Download presentation
Presentation is loading. Please wait.

1
Query Optimization of Frequent Itemset Mining on Multiple Databases Mining on Multiple Databases David Fuhry Department of Computer Science Kent State University Joint work with Ruoming Jin and Abdulkareem Alali (Kent State) March 27, 2008 / EDBT’08
 March 27, 2008 / EDBT’08")
2
Why do we care about mining multiple datasets? Multiple datasets are everywhere –Data warehouse –Data collected at different places, at different times –Large dataset logically partitioned into several small datasets Comparing the patterns from different datasets is very important Combining mining results from each individual dataset is not good enough

3
Frequent Itemset Mining One of the most well-studied areas in KDD; one of the most widely used data mining techniques; one of the most costly data mining operators Tens (or maybe well over one hundred) of algorithms have been developed –Among them, Apriori and FP-Tree Frequent Pattern Mining (FPM) –Sequences, Trees, Graphs, Geometric structures, … Implemented in modern database system –Oracle, SQL Server, DB2, …
 of algorithms have been developed –Among them, Apriori and FP-Tree Frequent Pattern Mining (FPM) –Sequences, Trees, Graphs, Geometric structures, … Implemented in modern database system –Oracle, SQL Server, DB2, …")
4
Motivating Examples Mining the Data Warehouse for a Nation-wide Store: –Three branches in OH, MI, CA –One week’s retail transactions Queries –Find itemsets that are frequent with support level 0.1% in each of the stores –Find itemsets that are frequent with support level 0.05% in both the stores in mid-west, but are very infrequent (support less that 0.01%) in the west coast store
 in the west coast store")
5
So, how to answer these queries? Imagine we have only two transaction datasets, A and B A simple query –Find the itemsets that are frequent in A and B with support level 0.1 and 0.3, respectively, or the itemsets that are frequent in A and B with support level 0.3 and 0.1, respectively. We have the following options to evaluate this query –Option 1 Finding frequent itemsets in A with support level 0.1 Finding frequent itemsets in B with support level 0.3 Finding frequent itemsets in A with support level 0.3 Finding frequent itemsets in B with support level 0.1

