Download presentation
Presentation is loading. Please wait.

1
PVM : Parallel Virtual Machine The poor man s super- computer Yvon Kermarrec Based on http://www.pcc.qub.ac.uk/tec/courses/pvm/

2
PVM PVM is a software package that permits a heterogeneous collection of serial, parallel and vector computers which are connected to a network to appear as one large computing resource. PVM combines the power of a number of computers PVM may be used to create a virtual computer from multiple supercomputers enabling the solution of previously unsolvable "grand challenge" problems It is a poor man s supercomputer allowing one to exploit the aggregate power of unused worksstations during off-hours PVM may be used as an educational tool to create a parallel computer from low cost workstations

3
PVM Key features Easily obtainable public domain package Easy to install and to configure Many different virtual machines may co-exist on the same hardware Program development using a widely adopted message passing library Supports C / C++ and Fortran Installation only requires a few Mb of disk space Simple migration path to MPI

4
PVM history PVM project began in 1989 at Oak Ridge National Laboratory - prototype PVM 1.0 – US department of Energy Version 2.0 was written at the University of Tennessee and released in March 1991 PVM 2.1 -> 2.4 evolved as a response to user feedback Version 3 was completed in February 1993 The current version is 3.3 and subsequent releases are expected

5
Parallel processing Parallel processing is the method of using many small tasks to solve one large problem. 2 major developments have assisted parallel processing acceptance massively parallel processors (MPPs). the widespread use of distributed computing - process whereby a set of computers connected by a network are used collectively to solve a single large problem common to both is the notion of message-passing - in all parallel processing data must be exchanged between co-operating tasks.
. the widespread use of distributed computing - process whereby a set of computers connected by a network are used collectively to solve a single large problem common to both is the notion of message-passing - in all parallel processing data must be exchanged between co-operating tasks..")
6
PVM Parallel Virtual Machine (PVM) uses the message passing model to allow programmers to exploit distributed computing across a wide variety of computer types, including MPPs. When a programmer wishes to exploit a collection of networked computers, they may have to contend with several different types of heterogeneity: architecture data format computational speed machine load and network load.

7
PVM benefits (1/2) Using existing hardware keeps costs low Performance can be optimised by assigning each individual task to the most appropriate architecture Exploitation of the heterogeneous nature of a computation ie provides access to different types of processors for those parts of an application that can only run on a certain platform Virtual computer resources can grow in stages and take advantage of the latest computational and network technologies Program development can be enhanced by using a familiar environment ie editors, compilers, debuggers that are available on individual machines
 Using existing hardware keeps costs low Performance can be optimised by assigning each individual task to the most appropriate architecture Exploitation of the heterogeneous nature of a computation ie provides access to different types of processors for those parts of an application that can only run on a certain platform Virtual computer resources can grow in stages and take advantage of the latest computational and network technologies Program development can be enhanced by using a familiar environment ie editors, compilers, debuggers that are available on individual machines")
8
PVM benefits (2/2) Individual computers and workstations are usually stable and substantial expertise in their use should be available User-level or program-level fault tolerance can be implemented with little effort either in the application or in the underlying operating system Facilitates collaborative work
 Individual computers and workstations are usually stable and substantial expertise in their use should be available User-level or program-level fault tolerance can be implemented with little effort either in the application or in the underlying operating system Facilitates collaborative work")
9
PVM overview PVM provides a unified framework within which parallel programs can be developed efficiently using existing hardware. PVM transparently handles all message routing, data conversion, and task scheduling across a network of incompatible computer architectures. The programming interface is straightforward allowing simple program structures to be implemented in an intuitive manner. The user writes his application as a collection of co- operating tasks which access PVM resources through a library of standard interface routines.

10
Underlying principles (1/2) User-configured host pool: tasks execute on a set of machines selected by the user for a given run of the PVM program the host pool may be altered by adding/deleting machines during operation Translucent access to hardware: programs may view the hardware environment as an attributeless collection of virtual processing elements or may choose to exploit the capabilities of specific machines by placing certain tasks on certain machines.
 User-configured host pool: tasks execute on a set of machines selected by the user for a given run of the PVM program the host pool may be altered by adding/deleting machines during operation Translucent access to hardware: programs may view the hardware environment as an attributeless collection of virtual processing elements or may choose to exploit the capabilities of specific machines by placing certain tasks on certain machines.")
11
Underlying principles (2/2) Process-based computation: A task is the unit of parallelism in PVM - it is an independent sequential thread of control that alternates between communication and computation. Explicit message-passing model: Tasks co-operate by explicitly sending and receiving messages to and from one another. Message size is limited only by the amount of available memory. Heterogeneity support: PVM supports heterogeneity in terms of machines, networks and applications. Messages can also contain one or more data types to be exchanged between machines having different data representations.

