Download presentation
Presentation is loading. Please wait.

1
Evaluation of Five GIS based Interpolation Techniques for Estimating the Radon Concentration for Unmeasured Zip Codes in the State of Ohio By Suman Maroju Department of Civil Engineering The University of Toledo Advisor: Ashok Kumar PhD

2
Introduction Radon is a naturally occurring radioactive gas produced by the breakdown of Uranium in soil, rock and water. Radon is a naturally occurring radioactive gas produced by the breakdown of Uranium in soil, rock and water. Radon is the second most common cause of lung cancer after cigarette smoking, accounting for 15,000 to 22,000 cancer deaths per year in the US alone according to the National Cancer Institute (USA) Radon is the second most common cause of lung cancer after cigarette smoking, accounting for 15,000 to 22,000 cancer deaths per year in the US alone according to the National Cancer Institute (USA) Radon gas is believed to cause about 14% of lung cancer deaths (1000+ deaths) in Ohio annually. 45% of homes in Ohio exceed the USEPA action level. 62.5% of schools in Ohio have at least one room in excess of the USEPA action level
 Radon is the second most common cause of lung cancer after cigarette smoking, accounting for 15,000 to 22,000 cancer deaths per year in the US alone according to the National Cancer Institute (USA) Radon gas is believed to cause about 14% of lung cancer deaths (1000+ deaths) in Ohio annually. 45% of homes in Ohio exceed the USEPA action level. 62.5% of schools in Ohio have at least one room in excess of the USEPA action level.")
3
Data Collection Data collected from various county health departments, commercial testing services and university researchers. Data collected from various county health departments, commercial testing services and university researchers. Original database – Kumar et al. (1990) Original database – Kumar et al. (1990) 1996 and 1997 – 82,000 1996 and 1997 – 82,000 New data being constantly added New data being constantly added Total of 130,826 observations used in this study Total of 130,826 observations used in this study
 Original database – Kumar et al. (1990) 1996 and 1997 – 82, and 1997 – 82,000 New data being constantly added New data being constantly added Total of 130,826 observations used in this study Total of 130,826 observations used in this study.")
5
Objectives To evaluate the best interpolation technique for the radon data set. To evaluate the best interpolation technique for the radon data set. To perform this interpolation technique on the whole radon data set, obtain prediction map and estimate concentrations for unmeasured zip codes. To perform this interpolation technique on the whole radon data set, obtain prediction map and estimate concentrations for unmeasured zip codes. To present the impact of the results obtained from this study. To present the impact of the results obtained from this study.

6
ArcGIS Geostatistical Analyst Geostatistical Analyst provides a wide variety of tools for spatial data exploration, identification of data anomalies, evaluation of error in prediction surface models, statistical estimation and optimal surface creation.

7
Exploratory Spatial Data Analysis (ESDA) Tool The ESDA tools are designed to explore the distribution of data, look for global trends in the data, examining spatial autocorrelation and understand the correlation between multiple data sets. The ESDA tools are designed to explore the distribution of data, look for global trends in the data, examining spatial autocorrelation and understand the correlation between multiple data sets. Tools include Histogram, Normal QQ Plot, Trend Analysis, Semivariogram/Covariance Cloud. Tools include Histogram, Normal QQ Plot, Trend Analysis, Semivariogram/Covariance Cloud.

8
Histogram The Histogram tool in ESDA provides a univariate (one- variable) description of the data. The Histogram tool in ESDA provides a univariate (one- variable) description of the data. The plots shows the frequency distribution for the radon data set. The plots shows the frequency distribution for the radon data set.
 description of the data. The plots shows the frequency distribution for the radon data set. The plots shows the frequency distribution for the radon data set..")
9
Normal QQ Plot The QQ Plot is to compare the distribution of the data to a standard normal distribution.

