Download presentation
Presentation is loading. Please wait.

1
Inferential Statistics
Sampling, Probability, and Hypothesis Testing

2
Review of Sampling Population – group of people, communities, or organizations studied. Includes all possible objects of study. Sampling frame list of people/organizations etc. in the population who can be chosen for participation in the study. Most sampling frames do not include all people in the population (example – phone book) Sample – part of the population. Reduced down to manageable size. Ideally we would want to draw a sample that is representative of the population in terms of certain key characteristics (for example, gender and age).
 Sample – part of the population. Reduced down to manageable size. Ideally we would want to draw a sample that is representative of the population in terms of certain key characteristics (for example, gender and age).")
3
Important information about samples
For qualitative research, we are looking at specific situations. It may not be important to have a representative sample. We often use nonprobability sampling with qualitative methods (snowball, purposive, or convenience samples). For most types of quantitative research we do want a sample that is representative of the population. We will want to generalize our findings from the sample to the population.
. For most types of quantitative research we do want a sample that is representative of the population. We will want to generalize our findings from the sample to the population.")
4
To generalize means that we can say that we would expect to have the same findings if we studied everyone in the population as we did when we looked at the sample (within a certain degree of probability)
")
5
In studies in which we will generalize from the sample to the population
We must have a sample that is similar or the same on specific dimensions as the population. We will want to use inferential statistics to analyze our data so that we can infer that findings from a sample are the same as those we would get from the population. Theoretically, we must have a normal distribution in order to use inferential statistics. We will use sampling methods in which every respondent has a known probability of selection (probability sampling) The best type of sampling method to use with inferential statistics is that in which each participant has an equal probability of selection (random sampling).
 The best type of sampling method to use with inferential statistics is that in which each participant has an equal probability of selection (random sampling).")
6
Exceptions to this Rule
The population under study is small enough that everyone can be selected for participation (this still allows you to use inferential statistics) Certain types of applied research using quantitative methods such as community needs assessments and some types of surveys in which it is simply important to have as many people respond as possible. However, we will not be able to generalize our findings to the population.
 Certain types of applied research using quantitative methods such as community needs assessments and some types of surveys in which it is simply important to have as many people respond as possible. However, we will not be able to generalize our findings to the population.")
7
We can choose random samples by assigning a code number to each respondent and:
Pulling numbers out of a hat. Using a table of random numbers from a statistics book. Generating a table of random numbers on a computer.

8
Important Definitions
Probability – the mathematical likelihood that a certain event will occur. Probabilities can range from 0 to 1.00 Parameters describe the characteristics of a population. (Variables such as age, gender, income, etc.). Statistics describe the characteristics of a sample on the same types of variables.
. Statistics describe the characteristics of a sample on the same types of variables.")
9
We apply some of the ideas of central limit theorem to determining the probability that an event in research will occur The Normal Curve can be viewed as a theoretical frequency as well as a probability distribution for normally distributed ratio and interval data. The area under the curve is equal to 100% or a total probability of 1.00 Probability looks at how many chances out of l00 something will occur. Odds are chances against an event occurring.

10
Concepts related to Sampling Error
Sampling Error: The degree to which a sample differs on a key variable from the population. Confidence Level: The number of times out of 100 that the true value will fall within the confidence interval. Confidence Interval: A calculated range for the true value, based on the relative sizes of the sample and the population. Why is Confidence Level Important? Confidence levels, which indicate the level of error we are willing to accept, are based on the concept of the normal curve and probabilities. Generally, we set this level of confidence at either 90%, 95% or 99%. At a 95% confidence level, 95 times out of 100 the true value will fall within the confidence interval. Confidence Levels and Confidence Intervals (2004). Retrieved from on April 12, 2004.
. Retrieved from on April 12,")
11
The term used to describe the difference between sample statistics and population parameters is sampling error.

12
Confidence Level Example
Confidence level would fall between 2 points

13
We can theoretically draw numerous samples from a population that examine the value of one variable. The more samples we draw from the population, the more likely it is that the frequency distribution of that variable will resemble a normal distribution

14
Important concepts about sampling distributions:
If a sample is representative of the population, the mean (on a variable of interest) for the sample and the population should be the same. However, there will be some variation in the value of sample means due to random or sampling error. This refers to things you can’t necessarily control in a study or when you collect a sample. The amount of variation that exists among sample means from a population is called the standard error of the mean. Standard error decreases as sample size increases.
 for the sample and the population should be the same. However, there will be some variation in the value of sample means due to random or sampling error. This refers to things you can’t necessarily control in a study or when you collect a sample. The amount of variation that exists among sample means from a population is called the standard error of the mean. Standard error decreases as sample size increases.")
15
Two primary types of hypotheses:
Research hypothesis. Specifies expected relationship between two or more variables. Also called alternative hypothesis. May be symbolized by H1 or Ha. Null hypothesis. Statement that says there is no real relationship between the variables described in the research hypothesis.

16
Both null and research hypotheses can be:
Nondirectional: The direction of the relationship between the two variables is not specified. Usually relationships are positive or negative. A nondirectional relationship is also called a “two-tailed relationship: Directional or one-tailed. This means that the hypothesis explicitly states whether the relationship is positive or negative.