12
PVM supported approaches Functional Parallelism - an application can be parallelised along its functions so that each task performs a different function eg input, problem setup, solution, output and display. Data Parallelism - all the tasks are the same but each one only knows and solves a part of the data. This is also known as SPMD(single- program multiple data).
..")
13
PVM programming paradigm A user writes one or more sequential programs in C, C++ or Fortran 77 containing embedded calls to the PVM library. Each program corresponds to a task making up the application. The programs are compiled for each architecture in the host pool and the resulting object files are placed at a location accessible from machines in the host pool An application is executed when the user starts one copy of the application ie the `master' or `initiating' task, by hand from a machine within the host pool.

14
PVM programming paradigm The `master` process subsequently starts other PVM tasks, eventually there are a number of active tasks to compute and communicate to solve the problem. Tasks may interact through explicit message- passing using the system assigned opaque TID to identify each other. Finally once the tasks are finished they and the `master' task disassociate themselves from PVM by exiting from the PVM system.

15
Parallel models (1/3) Crowd computation Tree computation Hybrid moel
 Crowd computation Tree computation Hybrid moel")
16
Parallel models (2/3) The "crowd" computing model - consists of a collection of closely related processes, typically executing the same code, performing calculations on different portions of the workload and usually involving the periodic exchange of intermediate results eg master-slave (or host-mode) model has a separate `control' program ie the master which is responsible for spawning, initialization, collection and display of results. The slave programs perform the actual computations on the workload allocated either by the master or by themselves node-to-node model where multiple instances of a single program execute, with one process (typically the one initiated manually) taking over the noncomputational responsibilities as well as contributing to the calculation itself.
 taking over the noncomputational responsibilities as well as contributing to the calculation itself..")
17
Parallel models (3/3) A `tree' computation model - processes are spawned (usually dynamically as the computation grows) in a tree-like manner establishing a tree-like parent-child relationship eg branch-and-bound algorithms, alpha-beta search, and recursive `divide-and- conquer' algorithms. A `hybrid' or combination model- possesses an arbitrary spawning structure in that at any point in the application execution the process relationship may resemble an arbitrary and changing graph.

18
Workload allocation (1/3) For problesm which are too complex / too big to be resolved on a single computer Data decomposition Function decomposition
 For problesm which are too complex / too big to be resolved on a single computer Data decomposition Function decomposition")
19
Workload allocation (2/3) Data decomposition assumes that the overall problem involves applying computational operations or transformations on one or more data structures and that these data structures may be divided and operated upon. Eg if vectors of N elements and P processors are available N/P elements are assigned to each process. Partitioning can be done either `statically' where each processor knows at the beginning its workload or `dynamically' where a control or master process assigns portions of the workload to processor as and when they become free.

20
Workload allocation (3/3) Function decomposition divides the work based on different operations or functions. Eg the three stages of a typical program execution - input, processing and output or results could take the form of three separate and distinct programs each one being dedicated to one of the stages. Parallelism is obtained by concurrently executing the three programs and establishing a `pipeline' between them. A more realistic form of function decomposition is to partition the workload according to functions within the computational phase eg the different sub-algorithms which typically exist in application computations.

