Download presentation
Presentation is loading. Please wait.

1
AP Statistics Hamilton/Mann
Chapter 14 Inference for Distributions of Categorical Variables: Chi-Square Procedures AP Statistics Hamilton/Mann

2
Chapter 14 Section 1 Test for Goodness of Fit
HW: 14.1, 14.3, 14.6, 14.8

3
Test for Goodness of Fit
Suppose you open up a 1.69-ounce bag of M&M’s Milk Chocolate Candies and discover that out of 56 total M&M’s in the bag, there are only 2 red M&M’s. Knowing that 13% of all plain M&M’s made by the M&M/Mars Company are red, and that in our sample, the proportion of reds is you feel cheated out of some reds. You could use the z test described in Chapter 12 to test the hypotheses where p is the proportion of reds.

4
Test for Goodness of Fit
You could then perform additional tests of significance on each of the other colors. This, however, would be inefficient. More important, it wouldn’t tell us how likely it is that the six sample proportions differ from the values stated by M&M/Mars Company as much as our sample does. There is a single test that can be applied to see if the observed sample distribution is significantly different in some way from the hypothesized population distribution. This test is called the chi-square (χ2) test for goodness of fit.
 test for goodness of fit.")
5
Auto Accidents and Cell Phones
Are you more likely to have a motor vehicle collision when using a cell phone? A study of 699 drivers who were using a cell phone when they were involved in a collision examined this question. These drivers made 26,798 cell phone calls during a 14-month period. Each of the 699 collisions was classified in various ways. Here are the counts for each day of the week: Day Sun Mon Tues Wed Thurs Fri Sat Total Number 20 133 126 159 136 113 12 699

6
Auto Accidents and Cell Phones
We have a total of 699 accidents involving drivers who were using a cell phone at the time of their accident. Let’s explore the relationship between these accidents and the day of the week. Are the accidents equally likely to occur on any day of the week? We can think of this table of counts as a one-way table with seven cells, each with a count of the number of accidents that occurred on the particular day of the week.

7
Auto Accidents and Cell Phones
Our question is translated into the following hypotheses: We can also write it in terms of population proportions.

8
Goodness of Fit Test The idea of a goodness of fit test is this: we compare the observed counts for our sample with the counts that would be expected if the null hypothesis were true. The more the observed counts differ from the expected counts, the more evidence we have to reject H0 and conclude some of the proportions must be different than those we had in the null hypothesis. In general, the expected count for any categorical variable is obtained by multiplying proportion of the distribution for each category by the sample size.

9
Auto Accidents and Cell Phones
Before proceeding with a significance test, it’s always a good idea to plot the data. In this case, a bar graph allows you to compare the observed number of accidents by day with the expected numbers of accidents by day. The counts as well as the percents are given in the table below. Day Count Percent Cumulative Percent Sunday 20 2.86 Monday 133 19.0 21.86 Tuesday 126 18.0 39.86 Wednesday 159 22.7 62.56 Thursday 136 19.5 82.06 Friday 113 16.2 98.26 Saturday 12 1.72 99.98 Total 699

10
Auto Accidents and Cell Phones
Notice the percents did not add to 100% because of rounding error. Now, we need to calculate the expected counts for each day. Since there are 699 accidents and we are assuming that the probability of an accident is the same for each day, the expected number of accidents is given by The Bar Graph comparing the expected and observed counts is on the next page.

11
Auto Accidents and Cell Phones
Anything jump out at you from the bar graph?

12
Auto Accidents and Cell Phones
To determine whether the distribution of accidents is uniform, we need a way to measure how well the observed counts (O) fit the expected counts (E) under H0. The procedure is to calculate the quantity for each day and then add up these terms. The sum is denoted X2 and is called the chi-square statistic. So let’s figure out what the chi-square statistic is for our example.
 fit the expected counts (E) under H0. The procedure is to calculate the quantity for each day and then add up these terms. The sum is denoted X2 and is called the chi-square statistic. So let’s figure out what the chi-square statistic is for our example.")
13
Auto Accidents and Cell Phones
Day Sun Mon Tues Wed Thurs Fri Sat Total Number 20 133 126 159 136 113 12 699 Sunday Monday Tuesday Wednesday Thursday Friday Saturday Χ2=

