Download presentation
Presentation is loading. Please wait.

1
Bayesian network classification using spline-approximated KDE Y. Gurwicz, B. Lerner Journal of Pattern Recognition

2
Outline •Introduction •Background on Naïve Bayesian Network •Computational Issue with KDE •Proposed solution: Spline Approximated KDE •Experiments •Conclusion

3
Introduction •Bayesian Network (NB) classifiers have been successfully applied to a variety of domains •Attains asymptotically optimal classification error (i.e., Bayes Risk) given that the conditional and prior density estimates are asymptotically consistent (e.g., KDE) •A particular form of the BN is the Naïve BN (NBN) which has shown to provide good performance in practice and can help alleviate the curse of dimensionality [Zhang 2004] •Hence NBN is the focus of this work
![Introduction •Bayesian Network (NB) classifiers have been successfully applied to a variety of domains •Attains asymptotically optimal classification error (i.e., Bayes Risk) given that the conditional and prior density estimates are asymptotically consistent (e.g., KDE) •A particular form of the BN is the Naïve BN (NBN) which has shown to provide good performance in practice and can help alleviate the curse of dimensionality [Zhang 2004] •Hence NBN is the focus of this work](http://images.slideplayer.com/7/1878435/slides/slide_3.jpg "Introduction •Bayesian Network (NB) classifiers have been successfully applied to a variety of domains •Attains asymptotically optimal classification error (i.e., Bayes Risk) given that the conditional and prior density estimates are asymptotically consistent (e.g., KDE) •A particular form of the BN is the Naïve BN (NBN) which has shown to provide good performance in practice and can help alleviate the curse of dimensionality [Zhang 2004] •Hence NBN is the focus of this work")
4
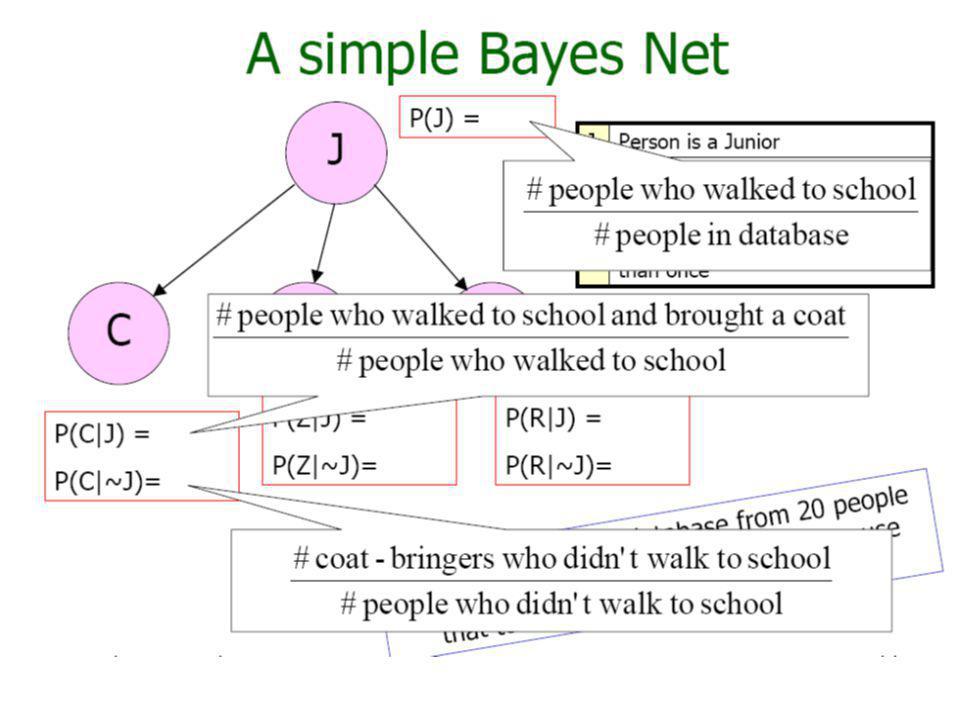
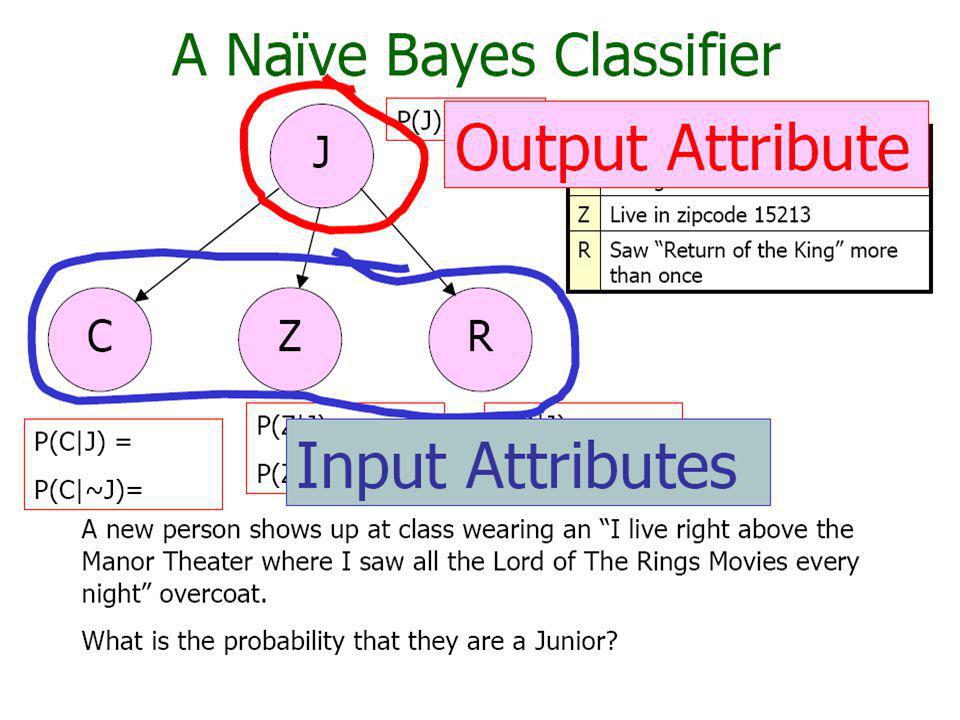
Naïve Bayesian Network (NBN) •A BN expresses joint probability distributions (nodes = RVs, edges = dependencies) •Because expressing node densities is difficult in high dimensions (sample density becomes sparse), the BN can be constrained so that the attributes (RVs) are independent for a given class (increases sample densities) •This constrained BN is called the Naïve BN •The following introductory slides are obtained from A. Moore tutorial

