Download presentation
Presentation is loading. Please wait.

1
Danny Bickson Parallel Machine Learning for Large-Scale Graphs
The GraphLab Team: Joe Hellerstein Alex Smola Yucheng Low Joseph Gonzalez Aapo Kyrola Jay Gu Carlos Guestrin

2
Parallelism is Difficult
Wide array of different parallel architectures: Different challenges for each architecture GPUs Multicore Clusters Clouds Supercomputers High Level Abstractions to make things easier

3
How will we design and implement parallel learning systems?

4
Build learning algorithms on-top of high-level parallel abstractions
... a popular answer: Map-Reduce / Hadoop Build learning algorithms on-top of high-level parallel abstractions

5
Map-Reduce for Data-Parallel ML
Excellent for large data-parallel tasks! Data-Parallel Graph-Parallel Map Reduce Feature Extraction Cross Validation Belief Propagation Label Propagation Kernel Methods Deep Belief Networks Neural Tensor Factorization PageRank Lasso Computing Sufficient Statistics

6
Example of Graph Parallelism

7
PageRank Example Iterate: Where: α is the random reset probability
L[j] is the number of links on page j 1 2 3 4 5 6

8
Properties of Graph Parallel Algorithms
Dependency Graph Local Updates Iterative Computation My Rank Friends Rank

9
Addressing Graph-Parallel ML
We need alternatives to Map-Reduce Data-Parallel Graph-Parallel Map Reduce Pregel (Giraph)? Map Reduce? Belief Propagation SVM Kernel Methods Deep Belief Networks Neural Tensor Factorization PageRank Lasso Feature Extraction Cross Validation Computing Sufficient Statistics
 Map Reduce Belief. Propagation. SVM. Kernel. Methods. Deep Belief. Networks. Neural. Tensor. Factorization. PageRank. Lasso. Feature. Extraction. Cross. Validation. Computing Sufficient. Statistics.")
10
Pregel (Giraph) Compute Communicate Bulk Synchronous Parallel Model:
Barrier

11
PageRank in Giraph (Pregel)
bsp_page_rank() { sum = 0 forall (message in in_messages()) sum = sum + message rank = ALPHA + (1-ALPHA) * sum; set_vertex_value(rank); if (current_super_step() < MAX_STEPS) { nedges = num_out_edges() forall (neighbors in out_neighbors()) send_message(rank / nedges); } else vote_to_halt(); } Sum PageRank over incoming messages Send new messages to neighbors or terminate
 { sum = 0. forall (message in in_messages()) sum = sum + message. rank = ALPHA + (1-ALPHA) * sum; set_vertex_value(rank); if (current_super_step() < MAX_STEPS) { nedges = num_out_edges() forall (neighbors in out_neighbors()) send_message(rank / nedges); } else vote_to_halt(); } Sum PageRank over incoming messages. Send new messages to neighbors or terminate.")
12
Bulk synchronous computation can be highly inefficient
Problem: Bulk synchronous computation can be highly inefficient

13
BSP Systems Problem: Curse of the Slow Job
Iterations Barrier Barrier Data Barrier Data Data Data CPU 1 CPU 2 CPU 1 CPU 1 Data CPU 2 CPU 2 Data Data CPU 3 CPU 3 CPU 3 Data Data Data

14
The Need for a New Abstraction
If not Pregel, then what? Data-Parallel Graph-Parallel Map Reduce Pregel (Giraph) Feature Extraction Cross Validation Belief Propagation SVM Kernel Methods Deep Belief Networks Neural Tensor Factorization PageRank Lasso Computing Sufficient Statistics
 Feature. Extraction. Cross. Validation. Belief. Propagation. SVM. Kernel. Methods. Deep Belief. Networks. Neural. Tensor. Factorization. PageRank. Lasso. Computing Sufficient. Statistics.")
15
The GraphLab Solution Designed specifically for ML needs
Express data dependencies Iterative Simplifies the design of parallel programs: Abstract away hardware issues Automatic data synchronization Addresses multiple hardware architectures Multicore Distributed Cloud computing GPU implementation in progress