14
Chi-Square Distribution
The larger the difference between the observed and expected values, the larger X2 will be, and the more evidence there will be against H0. The chi-square family of distribution curves is used to assess the evidence against H0 represented in the value of X2. The specific member of the family is determined by the degrees of freedom. A χ2 distribution with k degrees of freedom is written χ2(k). Since we are working not only with counts, but percents, six of the seven percents are free to vary, but the seventh is not since it would de determined by the first six. So there are 6 degrees of freedom.
. Since we are working not only with counts, but percents, six of the seven percents are free to vary, but the seventh is not since it would de determined by the first six. So there are 6 degrees of freedom.")
15
Chi-Square Distribution
Degrees of freedom is one less than the number of cells in the one-way table (not including the total column). Table D shows a typical chi-square curve with the right-tail area shaded. The chi-square test statistic is a point on the horizontal axis, and the area to the right under the curve is the P-value of the test. This P-value is the probability of observing a value of X2 at least as extreme as the one observed. The larger the value of the chi-square statistic, the smaller the P-value and the more evidence you have against the null hypothesis H0.
. Table D shows a typical chi-square curve with the right-tail area shaded. The chi-square test statistic is a point on the horizontal axis, and the area to the right under the curve is the P-value of the test. This P-value is the probability of observing a value of X2 at least as extreme as the one observed. The larger the value of the chi-square statistic, the smaller the P-value and the more evidence you have against the null hypothesis H0.")
16
Auto Accidents and Cell Phones
Looking at the Chi-Square Table, a P-value of with 6 degrees of freedom has a value of Since our X2 = is more extreme than the in the table, the probability of observing a result as the extreme as the one we observed, by chance alone, is less than 0.05%. So, there is sufficient evidence to reject H0 and conclude that these types of accidents are not equally likely to occur on each of the seven days of the week.

17
Test for Goodness of Fit
The chi-square test applied to the hypothesis that a categorical variable has a specified distribution is called the test for goodness of fit. The idea is that the test assesses whether the observed counts “fit” the hypothesized distribution. The details are on the next slide!

19
Conditions for Goodness of Fit Test
Notice that we don’t want to divide by zero, and since we are working with counts, we require that all expected counts be greater than 1. In checking conditions, remember that it is the expected counts, not the observed counts, that are important. Also notice that no more than 20% (1 out of 5) can have expected counts less than 5.
 can have expected counts less than 5.")
20
Properties of the Chi-Square Distribution
As the degrees of freedom increase, the density curve becomes less skewed and larger values for X2 become more likely. Table D gives critical values for chi-square distributions. To get P-values for a chi-square test, you can use Table D, computer software, or your calculator.

21
Properties of the Chi-Square Distribution
The chi-square density curves have the following properties: The total area under a chi-square curve is equal to 1. Each chi-square curve (except when degrees of freedom = 1) begins at 0 on the horizontal axis, increases to a peak, and them approaches the horizontal axis asymptotically from above. Each chi-square curve is skewed to the right. As the number of degrees of freedom increase, the curve becomes more and more symmetrical and looks more like a Normal curve.
 begins at 0 on the horizontal axis, increases to a peak, and them approaches the horizontal axis asymptotically from above. Each chi-square curve is skewed to the right. As the number of degrees of freedom increase, the curve becomes more and more symmetrical and looks more like a Normal curve.")
22
Properties of the Chi-Square Distribution

23
One Application of the Chi-Square Goodness of Fit Test
This is often used in the field of genetics. Scientists want to investigate the genetic characteristics of offspring that result from mating parents with known genetic makeups. Scientists use rules about dominant and recessive genes to predict the ratio of offspring that will fall in each possible genetic category. Then the researchers mate the parents and classify the resulting offspring. The chi-square goodness of fit test helps the scientists assess the validity of their hypothesized ratios.

24
Red-eyed Fruit Flies Scientists wish to mate two fruit flies having genetic makeup RrCc, indicating that each parent has one dominant gene (R) and one gene (r) for eye color, along with one dominant (C) and one recessive (c) gene for wing type. R is red-eyed and C is straight-winged. Each offspring receives one gene for each of the two traits from each parent. Let’s create the Punnett Square to show the possible genotypes the offspring could end up with.
 and one gene (r) for eye color, along with one dominant (C) and one recessive (c) gene for wing type. R is red-eyed and C is straight-winged. Each offspring receives one gene for each of the two traits from each parent. Let’s create the Punnett Square to show the possible genotypes the offspring could end up with.")
25
Red-eyed Fruit Flies Based on what we see in the Punnett Square:
Parent 2 Passes On RC Rc rC rc Parent 1 Passes On RRCC RRCc RrCC RrCc RRcc Rrcc rrCC rrCc rrcc Based on what we see in the Punnett Square: Probability of red-eyed and straight-winged is Probability of red-eyed and curly-winged is Probability of white-eyed and straight-winged is Probability of white-eyed and curly-winged is 9 out of 16. 3 out of 16. 1 out of 16.

