Download presentation
Presentation is loading. Please wait.

1
CESS Workshop Oxford University June 2013 Don Green Professor of Political Science Columbia University

2
Outline Examples of ongoing field experiments Why experiment? Why experiment in the field? Key ideas in Field Experiments: Design, Analysis, and Interpretation Randomization inference Noncompliance Attrition Spillover

3
Brief sketches of some current experimental projects Voter turnout and persuasion in the US and abroad (mass media, mail, phones, shoe leather, events…) with a recent focus on the influence of social norms Downstream experiments: habit, education and political participation Prejudice reduction Criminal sentencing and deterrence Civic education and political attitudes Media and pro-social behavior
 with a recent focus on the influence of social norms Downstream experiments: habit, education and political participation Prejudice reduction Criminal sentencing and deterrence Civic education and political attitudes Media and pro-social behavior")
4
Why experiment? The role of scientific procedures/design in making the case for unbiased inference Unobserved confounders and lack of clear stopping rules in observational research The value of transparent & intuitive science that involves ex ante design/planning and, in principle, limits the analyst’s discretion Experiments provide benchmarks for evaluating other forms of research

5
Why experiment in field settings? Four considerations regarding generalizability Subjects, treatments, contexts, outcome measures Narrowing the gap between an experimental design and the target estimand Trade off: must attend to treatment fidelity Systematic experimental inquiry can lead to the discovery and development of useful and theoretically illuminating interventions

6
What is an experiment? Perfectly controlled experiments in the physical sciences versus randomized experiments in the behavioral sciences A study that assigns subjects to treatment with a known probability between 0 and 1 Different types of random assignment: simple, complete, blocked, clustered Confusion between random sampling and random assignment

7
Experiment versus Alternative Research Designs: Example of Assessing the Effects of Election Monitors on Vote Fraud (inspired by the work of Susan Hyde) Randomized experiment: Researcher randomly assigns election monitoring teams to polling locations Natural/quasi experiment: Researcher compares polling locations visited by monitoring teams to polling locations not visited because some monitoring team leaders were sick and unable to travel Observational Study: Researcher compares polling locations visited by monitoring teams to polling locations not visited
 Randomized experiment: Researcher randomly assigns election monitoring teams to polling locations Natural/quasi experiment: Researcher compares polling locations visited by monitoring teams to polling locations not visited because some monitoring team leaders were sick and unable to travel Observational Study: Researcher compares polling locations visited by monitoring teams to polling locations not visited")
8
Are experiments feasible? Large-scale, government-funded “social experiments” and evaluations Research collaborations with political campaigns, organizations, etc. who allocate resources Researcher-driven/designed interventions Seizing opportunities presented by naturally occurring randomized assignment

9
Are experiments necessary? Not when the counterfactual outcome is obvious (e.g., the effects of parachutes on the well-being of skydivers) By the way, how do we know it’s obvious? Not when there is little or no heterogeneity among the units of observation (e.g., consumer product testing) Not when the apparent effect is so large that there is no reason to attribute it to unobserved heterogeneity (e.g., the butterfly ballot effect in the 2000 election) …for most behavioral science applications, experiments are indispensable
 By the way, how do we know it’s obvious. Not when there is little or no heterogeneity among the units of observation (e.g., consumer product testing) Not when the apparent effect is so large that there is no reason to attribute it to unobserved heterogeneity (e.g., the butterfly ballot effect in the 2000 election) …for most behavioral science applications, experiments are indispensable.")
10
Themes of FEDAI Importance of… Defining the estimand Appreciating core assumptions under which a given experimental design will recover the estimand Conducting data analysis in a manner that follows logically from the randomization procedure Following procedures that limit the role of discretion in data analysis Presenting results in a detailed and transparent manner