16
What is GraphLab?

17
The GraphLab Framework
Graph Based Data Representation Update Functions User Computation Consistency Model Scheduler

18
Data Graph A graph with arbitrary data (C++ Objects) associated with each vertex and edge. Graph: Social Network Vertex Data: User profile text Current interests estimates Edge Data: Similarity weights

19
Update Functions An update function is a user defined program which when applied to a vertex transforms the data in the scope of the vertex pagerank(i, scope){ // Get Neighborhood data (R[i], Wij, R[j]) scope; // Update the vertex data // Reschedule Neighbors if needed if R[i] changes then reschedule_neighbors_of(i); } Dynamic computation
{ // Get Neighborhood data. (R[i], Wij, R[j]) scope; // Update the vertex data. // Reschedule Neighbors if needed. if R[i] changes then. reschedule_neighbors_of(i); } Dynamic computation.")
20
PageRank in GraphLab GraphLab_pagerank(scope) { sum = 0
forall ( nbr in scope.in_neighbors() ) sum = sum + neighbor.value() / nbr.num_out_edges() old_rank = scope.vertex_data() scope.center_value() = ALPHA + (1-ALPHA) * sum double residual = abs(scope.center_value() – old_rank) if (residual > EPSILON) reschedule_out_neighbors() }
 ) sum = sum + neighbor.value() / nbr.num_out_edges() old_rank = scope.vertex_data() scope.center_value() = ALPHA + (1-ALPHA) * sum. double residual = abs(scope.center_value() – old_rank) if (residual > EPSILON) reschedule_out_neighbors() }")
21
Actual GraphLab2 Code! PageRank in GraphLab2 BE MORE CLEAR
struct pagerank : public iupdate_functor<graph, pagerank> { void operator()(icontext_type& context) { vertex_data& vdata = context.vertex_data(); double sum = 0; foreach ( edge_type edge, context.in_edges() ) sum += 1/context.num_out_edges(edge.source()) * context.vertex_data(edge.source()).rank; double old_rank = vdata.rank; vdata.rank = RESET_PROB + (1-RESET_PROB) * sum; double residual = abs(vdata.rank – old_rank) / context.num_out_edges(); if (residual > EPSILON) context.reschedule_out_neighbors(pagerank()); } }; BE MORE CLEAR
(icontext_type& context) { vertex_data& vdata = context.vertex_data(); double sum = 0; foreach ( edge_type edge, context.in_edges() ) sum += 1/context.num_out_edges(edge.source()) * context.vertex_data(edge.source()).rank; double old_rank = vdata.rank; vdata.rank = RESET_PROB + (1-RESET_PROB) * sum; double residual = abs(vdata.rank – old_rank) / context.num_out_edges(); if (residual > EPSILON) context.reschedule_out_neighbors(pagerank()); } }; BE MORE CLEAR.")
22
The Scheduler Scheduler
The scheduler determines the order that vertices are updated CPU 1 e f g k j i h d c b a b c Scheduler e f b a i h i j CPU 2 The process repeats until the scheduler is empty

23
The GraphLab Framework
Graph Based Data Representation Update Functions User Computation Consistency Model Scheduler

24
Ensuring Race-Free Code
How much can computation overlap?

25
Potentially Slower Convergence of ML
Need for Consistency? No Consistency Higher Throughput (#updates/sec) Potentially Slower Convergence of ML
 Potentially Slower Convergence of ML.")
26
Inconsistent ALS Consistent Netflix data, 8 cores
Full netflix, 8 cores Highly connected movies, bad intermediate results Netflix data, 8 cores

27
Even Simple PageRank can be Dangerous
GraphLab_pagerank(scope) { ref sum = scope.center_value sum = 0 forall (neighbor in scope.in_neighbors ) sum = sum + neighbor.value / nbr.num_out_edges sum = ALPHA + (1-ALPHA) * sum …
 { ref sum = scope.center_value. sum = 0. forall (neighbor in scope.in_neighbors ) sum = sum + neighbor.value / nbr.num_out_edges. sum = ALPHA + (1-ALPHA) * sum. …")
28
Inconsistent PageRank
8 cores,

