Download presentation
Presentation is loading. Please wait.

1
Todd Tannenbaum Computer Sciences Department University of Wisconsin-Madison condor-admin@cs.wisc.edu http://www.cs.wisc.edu/condor Condor RoadMap Condor Week 2007

2
2 Current Situation › Stable Series Current: Condor ver 6.8.4. (Feb 5th) › Development Series Current : Condor ver 6.9.2. (April 10th)
 › Development Series Current : Condor ver (April 10th).")
3
3 Major v6.9 Changes › Virtual Machine Universe See Jaeyoung’s talk › Quill 2.0 See Jeff and Erik’s talk › Scalability Improvements › GCB Improvements › Privilege Separation

4
4 Team Scalability! Dan “Two-Faces” Bradley (half CMS, half Condor), “Papa” Todd Tannenbaum, and “Uncle” Greg Thain
, Papa Todd Tannenbaum, and Uncle Greg Thain.")
5
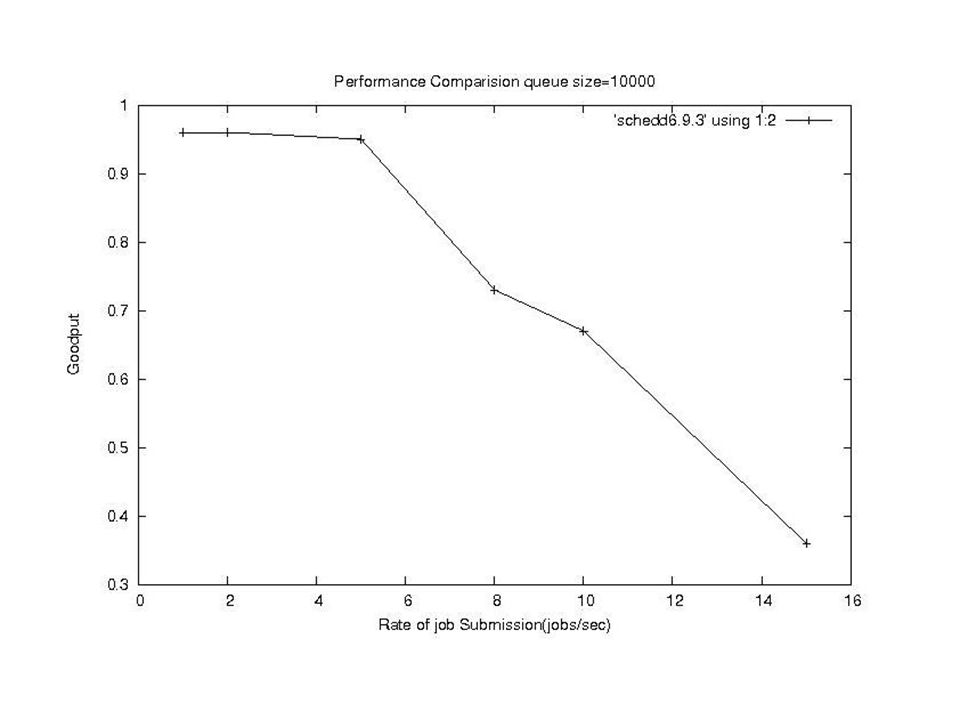
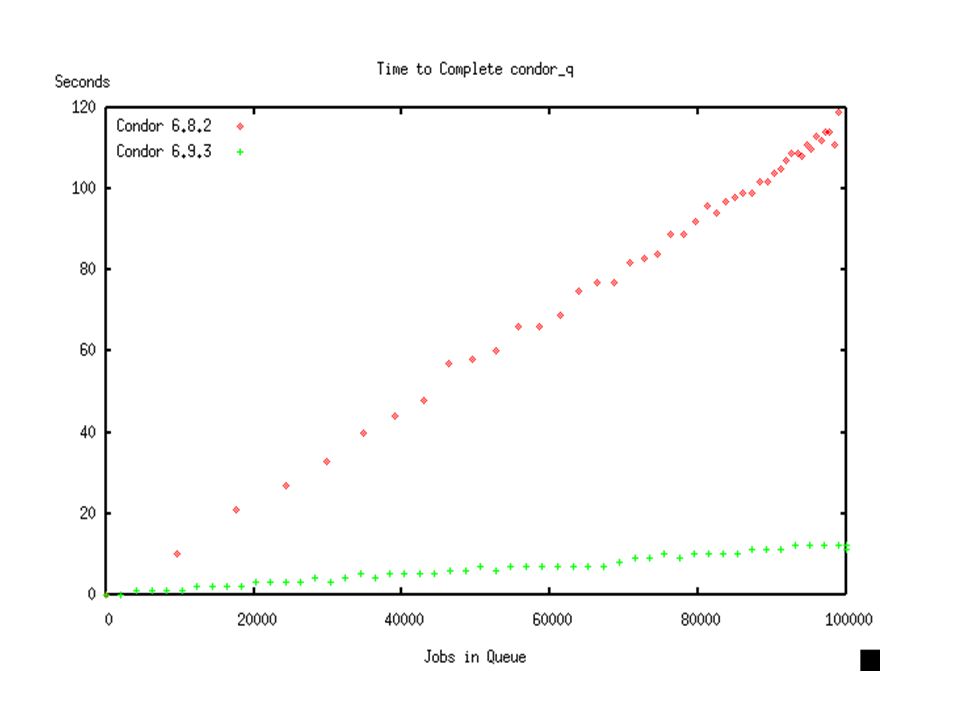
The new condor_q GUI?

