Download presentation
Presentation is loading. Please wait.

1
Coalescent Module- Faro July 26th-28th 04 www.coalescentwww.coalescent.dk Monday H: The Basic Coalescent W: Forest Fire W: The Coalescent + History, Geography & Selection H: The Coalescent with Recombination Tuesday H: Recombination cont. W: The Coalescent & Combinatorics HW: Computer Session H: The Coalescent & Human Evolution Wednesday H: The Coalescent & Statistics HW: Linkage Disequilibrium Mapping

2
globin Exon 2 Exon 1 Exon 3 5’ flanking 3’ flanking (chromosome 11) Zooming in! (from Harding + Sanger) *5.000 *20 6*10 4 bp 3*10 9 bp *10 3 3*10 3 bp ATTGCCATGTCGATAATTGGACTATTTTTTTTTT30 bp
 *5.000 *20 6*10 4 bp 3*10 9 bp *10 3 3*10 3 bp ATTGCCATGTCGATAATTGGACTATTTTTTTTTT30 bp.")
3
From Cavalli-Sforza,2001 Human Migrations

4
Data: -globin from sampled humans. From Griffiths, 2001 Assume: 1. At most 1 substitution per position. 2.No recombination Reducing nucleotide columns to bi- partitions gives a bijection between data & unrooted gene trees. C G

5
Africa Non-Africa 0.2 Mutation rate: 2.5 Rate of common ancestry: 1 Past Present Simplified model of human sequence evolution. Wait to common ancestry: 2N e

6
From Griffiths, 2001

7
Models and their benefits. Models + Data 1. probability of data (statistics...) 2. probability of individual histories 3. hypothesis testing 4. parameter estimation

8
Fixed Parameters: Population Structure, Mutation, Selection, Recombination,... Reproductive Structure Genealogies of non-sequenced data Genealogies of sequenced data Parameter Estimation Model Testing Coalescent Theory in Biology www. coalescent.dk TGTTGT CATAGT CGTTAT

9
Haploid Model Diploid Model Wright-Fisher Model of Population Reproduction i. Individuals are made by sampling with replacement in the previous generation. ii. The probability that 2 alleles have same ancestor in previous generation is 1/2N Individuals are made by sampling a chromosome from the female and one from the male previous generation with replacement Assumptions 1.Constant population size 2.No geography 3.No Selection 4.No recombination

10
10 Alleles’ Ancestry for 15 generations

11
Mean, E(X 2 ) = 2N. Ex.: 2N = 20.000, Generation time 30 years, E(X 2 ) = 600000 years. Waiting for most recent common ancestor - MRCA P(X 2 = j) = (1-(1/2N)) j-1 (1/2N) Distribution until 2 alleles had a common ancestor, X 2 ?: P(X 2 > j) = (1-(1/2N)) j P(X 2 > 1) = (2N-1)/2N = 1-(1/2N) 1 2N 1 1 1 2 j 1 1 2 j
 = (1-(1/2N)) j-1 (1/2N) Distribution until 2 alleles had a common ancestor, X 2 : P(X 2 > j) = (1-(1/2N)) j P(X 2 > 1) = (2N-1)/2N = 1-(1/2N) 1 2N j j.")
12
P(k):=P{k alleles had k distinct parents} 1 2N 1 2N *(2N-1) *..* (2N-(k-1)) =: (2N) [k] (2N) k k -> any k -> k k -> k-1 Ancestor choices: k -> j For k << 2N: S k,j - the number of ways to group k labelled objects into j groups.(Stirling Numbers of second kind.
![P(k):=P{k alleles had k distinct parents} 1 2N 1 2N *(2N-1) *..* (2N-(k-1)) =: (2N) [k] (2N) k k -> any k -> k k -> k-1 Ancestor choices: k -> j For k << 2N: S k,j - the number of ways to group k labelled objects into j groups.(Stirling Numbers of second kind.](http://images.slideplayer.com/8/2430161/slides/slide_12.jpg "P(k):=P{k alleles had k distinct parents} 1 2N 1 2N *(2N-1) *..* (2N-(k-1)) =: (2N) [k] (2N) k k -> any k -> k k -> k-1 Ancestor choices: k -> j For k << 2N: S k,j - the number of ways to group k labelled objects into j groups.(Stirling Numbers of second kind.")
13
Geometric/Exponential Distributions The Geometric Distribution: {1,..} Geo(p): P{Z=j)=p j (1-p) P{Z>j)=p j E(Z)=1/p. The Exponential Distribution: R+ Exp (a) Density: f(t) = ae -at, P(X>t)= e -at Properties: X ~ Exp(a) Y ~ Exp(b) independent i. P(X>t 2 |X>t 1 ) = P(X>t 2 -t 1 ) (t 2 > t 1 ) ii. E(X) = 1/a. iii. P(Z>t)=(≈)P(X>t) small a (p=e -a ). iv. P(X < Y) = a/(a + b). v. min(X,Y) ~ Exp (a + b).
 Density: f(t) = ae -at, P(X>t)= e -at Properties: X ~ Exp(a) Y ~ Exp(b) independent i. P(X>t 2 |X>t 1 ) = P(X>t 2 -t 1 ) (t 2 > t 1 ) ii. E(X) = 1/a. iii. P(Z>t)=(≈)P(X>t) small a (p=e -a ). iv. P(X < Y) = a/(a + b). v. min(X,Y) ~ Exp (a + b)..")
14
2 563 0.0 1.0 1.0 corresponds to 2N generations 1 4 0 2N 0 6 6/2N e t c :=t d /2N e Discrete Continuous Time

