Download presentation
Presentation is loading. Please wait.

1
Synchronization

2
Synchronization Difficult to implement synchronization in distributed environment Memory is not shared Clock is not shared Decisions are usually based on local information Centralized solutions undesirable (single point of failure, performance bottleneck) Synchronization mechanisms used to facilitate cooperative or competitive sharing Clock synchronization Event ordering Mutual exclusion Deadlock Election algorithms
 Synchronization mechanisms used to facilitate cooperative or competitive sharing. Clock synchronization. Event ordering. Mutual exclusion. Deadlock. Election algorithms.")
3
Clock synchronization
Timer mechanism used to keep track of current time, accounting purposes, measure duration of distributed activities that starts on one node and terminates on another node etc. Computer Clocks A quartz crystal that oscillates at fixed frequency. A counter register whose value is decremented by one for every oscillation of quartz crystal. A constant register to reinitialize counter register when its value becomes zero & an interrupt is generated.

4
Drifting of Clocks Differences in crystals result in difference in the rate at which two clocks run. Due to difference accumulated over time computer clocks drifts from real time clock used for their initial setting. If ρ is maximum drift rate allowable, a clock is said to be non-faulty if : 1- ρ ≤ dc/dt ≤ 1+ ρ The nodes of a distributed system must periodically resynchronize their local clocks to maintain a global time base across the entire system.

5
Clock Drift

6
Synchronization techniques
External Synchronization Synchronization with real time (external) clocks Synchronized to UTC (Coordinated Universal Time) Mutual (Internal) Synchronization For consistent view of time across all nodes of the system External Synchronization ensures internal synch.
 clocks. Synchronized to UTC (Coordinated Universal Time) Mutual (Internal) Synchronization. For consistent view of time across all nodes of the system. External Synchronization ensures internal synch.")
7
Issues in Clock synchronization
The difference in time values of two clocks is called clock skew . Set of clocks are said to be synchronized if the clock skew of any two is less than δ (Specified constant). A node can obtain only an approximate view of its clock skew with respect to other nodes’ clocks in the system, due to unpredictable communication delays. Readjustments done for fast/ slow running clocks If time of a fast clock readjusted to actual all at once, might result in running time backward for that clock. Use intelligent interrupt routine.
. A node can obtain only an approximate view of its clock skew with respect to other nodes’ clocks in the system, due to unpredictable communication delays. Readjustments done for fast/ slow running clocks. If time of a fast clock readjusted to actual all at once, might result in running time backward for that clock. Use intelligent interrupt routine.")
8
Question: A distributed system has 3 nodes n1, n2, n3 each having its own clock. The clock at nodes n1, n2, n3 tick 495, 500 & 505 times per millisecond. The system uses external clock synchronization mechanism in which all nodes receive real time every 20 seconds from an external file source & readjust their clocks. What is the maximum clock skew that will occur in this system?

9
Answer: n1 = .495 s, n2= .500 s, n3 = .505 s Maximum skew in 1 sec between n1 & n3 = ( ) = .010 sec Thus, skew in 20 sec = .010 * 20 = .2 sec

10
Synchronization algorithms
Active Time Server Passive Time Centralized Algorithms Distributed Algorithms Global Averaging Local Averaging

11
Centralized Algorithms
Keep the clocks of all nodes synchronized with the clock time of the time server node, a real time receiver. Drawbacks Single point of failure Poor scalability Passive time server centralized algorithm Active time server centralized algorithm