26
Red-eyed Fruit Flies To test their hypothesis about the distribution of offspring, the biologists mate the fruit flies. Of 200 offspring, 99 had red eyes and straight wings, 42 had red eyes and curly wings, 49 had white eyes and straight wings, and 10 had white eyes and curly wings. Do these results differ significantly from what the biologists would have predicted? We are going to use the inference toolbox to carry out the significance test.

27
Red-eyed Fruit Flies Step 1 – Hypotheses – The biologists are interested in the proportion of offspring that fall into each genetic category for the population of all fruit flies that would result from crossing two parents with genetic makeup RrCc. The hypotheses would be: Step 2 – Conditions – We must run a chi-square goodness of fit test. We must check expected counts. Since all are greater than 5, we can proceed.

28
Red-eyed Fruit Flies Step 3 – Calculations
We have 3 degrees of freedom since there are 4 categories. Our X2 value is between 5.32 and 6.25 which correspond to P-values of 0.15 and (On the calculator we get a P-value of ) Type Observed Expected Red-eyed, straight-winged 99 112.5 1.62 curly-winged 42 37.5 0.54 White-eyed, 49 3.5267 10 12.5 0.5 X2 =
 Type. Observed. Expected. Red-eyed, straight-winged curly-winged White-eyed, X2 =")
29
Red-eyed Fruit Flies Step 4 – Interpretation
Since the p-value (0.1029) is fairly large, that means that observed differences as large as we saw would happen by chance fairly regularly. Therefore, there is not sufficient evidence to reject the null hypothesis and reject the scientists’ predicted distribution. We can also do this on the calculator. Enter observed values in list 1. Calculate expected values and enter in list 2. Click Stat and go to Tests and choose D: χ2GOF-Test. Tell the calculator where the observed and expected counts are, input your degrees of freedom and calculate. Read the results!
 is fairly large, that means that observed differences as large as we saw would happen by chance fairly regularly. Therefore, there is not sufficient evidence to reject the null hypothesis and reject the scientists’ predicted distribution. We can also do this on the calculator. Enter observed values in list 1. Calculate expected values and enter in list 2. Click Stat and go to Tests and choose D: χ2GOF-Test. Tell the calculator where the observed and expected counts are, input your degrees of freedom and calculate. Read the results!")
30
Follow-Up Analysis In the chi-square test for goodness of fit, we test the null hypothesis that a categorical variable has a specified distribution. If we find significance, we can conclude that our variable has a distribution different from the specified one. In this case, it’s a good idea to determine which categories of the variable provide the greatest differences between observed and expected counts. To do this, look at the individual terms that are added together to produce the test statistic X2.

31
Follow-Up Analysis For the fruit flies example, the third category (white-eyed, straight-winged) contributed the most (3.5267) to the X2 statistic. For the days of the week that accidents occurred due to cell phone use, Saturday (77.299) and Sunday (63.863) contributed the most to the X2 statistic. This is known as the largest component of the chi-square statistic. This is the component whose percentage is very different from the hypothesized value.
 and Sunday (63.863) contributed the most to the X2 statistic. This is known as the largest component of the chi-square statistic. This is the component whose percentage is very different from the hypothesized value.")
32
Chapter 14 Section 2 Inference for Two-Way Tables
HW: 14.28, 29, 31, 32

33
Inference for Two-Way Tables
Two-sample z procedures of Chapter 13 allow us to compare the proportion of successes in two groups (either two populations or two treatments in an experiment). What if we want to compare more than two groups? Then we need a new statistical test. This new test begins by presenting the data as a two-way table. Two-way tables have more general uses than comparing the proportions of successes in several groups.
. What if we want to compare more than two groups Then we need a new statistical test. This new test begins by presenting the data as a two-way table. Two-way tables have more general uses than comparing the proportions of successes in several groups.")
34
Inference for Two-Way Tables
As we saw in Section 2 of Chapter 4, two-way tables can be used to describe relationships between any two categorical variables. The same test that compares several proportions also tests whether the row and column variables are related in any two-way table. We will start with the problem of comparing several proportions.

