Download presentation
Presentation is loading. Please wait.

1
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Script-Analysis Tools for the Cultural Heritage – SCRATCH Project review

2
Nederlandse Organisatie voor Wetenschappelijk Onderzoek From Scratch Lambert Schomaker Henny van Schie Tijn van der Zant Fons LaanSveta Zinger

3
Nederlandse Organisatie voor Wetenschappelijk Onderzoek PhD student: Tijn van der Zant Postdoc: Sveta Zinger Scientific programmer: Fons Laan Coordinator: Lambert Schomaker Nationaal Archief: Henny van Schie several ‘invisible’ transcription volunteers on WWW People

4
Nederlandse Organisatie voor Wetenschappelijk Onderzoek develop Script-retrieval methods strive for Script-Google don’t promise automatic transcription (but develop traditional recognizers ‘under the hood’) Goal
 Goal")
5
Experimentation platform: KdK archive

6
Nederlandse Organisatie voor Wetenschappelijk Onderzoek SCRipt Analysis Tools for the Cultural Heritage Traditional OCR: know all character shapes in advance, know the language, know the page layout, then start on page 1, towards the end Scratch philosophy: coarse to fine-grained access in an interactive cycle between users and machine pages annotate retrieval paragraphs annotate retrieval lines annotate retrieval words annotate retrieval recognition characters annotate retrieval recognition

7
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Retrieval vs Recognition Retrieval: Return(Set_of Image_objects | a_keyword) Recognition: Return(Sequence_of Letters | an_image)
 Recognition: Return(Sequence_of Letters | an_image)")
8
Nederlandse Organisatie voor Wetenschappelijk Onderzoek User interface and data-base issues Fons Laan Pattern-recognition methods Lambert Schomaker Behavior-based Machine Learning, scalability issues Tijn van der Zant Language modeling Sveta Zinger Transcription/annotation Henny van Schie and several volunteers Research and activity Tracks

9
Nederlandse Organisatie voor Wetenschappelijk Onderzoek developments: line-to-line matching (finished, published) word-to-line matching (finished, published) word spotting (continuing, published) word recognition (continuing, published) character recognition (continuing, unpublished yet) layout analysis (published) parallel computing (continuing, published) continuous transcription/annotation (continuing process) GUI, XML and database (continuing) other types of collections: Cliwoc / Admiraliteit 1777 Ubbo Emmius @ Elzevirium migration to public server and Target project Status of project
 word-to-line matching (finished, published) word spotting (continuing, published) word recognition (continuing, published) character recognition (continuing, unpublished yet) layout analysis (published) parallel computing (continuing, published) continuous transcription/annotation (continuing process) GUI, XML and database (continuing) other types of collections: Cliwoc / Admiraliteit 1777 Ubbo Elzevirium migration to public server and Target project Status of project")
11
Crude automatic word-zone segmentation Manual word-zone segmentation Unsheared line strips (B/W) t Unsheared Word Zones (B/W) Word labeling t B: Word retrieval and recognition route Word Classifiers tttt Character Classifiers tttt C: Word and character recognition
 t Unsheared Word Zones (B/W) Word labeling t B: Word retrieval and recognition route Word Classifiers tttt Character Classifiers tttt C: Word and character recognition")
12
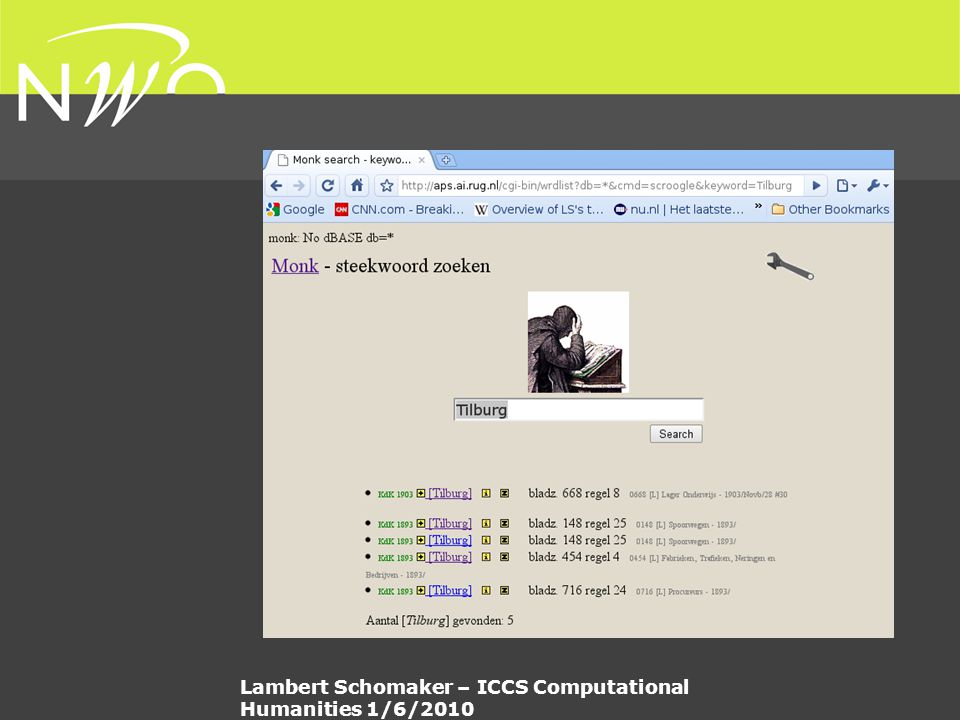
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Line-transcription web site