17
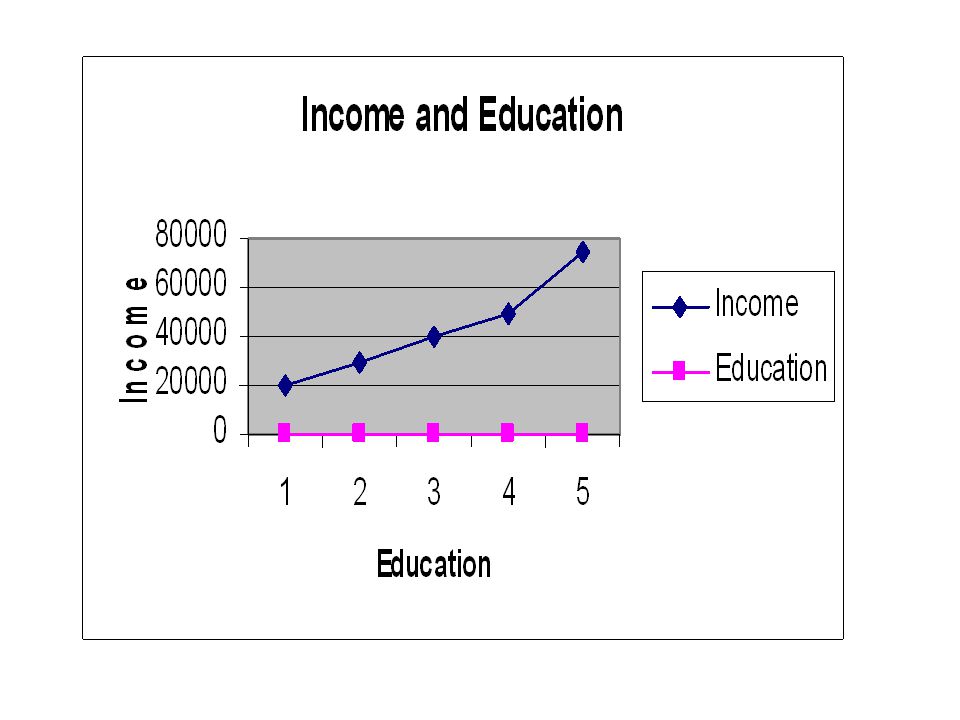
Example: Types of Relationships Positive Negative No Relationship
Income ($) Education (yrs) 20,000 10 18 14 30,000 12 16 40,000 50,000 75,000
 Education. (yrs) 20, , , , ,000.")
19
In inferential statistics, the hypothesis that is actually tested in the null hypothesis. Therefore what we must do is disprove that a relationship between the variables does not exist.

20
Examples of research hypotheses
There is an association between gender and scores on the self-esteem scale. Women will have higher levels of low self-esteem than men. There is a positive association between education and income. Scores on the MAST are negatively associated with successful treatment for alcoholism. (Are these hypotheses directional or nondirectional? What is the null hypotheses for each statement?)
")
21
Steps in the Hypothesis Testing Process
State the research hypothesis State the null hypothesis Choose a level of statistical significance (alpha level) Select and compute the test statistic Make a decision regarding whether to accept or reject the null hypothesis.
 Select and compute the test statistic. Make a decision regarding whether to accept or reject the null hypothesis.")
22
Significance level (also called confidence level or alpha):
How big a risk do we want to take in rejecting the null hypothesis when it actually is true. Significance levels are generally less than or equal to .10 (making an error 10 times out of 100) but can be less than or equal to .05 or .01. Larger data sets permit the researcher to set the significance level lower. The use of the confidence level allows us to create a decision rule. If the alpha (also called probability level or p) is lower than our confidence level, we will reject the null hypothesis and accept the research hypothesis. What we are really asking is whether the apparent relationship between our two variables really exists or is it due to random chance or error. SPSS print outs will contain information on the test statistic as well as the p or probability value.
 but can be less than or equal to .05 or .01. Larger data sets permit the researcher to set the significance level lower. The use of the confidence level allows us to create a decision rule. If the alpha (also called probability level or p) is lower than our confidence level, we will reject the null hypothesis and accept the research hypothesis. What we are really asking is whether the apparent relationship between our two variables really exists or is it due to random chance or error. SPSS print outs will contain information on the test statistic as well as the p or probability value.")
23
For example: We are looking at the correlation between income and education. A correlation (r) is a measure of nondirectional association between two variables. The information on our computer print out is r = .75, p. = .04. Our confidence level is .05. Would we accept or reject the null hypothesis?
 is a measure of nondirectional association between two variables. The information on our computer print out is r = .75, p. = .04. Our confidence level is .05. Would we accept or reject the null hypothesis")
24
Another example: A t-test is a measure that indicates whether there is a large difference between mean scores on one variable among members of two groups. We are looking at the mean scores on the self-esteem scale for men and women. T = 1.8, p. = .12. Confidence level = .10. Would we accept or reject the null hypothesis?

25
When we say that something is statistically significant, it means that the probability of something happening by chance is less than our confidence or significance level.

26
We can make two types of errors in hypothesis testing:
In the population, Ho actually is: Not reject Ho Reject Ho True Correct decision made Type 1 error Researcher thinks there is an actual relationship between the variables when there is not False Type II error There is an actual relationship between variables although researcher has accepted null hypothesis

Similar presentations








 Parameter Estimation of PDF and Fitting a Distribution Function.>")