35
Background Music and Purchasing Wine
Market researchers know that background music can influence the mood and purchasing behavior of customers. One study in a supermarket in Northern Ireland compared three treatments: no music, French accordion music, and Italian string music. Under each condition, the researchers recorded the number of bottles of French, Italian, and other wine purchased. Here is a table with the data Music Wine None French Italian Total 30 39 99 11 1 19 31 Other 43 35 113 84 75 243

36
Background Music and Purchasing Wine
The conditional distributions of types of wine sold for each kind of music (this means that the music must total to 100%) are given in the table below. This compares the distributions (percents) of the types of wines sold based on the music condition. Just like earlier, now we want to look at bar graphs comparing the different distributions. Music Wine None French Italian Total 35.7% 52% 40.7% 13.1% 1.3% 22.6% 12.8% Other 51.2% 46.7% 41.7% 46.5% 100%
 are given in the table below. This compares the distributions (percents) of the types of wines sold based on the music condition. Just like earlier, now we want to look at bar graphs comparing the different distributions. Music. Wine. None. French. Italian. Total. 35.7% 52% 40.7% 13.1% 1.3% 22.6% 12.8% Other. 51.2% 46.7% 41.7% 46.5% 100%")
37
Background Music and Purchasing Wine
Do you notice anything?

38
Background Music and Purchasing Wine
There appears to be an association between music and the type of wine purchased. When no music is played, other wine is purchased most often and very little Italian wine is purchased. When French music is played, more French wine is sold and very little Italian. When Italian music is played, the percent of Italian wine purchased increases dramatically. What if we instead looked at the conditional distributions of types of music for each kind of wine (this means that the wine type must total to 100%).
.")
39
Background Music and Purchasing Wine
The conditional distributions of types of music for each kind wine are given below. This shows that Italian wine is the wine most affected by music type. The other two types of wine have percentages that stay fairly consistent. Let’s look at these bar graphs. Music Wine None French Italian Total 30.3% 39.4% 100% 35.5% 3.2% 61.3% Other 38.1% 31% 34.6% 30.9%

40
Background Music and Purchasing Wine
So, what do we notice?

41
Background Music and Purchasing Wine
It appears that more French wine is sold when French music is playing. Similarly for Italian wine and Italian music. It also appears that French music has a dramatic negative impact on sales of Italian wine.

42
Problem of Multiple Comparisons
The researchers expected the type of music being played would influence sales, so type of music is the explanatory variable and type of wine purchased is the response variable. In general, the clearest way to describe this type of relationship is to compare the conditional distributions of the response variable for each value of the explanatory variable. This means that the explanatory variables rows or columns must add up to 100%. In our case, that means that the music columns must add up to 100%.

43
Problem of Multiple Comparisons
To compare the three population distributions, we might use chi-square goodness of fit procedures several times and test the following hypotheses: H0: the distribution of wine types for no music is the same as the distribution of wine types for French music H0: the distribution of wine types for no music is the same as the distribution of wine types for Italian music H0: the distribution of wine types for French music is the same as the distribution of wine types for Italian music

44
Problem of Multiple Comparisons
The weakness of doing three tests is that we get three results, one for each test alone. That doesn’t tell us how likely it is that the three sample distributions are as different as these if the corresponding population distributions are the same. It may be that the sample distributions are significantly different if we look at just two groups, but not significantly different if we look at two other groups. We can’t safely compare many parameters by doing tests or confidence intervals for two parameters at a time.

45
Problem of Multiple Comparisons
The problem of how to do many comparisons at once with some overall measure of confidence in all our conclusions is common in statistics. This is the problem of multiple comparisons. Statistical methods for dealing with multiple comparison usually have two parts: An overall test to see if there is good evidence of any differences among the parameters that we want to compare. A detailed follow-up analysis to decide which of the parameters differ and to estimate how large the differences are.

46
Problem of Multiple Comparisons
The test we use is one we are now familiar with – the chi-square test – but in this new setting it will be used to compare several population proportions. The follow-up analysis can be quite elaborate.

47
Two-Way Tables The first step in the overall test for comparing several population proportions is to arrange the data in a two-way table that gives the counts for both successes and failures. A table with r rows and c columns is called an r x c table. The table shows the relationship between two categorical variables. For our example, the type of music is the explanatory variable and the type of wine purchased is the response variable.