6
How to? (cont’d) –Option 2 Finding frequent itemsets in A with support 0.1 Finding frequent itemsets in B with support 0.1 –Option 3 Finding frequent itemsets in A (or B) with support 0.1 –Among them, finding itemsets that are also frequent in B (or A) with support 0.1 –Option 4 Finding frequent itemsets in A with support 0.3 –Among them, finding itemsets that are also frequent in B with support 0.1 Finding frequent itemsets in B with support 0.3 –Among them, finding itemsets that are also frequent in A with support 0.1 –…–… Depending on the characteristics of datasets A and B, and the support levels, each option can have very different total mining cost!
 –Option 2 Finding frequent itemsets in A with support 0.1 Finding frequent itemsets in B with support 0.1 –Option 3 Finding frequent itemsets in A (or B) with support 0.1 –Among them, finding itemsets that are also frequent in B (or A) with support 0.1 –Option 4 Finding frequent itemsets in A with support 0.3 –Among them, finding itemsets that are also frequent in B with support 0.1 Finding frequent itemsets in B with support 0.3 –Among them, finding itemsets that are also frequent in A with support 0.1 –…–… Depending on the characteristics of datasets A and B, and the support levels, each option can have very different total mining cost!.")
7
Basic Operations SF(A, α) –Find frequent itemsets in dataset A with support α ⊔ Union ⊓ Intersection σ β Select frequent itemsets with support β from results of SF(A, α) (β > α) (Inexpensive)
 –Find frequent itemsets in dataset A with support α ⊔ Union ⊓ Intersection σ β Select frequent itemsets with support β from results of SF(A, α) (β > α) (Inexpensive)")
8
Query M-Table Representation 0.1 0.05D 0.1 C 0.050.1B 0.050.1A F3F2F1 Query M-Table (SF(A,0.1) ⊓ SF(B,0.1) ⊓ SF(D,0.05)) ⊔ (SF(A,0.05) ⊓ SF(C,0.1) ⊓ SF(D,0.1)) ⊔ (SF(B,0.05) ⊓ SF(C,0.1) ⊓ SF(D,0.1)) dummy
 ⊓ SF(B,0.1) ⊓ SF(D,0.05)) ⊔ (SF(A,0.05) ⊓ SF(C,0.1) ⊓ SF(D,0.1)) ⊔ (SF(B,0.05) ⊓ SF(C,0.1) ⊓ SF(D,0.1)) dummy")
9
CF Mining Operator SF(A, α) –Find frequent itemsets in dataset A with support α Recall: CF(A, α, X) –Find frequent itemsets in dataset A with support α within the search space X –X is the result of a previous SF or CF operation (a set of frequent itemsets) –Equivalent to SF(A, α) ⊓ X
 –Find frequent itemsets in dataset A with support α Recall: CF(A, α, X) –Find frequent itemsets in dataset A with support α within the search space X –X is the result of a previous SF or CF operation (a set of frequent itemsets) –Equivalent to SF(A, α) ⊓ X")
10
Coloring the M-Table 0.1 0.05D 0.1 C 0.050.1 B 0.050.1 A F5F4F3F2F1 SF(A,0.05) SF(C,0.1) … When the M-Table is covered, the query is solved. Query Plan CF(B,0.1,SF(A,0.1))
).")
11
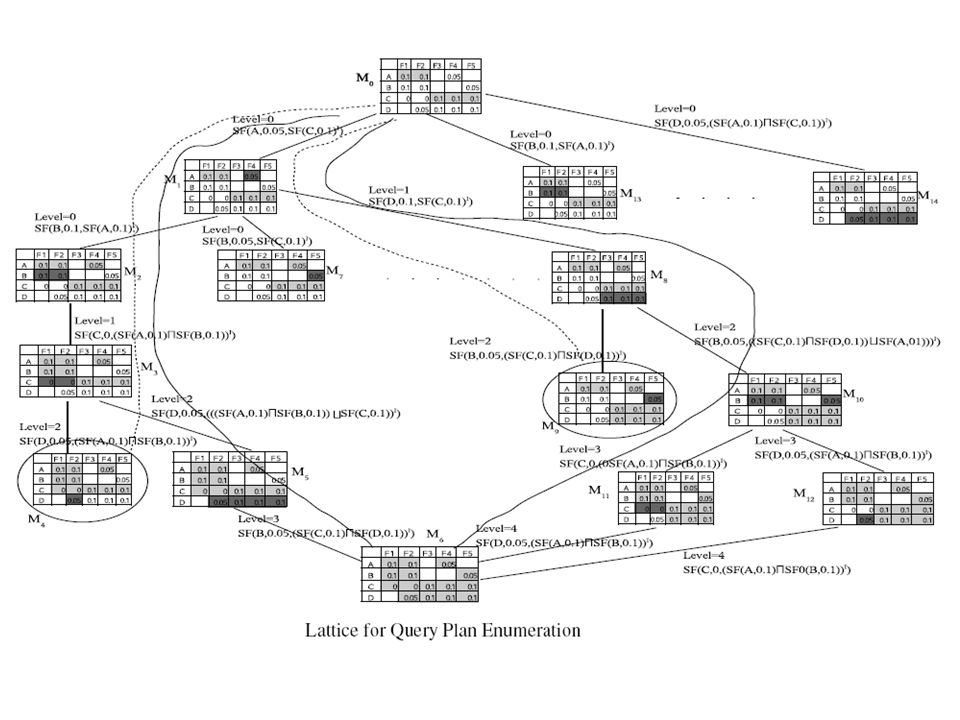
Query Plan Space Definitions: cell-set: A group of cells in the same row of the M-table. Query Plan: A sequence of cell-sets which colors all the nonempty cells in the M- Table.