7
7 How we looked… › Intuition / Heated hallway discussion › Wagering › Examination of the log files › Some Tools callgrind and kcachegrind Or Compuware DevPartner on Win32 gprof strace tcpdump

8
8 What we found… › Inappropriate Data Structures › Deadly embraces › Implementation issues Bad hash function, table sizes Buffer copy, copy, copy, copy, copy, copy “I am sooo embarrassed!” schedd Bill and Monica

9
9 What we did… › More non-blocking I/O in critical areas to eliminate timeouts/embraces › Cleansed a bunch o embarrassments › Reuse of a claim Carefully cache candidate jobs Use “autoclusters” › Auto-adapting parameters based on workload Old way: “do some bookeeping every 5 seconds” New way: “spend 5% of time doing bookeeping”

10
10 Creepy fork() Got This: 0.125sec/fork!Wanted this:
 Got This: 0.125sec/fork!Wanted this:")
11
11 Lets fix this one, please. (patch circa 2003)
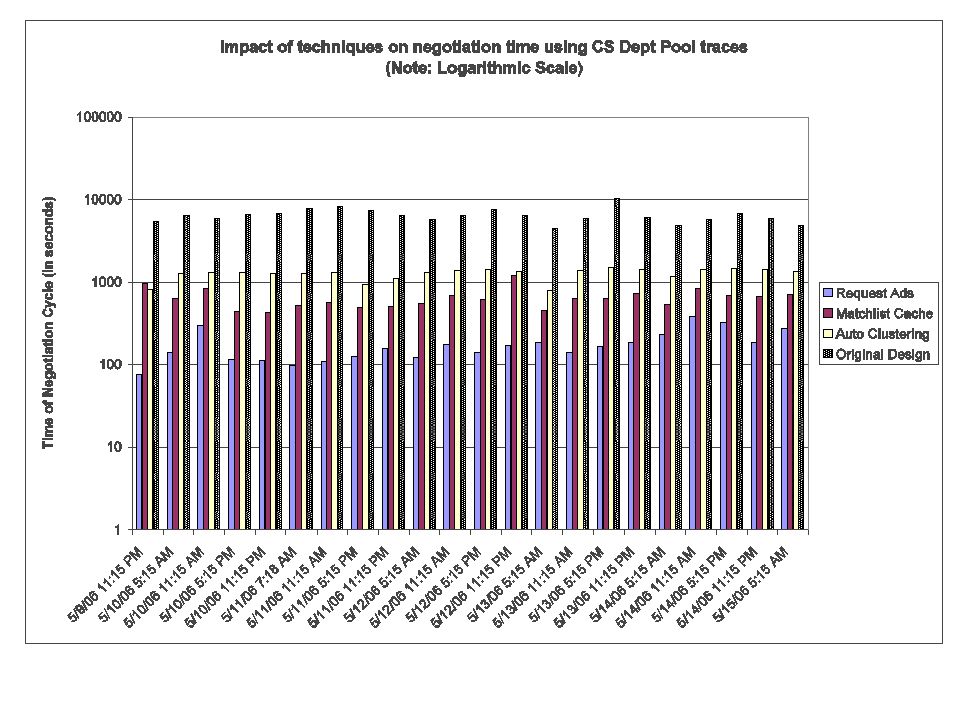
")
12
12 And last but not least, thanks you to Buffered writes to schedd transaction log (i.e. Francesco Prelz!) Numerous scalability improvements to Condor-C
 Numerous scalability improvements to Condor-C.")
13
13 Let’s see some results to date

15
15 SWEEEEET!! Todd, lets see that graph again!!!