29
Point of Convergence

30
Even Simple PageRank can be Dangerous
GraphLab_pagerank(scope) { ref sum = scope.center_value sum = 0 forall (neighbor in scope.in_neighbors) sum = sum + neighbor.value / nbr.num_out_edges sum = ALPHA + (1-ALPHA) * sum … CPU 1 CPU 2 Read Read-write race CPU 1 reads bad PageRank estimate, as CPU 2 computes value
 { ref sum = scope.center_value. sum = 0. forall (neighbor in scope.in_neighbors) sum = sum + neighbor.value / nbr.num_out_edges. sum = ALPHA + (1-ALPHA) * sum. … CPU 1. CPU 2. Read. Read-write race CPU 1 reads bad PageRank estimate, as CPU 2 computes value.")
31
Race Condition Can Be Very Subtle
GraphLab_pagerank(scope) { ref sum = scope.center_value sum = 0 forall (neighbor in scope.in_neighbors) sum = sum + neighbor.value / neighbor.num_out_edges sum = ALPHA + (1-ALPHA) * sum … Unstable GraphLab_pagerank(scope) { sum = 0 forall (neighbor in scope.in_neighbors) sum = sum + neighbor.value / nbr.num_out_edges sum = ALPHA + (1-ALPHA) * sum scope.center_value = sum … Stable This was actually encountered in user code.
 { ref sum = scope.center_value. sum = 0. forall (neighbor in scope.in_neighbors) sum = sum + neighbor.value / neighbor.num_out_edges. sum = ALPHA + (1-ALPHA) * sum. … Unstable. GraphLab_pagerank(scope) { sum = 0. forall (neighbor in scope.in_neighbors) sum = sum + neighbor.value / nbr.num_out_edges. sum = ALPHA + (1-ALPHA) * sum. scope.center_value = sum. … Stable. This was actually encountered in user code.")
32
GraphLab Ensures Sequential Consistency
For each parallel execution, there exists a sequential execution of update functions which produces the same result. CPU 1 time Parallel CPU 2 Single CPU Sequential

33
Consistency Rules Full Consistency Data Guaranteed sequential consistency for all update functions

34
Full Consistency Full Consistency

35
Obtaining More Parallelism
Full Consistency Edge Consistency

36
Edge Consistency Edge Consistency CPU 1 CPU 2 Safe Read

37
The GraphLab Framework
Graph Based Data Representation Update Functions User Computation Consistency Model Scheduler

38
What algorithms are implemented in GraphLab?

39
Dynamic Block Gibbs Sampling
Alternating Least Squares SVD Splash Sampler CoEM Bayesian Tensor Factorization Lasso Belief Propagation PageRank LDA SVM Gibbs Sampling Dynamic Block Gibbs Sampling K-Means Matrix Factorization …Many others… Linear Solvers

40
GraphLab Libraries Matrix factorization Linear Solvers Clustering
SVD,PMF, BPTF, ALS, NMF, Sparse ALS, Weighted ALS, SVD++, time-SVD++, SGD Linear Solvers Jacobi, GaBP, Shotgun Lasso, Sparse logistic regression, CG Clustering K-means, Fuzzy K-means, LDA, K-core decomposition Inference Discrete BP, NBP, Kernel BP