21
Heterogeneity Supported at 3 levels Application: tasks may be placed on processors to which they are most suited Machine: Computers with different data formats, different architectures(serial or parallel), and different operating systems Network: A virtual machine may span different types of networks such as FDDI, ethernet, ATM
, and different operating systems Network: A virtual machine may span different types of networks such as FDDI, ethernet, ATM")
22
Portability PVM is available across a wide range of Unix based computers PVM version 3 may be ported to non- Unix machines PVM will soon be ported to VMS Versions of PVM are available on machines such as CCM-5, CS-2 and iPSC/860, Cray T3D

23
Software components pvmd3 daemon Runs on each host and Executes processes Provides inter-host point of contact Provides authentication of tasks Provides fault tolerance Message routing and source / sink for messages libpvm programming library Contains the message passing routines and is linked to each application component application components User's programs, containing message passing calls, which are executed as PVM tasks

24
PVM terminology Host A physical machine such as a workstation Virtual Machine A combination of hosts running as a single concurrent resource Process A program, data, stack, etc such as a Unix process or node program Task A PVM process - the smallest unit of computation TID A unique identifier, within the virtual machine, which is associated with each task Message An ordered list of data to be sent between tasks

25
PVM message passing sending a message is a 3 step process Initialize a buffer using the pvm_initsend function Pack the data into the buffer using pvm_pack Send the contents of the buffer to another process using pvm_send or to a number of processes (multi-cast) using pvm_mcast Receiving a message is a 2 step process Call the blocking routine pvm_recv or the non- blocking routine pvm_nrecv Unpack the message using pvm_unpack
 using pvm_mcast Receiving a message is a 2 step process Call the blocking routine pvm_recv or the non- blocking routine pvm_nrecv Unpack the message using pvm_unpack")
26
Message buffers (1/2) PVM permits a user to manage multiple buffers but There is only one active send and one active receive buffer per process at any given moment the packing, sending, receiving and unpacking routines only affect active buffers the developer may switch between multiple buffers for message passing
 PVM permits a user to manage multiple buffers but There is only one active send and one active receive buffer per process at any given moment the packing, sending, receiving and unpacking routines only affect active buffers the developer may switch between multiple buffers for message passing")
27
Message buffers (2/2) In C PVM supports a number of different routines for packing data this corresponds to the different types of data to be packed Eg, pvm-pkint, pvm_pkdouble
 In C PVM supports a number of different routines for packing data this corresponds to the different types of data to be packed Eg, pvm-pkint, pvm_pkdouble")
28
PVM console (1/2) PVM console is analogous to a console on any multi-tasking computer. It is used to configure the virtual machine start pvm tasks (including the daemon) stop pvm tasks receives information and error messages