48
Stating Hypotheses We observe a clear relationship between music type and wine sales for the 243 bottles sold during the study. The chi-square test assesses whether this observed association is statistically significant, that is, too strong to occur often just by chance. The market researchers changed the background music and took three samples of wine sales in three distinct environments. Each column in the table represents one of these samples, and each row a wine type.

49
Stating Hypotheses This is an example of separate and independent random samples from each of c populations. The c columns of the two-way table represent the populations. There is a single categorical response variable, wine type. The r rows of the table correspond to the values of the response variable. The r x c table allows us to compare more than two populations, more than two categories of response, or both.

50
Stating Hypotheses In this setting, the null hypothesis becomes: H0: The distribution of the response variable is the same in all c populations. Because the response variable is categorical, its distribution just consists of the proportions of its r possible values or categories. The null hypothesis says that these population proportions are the same in all c populations.

51
Background Music and Purchasing Wine
In our study, the three populations are: Population 1 – bottles of wine sold when no music is playing Population 2 – bottles of wine sold when French music is playing Population 3 – bottles of wine sold when Italian music is playing We have three independent samples of sizes 84, 75, and 84, with a separate sample being taken from each population.

52
Background Music and Purchasing Wine
The null hypothesis for the chi-square test is H0: The proportions of each wine type sold is the same in all three populations. The parameters of the model are the proportions of the three types of wine that would be sold in each of the three environments. There are three proportions (for French wine, Italian wine and other wine) for each environment.
 for each environment.")
53
Computing Expected Cell Counts
Here is the formula for expected cell counts under the null hypothesis H0: The proportions of each wine type sold is the same in all three populations. Let’s look at our example to see if we can make some sense out of this!

54
Background Music and Purchasing Wine
None French Italian Total 30 39 99 11 1 19 31 Other 43 35 113 84 75 243 Back to end! Let’s find the expected count for the cell in row 1 (French wine) and column 1 (no music). The proportion of no music among all subjects in the study is Think of this as p, the overall proportion of no music. If H0 is true, we expect (except for random variation) this same proportion of no music in all three groups.
 and column 1 (no music). The proportion of no music among all subjects in the study is. Think of this as p, the overall proportion of no music. If H0 is true, we expect (except for random variation) this same proportion of no music in all three groups.")
55
Background Music and Purchasing Wine
So the expected count of no music among the 99 subjects who purchased French wine is Notice this would be We can now find the remaining expected counts in the same way. Results are summarized in the table below. Expected Counts for Music and Wine Music Wine None French Italian Total 34.222 30.556 99.000 10.716 9.568 31.000 Other 39.062 34.877 84.000 75.001

56
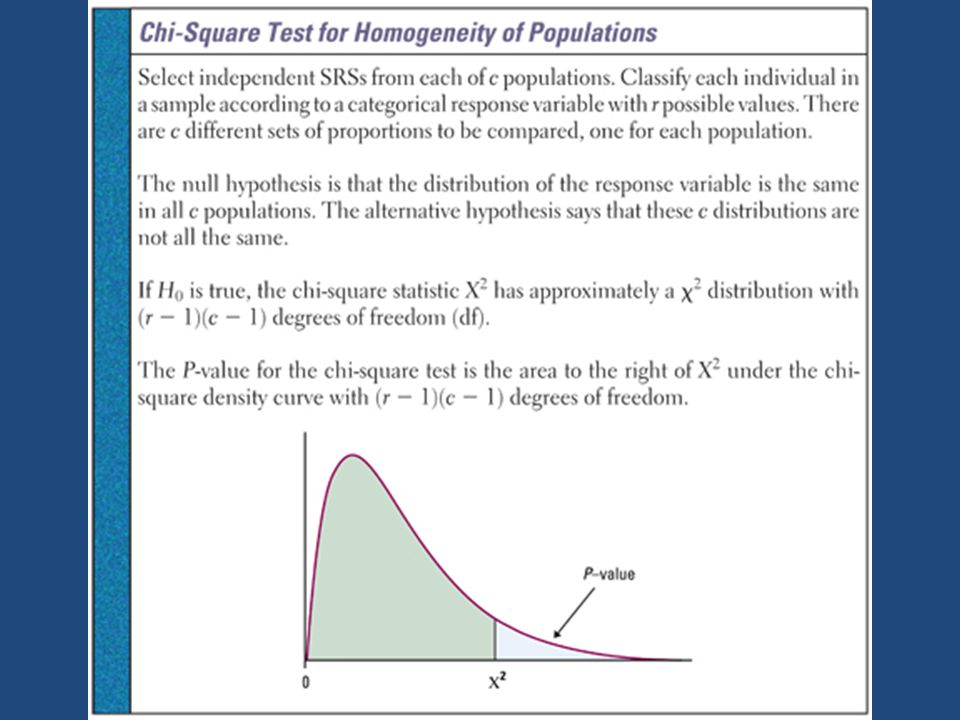
The Chi-Square Test for Homogeneity of Populations
This is an extension of the X2 statistic for one-way tables from Section 14.1. In that special case, r = 1 and c = 1.

