Download presentation
Presentation is loading. Please wait.

2
Statistical inference uses impersonal chance to draw conclusions about a population or process based on data drawn from a random sample or randomized experiment.

3
When data are produced by random sampling or randomized experiment, a statistic is a random variable that obeys the laws of probability.

4
A sampling distribution shows how a statistic would vary with repeated random sampling of the same size and from the same population. A sampling distribution, therefore, is a probability distribution of the results of an infinitely large number of such samples.

5
A population distribution of a random variable is the distribution of its values for all members of the population. Thus a population distribution is also the probability distribution of the random variable when we choose one individual (i.e. observation or subject) from the population at random.
 from the population at random..")
6
Recall that a sampling distribution is a conceptual ideal: it helps us to understand the logic of drawing random samples of size-n from the same population in order to obtain statistics by which we make inferences about a parameter. Population distribution is likewise a conceptual ideal: it tells us that sample statistics are based on probabilities attached to the population from which random samples are drawn.

7
Counts & Sample Proportions

8
Count: random variable X is a count of the occurrences of some outcome—of some ‘success’ versus a corresponding ‘failure’— in a fixed number of observations. A count is a discrete random variable that describes categorical data (concerning success vs. failure).
..")
9
Sample proportion: if the number of observations is n, then the sample proportion of observations is X/n. A sample proportion is also a discrete random variable that describes categorical data (concerning success vs. failure).
..")
10
Inferential statistics for counts & proportions are premised on a binomial setting.

11
The Binomial Setting 1.There are a fixed number n of observations. 2. The n observations are all independent. 3. Each observation falls into one of just two categories, which for convenience we call ‘success’ or ‘failure.’ 4.The probability of a success, p, is the same for each observation. 5.Strictly speaking, the population must be at least 20 times greater than the sample for counts, 10 times greater for proportions.

12
Counts The distribution of the count X of successes in the binomial setting is called the binomial distribution with parameters n & p (i.e. number of observations & probability of success on any one observation). X is B(n, p)
. X is B(n, p).")
14
Finding binomial probabilities: use factorial, binomial table, or software. Binomial mean & standard deviation:

15
Example: An experimental study finds that, in a placebo group of 2000 men, 84 got heart attacks, but in a treatment group of another 2000, just 56 got heart attacks. That is, 2000 independent observations of men have found count X of heart attacks is B(2000, 0.04), so that:. mean=np=(2000)(.04)=80. sd=sqrt(2000)(.04)(.96)=8.76
, so that:. mean=np=(2000)(.04)=80. sd=sqrt(2000)(.04)(.96)=8.76.")
16
Treatment group. bitesti 2000 56.04 N Observed k Expected k Assumed p Observed p -------------------------------------------------------------------- 2000 56 80 0.04000 0.02800 Pr(k >= 56) = 0.998333 (one-sided test) Pr(k <= 56) = 0.002497 (one-sided test) Pr(k = 106) = 0.005090 (two-sided test) So, it’s quite unlikely (p=.002) that there would be <=56 heart attacks by chance: the treatment looks promising. What about the placebo group?
 = (one-sided test) Pr(k <= 56) = (one-sided test) Pr(k = 106) = (two-sided test) So, it’s quite unlikely (p=.002) that there would be <=56 heart attacks by chance: the treatment looks promising. What about the placebo group .")
17
Placebo group. bitesti 2000 84.04 N Observed k Expected k Assumed p Observed p ----------------------------------------------------------------- 2000 84 80 0.04000 0.04200 Pr(k >= 84) = 0.339428 (one-sided test) Pr(k <= 84) = 0.700670 (one-sided test) Pr(k = 84) = 0.647786 (two-sided test) By contrast, it’s quite likely (p=.70) that the heart attack count in the placebo group would occur by chance. By comparison, then, the treatment looks promising.
 = (one-sided test) Pr(k <= 84) = (one-sided test) Pr(k = 84) = (two-sided test) By contrast, it’s quite likely (p=.70) that the heart attack count in the placebo group would occur by chance. By comparison, then, the treatment looks promising..")
18
Required Sample Size, Unbiased Estimator Strictly speaking, he population must be at least 20 times greater than the sample for counts (10 times greater for proportions). The formula for the binomial mean signifies that np is an unbiased estimator of the population mean.

19
Binomial test example (pages 370-71): Corinne is a basketball player who makes 75% of her free throws. In a key game, she shoots 12 free throws but makes just 7 of them. What are the chances that she would make 7 or fewer free throws in any sample of 12?. bitesti12 7.75 N Observed k Expected k Assumed p Observed p ------------------------------------------------------------------------------- 12 7 90.75000 0.58333 Pr(k >= 7) = 0.945598 (one-sided test) Pr(k <= 7) = 0.157644 (one-sided test) Pr(k = 12) = 0.189320 (two-sided test) Note: ‘bitesti…, detail’ gives k==.103
 = (one-sided test) Pr(k <= 7) = (one-sided test) Pr(k = 12) = (two-sided test) Note: ‘bitesti…, detail’ gives k==.103.")
20
See Stata ‘help bitest’.