10
Trend Analysis The Trend Analysis tool can help identify global trends in the input data set. The Trend Analysis tool can help identify global trends in the input data set. North-South Trend line East-West trend line North-South axis East-West axis

11
Semivariogram/Covariance Cloud Semivariogram points representing pairs of locations

12
Approach The geometric mean of radon concentration values is inputted for each zip code and zero values are assigned to the zip codes that are not measured. The geometric mean of radon concentration values is inputted for each zip code and zero values are assigned to the zip codes that are not measured. The polygon features of Ohio zip codes shape file is converted into point features to input as point data source in the interpolation techniques. The polygon features of Ohio zip codes shape file is converted into point features to input as point data source in the interpolation techniques. The point featured shape file is then divided into two shape files; one having 1066 zip codes with radon concentration data and the other contains 796 zip codes with no measured radon concentration data. The point featured shape file is then divided into two shape files; one having 1066 zip codes with radon concentration data and the other contains 796 zip codes with no measured radon concentration data.

13
Approach The first step is to evaluate the best interpolation technique. The first step is to evaluate the best interpolation technique. The point featured shape file is divided into 80% training data points and 20% test data points. Sensitivity analysis for division of data set The point featured shape file is divided into 80% training data points and 20% test data points. Sensitivity analysis for division of data set Sensitivity analysis for division of data set Sensitivity analysis for division of data set Then the different interpolation techniques are executed using the training data points which creates a layer of spatial variation and the predictions are evaluated for test data points. Then the different interpolation techniques are executed using the training data points which creates a layer of spatial variation and the predictions are evaluated for test data points.

14
Approach Second part Second part –Best interpolation technique is chosen based on values of statistical parameters. statistical parametersstatistical parameters –Modeling is done for the whole radon data set, which creates a surface of spatial variation and the predictions for unmeasured zip codes (where no data is collected) is evaluated from the surface created.
 is evaluated from the surface created..")
15
Interpolation methods Five Interpolation Techniques Five Interpolation Techniques Ordinary Kriging Ordinary Kriging Inverse Distance Weighting (IDW) Inverse Distance Weighting (IDW) Radial Basis Function (RBF) Radial Basis Function (RBF) Local Polynomial Interpolation Local Polynomial Interpolation Global Polynomial Interpolation Global Polynomial Interpolation
 Inverse Distance Weighting (IDW) Radial Basis Function (RBF) Radial Basis Function (RBF) Local Polynomial Interpolation Local Polynomial Interpolation Global Polynomial Interpolation Global Polynomial Interpolation")
16
Ordinary Kriging Kriging is divided into two distinct tasks: Kriging is divided into two distinct tasks: Quantifying the spatial structure of the data (known as variography) and producing a prediction i.e., fitting a spatial dependence model to the data. Quantifying the spatial structure of the data (known as variography) and producing a prediction i.e., fitting a spatial dependence model to the data. Make a prediction for the unknown value of a specific location. Achieved by using the fitted model from the variography (spatial data configuration) and values of the measured sample points around the prediction location. Make a prediction for the unknown value of a specific location. Achieved by using the fitted model from the variography (spatial data configuration) and values of the measured sample points around the prediction location.
 and producing a prediction i.e., fitting a spatial dependence model to the data. Make a prediction for the unknown value of a specific location. Achieved by using the fitted model from the variography (spatial data configuration) and values of the measured sample points around the prediction location. Make a prediction for the unknown value of a specific location. Achieved by using the fitted model from the variography (spatial data configuration) and values of the measured sample points around the prediction location..")
17
Ordinary Kriging The equation used in Ordinary Kriging is: Z* (u) is the Ordinary Kriging estimate at spatial location u, Z* (u) is the Ordinary Kriging estimate at spatial location u, n (u) is the number of the data used at the known locations given a neighborhood n (u) is the number of the data used at the known locations given a neighborhood Z (u α ) are the n measured data at locations u α located close to u Z (u α ) are the n measured data at locations u α located close to u m= mean of distribution m= mean of distribution Z*(u) = m
 is the Ordinary Kriging estimate at spatial location u, Z* (u) is the Ordinary Kriging estimate at spatial location u, n (u) is the number of the data used at the known locations given a neighborhood n (u) is the number of the data used at the known locations given a neighborhood Z (u α ) are the n measured data at locations u α located close to u Z (u α ) are the n measured data at locations u α located close to u m= mean of distribution m= mean of distribution Z*(u) = m")
18
Ordinary Kriging λ α (u)= weights for location u α computed from the spatial covariance matrix based on the spatial continuity (variogram) model, which is given by: n is the number of data pairs separated by distance h z(u i ) and z(u i +h) are the data values at locations separated by distance h γ (h) =
= weights for location u α computed from the spatial covariance matrix based on the spatial continuity (variogram) model, which is given by: n is the number of data pairs separated by distance h z(u i ) and z(u i +h) are the data values at locations separated by distance h γ (h) =")
19
Ordinary Kriging