15
Probability for two genes being identical: P(Coalescence < Mutation) = 1/(1+ ). m mutation pr. nucleotide pr.generation. L: seq. length µ = m*L Mutation pr. allele pr.generation. 2N e - allele number. := 4N*µ -- Mutation intensity in scaled process. Adding Mutations sequence time Discrete time Discrete sequence Continuous time Continuous sequence 1/L 1/(2N e ) time sequence /2 mutation coalescence Note: Mutation rate and population size usually appear together as a product, making separate estimation difficult. 1
 time sequence /2 mutation coalescence Note: Mutation rate and population size usually appear together as a product, making separate estimation difficult. 1.")
16
The Standard Coalescent Two independent Processes Continuous: Exponential Waiting Times Discrete: Choosing Pairs to Coalesce. 12345 WaitingCoalescing 4--5 3--(4,5) (1,2)--(3,(4,5)) 1--2 {1}{2}{3}{4}{5} {1,2}{3,4,5} {1,2,3,4,5} {1}{2}{3}{4,5} {1}{2}{3,4,5}
 (1,2)--(3,(4,5)) 1--2 {1}{2}{3}{4}{5} {1,2}{3,4,5} {1,2,3,4,5} {1}{2}{3}{4,5} {1}{2}{3,4,5}.")
17
Expected Height and Total Branch Length Expected Total height of tree: H k = 2(1-1/k) i.Infinitely many alleles finds 1 allele in finite time. ii. In takes less than twice as long for k alleles to find 1 ancestors as it does for 2 alleles. Expected Total branch length in tree, L k : 2*(1 + 1/2 + 1/3 +..+ 1/(k-1)) ca= 2*ln(k-1) 1 2 3 k 1/3 1 2 1 2/(k-1) Time Epoch Branch Lengths
) ca= 2*ln(k-1) k 1/ /(k-1) Time Epoch Branch Lengths.")
18
B. The Paint Box & exchangable distributions on Partitions. C. All coalescents are restrictions of “The Coalescent” – a process with entrance boundary infinity. D. Robustness of “The Coalescent”: If offspring distribution is exchangeable and Var( 1 ) --> 2 & E( 1 m ) < M m for all m, then genealogies follows ”The Coalescent” in distribution. E. A series of combinatorial results. Kingman (Stoch.Proc. & Appl. 13.235-248 + 2 other articles,1982) A. Stochastic Processes on Equivalence Relations. ={(i,i);i= 1,..n} ={(i,j);i,j=1,..n} 1 if s < t q s,t = 0 otherwise This defines a process, R t, going from to through equivalence relations on {1,..,n}.
 --> 2 & E( 1 m ) < M m for all m, then genealogies follows The Coalescent in distribution. E. A series of combinatorial results. Kingman (Stoch.Proc. & Appl other articles,1982) A. Stochastic Processes on Equivalence Relations. ={(i,i);i= 1,..n} ={(i,j);i,j=1,..n} 1 if s < t q s,t = 0 otherwise This defines a process, R t, going from to through equivalence relations on {1,..,n}..")
19
Effective Populations Size, N e. In an idealised Wright-Fisher model: i. loss of variation per generation is 1-1/(2N). ii. Waiting time for random alleles to find a common ancestor is 2N. Factors that influences N e : i. Variance in offspring. WF: 1. If variance is higher, then effective population size is smaller. ii. Population size variation - example k cycle: N 1, N 2,..,N k. k/N e = 1/N 1 +..+ 1/N k. N 1 = 10 N 2 = 1000 => N e = 50.5 iii. Two sexes N e = 4N f N m /(N f +N m )I.e. N f - 10 N m -1000 N e - 40
. ii. Waiting time for random alleles to find a common ancestor is 2N. Factors that influences N e : i. Variance in offspring. WF: 1. If variance is higher, then effective population size is smaller. ii. Population size variation - example k cycle: N 1, N 2,..,N k. k/N e = 1/N /N k. N 1 = 10 N 2 = 1000 => N e = 50.5 iii. Two sexes N e = 4N f N m /(N f +N m )I.e. N f - 10 N m N e")
20
6 Realisations with 25 leaves Observations: Variation great close to root. Trees are unbalanced.

