Download presentation
Presentation is loading. Please wait.

1
Image quality assessment and statistical evaluation Lecture 3 February 4, 2005

2
Image Quality Many remote sensing datasets contain high-quality, accurate data. Unfortunately, sometimes error (or noise) is introduced into the remote sensor data by: the environment (e.g., atmospheric scattering, cloud), random or systematic malfunction of the remote sensing system (e.g., an uncalibrated detector creates striping), or improper airborne or ground processing of the remote sensor data prior to actual data analysis (e.g., inaccurate analog-to-digital conversion).
 is introduced into the remote sensor data by: the environment (e.g., atmospheric scattering, cloud), random or systematic malfunction of the remote sensing system (e.g., an uncalibrated detector creates striping), or improper airborne or ground processing of the remote sensor data prior to actual data analysis (e.g., inaccurate analog-to-digital conversion)..")
3
155 154155 160 162 163 164 MODIS True 143 Cloud

4
Cloud in ETM+

5
Striping Noise and RemovalCPCA Combined Principle Component Analysis Xie et al. 2004

6
Speckle Noise and Removal G-MAP Blurred objects and boundary Gamma Maximum A Posteriori Filter

7
Remote sensing sampling theory Large samples drawn randomly from natural populations usually produce a symmetrical frequency distribution: most values are clustered around some central values, and the frequency of occurrence declines away from this central point- bell shaped, and is also called a normal distribution. Many statistical tests used in the analysis of remotely sensed data assume that the brightness values (DN) recorded in a scene are normally distributed. Unfortunately, remotely sensed data may not be normally distributed and the analyst must be careful to identify such conditions. In such instances, nonparametric statistical theory may be preferred.
 recorded in a scene are normally distributed. Unfortunately, remotely sensed data may not be normally distributed and the analyst must be careful to identify such conditions. In such instances, nonparametric statistical theory may be preferred..")
8
Remote sensing pixel values and statistics Many different ways to check the pixel values and statistics: looking at the frequency of occurrence of individual brightness values (or digital number-DN) in the image displayed in a histogram viewing on a computer monitor individual pixel brightness values or DN at specific locations or within a geographic area, computing univariate descriptive statistics to determine if there are unusual anomalies in the image data, and computing multivariate statistics to determine the amount of between-band correlation (e.g., to identify redundancy).
 in the image displayed in a histogram viewing on a computer monitor individual pixel brightness values or DN at specific locations or within a geographic area, computing univariate descriptive statistics to determine if there are unusual anomalies in the image data, and computing multivariate statistics to determine the amount of between-band correlation (e.g., to identify redundancy).")
9
A graphic representation of the frequency distribution of a continuous variable. Rectangles are drawn in such a way that their bases lie on a linear scale representing different intervals, and their heights are proportional to the frequencies of the values within each of the intervals 1. Histogram

10
Histogram of A Single Band of Landsat TM Data of Charleston, SC Metadata of the image What is metadata? a.Open water, b.Coastal wetland c.Upland

11
2. Viewing individual pixel values at specific locations or within a geographic area There are different ways in ENVI to see pixel values Cursor location/value Cursor location/value Special pixel editor Special pixel editor 3D surface view 3D surface view

12
3. Univariate descriptive image statistics The mode is the value that occurs most frequently in a distribution and is usually the highest point on the curve (histogram). It is common, however, to encounter more than one mode in a remote sensing dataset. The median is the value midway in the frequency distribution. One- half of the area below the distribution curve is to the right of the median, and one-half is to the left The mean The mean is the arithmetic average and is defined as the sum of all brightness value observations divided by the number of observations.
. It is common, however, to encounter more than one mode in a remote sensing dataset. The median is the value midway in the frequency distribution. One- half of the area below the distribution curve is to the right of the median, and one-half is to the left The mean The mean is the arithmetic average and is defined as the sum of all brightness value observations divided by the number of observations..")
13
Cont’ Min Max Variance Standard deviation Coefficient of variation (CV) Skewness Kurtosis Moment
 Skewness Kurtosis Moment")
15
Measures of Distribution (Histogram) Asymmetry and Peak Sharpness Skewness is a measure of the asymmetry of a histogram and is computed using the formula: A perfectly symmetric histogram has a skewness value of zero. If a distribution has a long right tail of large values, it is positively skewed, and if it has a long left tail of small values, it is negatively skewed. Skewness is a measure of the asymmetry of a histogram and is computed using the formula: A perfectly symmetric histogram has a skewness value of zero. If a distribution has a long right tail of large values, it is positively skewed, and if it has a long left tail of small values, it is negatively skewed.