41
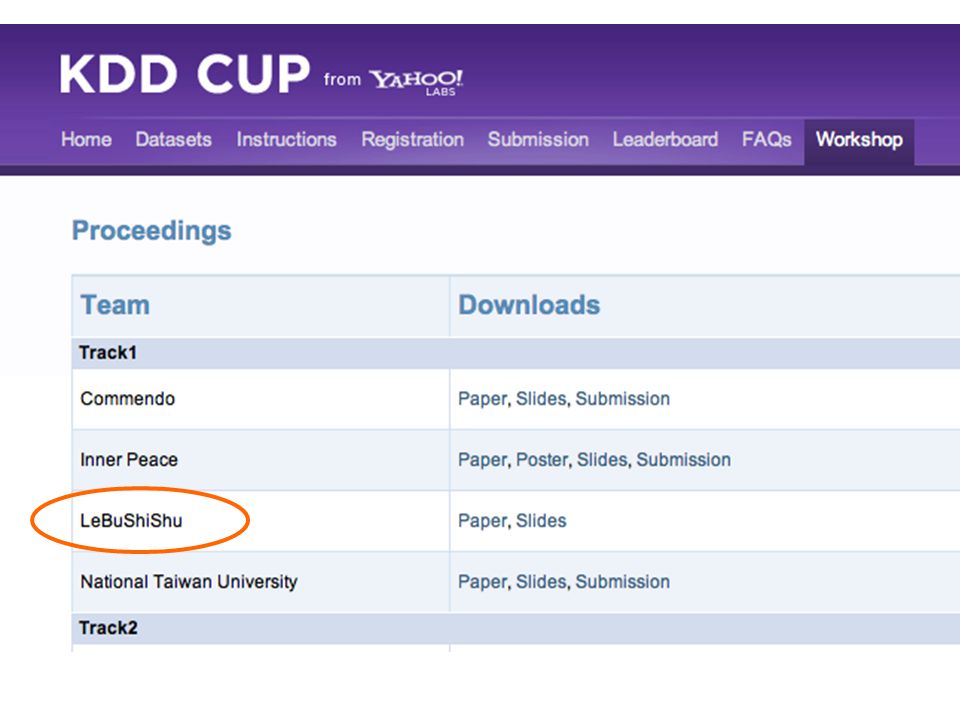
Institute of Automation Chinese Academy of Sciences
Efficient Multicore Collaborative Filtering LeBuSiShu team – 5th place in track1 Yao Wu Qiang Yan Qing Yang Danny Bickson Yucheng Low Institute of Automation Chinese Academy of Sciences Machine Learning Dept Carnegie Mellon University ACM KDD CUP Workshop 2011

43
ACM KDD CUP 2011 Task: predict music score Two main challenges:
Data magnitude – 260M ratings Taxonomy of data

44
Data taxonomy

45
Our approach Use ensemble method
Custom SGD algorithm for handling taxonomy This graph shows performance of the different methods using RMSE metric (root square mean error) Note that time-MFITR has very good performance after time-svd++
 Note that time-MFITR has very good performance after time-svd++")
46
Ensemble method Solutions are merged using linear regression

47
Performance results Blended Validation RMSE: 19.90
This graph shows performance of the different methods using RMSE metric (root square mean error) Note that time-MFITR has very good performance after time-svd++
 Note that time-MFITR has very good performance after time-svd++")
48
Classical Matrix Factorization
Sparse Matrix Users Item MFITR is our developed novel method for coping with KDD characteristics of data, namely hierarchy of track, album artist and genere. It is composed of two elements. This slides discusses the first element. r_ui – is the scalar predicted rating between user u and item i. We have here a linear prediction rule. Mu – is the model mean b_i, b_u, b_a are biases of item user and artiest, which are learned from the data. q_i, q_a, p_u are feature vectors which are learned form the data 1) In addition to linear model of matrix factorization who factor the model into user and feature vectors, we add an additional feature which is the artist feature (noted q_a) d
 In addition to linear model of matrix factorization who factor the model into user and feature vectors, we add an additional feature which is the artist feature (noted q_a) d.")
49
MFITR Features of the Artist Features of the Album
Sparse Matrix Users Features of the Artist Features of the Album Item Specific Features “Effective Feature of an Item” d MFITR is our developed novel method for coping with KDD characteristics of data, namely hierarchy of track, album artist and genere. It is composed of two elements. This slides discusses the first element. r_ui – is the scalar predicted rating between user u and item i. We have here a linear prediction rule. Mu – is the model mean b_i, b_u, b_a are biases of item user and artiest, which are learned from the data. q_i, q_a, p_u are feature vectors which are learned form the data 1) In addition to linear model of matrix factorization who factor the model into user and feature vectors, we add an additional feature which is the artist feature (noted q_a)
 In addition to linear model of matrix factorization who factor the model into user and feature vectors, we add an additional feature which is the artist feature (noted q_a)")
50
Penalty terms which ensure Artist/Album/Track features are “close”
Intuitively, features of an artist and features of his/her album should be “similar”. How do we express this? Artist Penalty terms which ensure Artist/Album/Track features are “close” Strength of penalty depends on “normalized rating similarity” (See neighborhood model) Album Track
 Album. Track.")
51
Fine Tuning Challenge Dataset has around 260M observed ratings
12 different algorithms, total 53 tunable parameters How do we train and cross validate all these parameters? USE GRAPHLAB!