12
Estimating prior and conditional probabilities •Methods for estimating prior P(C) and conditional P(e|C) probabilities –Parametric •Gaussian form are mainly used (CRV) •Fast to compute •May not accurately reflect the true distribution –Non-parametric •KDE •Slow •Can accurately model the true distribution •Can we come up with a fast non-parametric method?
 and conditional P(e|C) probabilities –Parametric •Gaussian form are mainly used (CRV) •Fast to compute •May not accurately reflect the true distribution –Non-parametric •KDE •Slow •Can accurately model the true distribution •Can we come up with a fast non-parametric method")
13
Cost of calculating conditionals •Let N_ts = test patterns; N_tr = training patterns; N_f = # of dimensions; N_c = # of classes •Parametric approach: O(N_ts * N_c * N_f) •Non-parametric approach: O(N_ts * N_tr * N_f) •N_c << N_tr
 •Non-parametric approach: O(N_ts * N_tr * N_f) •N_c << N_tr")
14
Reducing N_tr: Spline approximation •Estimate the KDE using splines •Splines are piecewise polynomial regression of order P interpolated at K intervals over the domain constrained to some smoothness property (e.g., s 1 ’’=s 2 ’’) •Spline regression only requires O(P * Log K) or O (P) (if a hash function is employed) •Usually P = 4 •Hence significant computational savings can be attained over the direct KDE
 •Spline regression only requires O(P * Log K) or O (P) (if a hash function is employed) •Usually P = 4 •Hence significant computational savings can be attained over the direct KDE")
15
Constructing the Splines •Calculate the endpoints for the K intervals to interpolate –K+1 estimates from the KDE –O(K * N_tr) •Calculate the P coefficients for all the individual splines of the K intervals –O(K * P) •Once splines have been obtained, a density query can be computed in O(P) time
 •Calculate the P coefficients for all the individual splines of the K intervals –O(K * P) •Once splines have been obtained, a density query can be computed in O(P) time")
16
Experiment •Measurement –Approximation accuracy –Classification accuracy –Classification speed •Classifiers –BN-KDE –BN-Spline –BN-Gauss •Synthetic and real-world

17
Approximation Accuracy

18
Classification Accuracy

19
Classification Speed

20
Conclusion •Spline based method can well approximate the univariate standard KDE •Speed gains can be realized over the direct KDE •Comments –How to determine the # of intervals in the splines? Analogous problem to bandwidth specification in KDE.. –Assigns static intervals.. Same problem as the global bandwidth –This is an approximation for the global bandwidth KDE. How well do the splines approximate the AKDE? –Proposed method works for static data set, however if data distribution changes, then splines will need to be reconstructed •May not be directly applicable to data streams –Implication to LR-KDE •Develop multi-query algorithms (e.g., deriving K+1 endpoints/knots) •Assign dynamic spline intervals based on regularized LR since each LR models a simple density
 •Assign dynamic spline intervals based on regularized LR since each LR models a simple density.")
21
Reference •H. Zhang, “The optimality of Naïve Bayes”, AAAI 2004

Similar presentations







2005.>")











 – Sections 3.1-3.2 CS479/679 Pattern Recognition Dr. George Bebis.>")


 Qi Thomas P. Minka Rosalind W. Picard Zoubin Ghahramani.>")
 by R. O. Duda, P.>")