16
A histogram may be symmetric but have a peak that is very sharp or one that is subdued when compared with a perfectly normal distribution. A perfectly normal distribution (histogram) has zero kurtosis. The greater the positive kurtosis value, the sharper the peak in the distribution when compared with a normal histogram. Conversely, a negative kurtosis value suggests that the peak in the histogram is less sharp than that of a normal distribution. Kurtosis is computed using the formula: Measures of Distribution (Histogram) Asymmetry and Peak Sharpness
 has zero kurtosis. The greater the positive kurtosis value, the sharper the peak in the distribution when compared with a normal histogram. Conversely, a negative kurtosis value suggests that the peak in the histogram is less sharp than that of a normal distribution. Kurtosis is computed using the formula: Measures of Distribution (Histogram) Asymmetry and Peak Sharpness.")
17
In this example Kurtosis does not subtract 3. http://www.itl.nist.gov/div898/handbook/eda/section3/eda35b.htm http://www.itl.nist.gov/div898/handbook/eda/section3/eda35b.htm

18
We can use ENVI/IDL to calculate them ENVI Entire image, Using ROI Using mask examples IDL examples

20
4. Multivariate Image Statistics Remote sensing research is often concerned with the measurement of how much radiant flux is reflected or emitted from an object in more than one band. It is useful to compute multivariate statistical measures such as covariance and correlation among the several bands to determine how the measurements covary. Later it will be shown that variance– covariance and correlation matrices are used in remote sensing principal components analysis (PCA), feature selection, classification and accuracy assessment.
, feature selection, classification and accuracy assessment..")
21
Covariance The different remote-sensing-derived spectral measurements for each pixel often change together in some predictable fashion. If there is no relationship between the brightness value in one band and that of another for a given pixel, the values are mutually independent; that is, an increase or decrease in one band’s brightness value is not accompanied by a predictable change in another band’s brightness value. Because spectral measurements of individual pixels may not be independent, some measure of their mutual interaction is needed. This measure, called the covariance, is the joint variation of two variables about their common mean.