57
The X2 Statistic and Its P-value
All of the expected counts were large, so we can proceed with the chi-square test. Just as we did with the goodness of fit test, we must compare the table of observed counts with the expected counts using the X2 statistic. We must calculate the sum for each cell and then add up the contributions from each of the nine cells. This is much too tedious to show the entire process, so we will use the calculator to make it much simpler.

58
The X2 Statistic and Its P-value
As in the test for goodness of fit, think of the chi-square statistic as a measure of the distance of the observed counts from the expected counts. Like any distance, it is always zero or positive, and it is only zero when the observed counts are exactly equal to the expected counts. Large values of X2 are evidence against H0 because they say that the observed counts are far from what we would expect if H0 were true.

59
The X2 Statistic and Its P-value
Although the alternative hypothesis Ha is many-sided, the chi-square test is one-sided because any violation of H0 tends to produce a large value of X2. Small values of X2 are not evidence against H0. The same chi-square procedure we used to test goodness of fit allows us to compare the distribution of proportions in several populations, provided that we take separate and independent samples from each population.

61
Chi-Square Test The chi-square test, like the z procedure for comparing two proportions, is an approximate method that becomes more accurate as the counts in the cells of the table get larger. Fortunately, the approximation is accurate for quite modest counts. Here is a practical guideline. Now lets run the inference procedure.

62
Background Music and Purchasing Wine
Step 1: Populations and Parameters We want to use X2 to compare the distributions of types of wine selected for each type of music. Our hypotheses are Step 2: Conditions To use the chi-square test for homogeneity of populations: The data must come from independent SRSs from the populations of interest. We are willing to treat the subjects in the three groups as SRSs from their respective populations. All expected cell counts must be greater than 1, and no more than 20% are less than 5. We meet this condition as well.

63
Background Music and Purchasing Wine
Step 3 – Calculations The test statistic is Because there are r = 3 types of wine and c = 3 types of music, the degrees of freedom are given by Now we can look up the P-value in the table or on the calculator. The X2 value of with df = 4 is located between and which correspond to P-values of and So our P-value is between and

64
Background Music and Purchasing Wine
Step 4 – Interpretation Because the expected cell counts are all large, the P-value associated with the test will be quite accurate. There is strong evidence to reject H0 (X2 = 18.28, df = 4, p < ) and conclude that the type of music being played has a significant effect on sales.
 and conclude that the type of music being played has a significant effect on sales.")
65
Performing the Chi-Square Test with Technology
Calculating expected counts and the chi-square statistic by hand is a bit time-consuming. As usual, computer software saves time and always gets the arithmetic right. Our calculator can also run the test for us. The book describes how to use the calculator to run the test on p Let’s look at running the test now! We’ll do the example we just finished!

66
Follow-up Analysis The chi-square test is the overall test for comparing any number of population proportions. If the test allows us to reject the null hypothesis that all proportions are equal, we then do a follow-up analysis that examines the differences in detail. We don’t get into doing a follow-up analysis, but you should look at the data to see what specific effects they suggest.

67
Background Music and Purchasing Wine
Follow-up Analysis We can look at the row and column percents. We created earlier. They show that there are major differences in wine type purchased for each type of music played. Italian wine sells very poorly when French music is played. French wine sells well across the board, but particularly well when French music is played. You can also compare the observed and expected counts. Look at the contributions from each component of X2. The largest components show which cells contribute the most to X2. For our example, sales of Italian wine are much below what is expected when French music is playing and well above expectation when Italian music is playing. Let’s look on our calculator.

68
Background Music and Purchasing Wine
The test we ran confirms only that there is some relationship . The percents we have compared describe the nature of the relationship. The chi-square test itself does not tell us what population our conclusion describes. If the study was done in one market on a Saturday, the results may apply only to Saturday shoppers at this market. So we have a limited Scope of Inference!