21
Sampling more sequences The probability that the ancestor of the sample of size n is in a sub-sample of size k is Letting n go to infinity gives (k-1)/(k+1), i.e. even for quite small samples it is quite large.

22
Three Models of Alleles and Mutations. Infinite Allele Infinite Site Finite Site acgtgctt acgtgcgt acctgcat tcctgcat acgtgctt acgtgcgt acctgcat tcctggct tcctgcat i. Only identity, non-identity is determinable ii. A mutation creates a new type. i. Allele is represented by a line. ii. A mutation always hits a new position. i. Allele is represented by a sequence. ii. A mutation changes nucleotide at chosen position.

23
1 2 3 45 Infinite Allele Model

24
Final Aligned Data Set: Infinite Site Model

25
0 1 2 3 4 5 6 7 8 1 1 4 2 5 3 1 5 5
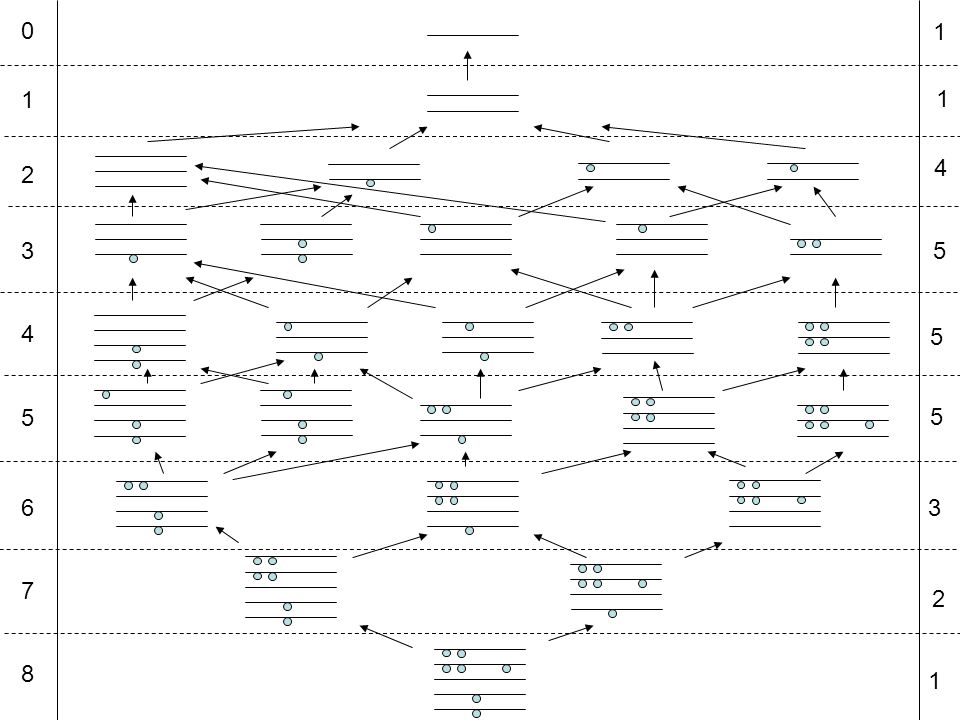
26
0 1 2 3 4 5 6 7 8 1 1 4 2 5 3 1 5 5 Number of paths: 2 2 2 3 4 4 6 2 7 7 14 8 2 28 22 10 50 32 82 2