12
Passive Time Server Centralized
Each node periodically sends message (“time=?”) to the time server Server responds by sending (“time = T”) After receiving client adjusts time to T+ (T1-T0)/2 (T0 – time when client sent request, T1 - time of client when received reply, thus message propagation time one way is ((T1-T0)/2) T+ (T1-T0- I)/2, I is time taken by time server to handle time request message T+ (average (T1-T0))/2
 to the time server. Server responds by sending ( time = T ) After receiving client adjusts time to. T+ (T1-T0)/2. (T0 – time when client sent request, T1 - time of client when received reply, thus message propagation time one way is ((T1-T0)/2) T+ (T1-T0- I)/2, I is time taken by time server to handle time request message. T+ (average (T1-T0))/2.")
13
Active Time Server Centralized
Time server node periodically broadcasts clock time (“time=T”) Time of propagation (Ta) from server to client is known to all clients Client adjusts time to T + Ta Drawbacks Not fault tolerant in case message reaches too late at a node, its clock will be adjusted to wrong value Requires broadcast facility Drawbacks overcome by Berkeley algorithm
 Time of propagation (Ta) from server to client is known to all clients. Client adjusts time to T + Ta. Drawbacks. Not fault tolerant in case message reaches too late at a node, its clock will be adjusted to wrong value. Requires broadcast facility. Drawbacks overcome by Berkeley algorithm.")
14
Berkeley Algorithm Used for internal clock synchronization of a group
Time server periodically sends a message (“time=?”) to all computers in the group Each computer in the group sends its clock value to the server Server has prior knowledge of propagation time from node to server Time server readjusts the clock values of the reply messages using propagation time & then takes fault tolerant average The time server readjusts its own time & sends the adjustment (positive or negative) to each node
 to all computers in the group. Each computer in the group sends its clock value to the server. Server has prior knowledge of propagation time from node to server. Time server readjusts the clock values of the reply messages using propagation time & then takes fault tolerant average. The time server readjusts its own time & sends the adjustment (positive or negative) to each node.")
15
Distributed Algorithms
All nodes are equipped with real time receiver so that each node’s clock is independently synchronized with real time External synchronization also results in internal synchronization. Internal synchronization performed for better results Global averaging distributed algorithms Localized averaging distributed algorithms

16
Global Averaging Distributed Algorithms
Local time with “resync” message is broadcasted from each node at beginning of every fixed length resynchronization interval T0+iR, R is system parameter. All broadcasts do not happen simultaneously due to difference in local clocks. Broadcasting node waits for time T during which it collects “resync” messages by other nodes & records time of receipt according to its own clock. At the end of waiting time, it estimates the skew of its clock with respect to other nodes on the basis of times at which it received “resync” messages. Calculate fault tolerant average of estimated skews & uses it to correct its own local clock before restart of next “resync” interval

17
Localized Averaging Distributed Algorithms
Nodes of a DS are logically arranged in some kind of pattern, such as ring or a grid. Periodically, each node exchanges its clock time with its neighbors in the ring, grid etc. It then sets its clock time to the average of its own clock time and the clock time of its neighbors.

18
Event Ordering Observations by Lamport
If two processes do not interact, it is not necessary to keep their clocks synchronized. All processes need not agree on exactly what time it is, rather they agree on the order in which events occur. Events can be Procedure invocation Instruction execution Message exchange (Send/ Receive) Defined relation happened before, for partial ordering of events.
 Defined relation happened before, for partial ordering of events.")
19
Happened Before Relation
Happened before relation ( casual ordering) If a and b are events in the same process, and a occurs before b then a→ b is true. If a is the event of a message being sent by one process, and b is the event of the message being received by another process, then a → b is also true. If a → b and b → c, then a → c (transitive). Irreflexive, a → a not true Concurrent Events - events a and b are concurrent (a||b) if neither a → b nor b → a is true.
 If a and b are events in the same process, and a occurs before b then a→ b is true. If a is the event of a message being sent by one process, and b is the event of the message being received by another process, then a → b is also true. If a → b and b → c, then a → c (transitive). Irreflexive, a → a not true. Concurrent Events - events a and b are concurrent (a||b) if neither a → b nor b → a is true.")
20
Space-time Diagram for three processes
Process P1 Process P2 Process P3 e10 e11 e12 e13 e22 e30 e31 e32 e21 e20 e23 e24 Time Casually ordered events => (e10→e11), (e20 →e24), (e21 →e23), (e21 →e13), (e30 →e24), (e11 →e32) Concurrent events => (e12, e20), (e21,e30),(e10,e30),(e12,e32),(e13,e22)
, (e20 →e24), (e21 →e23), (e21 →e13), (e30 →e24), (e11 →e32) Concurrent events => (e12, e20), (e21,e30),(e10,e30),(e12,e32),(e13,e22)")
21
Question List all pairs of concurrent events according to happened before relation. Process P1 Process P2 e1 e2 e3 e4 e7 e6 e5 e8 e9 Time