13
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Example of hit list for a trained word spotter: find the machine errors for abbreviation “RvSt”!

14
Nederlandse Organisatie voor Wetenschappelijk Onderzoek ~1200 scanned pages / 29k lines of which 30k lines have now been transcribed via our web interface Then, of a set of 115k Word Zones (white-space delimited text chunks), 74k words have been labeled by man+machine in concerted action during the last six year: Incremental Machine learning Data
, 74k words have been labeled by man+machine in concerted action during the last six year: Incremental Machine learning Data")
15
Nederlandse Organisatie voor Wetenschappelijk Onderzoek In order to demonstrate genericity of the approach: new KdK books will be processed ‘cliwoc’ admirality books, e.g., captain’s log of 1777, is being processed at the moment Difficult machine-printed books are a new target, e.g., Ubbo Emmius (1616). Rerum Frisicarum Historia, published by Elzevirium. Data

16
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Several non-KdK collections (captain’s logs) have been ‘ingested’ by the system (Monk@ai). Page and line segmentation methods could be used without much problems A ‘JAVA’ tool was developed for manual segmentation and labeling of words (in addition to the automatic method). This tool allows for fine-tuned word and letter harvesting. An independent tool was developed for high-quality refinement of line transcriptions. This tool will now be migrated to WWW New books (~37 KdK, ~1000 pages each) will be scanned Data, developments
. This tool allows for fine-tuned word and letter harvesting. An independent tool was developed for high-quality refinement of line transcriptions. This tool will now be migrated to WWW New books (~37 KdK, ~1000 pages each) will be scanned Data, developments.")
17
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Patch9x9 Kohonen map 33x33 cells trained on 1.6M patches

18
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Examples of Patch9x9Quadrants feature Amsterdam Groningen 4x33x33

19
Nederlandse Organisatie voor Wetenschappelijk Onderzoek “typical results” (difficult samples, correct) aanhangig Officier overweging zijn zulks
 aanhangig Officier overweging zijn zulks")
20
for nearest-neighbour matching Lambert Schomaker – ICCS Computational Humanities 1/6/2010

