Download presentation
Presentation is loading. Please wait.

1
SC968: Panel Data Methods for Sociologists
Introduction to survival/event history models

2
Types of outcome Continuous OLS Linear regression
Binary Binary regression Logistic or probit regression Time to event data Survival or event history analysis

3
Examples of time to event data
Time to death Time to incidence of disease Unemployed - time till find job Time to birth of first child Smokers – time till quit smoking

4
Time to event data Set of a finite, discrete states Units (individuals, firms, households etc.) –in one state Transitions between states Time until a transition takes place

5
4 key concepts for survival analysis
States Events Risk period Duration/ time

6
States States are categories of the outcome variable of interest
Each person occupies exactly one state at any moment in time Examples alive, dead single, married, divorced, widowed never smoker, smoker, ex-smoker Set of possible states called the state space

7
Events A transition from one state to another
From an origin state to a destination state Possible events depend on the state space Examples From smoker to ex-smoker From married to widowed Not all transitions can be events E.g. from smoker to never smoker

8
Risk period 2 states: A & B Event: transition from A B
To be able to undergo this transition, one must be in state A (if in state B already cannot transition) Not all individuals will be in state A at any given time Example can only experience divorce if married The period of time that someone is at risk of a particular event is called the risk period All subjects at risk of an event at a point in time called the risk set
 Not all individuals will be in state A at any given time. Example. can only experience divorce if married. The period of time that someone is at risk of a particular event is called the risk period. All subjects at risk of an event at a point in time called the risk set.")
9
Time Various meanings... Calendar time
...but onset of risk usually not simultaneous for all units Ex: by age 40, some individuals will have smoked for 20+ years, other for 1 year Duration=time since onset of risk ...intensity may not be the same EX: one smoker may smoke 5 cigarettes a day, another 20 1 unit of time -same for all individuals

10
Duration Event history analysis is to do with the analysis of the duration of a nonoccurrence of an event or the length of time during the risk period Examples Duration of marriage Length of life In practice we model the probability of a transition conditional on being in the risk set

11
Example data ID Entry date Died End date 1 01/01/1991 01/01/2008
1 01/01/ /01/2008 01/01/ /01/ /01/2000 3 01/01/ /01/2005 4 01/01/ /07/ /07/2004

12
Calendar time Study follow-up ended

13
Censoring Ideally: observe individual since the onset of risk until event has occurred ...very demanding in terms of data collection (ex: risk of death starts when one is born) Usually– incomplete data censoring An observation is censored if it has incomplete information Types of censoring Right censoring Left censoring
 Usually– incomplete data censoring. An observation is censored if it has incomplete information. Types of censoring. Right censoring. Left censoring.")
14
Censoring Right censoring: the person did not experience the event during the time that they were studied Common reasons for right censoring the study ends the person drops-out of the study We do not know when the person experiences the event but we do know that it is later than a given time T Left censoring: the person became at risk before we started observing her We do not know when the person entered the risk set EHA cannot deal with We know when the person entered the risk set condition on the person having survived long enough to enter the study Censoring independent of survival processes!!

15
Study time in years censored event censored event

16
Why a special set of methods?
duration =continuous variable why not OLS? Censoring If excluding higher probability to throw out longer durations If treating as complete mis-measurement of duration Non normality of residuals Time varying co-variates Interested in the probability of a transition at any given time rather than in the length of complete spells Need to simultaneously take into account: Whether the event has taken place or not The length of the period at risk before the event ocurred