20
There are three primary parameters that describe the autocorrelation of radon concentrations. These are range, nugget and sill. – –The range is where the best-fit line starts to level off, (46.55). Within the range, all data are correlated. – –The maximum semivariogram value is sill parameter (0.2869) – –Nugget is data variation due to measurement errors (0.20487). Range Sill Nugget Spherical model
. Within the range, all data are correlated. – –The maximum semivariogram value is sill parameter (0.2869) – –Nugget is data variation due to measurement errors ( ). Range Sill Nugget Spherical model.")
21
Ordinary Kriging Ordinary Kriging

23
Inverse Distance Weighting (IDW) IDW interpolation assumes that things close to one another are more alike than those farther apart. IDW interpolation assumes that things close to one another are more alike than those farther apart. To predict a value for any unmeasured location, IDW will use the measured values surrounding the prediction location. To predict a value for any unmeasured location, IDW will use the measured values surrounding the prediction location. Measured values closest to the prediction location will have more influence on the predicted value than those farther away. Measured values closest to the prediction location will have more influence on the predicted value than those farther away. IDW assumes that each measured point has a local influence that diminishes with distance. IDW assumes that each measured point has a local influence that diminishes with distance.

24
Inverse Distance Weighting A simple IDW weighting function, as defined by Shepard, is : A simple IDW weighting function, as defined by Shepard, is : Where w(d) is the weighting factor applied to a known value Where w(d) is the weighting factor applied to a known value d is the distance between known and unknown values d is the distance between known and unknown values p is the power parameter (most common value is 2). p is the power parameter (most common value is 2). A general form of interpolating a value using IDW is: A general form of interpolating a value using IDW is:
. A general form of interpolating a value using IDW is: A general form of interpolating a value using IDW is:.")
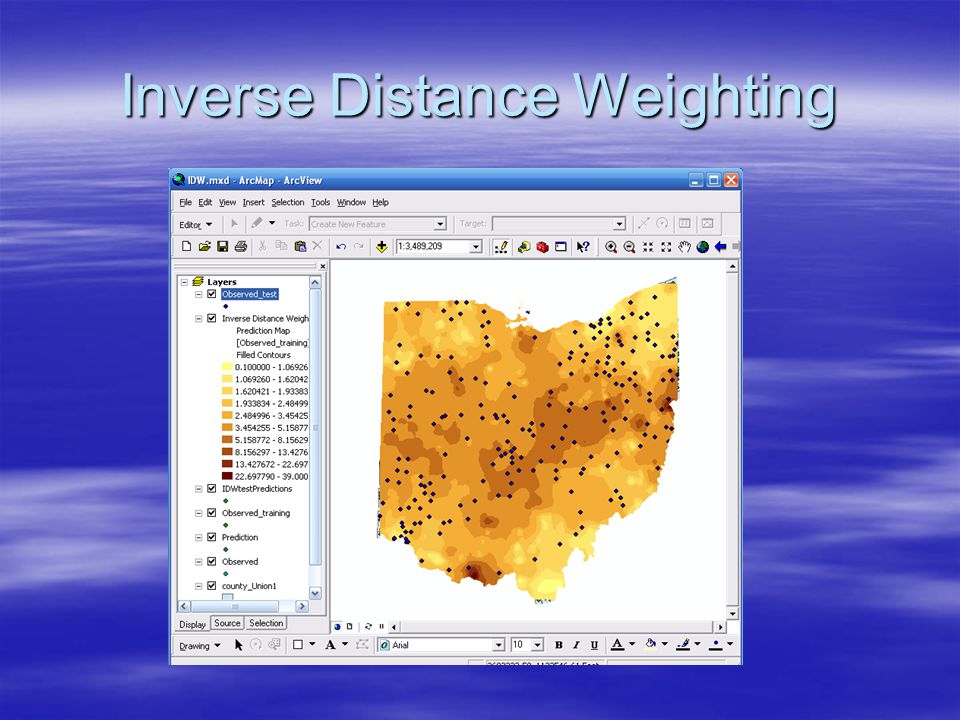
25
Inverse Distance Weighting

27
Radial Basis Function (RBF) RBF is an exact interpolation technique in the sense that, the surface created must go through each measured sample value. RBF is an exact interpolation technique in the sense that, the surface created must go through each measured sample value. It is similar to IDW, except that it predicts values above the maximum and below the minimum measured values. It is similar to IDW, except that it predicts values above the maximum and below the minimum measured values.