27
1 3 4 5 2 1 3 4 5 2 {},, Ignoring mutation position Ignoring sequence label Ignoring mutation position Ignoring sequence label Labelling and unlabelling:positions and sequences 9 coalescence events incompatible with data 4 classes of mutation events incompatible with data The forward-backward argument

28
Infinite Site Model: An example Theta=2.12 2 3 2 3 5 5 4 9 10 5 19 14 33

29
Impossible Ancestral States

30
Final Aligned Data Set: acgtgctt acgtgcgt acctgcat tcctgcat s s s Finite Site Model

31
1) Only substitutions. s1 TCGGTA s1 TCGGA s2 TGGT-T s2 TGGTT 2) Processes in different positions of the molecule are independent. 3) A nucleotide follows a continuous time Markov Chain. 4) Time reversibility: I.e. π i P i,j (t) = π j P j,i (t), where π i is the stationary distribution of i. This implies that Simplifying assumptions 5) The rate matrix, Q, for the continuous time Markov Chain is the same at all times. = a N1N1 N2N2 l 2 +l 1 l1l1 l2l2 N2N2 N1N1
 Processes in different positions of the molecule are independent. 3) A nucleotide follows a continuous time Markov Chain. 4) Time reversibility: I.e. π i P i,j (t) = π j P j,i (t), where π i is the stationary distribution of i. This implies that Simplifying assumptions 5) The rate matrix, Q, for the continuous time Markov Chain is the same at all times. = a N1N1 N2N2 l 2 +l 1 l1l1 l2l2 N2N2 N1N1.")
32
Evolutionary Substitution Process t1t1 t2t2 C C A P i,j (t) = probability of going from i to j in time t.

33
Jukes-Cantor 69: Total Symmetry. -3* -3* -3* -3* TO A C G T FROM A.Stationary Distribution: (.25,.25,.25,.25) B. Expected number of substitutions: 3 t ACGTACGT 0 t Higher Cells ChimpMouse Fish E.coli ATTGTGTATATAT….CAG ATTGCGTATCTAT….CCG
 B. Expected number of substitutions: 3 t ACGTACGT 0 t Higher Cells ChimpMouse Fish E.coli ATTGTGTATATAT….CAG ATTGCGTATCTAT….CCG.")
34
History of Coalescent Approach to Data Analysis 1930-40s: Genealogical arguments well known to Wright & Fisher. 1964: Crow & Kimura: Infinite Allele Model 1968: Motoo Kimura proposes neutral explanation of molecular evolution & population variation. So does King & Jukes 1971: Kimura & Otha proposes infinite sites model. 1972: Ewens’ Formula: Probability of data under infinite allele model. 1975: Watterson makes explicit use of “The Coalescent” 1982: Kingman introduces “The Coalescent”. 1983: Hudson introduces “The Coalescent with Recombination” 1983: Kreitman publishes first major population sequences.

35
History of Coalescent Approach to Data Analysis 1987-95: Griffiths, Ethier & Tavare calculates site data probability under infinite site model. 1994-: Griffiths-Tavaré + Kuhner-Yamoto-Felsenstein introduces highly computer intensitive simulation techniquees to estimate parameters in population models. 1996- Krone-Neuhauser introduces selection in Coalescent 1998- Donnelly, Stephens, Fearnhead et al.: Major accelerations in coalescent based data analysis. 2000-: Several groups combines Coalescent Theory & Gene Mapping. 2002: HapMap project is started.

36
Basic Coalescent Summary i. Genealogical approach to population genetics. ii. ”The Coalescent” - generic probability distribution on allele trees. iii. Combining ”The Coalescent” with Allele/Mutation Models allows the calculation the probability of data.

Similar presentations




















