Download presentation
Presentation is loading. Please wait.

1
More on File Management
Chapter 12

2
File Management provide file abstraction for data storage
guarantee, to the extend possible, that data in the file is valid performance: throughput and response time minimize the potential for lost or destroyed data: reliability provide protection API: create, delete, read, write files

3
File Naming files must be referable by unique names
external names: symbolic in a hierarchical file system (UNIX) external names are given as pathnames (path from the root to the file) internal names: i-node in UNIX (an index into an array of file descriptors/headers for a volume) directory: translation from external to internal names (more than one external name for an internal name is allowed) information about file is split between the directory and the file descriptor (in UNIX all of it is stored in the file descriptor): size, location on disk, owner, permissions, date created, date last modified, date last access, link count (in UNIX)
 external names are given as pathnames (path from the root to the file) internal names: i-node in UNIX (an index into an array of file descriptors/headers for a volume) directory: translation from external to internal names (more than one external name for an internal name is allowed) information about file is split between the directory and the file descriptor (in UNIX all of it is stored in the file descriptor): size, location on disk, owner, permissions, date created, date last modified, date last access, link count (in UNIX)")
4
Protection Mechanisms
files are OS objects: unique names and a finite set of operations that processes can perform on them protection domain is a set of {object,rights} where right is the permission to perform one of the operations at every instant in time, each process runs in some protection domain in Unix, a protection domain is {uid, gid} protection domain in Unix is switched when running a program with SETUID/SETGID set or when the process enters the kernel mode by issuing a system call how to store all the protection domains ?

5
Protection Mechanisms (cont’d)
Access Control List (ACL): associate with each object a list of all the protection domains that may access the object and how in Unix ACL is reduced to three protection domains: owner, group and others Capability List (C-list): associate with each process a list of objects that may be accessed along with the operations C-list implementation issues: where/how to store them (hardware, kernel, encrypted in user space) and how to revoke them
: associate with each object a list of all the protection domains that may access the object and how. in Unix ACL is reduced to three protection domains: owner, group and others. Capability List (C-list): associate with each process a list of objects that may be accessed along with the operations. C-list implementation issues: where/how to store them (hardware, kernel, encrypted in user space) and how to revoke them.")
6
Secondary Storage Management
Space must be allocated to files Must keep track of the space available for allocation

7
Preallocation Need the maximum size for the file at the time of creation Difficult to reliably estimate the maximum potential size of the file Tend to overestimated file size so as not to run out of space