17
Survival function Length of time (duration) before an event occurs (length of ‘spell’-T) probability density function (pdf)- f(t) f(t)= lim Pr(t<=T<=t+Δt) = δF(t) δt Δt Δt cumulative density function (cdf)- F(t) F(t)= Pr( T<=t) =∫f(t) dt Survival function: S(t)=1-F(t)
= lim Pr(t<=T<=t+Δt) = δF(t) δt. Δt0 Δt. cumulative density function (cdf)- F(t) F(t)= Pr( T<=t) =∫f(t) dt. Survival function: S(t)=1-F(t)")
18
Hazard rate duration is continuous duration is discrete
h(t)= f(t)/ S(t) The exact definition & interpretation of h(t) differs: duration is continuous duration is discrete Conditional on having survived up to t, what is the probability of leaving between t and t+Δt It is a measure of risk intensity h(t) >=0 In principle h(t)= rate; not a probability There is a 1-1 relationship between h(t), f(t), F(t), S(t) EHA analysis: h(t)= g (t, Xs) g=parametric & semi-parametric specifications
= f(t)/ S(t) The exact definition & interpretation of h(t) differs: duration is continuous. duration is discrete. Conditional on having survived up to t, what is the probability of leaving between t and t+Δt. It is a measure of risk intensity. h(t) >=0. In principle h(t)= rate; not a probability. There is a 1-1 relationship between h(t), f(t), F(t), S(t) EHA analysis: h(t)= g (t, Xs) g=parametric & semi-parametric specifications.")
19
Data Survival or event history data characterised by 2 variables
Time or duration of risk period Failure (event) 1 if not survived or event observed 0 if censored or event not yet occurred Data structure different: Duration is discrete Duration is continuous Assume: 2 states; 1 transition; no repeated events
 1 if not survived or event observed. 0 if censored or event not yet occurred. Data structure different: Duration is discrete. Duration is continuous. Assume: 2 states; 1 transition; no repeated events.")
20
Data structure-Discrete time
ID Entry End date Event X at t0 X at t1 .... 1 01/01/1991 01/01/2008 01/01/2002 2 ID Date Duration (t) Event X 1 01/01/1991 01/01/1992 2 ... ..... .... 01/01/2002 11 01/01/2008 17
 Event. X /01/ /01/ /01/ /01/")
21
Data structure-Discrete time
The row is a an individual period An individual has as many rows as the number of periods he is observed to be at risk No longer at risk when Experienced event No longer under observation (censored) For each period (row)- explanatory variable X very easy to incorporate time varying co-variates Stata: reshape long
 For each period (row)- explanatory variable X very easy to incorporate time varying co-variates. Stata: reshape long.")
22
Data structure-continuous time
ID Entry Died End date Duration Event X /01/ /01/ /01/ /01/ /01/ /01/ /01/ /01/ /01/ /01/

23
Data structure-continuous time
The row is a person Indicator for observed events/ censored cases Calculate duration= exit date – entry date Exit date= Failure date Censoring date If time-varying covariates- Split the period an individual is under observation by the number of times time-varying Xs change If many Xs-change often- multiple rows

24
Worked example Random 20% sample from BHPS Waves 1 – 15
One record per person/wave Outcome: Duration of cohabitation Conditions on cohabiting in first wave Survival time: years from entry to the study in 1991 till year living without a partner

25
The data Duration = 6 years Event = 1 Ignore data after event = 1

26
The data (continued) Note missing waves before event
 Note missing waves before event")
27
Preparing the data Select records for respondents who
were cohabiting in 1991 Declare that you want to set the data to survival time Important to check that you have set data as intended

28
Checking the data setup
1 if observation is to be used and 0 otherwise time of entry time of exit 1 if event, 0 if censoring or event not yet occurred

29
Checking the data setup
How do we know when this person separated?

30
Trying again!

31
Checking the new data setup
Now censored instead of an event

32
Summarising time to event data
Individuals followed up for different lengths of time So can’t use prevalence rates (% people who have an event) Use rates instead that take account of person years at risk Incidence rate per year Death rate per 1000 person years
 Use rates instead that take account of person years at risk. Incidence rate per year. Death rate per 1000 person years.")
33
Summarising time to event data
Number of observations Person-years <25% of sample had event by 15 elapsed years Rate per year stvary-check whether a variable varies within individuals and over time