69
The Chi-Square Test and the Z Test
We can use the chi-square test to compare any number of proportions. If we are comparing r proportions and make the columns of the table “success” and “failure,” the counts form an r x 2 table. P-values come from the chi-square distribution with r – 1 degrees of freedom. If r = 2, we are comparing just two proportions. We have two ways to do this: the z test from Section 13.2 and the chi-square test with 1 degree of freedom for a 2 x 2 table.

70
The Chi-Square Test and the Z Test
These two tests always agree. In fact, the chi-square statistic is just the square of the z statistic, and the P-value for X2 is exactly the same as the two-sided P-value for z. The recommendation would be to use a z test to compare two proportions because it gives you the option of a one-sided test and is related to a confidence interval for p1 – p2.

71
The Chi-Square Test of Association/Independence
Two-way tables can arise in several ways. The music and wine study is an experiment that compared three music treatments using separate and independent samples. Each group is a sample from a separate population corresponding to a separate treatment. The study fixes the size of each sample in advance, and the data record which of the three outcomes (type of wine purchased) occurred for each category of the explanatory variable (type of music). The null hypothesis takes on the form of “equal proportions for each type of wine among the three populations.” There is also another type of setting.
 occurred for each category of the explanatory variable (type of music). The null hypothesis takes on the form of equal proportions for each type of wine among the three populations. There is also another type of setting.")
72
Franchises that Succeed
Franchises, such as McDonald’s, establish contracts with the entrepreneur’s who run them. One clause that these contracts could contain is a right to an exclusive territory, hence no other franchise will open within a certain number of miles. The question we have is how does the presence of an exclusive-territory clause in the contract relate to the survival of the business? A study designed to answer this questions collected data from a sample of 170 new franchise firms.

73
Franchises that Succeed
Two categorical variables were measured for each firm. The firm was classified as successful or not based on whether it was still franchising as of a certain date. The contract each firm offered to franchisees was classified according to whether or not there was an exclusive-territory clause . The count data are arranged in the two-way table below. Observed Number of Firms Exclusive Territory Success Yes No Total 108 15 123 34 13 47 142 28 170

74
Franchises that Succeed
The two categorical variables in this example are “success,” with values of “Yes” and No,” and “exclusive territory,” with values of “Yes” and “No.” The objective is to compare franchises that have exclusive territories with those that do not. We view “exclusive territory” as the explanatory variable and make it the column variable. So “success” is the response variable and is the row variable.

75
Franchises that Succeed
This two way table does not compare several populations. Instead, it arises by classifying observations from a single population in two ways: by exclusive territory and success. Both of these variables have two levels, so a statement of the null hypothesis is H0: There is no association between exclusive territory and success. Observed Number of Firms Exclusive Territory Success Yes No Total 108 15 123 34 13 47 142 28 170

76
Franchises that Succeed
This setting is very different from a comparison of several population proportions. Even so, we can apply a chi-square test. In general, a chi-square test tests the hypothesis, “the row and column variables are not related to each other” whenever this hypothesis makes sense for a two-way table.

77
Notice that here we have a single SRS from a single population.
When we tested for homogeneity, we had multiple SRSs from several different populations. This is how you distinguish between a test for homogeneity and association/independence.

78
The Chi-Square Test of Association/Independence
We start our analysis by computing descriptive statistics that summarize the observed relation between the two categorical variables. We compare a relationship between cateogorical variables by comparing percents. Once again, we always want to look at the effect that the explanatory variable has on the response variable. So the explanatory variable should always add up to 100% when we compute the conditional distributions.

79
Franchises that Succeed
Observed Number of Firms Exclusive Territory Success Yes No Total 108 15 123 34 13 47 142 28 170 Conditional Distribution by Exclusive Territory Exclusive Territory Success Yes No 76% 54% 24% 46% Total 100% The total row reminds us that every firm (whether exclusive territory or not) was classified as successful or not successful.
 was classified as successful or not successful.")
80
Franchises that Succeed
The bar graph to the right compares the percent of each type of firm that is successful. What do you notice? Can we conclude anything? Is there any need to compare the bar graphs for the percents that are not successful?