21
We’ve just considered sample counts. Next let’s considered sample proportions.

22
Sample Proportion Count of successes in a sample divided by sample size-n. Whereas a count has whole- number values, a sample proportion is always between 0 & 1.

23
This is another example of categorical data (success vs. failure). Mean & standard deviation of a sample proportion:
. Mean & standard deviation of a sample proportion:.")
24
The population must be at least 10 times greater than the sample. Formula for a proportion’s mean: unbiased estimator of population mean.

26
Sample proportion example (pages 373- 74): A survey asked a nationwide sample of 2500 adults if they agreed or disagreed that “I like buying new clothes, but shopping is often frustrating & time- consuming.” Suppose that 60% of all adults would agree with the question. What is the probability that the sample proportion who agree is at least 58%?

27
Step 1: compute the mean & standard deviation.

28
Step 2: solve the problem.

29
How to do it in Stata:. prtesti 2500.58.60 One-sample test of proportionx: Number of obs = 2500 Variable Mean Std. Err.[95% Conf. Interval] x.58.0098712.5606529.5993471 P(Z>z) = 0.9794 That is, there is a 98% probability that the percent of respondents who agree is at least 58%: this is quite consistent with the broader evidence.
 = That is, there is a 98% probability that the percent of respondents who agree is at least 58%: this is quite consistent with the broader evidence..")
30
See Stata ‘help prtest’.

31
We’ve just considered sample proportions. Next let’s consider sample means.

32
Sampling Distribution of a Sample Mean This is an example of quantitative data. A sample mean is just an average of observations (based on a variable’s expected value). There are two reasons why sample means are so commonly used:
. There are two reasons why sample means are so commonly used:.")
33
(1) Averages are less variable than individual observations. (2) Averages are more normally distributed than individual observations.
 Averages are more normally distributed than individual observations..")
34
Sampling distribution of a sample mean Sampling distribution of a sample mean: if a population has a normal distribution, then the sampling distribution of a sample mean of x for n independent observations will also have a normal distribution. General fact: any linear combination of independent normal random variables is normally distributed.

35
Standard deviation of a sample mean: ‘Standard error’ Divide the standard deviation of the sample mean by the square root of sample size-n. This is the standard error. Doing so anchors the standard deviation to the sample’s size-n: the sampling distribution of the sample mean across relatively small samples has larger spread & across relatively large samples has smaller spread.

36
Sampling distribution of a sample mean: If population’s distribution = then the sampling distribution of a sample mean =

38
Why does the the sampling distribution of the sample mean in relatively small samples have larger spread & in relatively large samples have smaller spread?

39
Because the standard deviation of the mean is divided by the square root of sample size-n. So, if you want the sampling distribution of sample means (i.e. the estimate of the population mean)to be less variable, what’s the most basic thing to do?
to be less variable, what’s the most basic thing to do .")
40
Make the sample size-n larger. But there are major costs involved, not only in obtaining a larger sample size per se, but also in the amount of increase needed. This is because the standard deviation of the sample mean is divided by the square root of n.

41
What does dividing the mean’s standard deviation by the square root of n imply? It implies that we’re estimating the variability of the sampling distribution of sample means from the expected value of the population, for an average sample of size n.

42
In short, we’re using a sample to estimate the population’s standard deviation of the sampling distribution of sample means.

43
Here’s another principle—one that’s even more important to the sampling distribution of sample means than the Law of Large Numbers.

44
Central Limit Theorem As the size of a random sample increases, the sampling distribution of the sample mean gets closer to a normal distribution. This is true no matter what shape the population distribution has.