 stop pvm tasks receives information and error messages.")
29
PVM console (2/2) Starting the console with a Unix command : pvm The console may be started and stopped multiple times on any of the hosts on which PVM is running The console responds with the prompt : pvm> The console accepts commands from standard input
 Starting the console with a Unix command : pvm The console may be started and stopped multiple times on any of the hosts on which PVM is running The console responds with the prompt : pvm> The console accepts commands from standard input")
30
Configuration of PVM (1/2) Conf Add Delete Spawn Quit and halt
 Conf Add Delete Spawn Quit and halt")
31
Configuration of PVM (2/6) conf The configuration of the virtual machine may be listed using the conf command pvm> conf1 host, 1 data format HOST DTID ARCH SPEED navaho-atm 40000 SGI5 1000 This gives a configuration of 1 host called navaho-atm, its pvmd task id, architecture and relative speed rating
 conf The configuration of the virtual machine may be listed using the conf command pvm> conf1 host, 1 data format HOST DTID ARCH SPEED navaho-atm SGI This gives a configuration of 1 host called navaho-atm, its pvmd task id, architecture and relative speed rating")
32
Configuration of PVM (3/6) add Additional hosts may be added using the add command pvm> add sioux-atm mohican-atm2 successful HOST DTID sioux-atm 100000 mohican-atm 140000 pvm> conf 3 hosts, 1 data format HOST DTID ARCH SPEED navaho-atm 40000 SGI5 1000 sioux-atm 100000 SGI5 1000 mohican-atm 140000 SGI5 1000
 add Additional hosts may be added using the add command pvm> add sioux-atm mohican-atm2 successful HOST DTID sioux-atm mohican-atm pvm> conf 3 hosts, 1 data format HOST DTID ARCH SPEED navaho-atm SGI sioux-atm SGI mohican-atm SGI5 1000")
33
Configuration of PVM (4/6) delete Hosts may be removed from the virtual machine using the delete command pvm> delete sioux-atm1 successful HOST STATUS sioux-atm deleted
 delete Hosts may be removed from the virtual machine using the delete command pvm> delete sioux-atm1 successful HOST STATUS sioux-atm deleted")
34
Configuration of PVM (5/6) spawn The spawn command may used to execute a program from the pvm console pvm> spawn -> program-name This will direct the output from the program to the screen
 spawn The spawn command may used to execute a program from the pvm console pvm> spawn -> program-name This will direct the output from the program to the screen")
35
Configuration of PVM (6/6) quit, halt To exit from the console session while leaving all daemons and jobs running use the quit command pvm> quit To kill all pvm processes including the console, and then shut down PVM pvm> halt
 quit, halt To exit from the console session while leaving all daemons and jobs running use the quit command pvm> quit To kill all pvm processes including the console, and then shut down PVM pvm> halt")
36
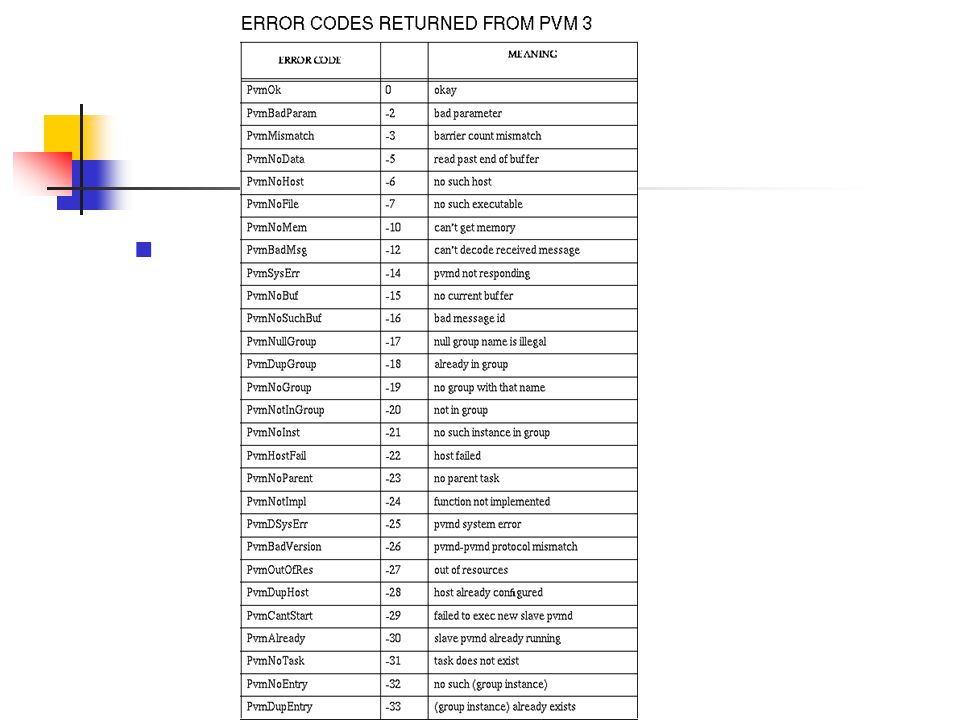
Error handling the completion status of a pvm routine may be checked, if the status >= 0 then the routine completed successfully, a negative value indicates that an error has occurred When an error occurs, a message is automatically printed that shows the task ID, function and error Error reports may be generated manually by calling pvm_perror