21
21 condor_q performance (sans Quill) › Already done batch sending of ads (eliminate latency, let tcp window warm up) projection of attributes (note : now “condor_q –l” more expensive than "condor_q -format"). › Still Todo ? i/o in another thread href protocol on the wire caching of parsed expressions -- classads are very redundant same improvements into condor_status

23
23 Collector Performance › Fixing Dropped updates increased incoming buffer sizes; problems caused by synchronization via condor_reconfig -all etc. Also, with Winsock, UDP sendto() is always successful. (!) › Added DNS caching for unauthenticated connections in Condor. profiling was important; we had no suspicion this was the problem. Collector was spending 20% of its time in the DNS resolver library! › Todo: Ian Alderman discovered non-blocking communication assumptions violated by authentication methods that require round-trips.
 is always successful. (!) › Added DNS caching for unauthenticated connections in Condor. profiling was important; we had no suspicion this was the problem. Collector was spending 20% of its time in the DNS resolver library. › Todo: Ian Alderman discovered non-blocking communication assumptions violated by authentication methods that require round-trips..")
25
25 Negotiation Performance › v6.8 -> automatic “significant attributes”. › v6.9 -> “resource request” ads Simple explanation: Resource request ad == a count plus all significant attributes. Inserted into a schedd submitter ad. “Give me 400 resources like this, and 200 resources like that, etc”. › Matchmaking algorithms remains the same, just how it “learns” about jobs changes. › Disabled by default. › Possibilities, possibilities… More robust against unresponsive schedds No startd Rank preemption? Others?

26
26 Impact of negotiation changes › UW CS Pool – Negotiation cycle times: 2583 seconds baseline Dropped to 366 secs w/ autoclustering Add matchlist caching, dropped to 223 secs Add resource request ads, drops again to 129 seconds. CM memory footprint increased by 80k.

28
28 Team GCB! Derek “Mr. Follow-CVS-rules-or-ELSE” Wright, Alan “Ask me about Social Security #s” DeSmet, and Jaime “The GridMan” Frey

29
29 › Improved Scalability: Only use the broker if required! Local Host Optimizations (6.9.1) Bypass GCB if two daemons are talking on the same host Local Network Optimizations (6.9.3) Two hosts on the same private net bypass the broker Every network is assigned a unique network name Daemons advertise (a) public accessible IP; (b) real IP; (c) network name. Names match ? use real ip : use public IP. › Improved Robustness Broker dies -> master finds another broker and restarts. When master starts up, it pings a list o brokers and randomly chooses from those that respond. Bug fixes › Improved Logging – now they are helpful and sane.
 Bypass GCB if two daemons are talking on the same host Local Network Optimizations (6.9.3) Two hosts on the same private net bypass the broker Every network is assigned a unique network name Daemons advertise (a) public accessible IP; (b) real IP; (c) network name. Names match . use real ip : use public IP. › Improved Robustness Broker dies -> master finds another broker and restarts. When master starts up, it pings a list o brokers and randomly chooses from those that respond. Bug fixes › Improved Logging – now they are helpful and sane..")
30
30 Team Privilege Separation! “Cousin” Greg Quinn, Pete “Psilord” Keller, and Zach “When the grid relaxes, its Zmiller time” Miller

31
31 Condor’s Privilege Separation › Apply principle of least privilege to Condor › No more root / super- user privilege required › Currently completed on execute side (v6.9.3), “almost” on submit side › Use glexec or Condor’s own sudo › Can still run the “old way” if you want › Refer to Greg Quinn’s Talk
, almost on submit side › Use glexec or Condor’s own sudo › Can still run the old way if you want › Refer to Greg Quinn’s Talk")
32
32 Minor v6.9 changes › Leases added to COD. › Simple best-fit algorithm added to dedicated scheduler. › Can reference resource usage and quota information in preemption policy. › condor_config_val –dump [-v] › Chirp improvements Jobs can write messages into the user log Can use proc 0 ClassAd as a “scratch pad” › Condor shutdown via expressions External Awareness Plug: Talk w/ Joe Meehan @ the Research BOF!