52
16 Cores Runtime This plot shows run time using 8 cores. While SGD is very fast, it has a worst speedup relative to ALS.

53
Speedup plots Yucheng knows what is speedup – so I don’t need to write it down… Anyway we can see that alternating least squares style algo perform very well since once a subset of nodes (user or movie) are fixes, all the other nodes (movies/user) can be run in parallel. SGD and SVD++ perform less well, since when two users have seen the same movie they need to update the movie feature vector at the same time
 are fixes, all the other nodes (movies/user) can be run in parallel. SGD and SVD++ perform less well, since when two users have seen the same movie they need to update the movie feature vector at the same time.")
55
Who is using GraphLab?

56
Universities using GraphLab

57
Companies tyring out GraphLab
Startups using GraphLab Unique Downloads Tracked (possibly many more from direct repository checkouts) Companies tyring out GraphLab
 Companies tyring out GraphLab.")
58
User community

59
Performance results

60
GraphLab vs. Pregel (BSP)
(via GraphLab) GraphLab Pregel (via GraphLab) 51% updated only once Multicore PageRank (25M Vertices, 355M Edges)
 GraphLab. Pregel. (via GraphLab) 51% updated only once. Multicore PageRank (25M Vertices, 355M Edges)")
61
CoEM (Rosie Jones, 2005) Vertices: 2 Million Edges: 200 Million Hadoop
Named Entity Recognition Task the dog Australia Catalina Island <X> ran quickly travelled to <X> <X> is pleasant Is “Dog” an animal? Is “Catalina” a place? Vertices: 2 Million Edges: 200 Million Hadoop 95 Cores 7.5 hrs

62
CoEM (Rosie Jones, 2005) Hadoop 95 Cores 7.5 hrs GraphLab 16 Cores
Better Optimal GraphLab CoEM Hadoop 95 Cores 7.5 hrs GraphLab 16 Cores 30 min 15x Faster! 6x fewer CPUs! 62

63
GraphLab in the Cloud

64
CoEM (Rosie Jones, 2005) 0.3% of Hadoop time Hadoop 95 Cores 7.5 hrs
Better Optimal Large Hadoop 95 Cores 7.5 hrs GraphLab 16 Cores 30 min Small GraphLab in the Cloud 32 EC2 machines 80 secs 0.3% of Hadoop time

65
Cost-Time Tradeoff a few machines helps a lot faster
video co-segmentation results a few machines helps a lot faster diminishing returns more machines, higher cost

66
Netflix Collaborative Filtering
Alternating Least Squares Matrix Factorization Model: 0.5 million nodes, 99 million edges Ideal D=100 D=20 Netflix Users Movies Hadoop MPI GraphLab D

67
Multicore Abstraction Comparison
Dynamic Computation, Faster Convergence Netflix Matrix Factorization

68
The Cost of Hadoop

69
Fault Tolerance

70
Fault-Tolerance Larger Problems Increased chance of Machine Failure
GraphLab2 Introduces two fault tolerance (checkpointing) mechanisms Synchronous Snapshots Chandi-Lamport Asynchronous Snapshots
 mechanisms. Synchronous Snapshots. Chandi-Lamport Asynchronous Snapshots.")
71
Synchronous Snapshots
Run GraphLab Run GraphLab Barrier + Snapshot Time Run GraphLab Run GraphLab Barrier + Snapshot Run GraphLab Run GraphLab