37
Debugging A task run by hand can be started under a serial debugger. Add PVMDEBUG flag to spawn The following steps should be followed when debugging Run program as a single task and debug as any other serial program Run the program on a single host to eliminate network errors and errors in message passing Run the program across a few hosts to locate deadlock and synchronization problems Use XPVM

38
Fault detection Pvmd will recover automatically, applications must perform their own error recovery A dead host will remain dead, but may be reconfigured later The pvmd to pvmd message passing system drives all fault detection Faults are triggered by retry time-out

39
Pvm_initsend Clears default send buffer and specifies message encoding CALL PVM_INITSEND (ENCODING, BUFID) encoding - specifies the next message's encoding scheme where the options are: PvmDataDefault ie XDR encoding used by default as PVM cannot know if a user is going to add a heterogeneous machine before this message PvmDataRaw ie no encoding used when it is known that the receiving machine understands the native format PvmDataInPlace ie specifies that data be left in place during packing bufid - integer returned containing the message buffer identifier. Values less than zero indicate an error.

40
Pvm_pack* Each data type is packed by a different function: int info = pvm_pkint(int *np, int item, int stride) Arguments are: a pointer to the first item nitem - number of items stride - stride/step through the data pvm_pkstr - packs a null terminated string (no nitem or stride) pkbyte, pkcplx, pkdcplx, pkdouble, pkfloat, pklong, pkshort, pkstr
 Arguments are: a pointer to the first item nitem - number of items stride - stride/step through the data pvm_pkstr - packs a null terminated string (no nitem or stride) pkbyte, pkcplx, pkdcplx, pkdouble, pkfloat, pklong, pkshort, pkstr")
41
Pvm_pack* Can be called multiple times in any combination C structures must be packed by element Complexity of packed message is unlimited Unpacking should occur in the same order (and size) as packing (not strictly necessary but good programming practice) Similar functions exist for unpacking
 as packing (not strictly necessary but good programming practice) Similar functions exist for unpacking")
42
Pvm_send Sends the data in the active message buffer Info = Pvm_Send(Tid, MsTag, Info) tid - integer task identifier of destination process msgtag - integer message tag supplied by the user, should be >= 0 info - integer status code returned by the routine, values less than zero indicate an error.
 tid - integer task identifier of destination process msgtag - integer message tag supplied by the user, should be >= 0 info - integer status code returned by the routine, values less than zero indicate an error.")
43
Pvm_recv Receives a message : blocking operation BUFID = PVM_RECV(TID, MSGTAG) tid - integer identifier of sending process supplied by the user, a -1 in this argument matches any tid ie. a wildcard. msgtag - integer message tag supplied by the user, should be >= 0, allows the user's program to distinguish between different kinds of messages. A -1 in this argument matches any msgtag ie. a wildcard. bufid - integer returns the value of the new active receive buffer identifier. Values less than zero indicate an error. Eg. BUFID = PVMFRECV(-1, 4)
.")
44
Pvm_bufinfo Returns information about the message in the nominated buffer. Useful when the message was received with wildcards for TID and msgtag Info = Pvm_BufInfo (BufId, Bytes,MsTag, Tid) BUFID - integer buffer id returned by pvmfrecv BYTES - length of the last message MSGTAG - integer message tag TID - TID of sending process INFO - return status
 BUFID - integer buffer id returned by pvmfrecv BYTES - length of the last message MSGTAG - integer message tag TID - TID of sending process INFO - return status.")
45
Pvm_spawn Starts new PVM processes Numt = Pvm_Spawn(Task, Flag, Where, Ntask, Tids) task - character string containing the executable file name of the PVM process to be started flag - integer specifying spawn options eg PvmTaskDefault which means PVM can choose any machine to start task where - character string specifying where to start the PVM process ntask - integer specifying the number of copies of the executable to start up tids - array of length at least ntask which contains the tids of the PVM process started by this pvm_spawn call numt - integer returning the actual number of tasks started, values less than 0 indicate a system error. A positive value less than ntask also indicates a partial failure Eg PVM_Spawn(`nodeprog', FLAG, `sioux-atm', 1, TIDS(3)))
)).")
46
Pvm_mcast Multicasts the data in the active message buffer to a set of tasks Info = PVM_MCAST(Ntask, Tds, Mstag) ntask - specifies the number of tasks to be sent a message tids - array of length at least ntask which contains the tids of the tasks to be sent the message msgtag - integer message tag supplied by the user, should be >= 0 info - integer status code returned by the routine, values less than zero indicate an error.
 ntask - specifies the number of tasks to be sent a message tids - array of length at least ntask which contains the tids of the tasks to be sent the message msgtag - integer message tag supplied by the user, should be >= 0 info - integer status code returned by the routine, values less than zero indicate an error.")
47
Compilation Gcc compiler + reference to pvm librairies Libpvm Libgpvm Usage of aimk : a specific Makefile

48
Execution The PVM console command spawn searches for the executable programs in 2 places: in the user's directory ~/pvm3/bin/$PVM_ARCH in $PVM_ROOT/bin/$PVM_ARCH Therefore compiled programs should be moved to ~/pvm3/bin/$PVM_ARCH

49
Dynamic process group Group functions are built on top of the core PVM routines libgpvm3.a must be linked with user programs using any of the group functions pvmd does not perform the group functions - they are performed by a group server which is automatically started when the first group function is invoked.