22
Logical Clocks Need globally synchronized clocks to determine a → b
Rather use Logical clock concept Associate timestamp with every event Timestamps assigned to events by logical clocks must follow clock condition : if a → b, then C(a) < C(b) Conditions to follow to satisfy clock condition If a occurs before b in process Pi then Ci(a) < Ci(b) If a is the sending of a message by process Pi and b is the receipt of that message by process Pj then Ci(a) <Cj(b) Clocks should always go forward, that is corrections should be positive value To meet the above conditions : Lamport’s algorithm
 < C(b) Conditions to follow to satisfy clock condition. If a occurs before b in process Pi then Ci(a) < Ci(b) If a is the sending of a message by process Pi and b is the receipt of that message by process Pj then Ci(a) <Cj(b) Clocks should always go forward, that is corrections should be positive value. To meet the above conditions : Lamport’s algorithm.")
23
The implementation rules of lamport’s algorithm
IR1 : Each process Pi increments Ci between any two events IR2 : If event a is the sending of message m by process Pi the message m contains a timestamp Tm = Ci(a). Upon receiving the message m, a process Pj sets Cj greater than or equal to its present value but greater than Tm
. Upon receiving the message m, a process Pj sets Cj greater than or equal to its present value but greater than Tm.")
24
Implementation of Logical Clock using Counters
All processors have counters acting as logical clocks. Counters initialized to zero & incremented by 1 whenever an event occurs in that process. On sending of a message, the process includes the incremented value of the counter in the message. On receiving the message, counter value incremented by 1 & then checked against counter value received with message. If counter value is less than that of received message, the counter value set to (timestamp in the received message + 1). Ex. e13. If not , the counter value is left as it is. Ex. e08
. Ex. e13. If not , the counter value is left as it is. Ex. e08.")
25
Implementation of Logical Clock
Timestamp=4 Timestamp=6 Process 1 Process 2 time

26
Implementation of Logical Clock using Physical Clocks

27
Example: Three processes that run on different machines, each with its own clock, running at its own speed. When the clock has ticked 6 times in process 0, it has ticked 8 times in process 1 and 10 times in process 2. Each clock runs at a constant rate, but the rates are different due to differences in the crystals. At time 6: process 0 sends message A to process 1. The clock in process 1 reads 16 when it arrives. If the message carries the starting time 6 in it, process 1 will conclude that it took 10 ticks to make the journey. According to this reasoning, message B from 1 to 2 takes 16 (40 – 24) ticks, again a plausible value. Message from 2 to 1 leaves at 60 and arrives at 56. Impossible! Message D from 1 to leaves at 64 and arrives at 54. Impossible!
 ticks, again a plausible value. Message from 2 to 1 leaves at 60 and arrives at 56. Impossible! Message D from 1 to leaves at 64 and arrives at 54. Impossible!")
28
Lamport's solution: Each message carries the sending time, according to the sender's clock. When a message arrives and the receiver's clock shows a value prior to the time the message was sent, the receiver fast forwards its clock to be one more than the sending time. Since C left at 60, it must arrive at 61 or later. On the right we see that C now arrives at 61. Similarly, D arrives at 70.

29
Total Ordering No two events ever occur at exactly the same time.
Say events a & b occur in processes P1 & P2 respectively, at time 100 according to their clocks. Process identity numbers are used to create their ordering. Timestamp of a is (process id of P1 is 001) & of b is (process id of P2 is 002)
 & of b is (process id of P2 is 002)")
30
Mutual Exclusion Exclusive access to shared resources achieved by critical sections & mutual exclusion. Conditions to be satisfied by mutual exclusion: Mutual exclusion - Given a shared resource accessed by multiple concurrent processes, at any time only one process should access the resource. A process that has been granted the resource must release it before it can be granted to another process. No starvation – If every process that is granted resource eventually releases it, every request will be eventually granted.