11
Potential outcomes Potential outcomes: Y i (d) for d = {0,1} Unit-level treatment effect: Y i (1) – Y i (0) Average treatment effect: E[Y i (1) – Y i (0)] Indicator for treatment received: d i Observed outcome: Y i =d i Y i (1) + (1-d i )Y i (0)
![Potential outcomes Potential outcomes: Y i (d) for d = {0,1} Unit-level treatment effect: Y i (1) – Y i (0) Average treatment effect: E[Y i (1) – Y i (0)] Indicator for treatment received: d i Observed outcome: Y i =d i Y i (1) + (1-d i )Y i (0)](http://images.slideplayer.com/9/2390677/slides/slide_11.jpg "Potential outcomes Potential outcomes: Y i (d) for d = {0,1} Unit-level treatment effect: Y i (1) – Y i (0) Average treatment effect: E[Y i (1) – Y i (0)] Indicator for treatment received: d i Observed outcome: Y i =d i Y i (1) + (1-d i )Y i (0)")
12
Example: a (hypothetical) schedule of potential outcomes
 schedule of potential outcomes")
13
Core assumptions Random assignment of subjects to treatments implies that receiving the treatment is statistically independent of subjects’ potential outcomes Non-interference: a subject’s potential outcomes reflect only whether they receive the treatment themselves A subject’s potential outcomes are unaffected by how the treatments happened to be allocated Excludability: a subject’s potential outcomes respond only to the defined treatment, not other extraneous factors that may be correlated with treatment Importance of defining the treatment precisely and maintaining symmetry between treatment and control groups (e.g., through blinding)
")
14
Randomization inference State a set of assumptions under which all potential outcomes become empirically observable (e.g., the sharp null hypothesis of no effect for any unit) Define a test statistic: estimated it in the sample at hand and simulate its sampling distribution over all (or effectively all) possible random assignments Conduct hypothesis testing in a manner that follows from the randomization procedure (e.g., blocking, clustering, restricted randomizations) using the ri() package in R. Analogous procedures for confidence intervals

15
Using the ri() package in R (Aronow & Samii 2012) Uses observed data and a maintained hypothesis to impute a full schedule of potential outcomes Detects complex designs and makes appropriate adjustments to estimators of the ATE (or CACE) Avoids common data analysis errors related to blocking or clustering Simulates the randomization distribution and calculates p-values and confidence intervals Provides a unified framework for a wide array of tests and sidesteps distributional assumptions
 package in R (Aronow & Samii 2012) Uses observed data and a maintained hypothesis to impute a full schedule of potential outcomes Detects complex designs and makes appropriate adjustments to estimators of the ATE (or CACE) Avoids common data analysis errors related to blocking or clustering Simulates the randomization distribution and calculates p-values and confidence intervals Provides a unified framework for a wide array of tests and sidesteps distributional assumptions")
16
Example: RI versus t-tests as applied to a small contributions experiment (n=20) One-tailed p-values for the estimated ATE of 70: randomization inference p=0.032 t(equal variances) p=0.082 t(unequal variances) p=0.091
 One-tailed p-values for the estimated ATE of 70: randomization inference p=0.032 t(equal variances) p=0.082 t(unequal variances) p=0.091")
17
Example of a common error in the analysis of a block-randomized design A GOTV phone-calling experiment conducted in two blocks: competitive and uncompetitive. We effectively have two experiments, one in each block.

18
Doh! Notice what happens if you neglect to control for the blocks! Statistically significant – and misleading – results…

19
Noncompliance: avoiding common errors People you fail to treat are NOT part of the control group! Do not throw out subjects who fail to comply with their assigned treatment Base your estimation strategy on the ORIGINAL treatment and control groups, which were randomly assigned and therefore have comparable potential outcomes

20
A misleading comparison: comparing groups according to the treatment they received rather than the treatment they were assigned What if we had compared those contacted and those not contacted in the phone bank study?

21
Addressing (one-sided) noncompliance statistically Define “Compliers” and estimate the average treatment effect within this subgroup Model the expected treatment and control group means as weighted averages of latent groups, “Compliers” and “Never-takers” Assume excludability: assignment to treatment only affects outcomes insofar as it affects receipt of the treatment (the plausibility of this assumption varies by application)
 noncompliance statistically Define Compliers and estimate the average treatment effect within this subgroup Model the expected treatment and control group means as weighted averages of latent groups, Compliers and Never-takers Assume excludability: assignment to treatment only affects outcomes insofar as it affects receipt of the treatment (the plausibility of this assumption varies by application)")
22
Simplified model notation Suppose that the subject pool consists of two kinds of people: Compliers and Never-takers Let P c = the probability that Compliers vote Let P n = the probability that Never-takers vote Let = the proportion of Compliers people in the subject pool Let T = the average treatment effect among Compliers