50
Dynamic process group Any PVM task can join or leave a group at any time without having to inform any other task in the affected groups. Tasks can broadcast messages to groups of which they are not a member Any PVM task may call any of the group functions except for – pvm_lvgroup(), pvm_barrier(), and pvm_reduce()
, pvm_barrier(), and pvm_reduce().")
51
Joining a group Pvm_Joingroup creates a group - Info = Pvm_JoinGroup (Group, Inum) puts the calling task in the group group is a character string containing the group name returns the instance number, inum, of the process in this group - ie a number from 0 to the number of group members -1
 puts the calling task in the group group is a character string containing the group name returns the instance number, inum, of the process in this group - ie a number from 0 to the number of group members -1")
52
Joining a group a task may join multiple groups on leaving and rejoining a group a task may receive a different instance number instance numbers are recycled and a task joining a group gets the lowest instance number available

53
Leaving a group Pvm_lvgroup() removes a task from a group but does not return until the task is confirmed to have left, a subsequent pvm_joingroup will assign the vacant instance number to the new task Info = Pvm_LvGroup (Group, Info)
 removes a task from a group but does not return until the task is confirmed to have left, a subsequent pvm_joingroup will assign the vacant instance number to the new task Info = Pvm_LvGroup (Group, Info)")
54
Group functions Pvm_gettid() returns the TID of the process with a given group name and instance number, it also allows two tasks to get each other's TID simply by joining a common group Pvm_getinst returns the instance number of TID in the specified group pvmfgetsize returns the number of members in the group
 returns the TID of the process with a given group name and instance number, it also allows two tasks to get each other s TID simply by joining a common group Pvm_getinst returns the instance number of TID in the specified group pvmfgetsize returns the number of members in the group")
55
Group functions Pvm_barrier() blocks a process until count number of processes have joined the group. pvmfbcast broadcasts to all the tasks in the specified group except itself ie all tasks that the group server thinks are in the group when the routine is called Pvm_reduce() performs a global arithmetic operation across the group, the result appears on root eg predefined functions that the user can place in func - PvmMax, PvmMin, PvmProduct, and PvmSum
 performs a global arithmetic operation across the group, the result appears on root eg predefined functions that the user can place in func - PvmMax, PvmMin, PvmProduct, and PvmSum.")
56
Dynamic PVM Configuration

57
Pvm_Config returns information about the present virtual machine configuration Info = Pvm_Config(Nhost, Narch, Dtid, Name,Arch, Speed) nhost - integer returning the number of hosts in the virtual machine narch - integer returning the number of different data formats being used. Note narch=1 indicates a homogeneous machine dtid - integer returning pvmd task ID for this host name - character string returning the name of this host arch - character string returning the name of host architecture speed - integer returning relative speed of this host ie default = 1000 info - integer status code returned by the routine, values less than 0 indicate an error