12
Query Plan Space Phase 1: Phase 1: Color at least one cell in every column using the SF mining operator. Phase 2: Phase 2: Color the remaining cells using the CF mining operator. Independent of the mining results generated from any other mining operation. Dependent on results from previous SF or CF operations.

13
Query Plan Space (cont’d) Example : 0.1 0.05 D 0.1 00 C 0.050.1 B 0.050.1 A F5F4F3F2F1 Phase1: Phase1: SF( A, 0.1) Phase2: Phase2: CF ( A, 0.05, SF( C, 0.1) ) SF( C, 0.1) CF ( B, 0.05, SF( A, 0.1) ⊔ SF( C, 0.1) ) CF ( D, 0.05, ( SF( A, 0.1 ) ⊔ SF( B, 0.01) ) ⊔ SF( C, 0 ) ) CF ( C, 0, SF( A, 0.1) ⊔ SF( B, 0.1) )
 Example : D C B A F5F4F3F2F1 Phase1: Phase1: SF( A, 0.1) Phase2: Phase2: CF ( A, 0.05, SF( C, 0.1) ) SF( C, 0.1) CF ( B, 0.05, SF( A, 0.1) ⊔ SF( C, 0.1) ) CF ( D, 0.05, ( SF( A, 0.1 ) ⊔ SF( B, 0.01) ) ⊔ SF( C, 0 ) ) CF ( C, 0, SF( A, 0.1) ⊔ SF( B, 0.1) )")
14
Partial Orders and Equivalent Query Plans Phase 2 of a Query Plan represented as a DAG Two Query Plans are equivalent if their corresponding Partial Orders are the same.

15
Reducing Search Space in Phase 1 Observation: CF Mining Operator usually costs less than its corresponding SF operator Heuristic 1: In Phase 1, perform the set of SF operations with the minimal cost so that every column has one cell colored. 0.1 0.05 D 0.1 00 C 0.050.1 B 0.050.1 A F5F4F3F2F1 Phase 1: SF(A, 0.1) SF(C, 0.1) done
 SF(C, 0.1) done.")
16
Reducing Search Space in Phase 2 Observation: Within a row, a CF operation can cover a single cell or multiple cells. Planning cost will be high if every combination of single cells is tested. Heuristic 2: Specify a basic unit as the smallest cell-set a CF operator can cover. We test three different granularities of basic units. Granularity One: A CF operation will color each cell individually. Granularity Two: Within a row, a CF operation will color all cells with the same support level. Granularity Three: Within a row, a CF operation will color all uncolored cells. 0.050.1 A F5F4F3F2F1 Granularity One Granularity Two Granularity Three