33
33 Minor v6.9 changes, cont. › More types of jobs can survive across a shutdown/crash of submit machine Such as jobs that stream stdout/err. › User’s job log changes. Can have a centralized job log file. Get values of any job ad attribute in log.

34
34 Hoping for v6.9, but no promises › Rich Wolski’s prediction work › Support for VOMS attributes › Update condor binaries on job boundaries › Secure install by default Via pool password?

35
35 So 2-3 more developer releases, then new stable series Condor 7.0 (… or Condor Vista? … ) And the next developer series after v6.9 ?
 And the next developer series after v6.9 .")
36
Terms of License Any and all dates in these slides are relative from a date hereby unspecified in the event of a likely situation involving a frequent condition. Viewing, use, reproduction, display, modification and redistribution of these slides, with or without modification, in source and binary forms, is permitted only after a deposit by said user into PayPal accounts registered to Todd Tannenbaum ….

37
37 Beyond v6.9 › For the next year, so far we have identified the following intial focus areas: Continue our work w/ Storage Management (MOPS) Refer to Dan Fraser’s talk Continue our work w/ Virtual Machines Refer to Jaeyoung Yoon’s talk Scheduling Work Startd Enhancements
 Refer to Dan Fraser’s talk Continue our work w/ Virtual Machines Refer to Jaeyoung Yoon’s talk Scheduling Work Startd Enhancements")
38
38 Scheduling in Condor Today CM schedd CMschedd startd › Distributed Ownership › Settings reflect 3 separate viewpoints: Pool manager, Resource Owner, Job Submitter

39
39 But some sites want to use Condor like this: schedd startd › Just one submission point (schedd) › All resources owned by one entity › We can do better for these sites. Policy configurations are complicated. Some useful policies not present because they are hard to do a wide-area distributed system. Today the dedicated “scheduler” only supports FIFO and a naive Best Fit algorithms.

40
40 So what to do? schedd startd › Give the schedd more scheduling options. Examples: why can’t the schedd do priority preemption without the matchmakers help? Or move jobs from slow to fast claimed resources ? › Pluggable scheduler routines.

41
41 StartD Enhancements: New sources of work › Condor-G enabled the SchedD to talk to many different scheduling systems to run jobs… › Now the StartD will be able to talk to different managers to fetch jobs and work. › StartD configured to be “claimed at boot” so that you don’t need the overhead of match-making. › Don’t necessarily need a SchedD -- fetch jobs (work units) from other systems (DB of jobs, etc).
 from other systems (DB of jobs, etc)..")
42
42 StartD Enhancements: Dynamic slots › Currently, resource slots are static -- some changes require restarting the StartD. › Would like to add dynamic computing slots: Dual-core machines are ubiquitous. 1 or 2 gigs of RAM is “commodity”. Instead of statically partitioning the RAM (1 gig for each slot), it’d be nice to advertise “2 CPUs, 2 gigs of RAM”, and once 1 CPU is claimed for 1/2 gig, to advertise “1 CPU, 1.5 gigs of RAM” for the other slot.
, it’d be nice to advertise 2 CPUs, 2 gigs of RAM , and once 1 CPU is claimed for 1/2 gig, to advertise 1 CPU, 1.5 gigs of RAM for the other slot..")
43
43 StartD Enhancements: Dynamic slots (cont’d) › Can also be used to simplify complex policies: Currently “checkpoint to swap” implemented with static slots and pre-configured policy. Would like to just dynamically allocate new slots, and make it easier to have global, slot-wide policy expressions, not just per-slot policies. › Could have implications for COD, GlideIn and other uses of the StartD… GlideIn under an existing Condor pool might just allocate a new slot on the “parent” StartD, instead of spawning a whole new StartD under the parent StartD COD claims could allocate new dynamic slots, too…

44
44 Thank you!

Similar presentations









 Se-Chang Son (University of.>")
