72
Curse of the slow machine
No Snapshot sync. Snapshot

73
Curse of the Slow Machine
Run GraphLab Run GraphLab Time Barrier + Snapshot Run GraphLab Run GraphLab

74
Curse of the slow machine
No Snapshot Delayed sync. Snapshot sync. Snapshot

75
Asynchronous Snapshots
Chandy Lamport algorithm implementable as a GraphLab update function! Requires edge consistency struct chandy_lamport { void operator()(icontext_type& context) { save(context.vertex_data()); foreach ( edge_type edge, context.in_edges() ) { if (edge.source() was not marked as saved) { save(context.edge_data(edge)); context.schedule(edge.source(), chandy_lamport()); } ... Repeat for context.out_edges Mark context.vertex() as saved; };
(icontext_type& context) { save(context.vertex_data()); foreach ( edge_type edge, context.in_edges() ) { if (edge.source() was not marked as saved) { save(context.edge_data(edge)); context.schedule(edge.source(), chandy_lamport()); } ... Repeat for context.out_edges. Mark context.vertex() as saved; };")
76
Snapshot Performance Async. Snapshot No Snapshot sync. Snapshot

77
Snapshot with 15s fault injection
Halt 1 out of 16 machines 15s sync. Snapshot No Snapshot Async. Snapshot

78
New challenges

79
Natural Graphs Power Law
Yahoo! Web Graph: 1.4B Verts, 6.7B Edges “Power Law” Top 1% of vertices is adjacent to 53% of the edges!

80
Problem: High Degree Vertices
High degree vertices limit parallelism: Requires Heavy Locking Touch a Large Amount of State Processed Sequentially

81
High Communication in Distributed Updates
Split gather and scatter across machines: Machine 1 Machine 2 Y Data from neighbors transmitted separately across network

82
High Degree Vertices are Common
Popular Movies “Social” People Users Movies Netflix Hyper Parameters Common Words Obama Docs Words LDA θ Z w B α θ Z w θ Z w θ Z w

83
Two Core Changes to Abstraction
Factorized Update Functors Delta Update Functors Monolithic Updates + Gather Apply Scatter Decomposed Updates Monolithic Updates Composable Update “Messages” f1 f2 (f1o f2)( )
( )")
84
PageRank in GraphLab Parallel “Sum” Gather Atomic Single Vertex Apply
struct pagerank : public iupdate_functor<graph, pagerank> { void operator()(icontext_type& context) { vertex_data& vdata = context.vertex_data(); double sum = 0; foreach ( edge_type edge, context.in_edges() ) sum += 1/context.num_out_edges(edge.source()) * context.vertex_data(edge.source()).rank; double old_rank = vdata.rank; vdata.rank = RESET_PROB + (1-RESET_PROB) * sum; double residual = abs(vdata.rank – old_rank) / context.num_out_edges(); if (residual > EPSILON) context.reschedule_out_neighbors(pagerank()); } }; Parallel “Sum” Gather Atomic Single Vertex Apply Parallel Scatter [Reschedule] BE MORE CLEAR
(icontext_type& context) { vertex_data& vdata = context.vertex_data(); double sum = 0; foreach ( edge_type edge, context.in_edges() ) sum += 1/context.num_out_edges(edge.source()) * context.vertex_data(edge.source()).rank; double old_rank = vdata.rank; vdata.rank = RESET_PROB + (1-RESET_PROB) * sum; double residual = abs(vdata.rank – old_rank) / context.num_out_edges(); if (residual > EPSILON) context.reschedule_out_neighbors(pagerank()); } }; Parallel Sum Gather. Atomic Single Vertex Apply. Parallel Scatter [Reschedule] BE MORE CLEAR.")
85
Decomposable Update Functors
Locks are acquired only for region within a scope Relaxed Consistency Gather Apply Y Scatter( ) Update adjacent edges and vertices. User Defined: Scatter Scope Y Y Y Parallel Sum Y Y Apply( , Δ) Apply the accumulated value to center vertex User Defined: … Δ Y User Defined: Gather( ) Δ Y Δ1 + Δ2 Δ3
 Update adjacent edges and vertices. User Defined: Scatter. Scope. Y. Y. Y. Parallel. Sum. Y. Y. Apply( , Δ) Apply the accumulated value to center vertex. User Defined: + + … + Δ. Y. User Defined: Gather( ) Δ. Y. Δ1 + Δ2 Δ3.")
86
Factorized PageRank double gather(scope, edge) {
return edge.source().value().rank / scope.num_out_edge(edge.source()) } double merge(acc1, acc2) { return acc1 + acc2 } void apply(scope, accum) { old_value = scope.center_value().rank scope.center_value().rank = ALPHA + (1 - ALPHA) * accum scope.center_value().residual = abs(scope.center_value().rank – old_value) void scatter(scope, edge) { if (scope.center_vertex().residual > EPSILON) reschedule_schedule(edge.target())
.value().rank / scope.num_out_edge(edge.source()) } double merge(acc1, acc2) { return acc1 + acc2 } void apply(scope, accum) { old_value = scope.center_value().rank. scope.center_value().rank = ALPHA + (1 - ALPHA) * accum. scope.center_value().residual = abs(scope.center_value().rank – old_value) void scatter(scope, edge) { if (scope.center_vertex().residual > EPSILON) reschedule_schedule(edge.target())")
87
Factorized Updates: Significant Decrease in Communication
Split gather and scatter across machines: Y Y F1 F2 ( o )( ) Y Y Y Y Small amount of data transmitted over network
( ) Y. Y. Y. Y. Small amount of data transmitted over network.")
88
Factorized Consistency
Neighboring vertices maybe be updated simultaneously: Gather Gather A B

