (2) But we want more –Assignment to a CEF-level, using only test scores, e.g., –less than 55 ‘level A2 or lower’ –55 or more ‘level B1 or higher’ –73 or more ‘level B2 or higher’ –By implication [55,72] assigns to B1 –55 and 73 are called cutting points (or cut-off scores) Two classes of techniques –Test Equating –Standard Setting")
19
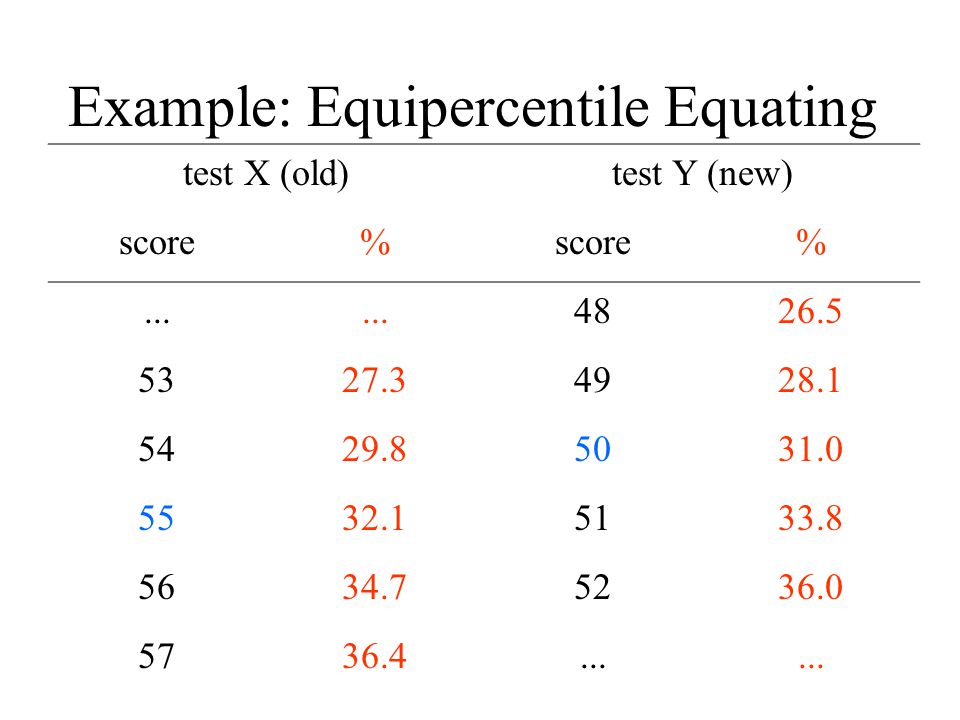
Test Equating To replace an ‘old’ test X by a ‘new’ test Y Problem: find for each possible score on X an equivalent score on Y Especially useful if X and Y are not equally difficult. Many techniques, some very easy to apply But...

20
Example: Equipercentile Equating test X (old)test Y (new) score% %... 4826.5 5327.34928.1 5429.85031.0 5532.15133.8 5634.75236.0 5736.4...
21
Standard Setting If there is no test to equate with, somebody has to decide whether the minimum score for a ‘B1’ assignment is 55 or 54 or 61 or whatever. –Who is/are this somebody? –How do they decide? –Is their decision the ‘truth’? –Why would we trust such a decision?

22
Who is involved? Not a single individual, but a group of persons (‘the larger the better’) A group of experts, i.e. trained persons –They know the CEF –They recognize exemplars A whole chapter of the manual is devoted to this problem.
 A group of experts, i.e. trained persons –They know the CEF –They recognize exemplars A whole chapter of the manual is devoted to this problem..")
23
How to decide? Many standard setting methods documented in the literature (starting in 1954!) See Section B of the Reference Supplement of the manual. –Test centered –Examinee centered
 See Section B of the Reference Supplement of the manual. –Test centered –Examinee centered.")
24
Standard Setting in Dialang Suppose the target level is B1 For each item, ask the following question: “Do you think a person at level B1 should be able to answer this item correctly?” Count the number of items responded to by ’yes’. Average across judges and you get the standard

25
Is their decision the truth? ?

26
Why would we trust such decisions? Intra-judge consistency –‘Easy’ items (yes), ‘hard’ items (no) Inter-judge consistency –Do you agree ‘in general’ with your colleagues External validation –Maybe there is an external test –Overall judgment of the teacher
, ‘hard’ items (no) Inter-judge consistency –Do you agree ‘in general’ with your colleagues External validation –Maybe there is an external test –Overall judgment of the teacher.")
Similar presentations





. All rights reserved. 800 837 8969.>")