23
Expected voting rates in control and treatment groups Probability of voting in the control group (V 0 ) is a weighted average of Complier and Never-taker voting rates: V 0 = P c + (1- ) P n Probability of voting in the treatment group (V 1 ) is also a weighted average of Complier and Never-taker voting rates: V 1 = (P c + T) + (1- ) P n
 is a weighted average of Complier and Never-taker voting rates: V 0 = P c + (1- ) P n Probability of voting in the treatment group (V 1 ) is also a weighted average of Complier and Never-taker voting rates: V 1 = (P c + T) + (1- ) P n")
24
Derive an Estimator for the Treatment-on-treated Effect (T) V 1 - V 0 = (P c +T)+(1- )P n – { P c + (1- ) P n } = T T is the “intent to treat” effect To estimate T, insert sample values into the formula: T* = (V* 1 – V* 0 )/ where is the proportion of contacted people (Compliers) observed in the treatment group, and V* 1 and V* 0 are the observed voting rates in the assigned treatment and control groups, respectively
 V 1 - V 0 = (P c +T)+(1- )P n – { P c + (1- ) P n } = T T is the intent to treat effect To estimate T, insert sample values into the formula: T* = (V* 1 – V* 0 )/ where is the proportion of contacted people (Compliers) observed in the treatment group, and V* 1 and V* 0 are the observed voting rates in the assigned treatment and control groups, respectively")
25
Example: Door-to-door canvassing (only) in New Haven, 1998: =.3208
 in New Haven, 1998: =.3208")
26
Example: V* 1 =.4626, V* 0 =.4220

27
Estimate Actual Treatment Effect ( V* 1 – V* 0 ) / = ( 46.26 – 42.20) /.3208 = 12.7 In other words: actual contact with canvassers increased turnout by 12.7 percentage-points This estimator is equivalent to instrumental variables regression, where assignment to treatment is the instrument for actual contact. Notice that we NEVER compare the voting rates of those who were contacted to those who were not contacted!…Why not?

28
Design question: Compare the assigned treatment group to an untreated control group or a placebo group? Placebo must be (1) ineffective and (2) administered in the same way as the treatment, such that assignment to placebo/treatment is random among those who are contacted Assignment to placebo should be blinded and made at the last possible moment before treatment Placebo design can generate more precise estimates when contact rates are low
 ineffective and (2) administered in the same way as the treatment, such that assignment to placebo/treatment is random among those who are contacted Assignment to placebo should be blinded and made at the last possible moment before treatment Placebo design can generate more precise estimates when contact rates are low.")
29
Nickerson’s (2005) Canvassing Experiment: GOTV, Placebo, and Control Groups Contact rate was low (GOTV: 18.9% and placebo: 18.2%) Turnout results for GOTV and control: GOTV treatment (N=2,572): 33.9% Control (N=2,572): 31.2% Treatment on treated: b=.144, SE=.069. Turnout results for contacted GOTV and contacted placebo: GOTV treatment (N=486): 39.1% Placebo (N=470): 29.8% Treatment on treated: b=.093, SE=.031 Bottom line: placebo control led to more precise estimates
: 39.1% Placebo (N=470): 29.8% Treatment on treated: b=.093, SE=.031 Bottom line: placebo control led to more precise estimates.")
30
Attrition Can present a grave threat to any experiment because missing outcomes effectively un- randomize the assignment of subjects If you confront attrition, consider whether it threatens the symmetry between assigned experimental groups Consider design-based solutions such as an intensive effort to gather outcomes from a random sample of the missing

31
Spillovers Complication: equal-probability random assignment of units does not imply equal- probability assignment of exposure to spillovers Unweighted difference-in-means or unweighted regression can give severely biased estimates

32
Hypotheses about spillovers Contagion: The effect of being vaccinated on one’s probability of contracting a disease depends on whether others have been vaccinated. Displacement: Police interventions designed to suppress crime in one location may displace criminal activity to nearby locations. Communication: Interventions that convey information about commercial products, entertainment, or political causes may spread from individuals who receive the treatment to others who are nominally untreated. Social comparison: An intervention that offers housing assistance to a treatment group may change the way in which those in the control group evaluate their own housing conditions. Persistence and memory: Within-subjects experiments, in which outcomes for a given unit are tracked over time, may involve “carryover” or “anticipation.”