28
Radial Basis Function (RBF)
")
30
Global Polynomial Interpolation Global polynomial interpolation technique fits a plane through the measured data points. A plane is typically a polynomial. Global polynomial interpolation technique fits a plane through the measured data points. A plane is typically a polynomial.

31
Global Polynomial Interpolation

32
Local polynomial Interpolation While Global Polynomial interpolation fits a polynomial to the entire surface, Local Polynomial interpolation fits many polynomials, each within specified overlapping neighborhoods. While Global Polynomial interpolation fits a polynomial to the entire surface, Local Polynomial interpolation fits many polynomials, each within specified overlapping neighborhoods.

33
Local polynomial Interpolation

34
Evaluation Criteria Several statistical indicators (Root Mean Square Error (RMSE), Mean Error (ME), Mean Absolute Error (MAE) and Mean Square Error (MSE)) are computed on observed and predicted radon concentrations. Several statistical indicators (Root Mean Square Error (RMSE), Mean Error (ME), Mean Absolute Error (MAE) and Mean Square Error (MSE)) are computed on observed and predicted radon concentrations. Confidence limits on the statistics for Normalized Mean Square Error (NMSE), Fractional Bias (FB), and Coefficient of Correlation (r) are calculated using Bootstrap application to identify the most suitable interpolation technique. Confidence limits on the statistics for Normalized Mean Square Error (NMSE), Fractional Bias (FB), and Coefficient of Correlation (r) are calculated using Bootstrap application to identify the most suitable interpolation technique.
, Mean Error (ME), Mean Absolute Error (MAE) and Mean Square Error (MSE)) are computed on observed and predicted radon concentrations. Confidence limits on the statistics for Normalized Mean Square Error (NMSE), Fractional Bias (FB), and Coefficient of Correlation (r) are calculated using Bootstrap application to identify the most suitable interpolation technique. Confidence limits on the statistics for Normalized Mean Square Error (NMSE), Fractional Bias (FB), and Coefficient of Correlation (r) are calculated using Bootstrap application to identify the most suitable interpolation technique..")
35
Results Measured Vs Predicted Radon Conc. Values for the test datasets

36
Results Measured Vs Predicted Radon Conc. Values for test datasets

37
Results ME, MAE, MSE and RMSE values of different interpolation techniques for geometric mean of radon concentration test predictions Ordinary Kriging IDWRBF Global Polynomial Interpolation Local Polynomial Interpolation ME0.090.170.190.10.14 MAE1.331.451.441.461.4 MSE4.995.775.575.155.21 RMSE Value 2.232.42.362.272.28

38
Results NMSE, FB and Corr. Values from Bootstrap Method Ordinary Kriging IDWRBF Global Polynomial Interpolation Local Polynomial Interpolation NMSE0.410.460.440.42 FB-0.026-0.047-0.055-0.027-0.041 Corr. (r)0.50.420.450.480.47
")
39
Results Summary of Robust and Seductive 95% Confidence Limits Analyses on Each Technique Ordinary Kriging IDWRBF Global Polynomial Local Polynomial NMSE XXXXX FB Corr. (r) XXXXX Note: X indicates significantly different from zero. Blank indicates not significantly different from zero.
 XXXXX Note: X indicates significantly different from zero. Blank indicates not significantly different from zero..")
40
Results Summary of Robust and Seductive 95% Confidence Limits Analyses among Each Technique Interpolation Technique Among Techniques NMSEFBCorr.(r) YesNoYesNoYesNo Ordinary Kriging- IDW Ordinary Kriging –RBF X Ordinary Kriging - GPI Ordinary Kriging - LPI IDW- RBF IDW- GPI IDW- LPI RBF- GPI RBF- LPI GPI – LPI Note: Yes- Indicates significantly different from zero. No- Indicates not significantly different from zero