81
Franchises that Succeed
To think about the problem another way Among franchises who had exclusive territories, the number of successful firms was about 3 times the number of unsuccessful firms. Among franchises without exclusive territories, only about half were successful. Therefore, it appears there is reason to believe that having an exclusive territory makes a firm more likely to be successful. Is this difference statistically significant or did it just happen by chance and there really is no association between exclusive territory and success.

82
This is output from CrunchIt. For our exclusive territory problem
This is output from CrunchIt! For our exclusive territory problem. What would we conclude?

83
Chi-Square Test of Association/Independence
The chi-square test of association/independence assesses whether this observed association is statistically significant. That is, is the exclusive territory-success relationship in the sample sufficiently strong for us to conclude that it is due to a relationship between those two variables in the underlying population and not merely to chance? Note that the test asks only whether there is evidence of some relationship.

84
Chi-Square Test of Association/Independence
To explore the direction or nature of the relationship we must examine the column or row percents. Note also that in using the chi-square test we are acting as if the subjects were an SRS from a single population of interest. If the franchises are a biased sample – for example, if unsuccessful franchises are reluctant to participate in the study – then conclusions about the entire population of franchises are not justified.

85
Computing Expected Cell Counts
The null hypothesis is that there is no relationship between exclusive territory and success in the population. The alternative is that these two variables are related. If we assume that the null hypothesis is true, then success and exclusive territory are independent. Therefore, we can find the expected cell counts using the multiplication rule for independent events.

86
Franchises that Succeed
What is the expected cell count for the cell corresponding to the event “successful” and “exclusive territory”? The expected count of “success and exclusive” would then be the probability of “success and exclusive” times the total number of franchises in the sample. This is the same formula we had before.

87
Franchises that Succeed
So let’s complete the table of expected counts. Observed Number of Firms Exclusive Territory Success Yes No Total 108 15 123 34 13 47 142 28 170 Expected Number of Firms Exclusive Territory Success Yes No Total 102.74 20.26 123 39.26 7.74 47 142 28 170

88
Performing the χ2 Test We are now ready to carry out the chi-square procedure for the success and exclusive-territory data, following the steps in the inference toolbox. Step 1: Hypotheses H0: Success and exclusive territory are independent. Ha: Success and exclusive territory are dependent. Or H0: There is no association between success and exclusive territory. Ha: There is an association between success and exclusive territory.

89
Performing the χ2 Test Step 2: Conditions
To use the chi-square test of association/independence, we must check that all expected cell counts are at least one and that no more than 20% of cell counts are less than 5. From the expected counts table we just created, we know this is true.

90
Performing the χ2 Test Step 3: Calculations The test statistic is
Since there are r = 2 categories of the row variable and c = 2 categories of the column variable, we have df = (r – 1)(c – 1) = (2 – 1)(2 – 1) = 1.
(c – 1) = (2 – 1)(2 – 1) = 1.")
91
Performing the χ2 Test Step 4: Interpretation
Since our p-value (0.0150) is less than any standard significance level (0.05 and 0.10), we reject H0. Therefore, there is sufficient evidence to believe that there is an association between success and exclusive territory. Of course, this association does not show that exclusive territory causes success.
 is less than any standard significance level (0.05 and 0.10), we reject H0. Therefore, there is sufficient evidence to believe that there is an association between success and exclusive territory. Of course, this association does not show that exclusive territory causes success.")
92
Conclusion To distinguish between the two types of chi-square tests for two-way tables, you must examine the design of the study. In the test for association/independence, there is a single sample from a single population. The individuals in the sample are classified according to two categorical variables. In the test for homogeneity of populations, there is a sample from each of two or more populations. Each individual is classified based on a single categorical variable. The hypothesis differ based on the test.

93
Music Wine None French Italian Total 35.7% 52% 40.7% 13.1% 1.3% 22.6% 12.8% Other 51.2% 46.7% 41.7% 46.5% 100% Go back! Music Wine None French Italian Total 30.3% 39.4% 100% 35.5% 3.2% 61.3% Other 38.1% 31% 34.6% 30.9%

94
Observed Counts for Music and Wine Expected Counts for Music and Wine
None French Italian Total 30 39 99 11 1 19 31 Other 43 35 113 84 75 243 Go back! Expected Counts for Music and Wine Music Wine None French Italian Total 34.222 30.556 99.000 10.716 9.568 31.000 Other 39.062 34.877 84.000 75.001

Similar presentations


>")











 CHI-SQUARE PROCEDURES TEST FOR GOODNESS OF FIT.>")





