Download presentation
Presentation is loading. Please wait.

1
Obligatory cuteness

2
Guidelines for Using Multiple Views in Information Visualization ● A guideline paper – does not introduce any new techniques, but rather identifies some good practice rules. ● Just like all design rules, they appear to be somewhat obvious on a first look.

3
Multiple view system design phases ● Determine view selection ● Decide on view presentation (how are the views shown on the page?) ● Choose the ways in which the views interact with each other (examples: navigational slaving, linking, brushing)
 ● Choose the ways in which the views interact with each other (examples: navigational slaving, linking, brushing)")
4
Guidelines for view selection ● Rule of Diversity – Use multiple views when there is a diversity of attributes, models, user profiles, levels of abstraction, or genres. ● Rule of Complementarity – Use multiple views when different views bring out correlations and/or disparities ● Rule of Decomposition – Partition complex data into multiple views to create manageable chunks and to provide insight into the interaction among different dimensions.. ● Rule of Parsimony – Use multiple views minimally.

5
Rule of Diversity ● Use multiple views when there is a diversity of attributes, models, user profiles, levels of abstraction, or genres. ● In plain English: A single view should not try to accomplish too much at once, as than it will end up bloated and useless.

6
Rule of Complementarity ● Use multiple views when different views bring out correlations and/or disparities. ● In plain English: a combination of views should provide more information than individual views on their own

7
Rule of Decomposition ● Partition complex data into multiple views to create manageable chunks and to provide insight into the interaction among different dimensions.

8
Rule of Parsimony (complex name for “keep it simple”)
")
9
Guidelines for presentation/interaction ● Rule of Space/Time Resource Optimization – Balance the spatial and temporal costs of presenting multiple views with the spatial and temporal benefits of using the views. ● Rule of Self-Evidence – Use perceptual cues to make relationships among multiple views more apparent to the user. ● Rule of Consistency – Make the interfaces for multiple views consistent, and make the states of multiple views consistent. ● Rule of Attention Management – Use perceptual techniques to focus the user’s attention on the right view at the right time.

10
Summary ● Good – The rules are reasonable and well-argumented – Examples are offered for every rule – A short “cheatsheet” of rules and their positive/negative effects is provided. ● Bad – Some rules are not relevant to subject matter, and are instead general UI design rules. ● Rule of Parsimony section could be replaced with a single word: KISS ● Rule of Attention Management also appears to be a generic UI design principle – Rules are not really “rules”, but rather somewhat incompatible guidelines

11
Graph-Theoretic Scagnostics ● What is scagnostics? ● What does graph theory bring into the mix? ● What does all that allow us to do?

12
What is Scagnostics? ● While a scatterplot matrix is a useful multidimensional analysis tool, its utility falls as number of dimensions increases. ● How would this diagram look with 50 dimensions? How would we find the interesting scatterplots out of N^2 available ones?

13
What is Scagnostics? ● Idea: replace scatterplots with values of some metrics (roundness, outlierness, normality, uniformity).
..")
14
How do we compute those metrics? ● Build a graph with edges that connect “nearby” scatterplot points. ● Most metrics are based on properties of alpha hull of this graph, spanning tree that the graph can be reduced to, convex hull of all points. ● Example: convexity is determined as area of alpha hull divided over area of convex hull.