33
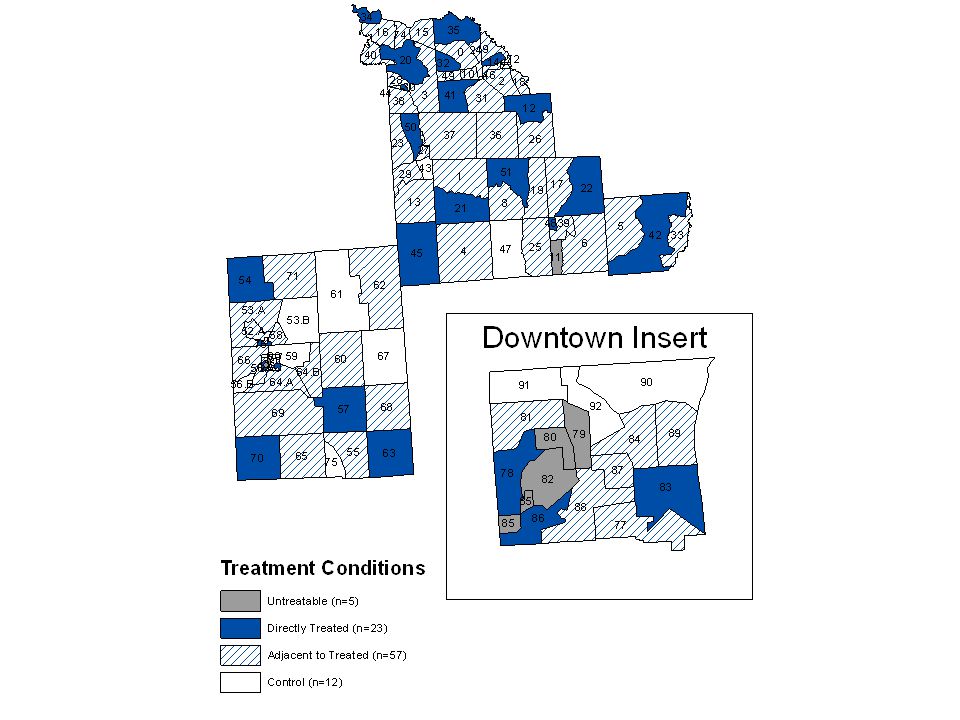
Example: Assessing the effects of lawn signs on a congressional candidate’s vote margin Complication: the precinct in which a lawn sign is planted may not be the precinct in which those who see the lawn sign cast their votes Exposure model: define a potential outcome for (1) precincts that receive signs, (2) precincts that are adjacent to precincts with signs, and (3) precincts that are neither treated nor adjacent to treated precincts Further complication: precincts have different probabilities of assignment to the three conditions
 precincts that receive signs, (2) precincts that are adjacent to precincts with signs, and (3) precincts that are neither treated nor adjacent to treated precincts Further complication: precincts have different probabilities of assignment to the three conditions")
38
Non-interference: Summing up Unless you specifically aim to study spillover, displacement, or contagion, design your study to minimize interference between subjects. Segregate your subjects temporally or spatially so that the assignment or treatment of one subject has no effect on another subject’s potential outcomes. If you seek to estimate spillover effects, remember that you may need to use inverse probability weights to obtain consistent estimates

39
Expect to perform a series of experiments. In social science, one experiment is rarely sufficient to isolate a causal parameter. Experimental findings should be viewed as provisional, pending replication, and even several replications and extensions only begin to suggest the full range of conditions under which a treatment effect may vary across subjects and contexts. Every experiment raises new questions, and every experimental design can be improved in some way.

Similar presentations



 address: Telephone: (27) 2233 Dont hesitate to get in touch.>")


