8
Methods of File Allocation
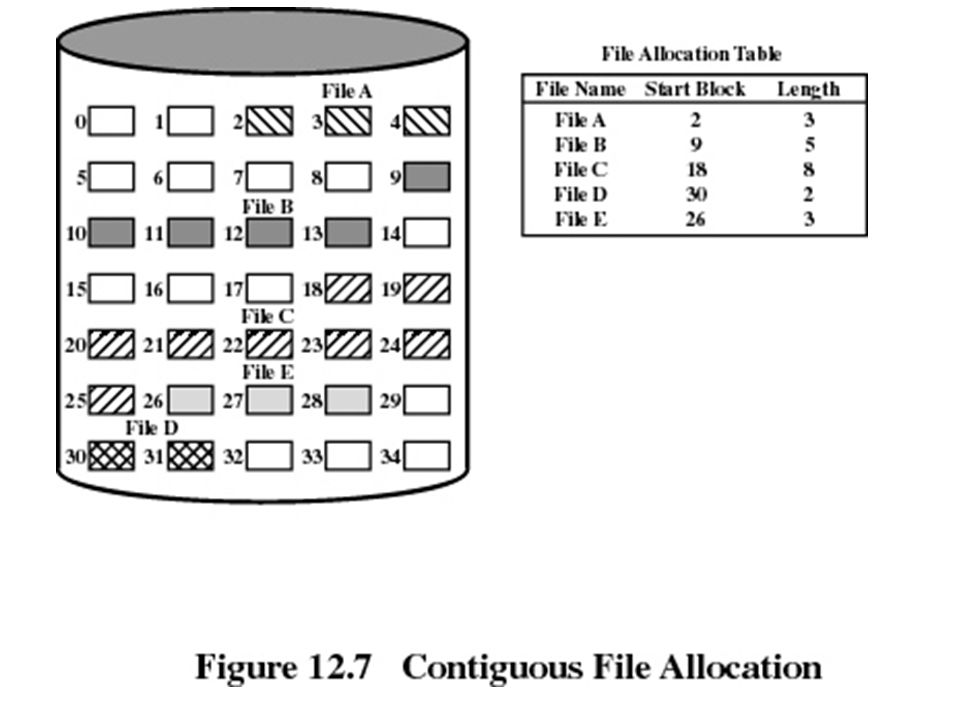
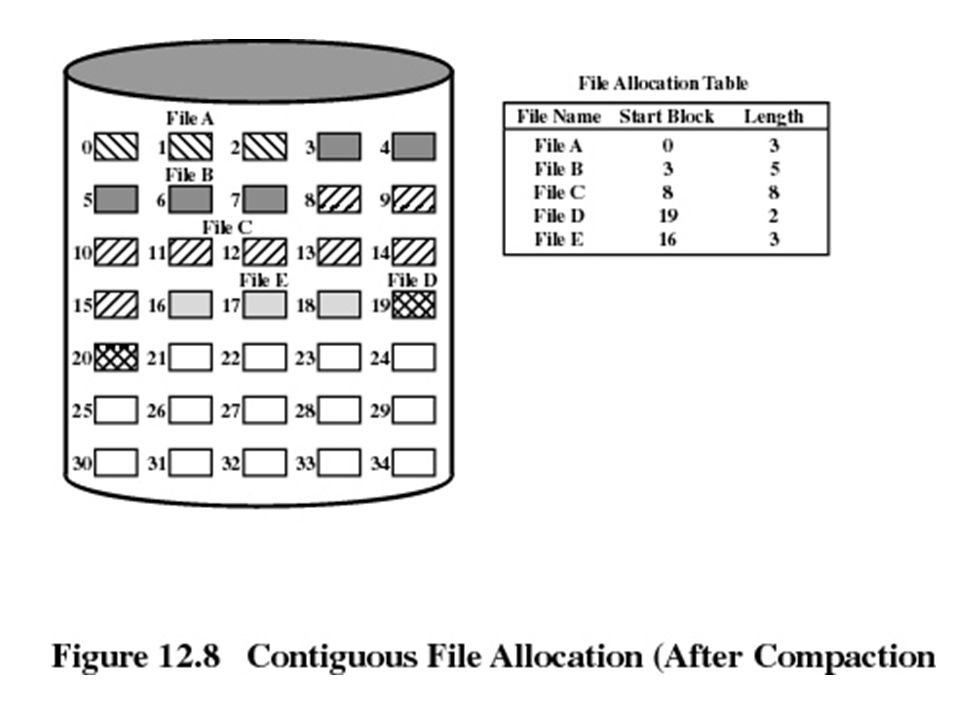
Contiguous allocation Single set of blocks is allocated to a file at the time of creation Only a single entry in the file allocation table Starting block and length of the file External fragmentation will occur

11
Methods of File Allocation
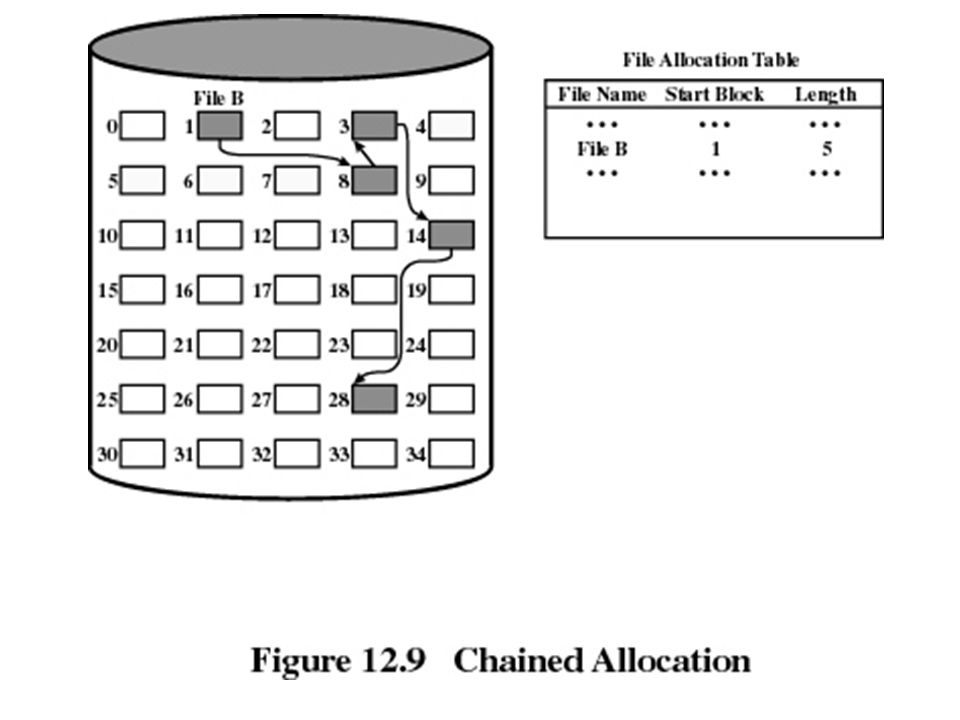
Chained allocation Allocation on basis of individual block Each block contains a pointer to the next block in the chain Only single entry in the file allocation table Starting block and length of file No external fragmentation Best for sequential files No accommodation of the principle of locality