22
Advances in writer identification and verification – Lambert Schomaker

23
Lambert Schomaker – ICCS Computational Humanities 1/6/2010 #Labels as a function of ‘days on-line’, KdK 1903

24
Lambert Schomaker – Digihist 1/7/2010 #Labels, total as a function of ‘days on-line’, KdK 1903,1893,1897

25
start t=0 synchronized Lambert Schomaker – Digihist 1/7/2010

26
Can we go from pixel to meaning? ... without going through the language (=ASCII) bottleneck? Idea: take a semantic category or concept Collect positive examples of text-line images Sample random, negative examples Train a binary classifier (SVM) to detect the presence of lines containing the concept Lambert Schomaker – Digihist 1/7/2010
 to detect the presence of lines containing the concept Lambert Schomaker – Digihist 1/7/2010.")
27
Image-feature based ‘municipality’ detector ConceptN labeled Precision (%) Recall (%) City Names 4837677 Lambert Schomaker – Digihist 1/7/2010
 Recall (%) City Names Lambert Schomaker – Digihist 1/7/2010")
28
Image-feature based ‘proper name’ detector ConceptN labeled Precision (%) Recall (%) City Names 4837677 Proper Names 3347981 Lambert Schomaker – Digihist 1/7/2010
 Recall (%) City Names Proper Names Lambert Schomaker – Digihist 1/7/2010")
29
Image-feature based ‘personal role’ detector “ambtenaren” “vervanger” “president” “verpleegde” ConceptN labeled Precision (%) Recall (%) City Names 4837677 Proper Names 3347981 Personal Roles 16465 Lambert Schomaker – Digihist 1/7/2010
 Recall (%) City Names Proper Names Personal Roles Lambert Schomaker – Digihist 1/7/2010")
30
X-position and semantics, Bayesian modeling Lambert Schomaker – Digihist 1/7/2010

31
From pixel to meaning these are examples of ‘data mining’ regular handwriting recognition (transcoding into ASCII) is not always needed to get at meaning with sufficient examples, abstract concepts can be learned interaction and iteration e-Science Lambert Schomaker – Digihist 1/7/2010
 is not always needed to get at meaning with sufficient examples, abstract concepts can be learned interaction and iteration e-Science Lambert Schomaker – Digihist 1/7/2010")
32
Nederlandse Organisatie voor Wetenschappelijk Onderzoek

33
Example entry wind & weather ‘gps’ coordinates geographical name event

34
Nederlandse Organisatie voor Wetenschappelijk Onderzoek

36
Important paper in IEEE PAMI (vd Zant et al): biologically inspired features for word recognition (89%) Dissertation: end 2009 (TvdZ) Preliminary word-recognition results for other collections: Admiraliteit, 1777: 93% KohSOM of patches, 4-quadrants Ubbo Emmius, Latin 95% (idem) KdK-51+ 92% (idem, +MLP) KdK-51+ (vd Zant) 93+% Engineered version of IEEE PAMI New books will be scanned Ubbo Emmius: scanning was improvised, digital camera Obtained 15kEuro from Gratama Foundation for serious scanning (Arnold Meijster) Results
: biologically inspired features for word recognition (89%) Dissertation: end 2009 (TvdZ) Preliminary word-recognition results for other collections: Admiraliteit, 1777: 93% KohSOM of patches, 4-quadrants Ubbo Emmius, Latin 95% (idem) KdK % (idem, +MLP) KdK-51+ (vd Zant) 93+% Engineered version of IEEE PAMI New books will be scanned Ubbo Emmius: scanning was improvised, digital camera Obtained 15kEuro from Gratama Foundation for serious scanning (Arnold Meijster) Results")
37
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Future Target project: 32 MEuro, 15 MEuro funded, 500kEuro for us. massive, long-term data storage and access methods, from bioinformatics, astronomy to cultural heritage about 6 person years New collections are being ‘ingested’: Qumran Scrolls, new institutions are contacting us we are aiming at a second ‘big’ journal article, to be submitted end 2009