41
Comparison of the behavior of the prediction maps with the soil uranium concentrations map

43
Results

44
Results Predicted Geometric Mean of Radon Concentrations Using Ordinary Kriging technique for Lucas County ZIP CODECOUNTYPREDICTED GM 43402LUCAS1.88 43445LUCAS2.96 43449LUCAS2.89 43460LUCAS2.35 43522LUCAS1.80 43551LUCAS2.28 43558LUCAS1.92

45
Conclusion Prediction maps were created using the training data set for all five interpolation techniques and projected values were estimated for the test data set. Prediction maps were created using the training data set for all five interpolation techniques and projected values were estimated for the test data set. Statistical parameters (error values) were evaluated and the prediction maps generated from these techniques were compared to the soil uranium concentration map. Statistical parameters (error values) were evaluated and the prediction maps generated from these techniques were compared to the soil uranium concentration map. It was inferred that any of the four (Ordinary Kriging, IDW, RBF and Local Polynomial) interpolation techniques can be used for predicting the radon concentrations for unmeasured zip codes. It was inferred that any of the four (Ordinary Kriging, IDW, RBF and Local Polynomial) interpolation techniques can be used for predicting the radon concentrations for unmeasured zip codes. Ordinary Kriging technique was chosen and the geometric means of radon concentrations were evaluated for unmeasured zip codes. Ordinary Kriging technique was chosen and the geometric means of radon concentrations were evaluated for unmeasured zip codes.
 were evaluated and the prediction maps generated from these techniques were compared to the soil uranium concentration map. Statistical parameters (error values) were evaluated and the prediction maps generated from these techniques were compared to the soil uranium concentration map. It was inferred that any of the four (Ordinary Kriging, IDW, RBF and Local Polynomial) interpolation techniques can be used for predicting the radon concentrations for unmeasured zip codes. It was inferred that any of the four (Ordinary Kriging, IDW, RBF and Local Polynomial) interpolation techniques can be used for predicting the radon concentrations for unmeasured zip codes. Ordinary Kriging technique was chosen and the geometric means of radon concentrations were evaluated for unmeasured zip codes. Ordinary Kriging technique was chosen and the geometric means of radon concentrations were evaluated for unmeasured zip codes..")
46
Conclusion From the data sets available prior to study, number of zip codes having geometric mean of radon concentration over 4.0 pCi/l is 390. From the data sets available prior to study, number of zip codes having geometric mean of radon concentration over 4.0 pCi/l is 390. After using the Ordinary Kriging interpolation technique to calculate the predictions for unmeasured zip codes, number of zip codes having radon concentration over 4.0 pCi/l is 688. After using the Ordinary Kriging interpolation technique to calculate the predictions for unmeasured zip codes, number of zip codes having radon concentration over 4.0 pCi/l is 688. The predicted radon concentrations for unmeasured zip codes were found to be below 8 pCi/l. The predicted radon concentrations for unmeasured zip codes were found to be below 8 pCi/l. Therefore, for the cases where the geometric mean of radon concentration exceeds 8 pCi/l and 20 pCi/l, the number of zip codes from existing data is equal to that obtained by interpolation technique for unmeasured zip codes (85 and 9 for the respective cases). Therefore, for the cases where the geometric mean of radon concentration exceeds 8 pCi/l and 20 pCi/l, the number of zip codes from existing data is equal to that obtained by interpolation technique for unmeasured zip codes (85 and 9 for the respective cases).
. Therefore, for the cases where the geometric mean of radon concentration exceeds 8 pCi/l and 20 pCi/l, the number of zip codes from existing data is equal to that obtained by interpolation technique for unmeasured zip codes (85 and 9 for the respective cases)..")
47
Thank you

48
Sensitivity Analysis for division of data set Interpolation Technique 80-20 (%)70-30 (%)60-40 (%) RMSE Ordinary Kriging2.233.332.86 IDW2.43.312.29 RBF2.363.312.93 Global Polynomial2.273.573.06 Local Polynomial2.283.32.91
70-30 (%)60-40 (%) RMSE Ordinary Kriging IDW RBF Global Polynomial Local Polynomial")
Similar presentations
















 Coordinator California Department of Fish and Game.>")






 data into Raster based PMP data using different interpolation.>")