89
Factorized Consistency Locking
Gather on an edge cannot occur during apply: Gather A B Apply Vertex B gathers on other neighbors while A is performing Apply

90
Factorized PageRank BE MORE CLEAR
struct pagerank : public iupdate_functor<graph, pagerank> { double accum = 0, residual = 0; void gather(icontext_type& context, const edge_type& edge) { accum += 1/context.num_out_edges(edge.source()) * context.vertex_data(edge.source()).rank; } void merge(const pagerank& other) { accum += other.accum; } void apply(icontext_type& context) { vertex_data& vdata = context.vertex_data(); double old_value = vdata.rank; vdata.rank = RESET_PROB + (1 - RESET_PROB) * accum; residual = fabs(vdata.rank – old_value) / context.num_out_edges(); void scatter(icontext_type& context, const edge_type& edge) { if (residual > EPSILON) context.schedule(edge.target(), pagerank()); }; BE MORE CLEAR
 { accum += 1/context.num_out_edges(edge.source()) * context.vertex_data(edge.source()).rank; } void merge(const pagerank& other) { accum += other.accum; } void apply(icontext_type& context) { vertex_data& vdata = context.vertex_data(); double old_value = vdata.rank; vdata.rank = RESET_PROB + (1 - RESET_PROB) * accum; residual = fabs(vdata.rank – old_value) / context.num_out_edges(); void scatter(icontext_type& context, const edge_type& edge) { if (residual > EPSILON) context.schedule(edge.target(), pagerank()); }; BE MORE CLEAR.")
91
Decomposable Loopy Belief Propagation
Gather: Accumulates product of in messages Apply: Updates central belief Scatter: Computes out messages and schedules adjacent vertices

92
Decomposable Alternating Least Squares (ALS)
y1 y2 y3 y4 w1 w2 x1 x2 x3 User Factors (W) Movie Factors (X) Users Movies Netflix ≈ x xj wi Update Function: Gather: Sum terms Apply: matrix inversion & multiply
 Movie Factors (X) Users. Movies. Netflix. ≈ x. xj. wi. Update. Function: Gather: Sum terms. Apply: matrix inversion & multiply.")
93
Decomposable Functors
Fits many algorithms Loopy Belief Propagation, Label Propagation, PageRank… Addresses the earlier concerns: Large State Distributed Gather and Scatter Heavy Locking Fine Grained Locking Sequential Parallel Gather and Scatter