58
Dynamic PVM Configuration Adds a host to the virtual machine Info = Pvm_AddHost(Host) host - a character string containing the name of the machines to be added info - status code (values <1 indicate failure) eg info = Pvm_AddHost (`pawnee-atm')
 host - a character string containing the name of the machines to be added info - status code (values <1 indicate failure) eg info = Pvm_AddHost (`pawnee-atm )")
59
Dynamic PVM Configuration Pvm_Delhost deletes a host to the virtual machine Info = Pvm_Delhost (Host) host - a character string containing the name of the machines to be deleted info - status code where a value <1 indicates a failure
 host - a character string containing the name of the machines to be deleted info - status code where a value <1 indicates a failure")
60
Dynamic PVM Configuration Request notification of PVM event Info = PVM_Notify (What, Mstag, Count,Tids) what - integer identifier of event should trigger the notification eg PvmTaskExit - notify if tasks exits PvmHostDelete - notify if host is deleted PvmHostAdd - notify if host is added msgtag - message tag to be used in notification count - length of tids array for PvmTaskExit and PvmHostDelete tids - integer array of length the number of tasks to be notified - should be empty with a PvmAddHost option info - status code where a value <0 indicates a failure
 what - integer identifier of event should trigger the notification eg PvmTaskExit - notify if tasks exits PvmHostDelete - notify if host is deleted PvmHostAdd - notify if host is added msgtag - message tag to be used in notification count - length of tids array for PvmTaskExit and PvmHostDelete tids - integer array of length the number of tasks to be notified - should be empty with a PvmAddHost option info - status code where a value <0 indicates a failure")
61
Dynamic PVM Configuration When using Pvm_Notify, calling task(s) are responsible for receiving the message with the specified message tag and taking the appropriate action
 are responsible for receiving the message with the specified message tag and taking the appropriate action")
62
Pvm_Kill Terminates a specified PVM process Info = Pvm_KILL(TID) tid - integer task identifier of the PVM process to be killed ie not yourself info - integer status code returned by the routine, values less than zero indicate an error Pvm_exit() is used to kill yourself Error conditions returned by pvm_kill are PvmBadParam - giving an invalid tid value PvmSysErr - pvmd not responding
 tid - integer task identifier of the PVM process to be killed ie not yourself info - integer status code returned by the routine, values less than zero indicate an error Pvm_exit() is used to kill yourself Error conditions returned by pvm_kill are PvmBadParam - giving an invalid tid value PvmSysErr - pvmd not responding")
63
Error handling All PVM routines return an error condition if they detect an error during execution PVM prints error conditions detected Pvm_setopt() turns automatic reporting off Diagnostic prints can be viewed using PVM console redirection or Calling pvm_catchout() - this causes the standard output of all subsequently spawned tasks to appear on the standard output of the spawner
 turns automatic reporting off Diagnostic prints can be viewed using PVM console redirection or Calling pvm_catchout() - this causes the standard output of all subsequently spawned tasks to appear on the standard output of the spawner")
65
A brief look into the entrails of PVM

66
How PVM works ? Design considerations Components Messages PVM Daemon Libpvm Protocols Routing Task Environment Resource Limitations

67
Design considerations Portable - avoid use of features (operating system and language) which are hard to replace if not available. Therefore generic port is as simple as possible but can be optimised Sockets used for interprocess communication Connection within a virtual machine is always possible via TCP or UDP protocols Mutiprocessor machines which don't support sockets on the nodes have front-end processors which do

68
TID TID consists of 4 fields and fits into largest integer data type (32 bits) S, G and H have global meaning H - host number relative to virtual machine (2**12 – 1 machines in a virtual machine max)- S - address pvmds L - local task TIDs per pvmd (may accomodate 2**18 – 1 tasks) G - GIDs used in multicasting
 S, G and H have global meaning H - host number relative to virtual machine (2**12 – 1 machines in a virtual machine max)- S - address pvmds L - local task TIDs per pvmd (may accomodate 2**18 – 1 tasks) G - GIDs used in multicasting")
69
TID Tasks assigned TIDs by local pvmds without host-to-host communication Message routing by hierarchical naming Functions may return a mixed vector of error codes and legal TIDs TIDs should be opaque to applications - never attempt to predict TIDs (use groups or implement a name server)
")
70
Architecture classes Architecture name is assigned to each machine implementation Architecture name used to locate executables (and pvm libraries) List of architecture names may (will) expand Machines with incompatible executables may have the same data representation Architecture names are mapped to data encoding numbers which are used to determine when encoding is required
 List of architecture names may (will) expand Machines with incompatible executables may have the same data representation Architecture names are mapped to data encoding numbers which are used to determine when encoding is required")
71
pvmd pvmds are owned by users and do not interact with those of other users pvmd - message router and controller pvmd provides authentication, process control and fault detection pvmds continue running after an application crashes to help with debugging

72
pvmd First pvmd to start is designated as the master which then starts the other pvmds which are designated as slaves All pvmds are considered equal except: Reconfiguration requests are forwarded from slave to master Only the master can forcibly delete hosts