45
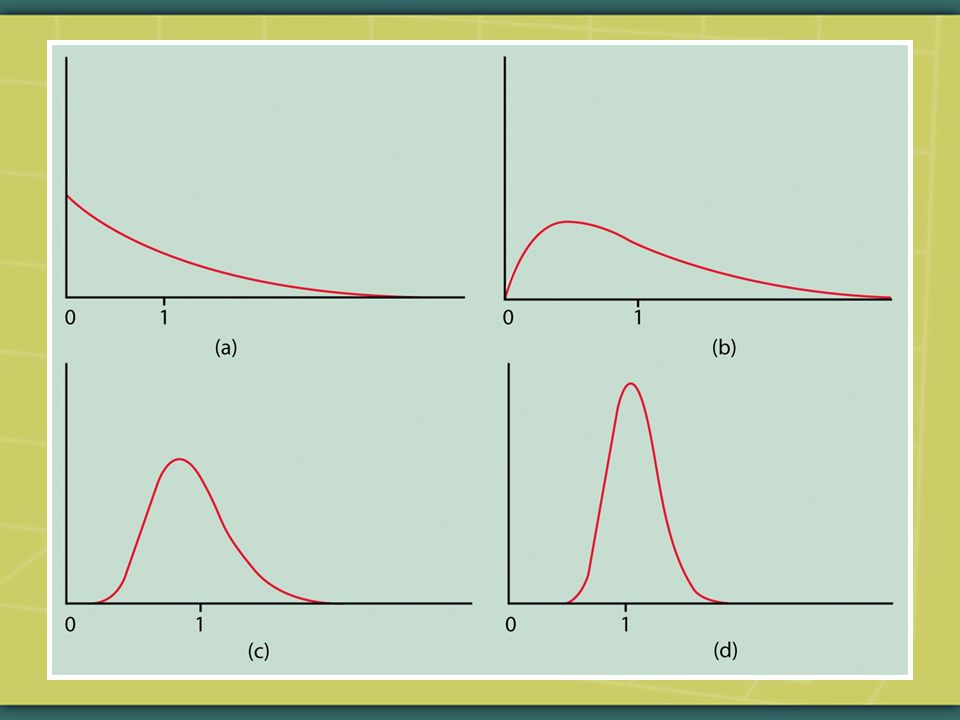
The following graphs illustrate the Central Limit Theorem. The first sample sizes are very small small; the sample sizes become progressively larger.

47
Note: the Central Limit Theorem applies to the sampling distribution of not only sample means but also sample sums. Other statistics (e.g., standard deviations) have their own sampling distributions.
 have their own sampling distributions..")
48
The Central Limit Theorem allows us to use normal probability calculations to answer questions about sample means from many observations, even when the population distribution is not normal. Thus, it justifies reliance of inferential statistics on the normal distribution. N=30 (but perhaps up to 100 or more, depending on the population’s standard deviation) is a common benchmark threshold for the Central Limit Theorem— although a far larger sample is usually necessary for other statistical reasons. The larger the population’s standard deviation, the larger N must be.
 is a common benchmark threshold for the Central Limit Theorem— although a far larger sample is usually necessary for other statistical reasons. The larger the population’s standard deviation, the larger N must be..")
49
Why not estimate a parameter on the basis of just one observation?

50
First, because the sample mean is an unbiased estimator of the population mean & is less variable than a single observation. Recall that averages are less variable than individual observations. And recall that averages are more normally distributed than individual observations.

51
Second, because a sample size of just one observations yields no measure of variability. That is, we can’t estimate where the one observed value falls in a sampling distribution of values.

52
In summary, the sampling distribution of sample means is: Normal if the population distribution is normal (i.e. a sample mean is a linear combination of independent normal random variables). Approximately normal for large samples in any case (according to the Central Limit Theorem).
. Approximately normal for large samples in any case (according to the Central Limit Theorem)..")
53
How can we confirm these pronouncements? By drawing simulated samples from the sampling distribution applet, or by simulating samples of varying sizes via a statistics software program (see Moore/McCabe, chapter 3, for review).
..")
54
Let’s briefly review several principles of probability that are strategic to doing inferential statistics: (1) In random samples, the sample mean, the binomial count, & the sample proportion are unbiased estimators of the population mean; & they can be made less variable by substantially increasing sample size-n. (2) The Law of Large Numbers (which is based on the sample size-n, not on the proportion of the population that is sampled).
 The Law of Large Numbers (which is based on the sample size-n, not on the proportion of the population that is sampled)..")
55
(3) Averages are less variable than individual observations & are more normally distributed than individual observations. (4) The sampling distribution of sample means is normal if the population distribution is normal. Put differently, the sample mean is a linear combination of independent normal random variables.
 The sampling distribution of sample means is normal if the population distribution is normal. Put differently, the sample mean is a linear combination of independent normal random variables..")
56
(5) The Central Limit Theorem: the sampling distribution of sample means is approximately normal for large samples, even if the underlying population distribution is not normal.
 The Central Limit Theorem: the sampling distribution of sample means is approximately normal for large samples, even if the underlying population distribution is not normal.")
57
These principles become additionally important because—by justifying the treatment of means drawn from relatively large samples as more or less normal distributions—they underpin two more fundamental elements of inferential statistics: confidence intervals & significance tests.

58
What problems could bias your predictions, even if your sample is well designed?

59
Answer Non-sampling problems such as undercoverage, non- response, response bias, & poorly worded questions.

Similar presentations













2000 South-Western College Publishing.>")







 Binomial distributions The binomial setting and binomial distributions Binomial distributions in statistical sampling >")