22
Correlation To estimate the degree of interrelation between variables in a manner not influenced by measurement units, the correlation coefficient, is commonly used. The correlation between two bands of remotely sensed data, r kl, is the ratio of their covariance (cov kl ) to the product of their standard deviations (s k s l ); thus: If we square the correlation coefficient (r kl ), we obtain the sample coefficient of determination (r 2 ), which expresses the proportion of the total variation in the values of “band l” that can be accounted for or explained by a linear relationship with the values of the random variable “band k.” Thus a correlation coefficient (r kl ) of 0.70 results in an r 2 value of 0.49, meaning that 49% of the total variation of the values of “band l” in the sample is accounted for by a linear relationship with values of “band k”.
 to the product of their standard deviations (s k s l ); thus: If we square the correlation coefficient (r kl ), we obtain the sample coefficient of determination (r 2 ), which expresses the proportion of the total variation in the values of band l that can be accounted for or explained by a linear relationship with the values of the random variable band k. Thus a correlation coefficient (r kl ) of 0.70 results in an r 2 value of 0.49, meaning that 49% of the total variation of the values of band l in the sample is accounted for by a linear relationship with values of band k ..")
23
example Band 1(Band 1 x Band 2)Band 2 1307,41057 1655,77535 1002,50025 1356,75050 1459,42565 67531,860232 PixelBand 1 (green) Band 2 (red) Band 3 (ni) Band 4 (ni) (1,1)13057180205 (1,2)16535215255 (1,3)10025135195 (1,4)13550200220 (1,5)14565205235
Band , , , , , , PixelBand 1 (green) Band 2 (red) Band 3 (ni) Band 4 (ni) (1,1) (1,2) (1,3) (1,4) (1,5)")
24
Band 1Band 2Band 3Band 4 Mean ( k ) 13546.40187222 Variance (var k )562.50264.801007570 (sk)(sk)23.7116.2731.423.87 (min k )10025135195 (max k )16565215255 Range (BV r )65408060 Band 1Band 2Band 3Band 4 Band 1562.25--- Band 2135264.80-- Band 3718.75275.251007.50- Band 4537.5064663.75570 Univariate statistics covariance Band 1 Band 2 Band 3 Band 4 Band 1---- Band 20.35--- Band 30.950.53-- Band 40.940.160.87- Covariance Correlation coefficient
 Variance (var k ) (sk)(sk) (min k ) (max k ) Range (BV r ) Band 1Band 2Band 3Band 4 Band Band Band Band Univariate statistics covariance Band 1 Band 2 Band 3 Band 4 Band Band Band Band Covariance Correlation coefficient")
25
Feature space plot, or 2D scatter plot in ENVI Individual bands of remotely sensed data are often referred to as features in the pattern recognition literature. To truly appreciate how two bands (features) in a remote sensing dataset covary and if they are correlated or not, it is often useful to produce a two-band feature space plot Demo of 2D scatter plot in ENVI Bright areas in the plot represents pixel pairs that have a high frequency of occurrence in the images If correlation is close to 1, then all points will be almost in 1:1 lines
 in a remote sensing dataset covary and if they are correlated or not, it is often useful to produce a two-band feature space plot Demo of 2D scatter plot in ENVI Bright areas in the plot represents pixel pairs that have a high frequency of occurrence in the images If correlation is close to 1, then all points will be almost in 1:1 lines.")
Similar presentations
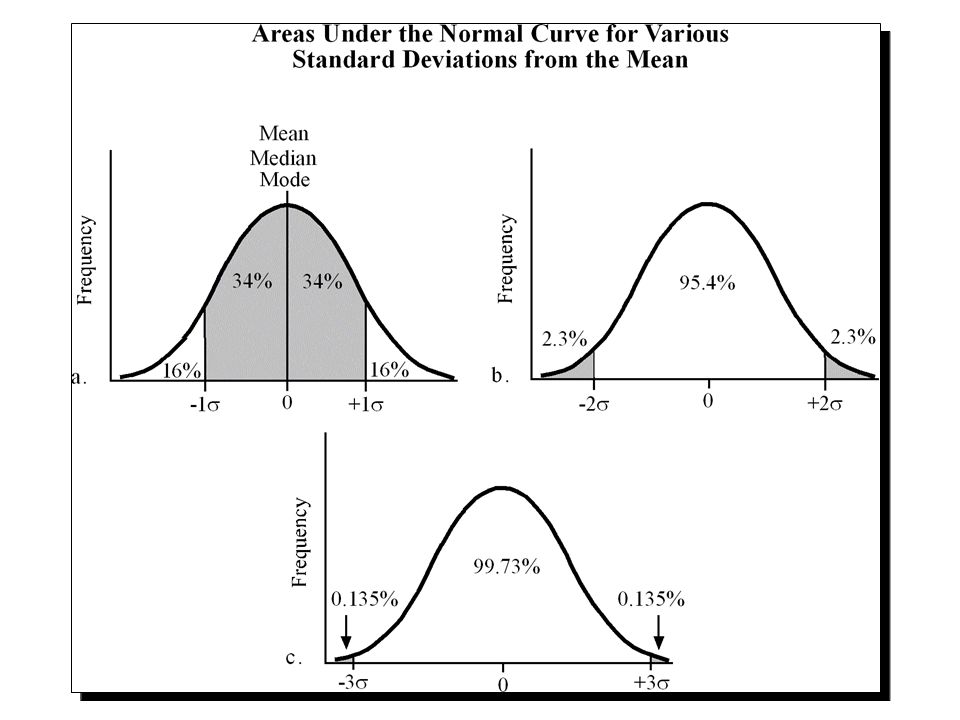






 Image Quality Assessment Radiometric Correction Geometric Correction Image Classification Introduction.>")