15
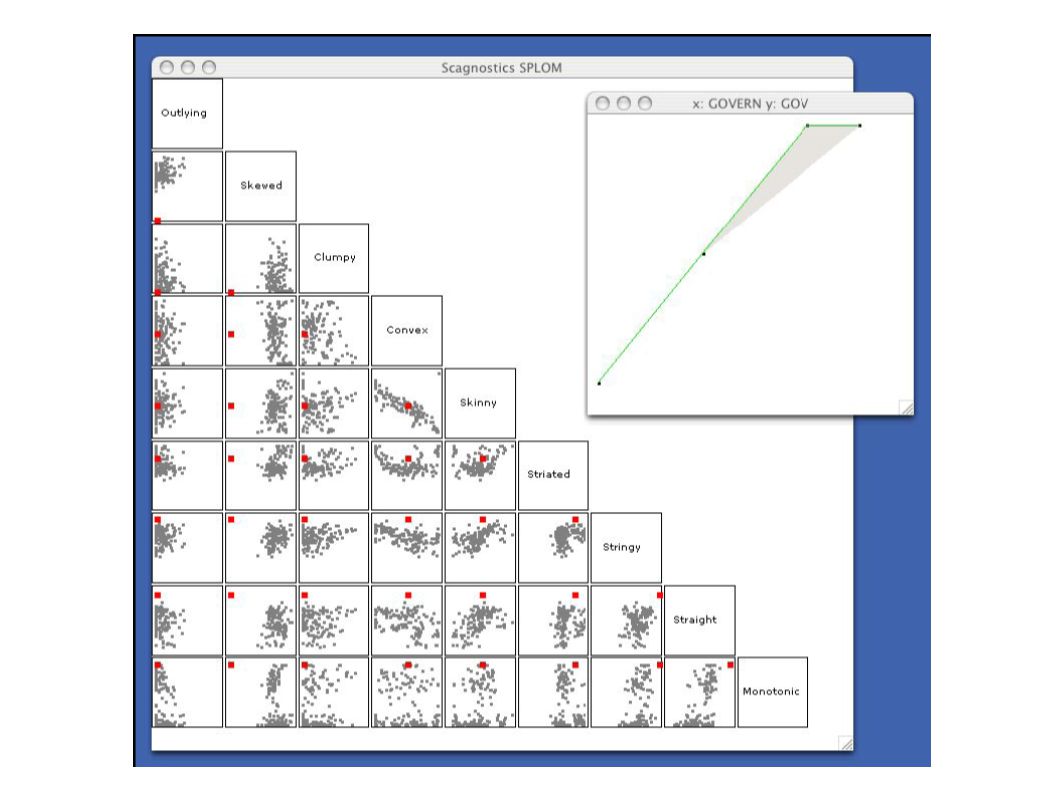
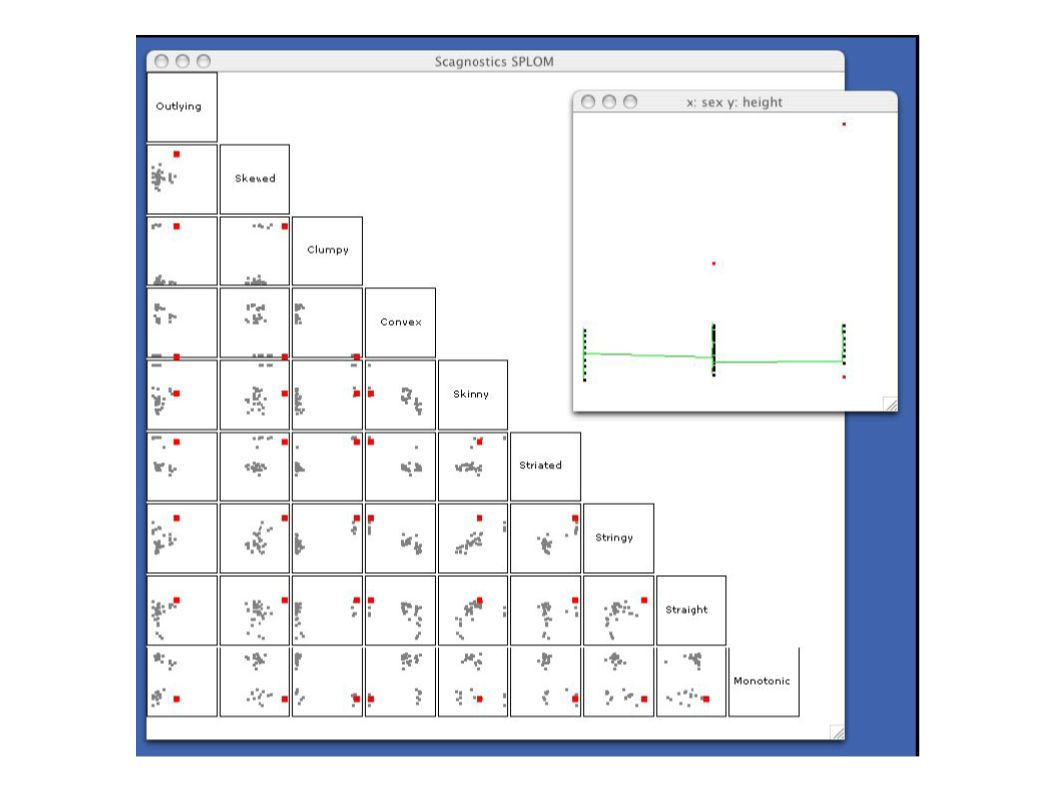
Examples of different metrics applied to different scatterplots

16
And what can we do with all these tools? ● To solve our initial problem of dealing with far too many scatterplots, we add a level of indirection. ● Every point in a scatterplot inside high-level scatterplot matrix now corresponds to a single “normal” scatterplot ● Brushing is used to highlight all positions of a scatterplot “point”

20
Summary ● Written by statisticians for statisticians ● Little focus on actual visualization, but a lot of explanations on how it actually works, and strong performance focus ● Good – Original ● Bad – Does not appear usable – No user studies (did the users run screaming from this thing?)
")
Similar presentations




 divide-and-conquer technique for Minimum Spanning Tree problem Step 1: Divide the graph into N sub-graph by clustering. Step 2: Solve each.>")