31
Centralized Approach Coordinator coordinates entry to critical section
Allows only one process to enter critical section. Ensures no starvation as uses first come, first served policy. Simple implementation 3 messages per critical section – request, reply, release Single point of failure & performance bottleneck.

32
Centralized Approach Pc Status of request queue Initial state P2
Status after 3 Status after 4 Status after 5 Status after 7 8 Reply 9 Release P1 Pc 5 Release 2 Reply 1 Request 4 Request 3 Request 7 Release 6 Reply

33
Distributed Approach Ricart & Agrawala’s Algorithm
When a process wants to enter the CS, it sends a request message to all other processes, and when it receives reply from all processes, then only it is allowed to enter the CS. The request message contains following information: Process identifier Name of CS Unique time stamp generated by process for request message

34
The decision whether receiving process replies immediately to a request message or defers its reply is based on three cases: If receiver process is in its critical section, then it defers its reply If receiver process does not want to enter its critical section, then it immediately sends a reply. If receiver process itself is waiting to enter critical section, then it compares its own request timestamp with the timestamp in request message If its own request timestamp is greater than timestamp in request message, then it sends a reply immediately. Otherwise, the reply is deferred

35
Distributed Approach P1 P4 P2 P3 TS=4 TS=6 Already in CS a b OK P3 P4
Defer sending reply to P1 and p2 Queue Defer sending a reply to P1

36
Exits CS P4 P3 P2 P1 OK Queue Enters CS c P3 P4 P2 P1 OK Exits CS Enters CS d

37
Guarantees mutual exclusion as a process enters critical section only after getting permission from all other processes. Guarantees no starvation as scheduling done according to timestamp ordering. If there are n processes, 2(n-1) messages (n-1 request & n-1 reply) are required per critical section entry.
 messages (n-1 request & n-1 reply) are required per critical section entry.")
38
Drawbacks N points of failure in a system of n processes. All requesting processes have to wait indefinitely if one process fails. Send “permission denied” instead of deferring reply & “ok” when permission granted. The processes need to know the identity of all other processes in the system, which makes the dynamic addition and removal of processes more complex. Suitable for groups whose member processes are fixed. Process enters critical section after exchange of 2(n-1) messages. Waiting time for exchanging 2(n-1) messages can be quite large. Suitable for small group of co-operating processes.
 messages. Waiting time for exchanging 2(n-1) messages can be quite large. Suitable for small group of co-operating processes.")
39
Token Passing Approach
Processes organized in logical ring Single token circulated among processes in system Token holder allowed to enter critical section On receiving token, process: If it wants to enter CS, keeps token & enters CS. It passes token to its neighbor on leaving CS. A process can enter only one CS when it receives the token. If it does not want to enter CS, it passes token to its neighbor.

40
Mutual exclusion achieved as single token present.
No starvation as ring is unidirectional & a process is permitted to enter only one CS at a time. Number of messages per CS vary from 1 to unbounded value. Wait time to enter a CS varies from 0 to n-1 messages.

41
Two types of failure can occur:
Process failure Requires detection of failed process & dynamic reconfiguration of logical ring Process receiving token sends back acknowledgement to neighbor When a process detects failure of neighbor, it removes failed process by skipping it & passing token to process after it. Lost token Must have mechanism to detect & regenerate token Designate process as monitor. Monitor periodically circulates “who has token” Owner of token writes its process identifier in message & passes on. On receipt of message, monitor checks process identifier field. If empty generate new token & passes it. Multiple monitors can be used.