14
Methods of File Allocation
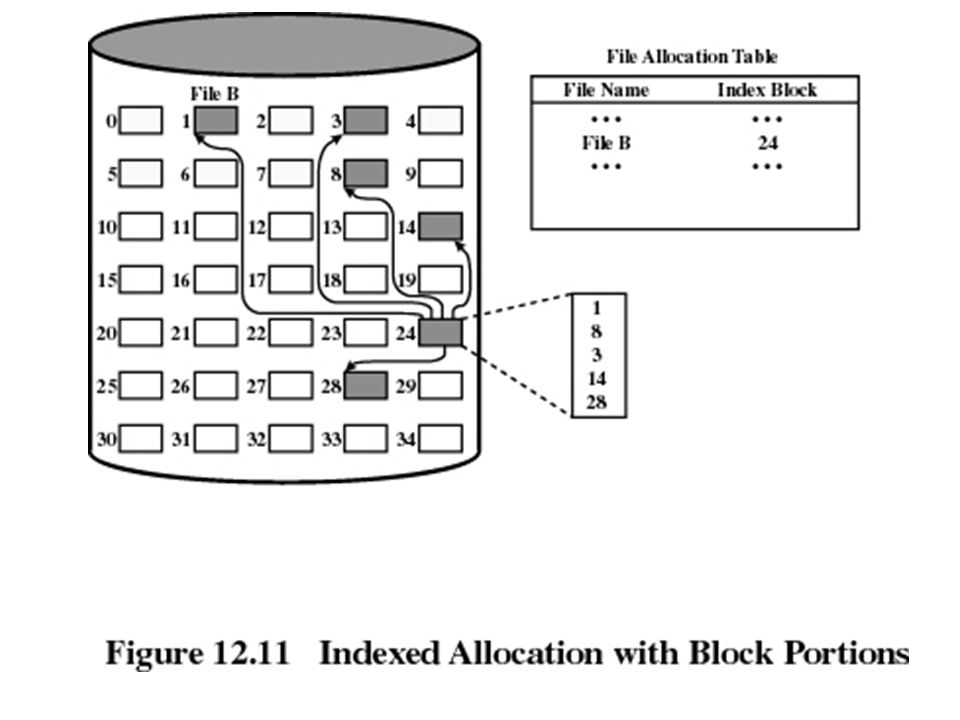
Indexed allocation File allocation table contains a separate one-level index for each file The index has one entry for each portion allocated to the file The file allocation table contains block number for the index

17
File Allocation contiguous: a contiguous set of blocks is allocated to a file at the time of file creation good for sequential files file size must be known at the time of file creation external fragmentation chained allocation: each block contains a pointer to the next one in the chain consolidation to improve locality indexed allocation: good both for sequential and direct access (UNIX)
")
18
Free Space Management bitmap: one bit for each block on the disk
good to find a contiguous group of free blocks small enough to be kept in memory chained free portions: {pointer to the next one, length} index: treats free space as a file

19
UNIX File System Naming Lookup Protection Free Space Management
External/Internal names, Directories Lookup File blocks Disk blocks Protection Free Space Management

20
File Naming External names (used by the application)
Pathname: /usr/users/file1 Internal names (used by the OS kernel) I-node: file number/index on disk File system on disk 1 superblock I-node area ( one I-node per file) File-block area
 I-node: file number/index on disk. File system. on disk. 1. superblock. I-node area. ( one I-node per file) File-block area.")
21
Directories Files which store translation tables (external names to internal names) usr usr users usr users 41 file1 87 Root directory (always I-node 2) /usr/users/file1 corresponds to I-node 87
 /usr/users/file1 corresponds to I-node 87.")
22
File Content Lookup address table used to translate logical file blocks into disk blocks address table stored in the I-node 1 2 45 File with i-node 87 65 Address Table 85 File System disk 45 65 85