38
Nederlandse Organisatie voor Wetenschappelijk Onderzoek 1 [J] van der Zant, T., Schomaker, L.R.B. & Haak, K. (2008). Handwritten-word spotting using biologically inspired features, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol x(x), pp. xxx-xxx. [accepted] 2 [J] Schomaker, L.R.B., Franke, K., Bulacu, M. (2007). Using codebooks of fragmented connected- component contours in forensic and historic writer identification. In: Pattern Recognition Letters, 28(6), p. 719-727. 3 [C] Schomaker, L.R.B. (2008). Word mining in a sparsely-labeled handwritten collection, Document Recognition and Retrieval XV, IS&T/SPIE International Symposium on Electronic Imaging, pp. xxx-xxx. 4 [C] van der Zant, T., Schomaker, L.R.B., Valentijn, E. (2008). Large-scale parallel document-image processing, Document Recognition and Retrieval XV, IS&T/SPIE International Symposium on Electronic Imaging, pp. xxx-xxx. 5 [C] Schomaker, L.R.B. (2007). Retrieval of handwritten lines in historical documents. In: Proceedings of the 9th International Conference on Document Analysis and Recognition (ICDAR 2007), IEEE Computer Society, pp. xxx-xxx, vol. x, 23 - 26 September, Curitiba, Brazil. 6 [C] Bulacu, M., van Koert, R., Schomaker, L.R.B., van der Zant, T. (2007). Layout analysis of handwritten historical documents for searching the archive of the Cabinet of the Dutch Queen. In: Proceedings of the 9th International Conference on Document Analysis and Recognition (ICDAR 2007), IEEE Computer Society, pp. xxx-xxx, vol. x, 23 - 26 September, Curitiba, Brazil. Publications [j]=journal, [c]=peer-reviewed proceedings
![Nederlandse Organisatie voor Wetenschappelijk Onderzoek 1 [J] van der Zant, T., Schomaker, L.R.B.](http://images.slideplayer.com/10/2933110/slides/slide_38.jpg "& Haak, K. (2008). Handwritten-word spotting using biologically inspired features, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol x(x), pp. xxx-xxx. [accepted] 2 [J] Schomaker, L.R.B., Franke, K., Bulacu, M. (2007). Using codebooks of fragmented connected- component contours in forensic and historic writer identification. In: Pattern Recognition Letters, 28(6), p 3 [C] Schomaker, L.R.B. (2008). Word mining in a sparsely-labeled handwritten collection, Document Recognition and Retrieval XV, IS&T/SPIE International Symposium on Electronic Imaging, pp. xxx-xxx. 4 [C] van der Zant, T., Schomaker, L.R.B., Valentijn, E. (2008). Large-scale parallel document-image processing, Document Recognition and Retrieval XV, IS&T/SPIE International Symposium on Electronic Imaging, pp. xxx-xxx. 5 [C] Schomaker, L.R.B. (2007). Retrieval of handwritten lines in historical documents. In: Proceedings of the 9th International Conference on Document Analysis and Recognition (ICDAR 2007), IEEE Computer Society, pp. xxx-xxx, vol. x, September, Curitiba, Brazil. 6 [C] Bulacu, M., van Koert, R., Schomaker, L.R.B., van der Zant, T. (2007). Layout analysis of handwritten historical documents for searching the archive of the Cabinet of the Dutch Queen. In: Proceedings of the 9th International Conference on Document Analysis and Recognition (ICDAR 2007), IEEE Computer Society, pp. xxx-xxx, vol. x, September, Curitiba, Brazil. Publications [j]=journal, [c]=peer-reviewed proceedings.")
39