17
Query Plan With Granularity 2 Example: 0.1 0.05 D 0.1 00 C 0.050.1 B 0.050.1 A F5F4F3F2F1 Phase1: SF(A, 0.1), SF(C, 0.1) Phase2 : CF(B, 0.1, SF(A,0.1) ) CF(D, 0.1, SF(C, 0.1) ) CF(A, 0.05, SF(C, 0.1) ⊓ SF(D, 0.1) ) CF(B, 0.05, SF(C, 0.1) ⊓ SF(D, 0.1) ) CF(D, 0.05, SF(A, 0.1) ⊓ SF(B, 0.1) ) CF(C, 0, SF(A, 0.1) ⊓ SF(B, 0.1) )
, SF(C, 0.1) Phase2 : CF(B, 0.1, SF(A,0.1) ) CF(D, 0.1, SF(C, 0.1) ) CF(A, 0.05, SF(C, 0.1) ⊓ SF(D, 0.1) ) CF(B, 0.05, SF(C, 0.1) ⊓ SF(D, 0.1) ) CF(D, 0.05, SF(A, 0.1) ⊓ SF(B, 0.1) ) CF(C, 0, SF(A, 0.1) ⊓ SF(B, 0.1) )")
19
Cost Estimation Cost estimation for SF –Factors: The number of transactions: n The average length of the transactions: |I| The density of the datasets: d (entropy of correlations) –Use density formula proposed in [Palmerini, 2004] The support level: s –Formula (best of several we tested): –Regression to determine parameters –CF based on SF ►Show density formula
![Cost Estimation Cost estimation for SF –Factors: The number of transactions: n The average length of the transactions: |I| The density of the datasets: d (entropy of correlations) –Use density formula proposed in [Palmerini, 2004] The support level: s –Formula (best of several we tested): –Regression to determine parameters –CF based on SF ►Show density formula](http://images.slideplayer.com/12/3389897/slides/slide_19.jpg "Cost Estimation Cost estimation for SF –Factors: The number of transactions: n The average length of the transactions: |I| The density of the datasets: d (entropy of correlations) –Use density formula proposed in [Palmerini, 2004] The support level: s –Formula (best of several we tested): –Regression to determine parameters –CF based on SF ►Show density formula")
20
Query Plan Generation with Cost Estimation Dynamic Programming Branch & Bound –Use cost of Greedy as initial min cost –Enumerate query plans, prune branches which begin to exceed min cost –Cheaper completed query plans update the min cost

21
Results for Query Evaluation Averages are across nine datasets, ranging from 500,000 to 2,000,000 transactions. Greedy and cost-based approaches significantly reduce evaluation costs Average of 10x speedup Up to 20x speedup on QUEST-6 The cost-based algorithm reduces the mining cost of the query plan generated by the heuristic algorithm by an average of 20% per query (significantly improves 40% of the queries) Average Cost (in seconds) to evaluate query plan
 Average Cost (in seconds) to evaluate query plan.")
22
Results for Query Planning Average Cost (in seconds) to Generate a Query Plan Using granularities 2 and 3 significantly reduces planning cost. Cost-based algorithms’ planning cost can be competitive with Greedy.

23
Conclusions Cost-Based Query Optimization on Multiple Datasets an important part of a Knowledge Discovery and Data Mining Management System (KDDMS) A Long-term goal for data mining –Interactive data mining –New techniques in database-type environment to support efficient data mining
 A Long-term goal for data mining –Interactive data mining –New techniques in database-type environment to support efficient data mining")
24
Thank You

25
Density Formula Palmerini et. al. 2004. Statistical properties of transactional databases. ◄ Return to Cost Estimation

27
Frequent Itemset Cardinality Estimation Sampling Sketch Matrix

28
Granularity 2 Example: 0.1 0.05 D 0.1 00 C 0.050.1 B 0.050.1 A F5F4F3F2F1 Phase1: SF(A, 0.1), SF(C, 0.1) Phase2 : CF(D, 0.1, SF(C, 0.1) ) CF(A, 0.05, SF(C, 0.1) ⊓ SF(D, 0.1) ) CF(B, 0.05, SF(C, 0.1) ⊓ SF(D, 0.1) ) CF(D, 0.05, SF(A, 0.1) ⊓ SF(B, 0.1) ) CF(C, 0, SF(A, 0.1) ⊓ SF(B, 0.1) ) CF(B, 0.1, SF(A,0.1) )
, SF(C, 0.1) Phase2 : CF(D, 0.1, SF(C, 0.1) ) CF(A, 0.05, SF(C, 0.1) ⊓ SF(D, 0.1) ) CF(B, 0.05, SF(C, 0.1) ⊓ SF(D, 0.1) ) CF(D, 0.05, SF(A, 0.1) ⊓ SF(B, 0.1) ) CF(C, 0, SF(A, 0.1) ⊓ SF(B, 0.1) ) CF(B, 0.1, SF(A,0.1) )")
Similar presentations



















 Rule-based classification JRIP (RIPPER) Logistic Regression.>")
