Download presentation
Presentation is loading. Please wait.

1
Deepak Turaga 1, Michalis Vlachos 2, Olivier Verscheure 1 1 IBM T.J. Watson Research Center, NY, USA 2 IBM Zürich Research Laboratory, Switzerland On K-Means Cluster Preservation using Quantization Schemes

2
overview – what we want to do… Examine under what conditions compression methodologies retain the clustering outcome We focus on the K-Means algorithm k-Means cluster 1 cluster 2 cluster 3 cluster 1 cluster 2 cluster 3 k-Means identical clustering results original dataquantized data

3
why we want to do that… Reduced Storage –The quantized data will take up less space

4
why we want to do that… Reduced Storage –The quantized data will take up less space Faster execution –Since the data can be represented in a more compact form the cluster algorithm will require less runtime

5
why we want to do that… Reduced Storage –The quantized data will take up less space Faster execution –Since the data can be represented in a more compact form the cluster algorithm will take less runtime Anonymization/Privacy Preservation –The original values are not disclosed

6
why we want to do that… Reduced Storage –The quantized data will take up less space Faster execution –Since the data can be represented in a more compact form the cluster algorithm will take less runtime Anonymization/Privacy Preservation –The original values are not disclosed Authentication –encode some message with the quantization We will achieve the above and still guarantee same results

7
other cluster preservation techniques We do not transform into another space Space requirements same – no data simplification Shape preservation [Oliveira04] S. R. M. Oliveira and O. R. Zaane. Privacy Preservation When Sharing Data For Clustering, 2004 [Parameswaran05] R. Parameswaran and D. Blough. A Robust Data Obfuscation Approach for Privacy Preservation of Clustered Data, 2005 original quantized
![other cluster preservation techniques We do not transform into another space Space requirements same – no data simplification Shape preservation [Oliveira04] S.](http://images.slideplayer.com/8/2346669/slides/slide_7.jpg "R. M. Oliveira and O. R. Zaane. Privacy Preservation When Sharing Data For Clustering, 2004 [Parameswaran05] R. Parameswaran and D. Blough. A Robust Data Obfuscation Approach for Privacy Preservation of Clustered Data, 2005 original quantized.")
8
K-Means Algorithm: 1.Initialize k clusters (k specified by user) randomly. 2.Repeat until convergence 1.Assign each object to the nearest cluster center. 2.Re-estimate cluster centers. k-means overview

9
k-means example

10
k-means applications/usage Fast pre-clustering

11
k-means applications/usage Fast pre-clustering Real-time clustering (eg image, video effects) –Color/Image segmentation
 –Color/Image segmentation")
12
k-means objective function Objective: Mininize sum of intra-class variance Cluster centroid After some algebraic manipulations clusters Dimensions/Time instances 2 nd moment 1 st moment

13
k-means objective function So we can preserve the k-Means outcome if: clusters Dimensions/Time instances 2 nd moment 1 st moment We maintain the cluster assignment We preserve the 1st and 2nd moment of the cluster objects

14
moment preserving quantization 1st moment: average 2 nd (central) moment : variance 3 rd moment: skewness 4 th moment: kyrtosis
 moment : variance 3 rd moment: skewness 4 th moment: kyrtosis")
15
In order to preserve the first and second moment we will use the following quantizer: Everything below the mean value is ‘snapped’ here Everything above the mean value is ‘snapped’ here

16
Everything below the mean value is ‘snapped’ here = 0.2049 = -1.4795 -2.4240 -0.2238 0.0581 -0.4246 -0.2029 -1.5131 -1.1264 -0.8150 0.3666 -0.5861 1.5374 0.1401 -1.8628 -0.4542 -0.6521 0.1033 -0.2206 -0.2790 -0.7337 -0.0645 original -1.4795 0.2049 -1.4795 0.2049 -1.4795 0.2049 -1.4795 0.2049 -1.4795 0.2049 -1.4795 0.2049 quantized -0.4689 average = -0.4689 average =

17
These are the points for one dimension and for one cluster of objects. Process is repeated for all dimensions and for all clusters We have one quantizer per class Dimension d (or time instance d)
.")
18
our quantization One quantizer per class The quantized data are binary

19
our quantization The fact the we have 1 quantizer per class suggests that we need to run k-Means once before we quantize This is not a shortcoming of the technique as we need to know the cluster boundaries so that we know how much we can simplify the data.