Nederlandse Organisatie voor Wetenschappelijk Onderzoek 7 [C] Bulacu, M., Schomaker, L.R.B. (2007) Automatic handwriting identification on medieval documents. In: Proceedings of 14th International Conference on Image Analysis and Processing (ICIAP 2007), IEEE Computer Society, 11 - 13 September, Modena, Italy, pp. 279-284. 8 [CB] Schomaker, L.R.B. (2007). Reading Systems: An introduction to Digital Document Processing. In: B.B. Chaudhuri (Ed.), Digital Document Processing, Springer-Verlag: Guildford, Surrey, UK. ISBN: 18462-8501-1, p. 1-28. 9 [C] Bulacu, M. & Schomaker, L.R.B. (2007). Automatic handwriting identification on medieval documents, Proc. of 14th Int. Conf. on Image Analysis and Processing (ICIAP 2007), IEEE Computer Society, pp. 279- 284, 11 - 13 September, Modena, Italy. 10 [C] van der Zant, T., Schomaker, L.R.B., Wiering, M. & Brink, A. (2006). Cognitive Developmental Pattern Recognition: Learning to Learn. IEEE SMC 2006, p. 1208-1213. 11 [C] S. Zinger, J. Nerbonne, L.R.B. Schomaker, H. van Schie, "Script Analysis Tools for the Cultural Heritage: text line matching for historical handwritten document retrieval", SIREN 2007, Scientific Information and communication technology Research Event Netherlands, p. 49, Delft (the Netherlands), October 2007. Publications
![Nederlandse Organisatie voor Wetenschappelijk Onderzoek 7 [C] Bulacu, M., Schomaker, L.R.B.](http://images.slideplayer.com/10/2933110/slides/slide_39.jpg "(2007) Automatic handwriting identification on medieval documents. In: Proceedings of 14th International Conference on Image Analysis and Processing (ICIAP 2007), IEEE Computer Society, September, Modena, Italy, pp 8 [CB] Schomaker, L.R.B. (2007). Reading Systems: An introduction to Digital Document Processing. In: B.B. Chaudhuri (Ed.), Digital Document Processing, Springer-Verlag: Guildford, Surrey, UK. ISBN: , p 9 [C] Bulacu, M. & Schomaker, L.R.B. (2007). Automatic handwriting identification on medieval documents, Proc. of 14th Int. Conf. on Image Analysis and Processing (ICIAP 2007), IEEE Computer Society, pp , September, Modena, Italy. 10 [C] van der Zant, T., Schomaker, L.R.B., Wiering, M. & Brink, A. (2006). Cognitive Developmental Pattern Recognition: Learning to Learn. IEEE SMC 2006, p 11 [C] S. Zinger, J. Nerbonne, L.R.B. Schomaker, H. van Schie, Script Analysis Tools for the Cultural Heritage: text line matching for historical handwritten document retrieval , SIREN 2007, Scientific Information and communication technology Research Event Netherlands, p. 49, Delft (the Netherlands), October Publications.")
40
Nederlandse Organisatie voor Wetenschappelijk Onderzoek 12 [C] S. Zinger, J. Nerbonne, L. Schomaker, H. van Schie, "Content-based text line comparison for historical document retrieval", Computational Phonology workshop, Recent Advances in Natural Language Processing conference, RANLP-2007, pp. 79-84, Borovets (Bulgaria), September 2007. 13 [C] S. Zinger, J. Nerbonne, L.R.B. Schomaker, H. van Schie, "Script Analysis Tools for the Cultural Heritage: statistics on queries and line matching", SIREN 2006, Scientific Information and communication technology Research Event Netherlands, p. 91, Utrecht (the Netherlands), October 2006. 14 [P] Schomaker, L.R.B., Zant, T. van der & Bogaarts, J. (2005). NWO/Catch project "Scratch" - Script-Analysis Tools for the Cultural Heritage. A Pilot Experiment on sparse- knowledge search methods for handwritten collections. Informatica Platform Nederland (IPN), Siren, October 6th, Eindhoven, The Netherlands. 15 [P] M. Bulacu, A. Brink, T. van der Zant, L. Schomaker (2009) Recognition of handwritten numerical fields in a large single-writer historical collection. In: Proceedings of the 10th Int. Conf. on Document Analysis and Recognition (ICDAR 2009), 26 - 29 July, Barcelona, Spain Publications