73
Messages and buffers pvmd and libpvm manage message buffers - potentially a large dynamic amount of data Data is stored in data buffers and accessed via pointers which are passed arround - eg. a multicast message is not replicated only the pointers A refcount is also passed with the pointer and pvm routines use this to decide when to free the data buffer Messages are composed without a maximum length. The pack functions allocate memory blocks for buffers and frag descriptors to chain the databufs together A frag desciptor struct frag holds: a pointer to a block of data fr_dat the length of the block fr_len a pointer to the databuf fr_buf and its total length fr_max (to prepend or append data) link pointers for chaining a list refcount - frag is deleted when refcount = 0 refcount of frag at head of list applies to list and list is deleted when refcount = 0
 link pointers for chaining a list refcount - frag is deleted when refcount = 0 refcount of frag at head of list applies to list and list is deleted when refcount = 0.")
74
Host table Describes the configuration of the virtual machine Various host tables exist - constructed from host descriptors List the name, address and communication state of each host Issued by the master pvmd and kept synchronised across the pvmds Each pvmd can autonomously delete hosts which become unreachable Hosts are added in a 3 phase commit operation to ensure global availability As the configuration changes host descriptors are propagated throught the virtual machine Host tables are used to manipulate the set of hosts; eg. select a machine when spawning a process Hostfile is parsed and a host table constructed

76
PVMd pvmd configures itself as master or slave Creates and binds sockets Opens error log file /tmp/pvml.uid Master pvmd reads host file (if specified) Slave pvmds get their setup configuration from the master pvmd Pvmds enter a loop in a function called work() which: probes all sources of input receives and routes packets assembles messages to the pvmd and passes these to the appropriate entry points
 Slave pvmds get their setup configuration from the master pvmd Pvmds enter a loop in a function called work() which: probes all sources of input receives and routes packets assembles messages to the pvmd and passes these to the appropriate entry points")
77
Wait contexts pvmd is not truly multi-threaded but performs operations concurrently Wait contexts (waitc) used to store current state when the context must be changed Where more than one phase of waiting is necessary waitcs are linked in a list Waitcs are sequentially numbered and this id is sent in the message header of replies - once reply is acknowledged waitc is discarded Waitcs associated with exiting(failing) hosts and tasks are retained until outstanding replies are cleared
 used to store current state when the context must be changed Where more than one phase of waiting is necessary waitcs are linked in a list Waitcs are sequentially numbered and this id is sent in the message header of replies - once reply is acknowledged waitc is discarded Waitcs associated with exiting(failing) hosts and tasks are retained until outstanding replies are cleared")
78
Fault detection and recovery pvmd can recover from the loss of any foreign pvmd - except the master If a slave loses contact with the master it shuts down Virtual machine retains its integrity - does not fragment into partial virtual machines Fault tolerance is limited as the master must never crash - run master on most secure system Master cannot hand over to another pvmd and exit PVM 2 - failure of any pvmd crashed the virtual machine

79
PVM_Send in action

81
Message routing Messages are routed by destination address Messages to other pvmds are linked to packet descriptors and attached to send queue pvmd often sends loop-back style messages to itself (no packet descriptor) Messages to a pvmd are reassembled from packets in message reassembly buffers - one buffer for each local task and remote pvmd Packet routing From local tasks: pvmd reads header, creates a buffer and then chains the descriptor on to the queue for its destination Multicast: descriptor is replicated and one copy placed on each relevant queue, when the last message is send the buffer is freed Refragmentation: messages are built to avoid fragmentation - in some cases a pvmd needs to fragment a packet for retransmission
 Messages to a pvmd are reassembled from packets in message reassembly buffers - one buffer for each local task and remote pvmd Packet routing From local tasks: pvmd reads header, creates a buffer and then chains the descriptor on to the queue for its destination Multicast: descriptor is replicated and one copy placed on each relevant queue, when the last message is send the buffer is freed Refragmentation: messages are built to avoid fragmentation - in some cases a pvmd needs to fragment a packet for retransmission")
82
Xpvm A graphical and very useful tool It provides a graphical interface to the pvm console commands and information, along with several animated views to monitor the execution of PVM programs. These views provide information about the interactions among tasks in a parallel PVM program, to assist in debugging and performance tuning.

83
xpvm

85
Xpvm and network view

86
CPU Usage

87
XPVM Debugging Features

88
Message flow

89
Conclusions Simple and rich environment Fun to use and discover distributed systems A first step towards MPI and more elaborate middlewares

90
To know more http://www.csm.ornl.gov/pvm/pvm_ho me.html http://www.csm.ornl.gov/pvm/pvm_ho me.html http://www.netlib.org/pvm3/book/pvm- book.html (MitPress) http://www.netlib.org/pvm3/book/pvm- book.html
 book.html")
Similar presentations













>")





 is a package of libraries and runtime daemons that enables building parallel apps easily and efficiently.>")