94
Comparison of Abstractions
GraphLab1 Factorized Updates Multicore PageRank (25M Vertices, 355M Edges)
")
95
Need for Vertex Level Asynchrony
Costly gather for a single change! Y Exploit commutative associative “sum” Y

96
Commut-Assoc Vertex Level Asynchrony
Exploit commutative associative “sum” Y

97
Commut-Assoc Vertex Level Asynchrony
+ Δ Exploit commutative associative “sum” Δ Y

98
Delta Updates: Vertex Level Asynchrony
Exploit commutative associative “sum” Δ Old (Cached) Sum Y
 Sum. Y.")
99
Delta Updates: Vertex Level Asynchrony
Δ Exploit commutative associative “sum” Δ Old (Cached) Sum Y
 Sum. Y.")
100
Delta Update Program starts with: schedule_all(ALPHA)
void update(scope, delta) { scope.center_value() = scope.center_value() + delta if(abs(delta) > EPSILON) { out_delta = delta * (1 – ALPHA) * 1 / scope.num_out_edge(edge.source()) reschedule_out_neighbors(delta) } double merge(delta, delta) { return delta + delta } Slide 92 Program starts with: schedule_all(ALPHA)
 { scope.center_value() = scope.center_value() + delta. if(abs(delta) > EPSILON) { out_delta = delta * (1 – ALPHA) * 1 / scope.num_out_edge(edge.source()) reschedule_out_neighbors(delta) } double merge(delta, delta) { return delta + delta } Slide 92. Program starts with: schedule_all(ALPHA)")
101
Scheduling Composes Updates
Calling reschedule neighbors forces update function composition: reschedule_out_neighbors(pagerank(3)) pagerank(3) pagerank(3) Pending: pagerank(10) Pending: pagerank(7) Pending: pagerank(3)
) pagerank(3) pagerank(3) Pending: pagerank(10) Pending: pagerank(7) Pending: pagerank(3)")
102
Multicore Abstraction Comparison
Multicore PageRank (25M Vertices, 355M Edges)
")
103
Distributed Abstraction Comparison
GraphLab1 GraphLab1 GraphLab2 (Delta Updates) GraphLab2 (Delta Updates) Distributed PageRank (25M Vertices, 355M Edges)
 GraphLab2 (Delta Updates) Distributed PageRank (25M Vertices, 355M Edges)")
104
PageRank 1.4B vertices, 6.7B edges Altavista Webgraph 2002 Hadoop
800 cores Prototype GraphLab2 431s 512 cores Known Inefficiencies. 2x gain possible

105
Summary of GraphLab2 Decomposed Update Functions: Expose parallelism in high-degree vertices: Delta Update Functions: Expose asynchrony in high-degree vertices + Gather Apply Scatter Y Δ Y

106
Lessons Learned Machine Learning: System:
Asynchronous often much faster than Synchronous Distributed asynchronous systems are harder to build Dynamic computation often faster But, no distributed barriers == better scalability and performance However, can be difficult to define optimal thresholds: Scaling up by an order of magnitude requires rethinking of design assumptions Science to do! Consistency can improve performance E.g., distributed graph representation Sometimes required for convergence High degree vertices & natural graphs can limit parallelism Though there are cases where relaxed consistency is sufficient Need further assumptions on update functions

107
Summary An abstraction tailored to Machine Learning
Targets Graph-Parallel Algorithms Naturally expresses Data/computational dependencies Dynamic iterative computation Simplifies parallel algorithm design Automatically ensures data consistency Achieves state-of-the-art parallel performance on a variety of problems

108
Parallel GraphLab 1.1 Multicore Available Today GraphLab2 (in the Cloud) soon…
Documentation… Code… Tutorials…

Similar presentations












![1 Machine Learning with Apache Hama Tommaso Teofili tommaso [at] apache [dot] org.](/15/4743173/big_thumb.jpg "1 Machine Learning with Apache Hama Tommaso Teofili tommaso [at] apache [dot] org.>")