![Nederlandse Organisatie voor Wetenschappelijk Onderzoek 12 [C] S.](http://images.slideplayer.com/10/2933110/slides/slide_40.jpg "Zinger, J. Nerbonne, L. Schomaker, H. van Schie, Content-based text line comparison for historical document retrieval , Computational Phonology workshop, Recent Advances in Natural Language Processing conference, RANLP-2007, pp , Borovets (Bulgaria), September 13 [C] S. Zinger, J. Nerbonne, L.R.B. Schomaker, H. van Schie, Script Analysis Tools for the Cultural Heritage: statistics on queries and line matching , SIREN 2006, Scientific Information and communication technology Research Event Netherlands, p. 91, Utrecht (the Netherlands), October 14 [P] Schomaker, L.R.B., Zant, T. van der & Bogaarts, J. (2005). NWO/Catch project Scratch - Script-Analysis Tools for the Cultural Heritage. A Pilot Experiment on sparse- knowledge search methods for handwritten collections. Informatica Platform Nederland (IPN), Siren, October 6th, Eindhoven, The Netherlands. 15 [P] M. Bulacu, A. Brink, T. van der Zant, L. Schomaker (2009) Recognition of handwritten numerical fields in a large single-writer historical collection. In: Proceedings of the 10th Int. Conf. on Document Analysis and Recognition (ICDAR 2009), July, Barcelona, Spain Publications.")
41
Nederlandse Organisatie voor Wetenschappelijk Onderzoek Bulacu, M. & Schomaker, L.R.B. (2007). Text-independent Writer Identification and Verification Using Textural and Allographic Features, IEEE Trans. on Pattern Analysis and Machine Intelligence (PAMI), Special Issue - Biometrics: Progress and Directions, April, 29(4), p. 701-717. Schomaker, L.R.B., Franke, K. & Bulacu, M. (2007). Using codebooks of fragmented connected-component contours in forensic and historic writer identification, Pattern Recognition Letters, 28(6), p. 719-727. L. Schomaker & M. Bulacu (2004). Automatic writer identification using connected-component contours and edge-based features of upper-case Western script. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol 26(6), June 2004, pp. 787 - 798. M. Aussems, A. Brink (2009) Digital palaeography In: M. Rehbein, P. Sahle, and T. Schassan (Eds.), Kodikologie und Paläographie im Digitalen Zeitalter / Codicology and Palaeography in the Digital Age, ser. Schriftenreihe des Instituts für Dokumentologie und Editorik, Norderstedt: Books on Demand GmbH, 2009, vol. 2. ISBN: 978-3-8370-9842-6 Article [forthcoming]. Axel Brink, Jinna Smit, Marius Bulacu & Lambert Schomaker, "Quill Dynamics Feature for writer identification in historical documents". Publications – writer identification
. Text-independent Writer Identification and Verification Using Textural and Allographic Features, IEEE Trans. on Pattern Analysis and Machine Intelligence (PAMI), Special Issue - Biometrics: Progress and Directions, April, 29(4), p Schomaker, L.R.B., Franke, K. & Bulacu, M. (2007). Using codebooks of fragmented connected-component contours in forensic and historic writer identification, Pattern Recognition Letters, 28(6), p L. Schomaker & M. Bulacu (2004). Automatic writer identification using connected-component contours and edge-based features of upper-case Western script. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol 26(6), June 2004, pp M. Aussems, A. Brink (2009) Digital palaeography In: M. Rehbein, P. Sahle, and T. Schassan (Eds.), Kodikologie und Paläographie im Digitalen Zeitalter / Codicology and Palaeography in the Digital Age, ser. Schriftenreihe des Instituts für Dokumentologie und Editorik, Norderstedt: Books on Demand GmbH, 2009, vol. 2. ISBN: Article [forthcoming]. Axel Brink, Jinna Smit, Marius Bulacu & Lambert Schomaker, Quill Dynamics Feature for writer identification in historical documents . Publications – writer identification.")
Similar presentations