24
File Protection ACL with three protection domains (file owner, file owner group, others) Access rights: read/write/execute Stored in the I-node

25
Free Space Management Free I-nodes Free file blocks
Marked as free on disk An array of 50 free I-nodes stored in the superblock Free file blocks Stored as a list of 50- free block arrays First array stored in the superblock

26
In-Kernel File System Data Structures
fd=open(pathname,mode); /* fd = index in Per-Proc OFT */ for (..) read(fd,buf,size); close(fd); Application PCBs Per-process Open File Table OS Kernel Per-OS Open File Table (offset in file, ptr to I-node) I-node cache Buffer cache File system on disk 1
; /* fd = index in Per-Proc OFT */ for (..) read(fd,buf,size); close(fd); Application. PCBs. Per-process. Open File Table. OS Kernel. Per-OS Open File Table. (offset in file, ptr to I-node) I-node cache. Buffer cache. File system. on disk. 1.")
27
File System Consistency
a file system uses the buffer cache for performance reasons two copies of a disk block (buffer cache, disk) -> consistency problem if the system crashes before all the modified blocks are written back to disk the problem is critical especially for the blocks that contain control information (meta-data): directory blocks, i-node, free-list Solution: write through meta-data blocks (expensive) or order of write-back is important ordinary file data blocks written back periodically (sync) utility programs for checking block and directory consistency after crash
 -> consistency problem if the system crashes before all the modified blocks are written back to disk. the problem is critical especially for the blocks that contain control information (meta-data): directory blocks, i-node, free-list. Solution: write through meta-data blocks (expensive) or order of write-back is important. ordinary file data blocks written back periodically (sync) utility programs for checking block and directory consistency after crash.")
28
More on File System Consistency
Example 1: create a new file Two updates: (1) allocate a free I-node; (2) create an entry in the directory (1) and (2) must be write-through (expensive) or (1) must be written-back before (2) If (2) is written back first and a crash occurs before (1) is written back the directory structure is inconsistent and cannot be recovered Example 2: write a new block to a file Two updates: (1) allocate a free block; (2) update the address table of the I-node (1) and (2) must be write-through or (1) must be written-back before (2) If (2) is written back first and a crash occurs before (1) is written back the I-node structure is inconsistent and cannot be recovered
 allocate a free I-node; (2) create an entry in the directory. (1) and (2) must be write-through (expensive) or (1) must be written-back before (2) If (2) is written back first and a crash occurs before (1) is written back the directory structure is inconsistent and cannot be recovered. Example 2: write a new block to a file. Two updates: (1) allocate a free block; (2) update the address table of the I-node. (1) and (2) must be write-through or (1) must be written-back before (2) If (2) is written back first and a crash occurs before (1) is written back the I-node structure is inconsistent and cannot be recovered.")
29
Log-Structured File System (LFS)
as memory gets larger, buffer cache size increases -> increase the fraction of read requests which can be satisfied from the buffer cache with no disk access conclusion: in the future most disk accesses will be writes but writes are usually done in small chunks in most file systems (meta data for instance) which makes the file system highly inefficient LFS idea (Berkeley): to structure the entire disk as a log periodically, or when required, all the pending writes (data and metadata together) being buffered in memory are collected and written as a single contiguous segment at the end of the log
 which makes the file system highly inefficient. LFS idea (Berkeley): to structure the entire disk as a log. periodically, or when required, all the pending writes (data and metadata together) being buffered in memory are collected and written as a single contiguous segment at the end of the log.")
30
LFS segment contain i-nodes, directory blocks and data blocks, all mixed together each segment starts with a segment summary segment size: 512 KB - 1MB two key issues: how to retrieve information from the log how to manage the free space on disk

31
File location in LFS the i-node contains the disk addresses of the file block as in the standard UNIX but there is no fixed location for the i-node an i-node map is used to maintain the current location of each i-node i-node map blocks can also be scattered but a fixed checkpoint region on the disk identifies the location of all the i-node map blocks usually i-node map blocks are cached in main memory most of the time, thus disk accesses for them are rare

32
Segment cleaning in LFS
LFS disk is divided in segments which are written sequentially live data must be copied out of a segment before the segment can be re-written the process of copying data out of a segment: cleaning a separate cleaner thread moves along the log, removes old segments from the end and puts live data into memory for rewriting in the next segment as a result a LFS disk appears like a big circular buffer with the writer thread adding new segments to the front and the cleaner thread removing old segments from the end book-keeping is not trivial: i-node must be updated when blocks are moved to the current segment

Similar presentations

















 Ch 10 - 11.>")