20
why quantization works? Why does the clustering remain same before and after quantization? Centers do not change (averages remain same)
.")
21
why quantization works? Why does the clustering remain same before and after quantization? Centers do not change (averages remain same) Cluster assignment does not change because clusters ‘shrink’ due to quantization
 Cluster assignment does not change because clusters ‘shrink’ due to quantization.")
22
will it always work? The results will be the same for datasets with well-formed clusters Discrepancy of results means that clusters were not that dense

23
recap Use moment preserving quantization to preserve objective function Due to cluster shrinkage, cluster assignments will not change Identical results for optimal k-Means One quantizer per class 1-bit quantizer per dimension clusters Dimensions 2 nd moment 1 st moment

24
example: shape preservation

26
[Bagnall06] A. J. Bagnall, C. A. Ratanamahatana, E. J. Keogh, S. Lonardi, and G. J. Janacek. A Bit Level Representation for Time Series Data Mining with Shape Based Similarity. In Data Min. Knowl. Discov. 13(1), pages 11–40, 2006.
![[Bagnall06] A. J. Bagnall, C. A. Ratanamahatana, E.](http://images.slideplayer.com/8/2346669/slides/slide_26.jpg "J. Keogh, S. Lonardi, and G. J. Janacek. A Bit Level Representation for Time Series Data Mining with Shape Based Similarity. In Data Min. Knowl. Discov. 13(1), pages 11–40,")
27
example: cluster preservation 3 years Nasdaq stock ticker data We cluster into k=8 clusters Confusion Matrix

28
8 3% mislabeled data after the moment preserving quantization With Binary Clipping: 80% mislabeled Cluster centers 1 2 3 4 5 6 7

29
quantization levels indicate cluster spread

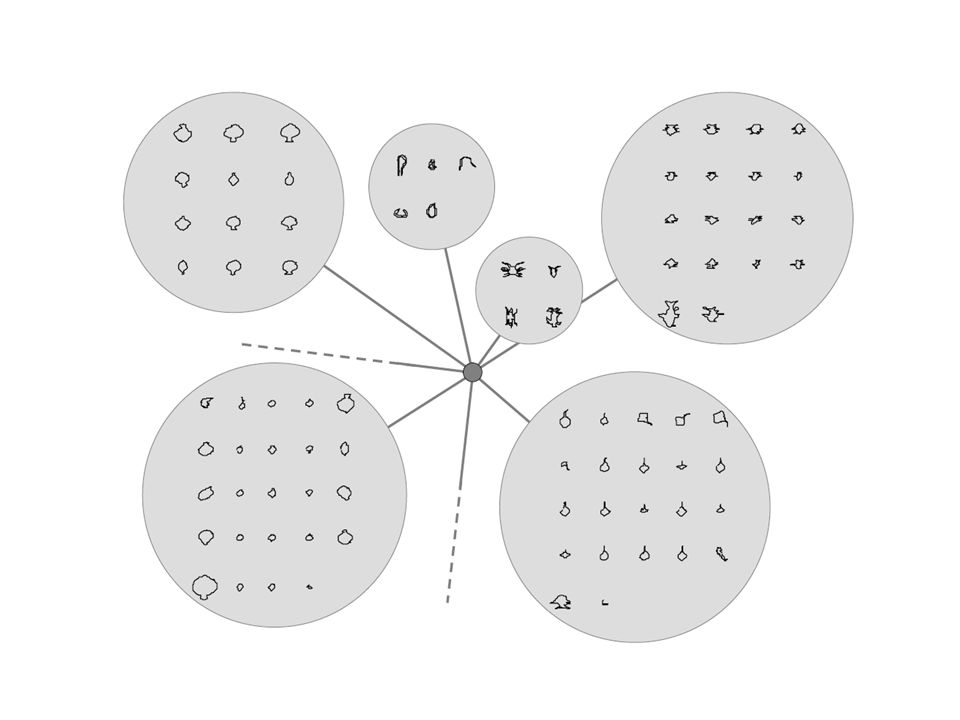
30
example: label preservation 2 datasets –Contours of fish –Contours of leaves Clustering and then k-NN voting Acer platanoidesSalix fragilisTilia Quercus robur For rotation invariance we use a rotation invariant features 0204060 0 1 2 3 4 5 0102030 0 5 10 15 20 25 30 35 space-time frequency

31
example: label preservation Very low mislabeling error for MPQ High error rate for Binary Clipping

33
other nice characteristics Low sensitivity to initial centers –Mismatch when starting from different centers is around 7%

34
other nice characteristics Low sensitivity to initial centers –Mismatch when starting from different centers is around 7% Neighborhood preservation –even though we are not optimizing directly that… –Good results because we are preserving the ‘shape’ of the object A B

35
size reduction by a factor of 3 when using the quantized scheme Compression reduces for increasing K

36
summary 1-bit quantizer per dimension sufficient to preserve kMeans ‘as well as possible’ Theoretically the results will be identical (under conditions) Good ‘shape’ preservation Future work: Multi-bit quantization Multi-dimension quantization
 Good ‘shape’ preservation Future work: Multi-bit quantization Multi-dimension quantization")
37
end..

Similar presentations














>")