42
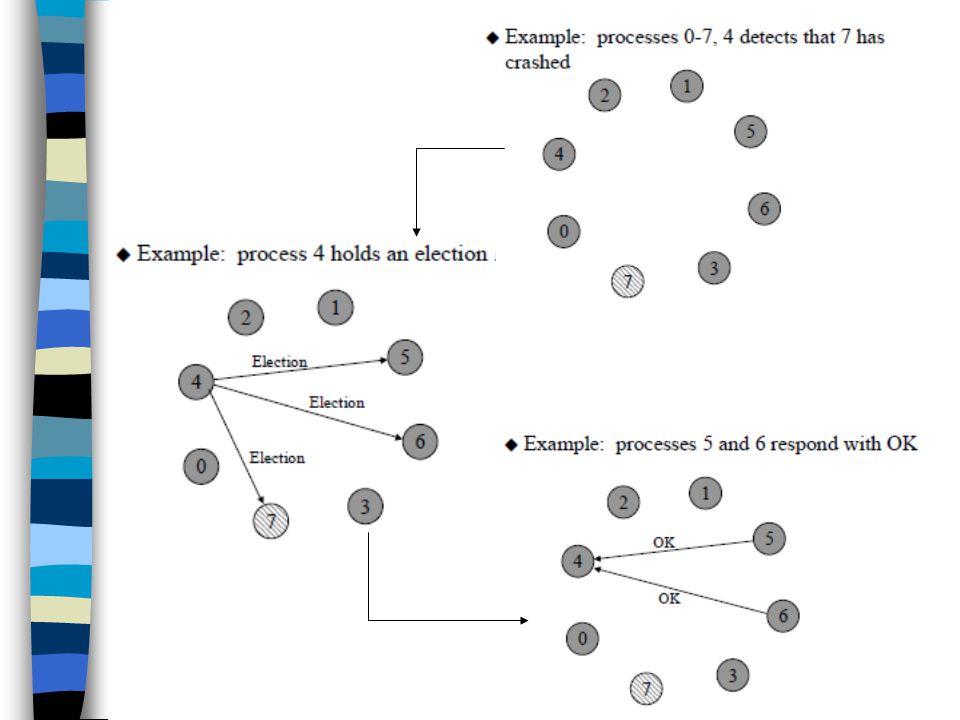
Election Algorithm Used for electing a coordinator process from among the currently running processes in such a manner that at any instance of time there is a single coordinator for all processes in the system. Election algorithms based on assumptions: Each process has unique priority number. Highest priority process among currently active processes is elected as the coordinator. On recovery, a failed process can rejoin the set of active processes.

43
Bully Algorithm Assumes that every process knows priority of every other process in the system. When a process Pj does not receive reply of request from coordinator within a fixed time period, it assumes that the coordinator has failed. Pj initiates election by sending message to the processes having priority higher than itself If Pj does not receive any reply, it takes up job of the coordinator & sends message to all processes with lower priority about it being new coordinator. If Pj receives any reply, process with higher priority is alive. Processes with higher priority now take over election activity. The highest priority process (that does not receive any reply) becomes new coordinator.
 becomes new coordinator.")
46
A failed process initiates election on recovery.
If process with highest priority recovers from failure, it simply sends a coordinator message to all other processes & bullies current coordinator into submission. In a system of n processes when process with lowest priority detects coordinator’s failure, n-2 elections are performed. O(n2) messages If process just below coordinator detects its failure, it elects itself as coordinator & sends n-2 messages. On process failure recovery, depending upon process priority O(n2) messages in worst case, n-1 messages in best case are required.
 messages. If process just below coordinator detects its failure, it elects itself as coordinator & sends n-2 messages. On process failure recovery, depending upon process priority O(n2) messages in worst case, n-1 messages in best case are required.")
47
Ring Algorithm Processes are ordered Each process knows its successor
No token involved Any process noticing that the coordinator is not responding sends an election message with its priority number to its next live successor Receiving process adds its priority number to the message and passes it along When message gets back to election initiator, it elects the process having the highest priority number as the coordinator and changes message to coordinator & circulates to all members Coordinator is process with highest priority number

48
When failed process recovers it does not initiate election
When failed process recovers it does not initiate election. It simply circulates the inquiry message in the ring to find current coordinator. If more than one process detects a crashed coordinator? More than one election will be produced but all messages will contain the same information (member process numbers, order of members). Same coordinator is chosen (highest number). Irrespective of which process detects error, election always require 2(n-1) messages. More efficient & easier to implement
. Same coordinator is chosen (highest number). Irrespective of which process detects error, election always require 2(n-1) messages. More efficient & easier to implement.")
Similar presentations










 2007 Prentice-Hall, Inc. All rights reserved. 0-13-239227-5 1 DISTRIBUTED.>")