34
Descriptive analysis To recap….
pdf= probability that a spell has a length of exactly T f(t)= lim Pr(t<=T<=t+Δt) = δF(t) δt Δt Δt cdf=probability that a spell has a length<=T F(t)= Pr( T<=t) =∫f(t) dt Survival function S(t)=1-F(t)
= lim Pr(t<=T<=t+Δt) = δF(t) δt. Δt0 Δt. cdf=probability that a spell has a length<=T. F(t)= Pr( T<=t) =∫f(t) dt. Survival function. S(t)=1-F(t)")
35
Kaplan-Meier estimates of survival time
The Kaplan-Meier cumulative probability of an individual surviving to any time, t Analysis can be made by subgroup Nonparametric method First period: S1=1-d1/n exit rate After t periods: St=(1-d1/n1)*(1-d2/n2)*……*(1-dt/nt) Survival function estimated only at times where you observe exits!!! Last t that can be estimated highest non-censored time observed
*(1-d2/n2)*……*(1-dt/nt) Survival function estimated only at times where you observe exits!!! Last t that can be estimated highest non-censored time observed.")
36
Survival/ failure function
Describing the survival/ failure function

37
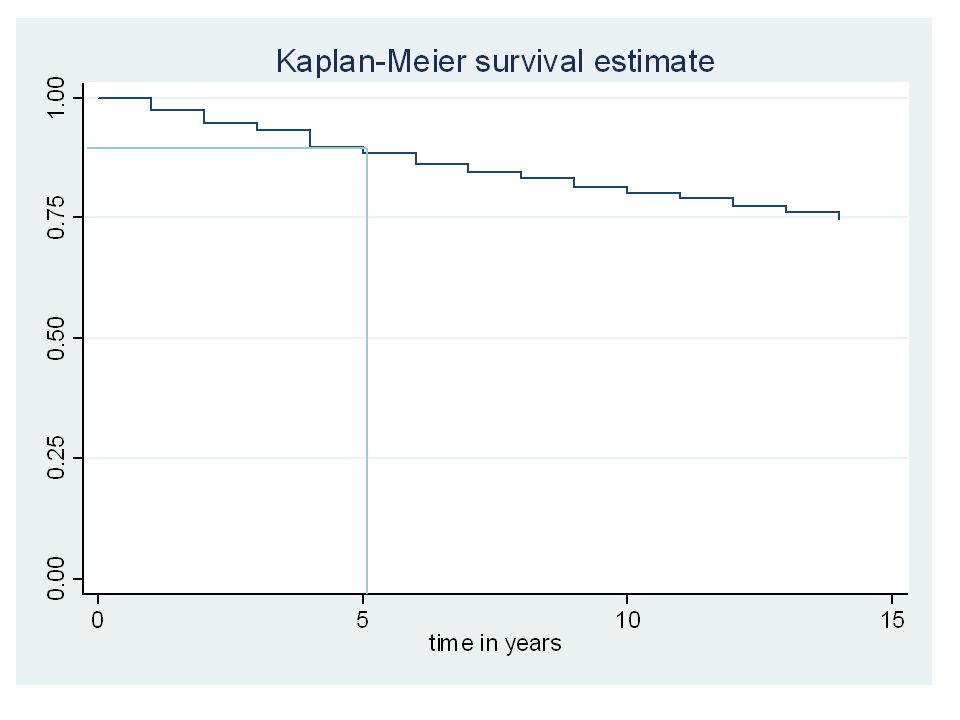
Kaplan-Meier graphs Can read off the estimated probability of surviving a relationship at any time point on the graph E.g. at 5 years 88% are still cohabiting The survival probability only changes when an event occurs graph not smooth but (irregular) stepwise sts graph, survival
 stepwise. sts graph, survival.")
41
Testing equality of survival curves among groups
The log-rank test A non –parametric test that assesses the null hypothesis that there are no differences in survival times between groups

42
Log-rank test example Significant difference between men and women

43
More elaborate models…
Modeling the hazard rate not survival time directly h(t)=transitioning at time t, having survived up to t Time: Continuous- parametric Exponential Weibull Log-logistic Continuous-semi-parametric Cox Discrete Logistic Complementary log-log
=transitioning at time t, having survived up to t. Time: Continuous- parametric. Exponential. Weibull. Log-logistic. Continuous-semi-parametric. Cox. Discrete. Logistic. Complementary log-log.")
44
Some hazard shapes Increasing Decreasing U-shaped Constant
Onset of Alzheimer's Decreasing Survival after surgery U-shaped Age specific mortality Constant Time till next arrives

45
Proportional-hazards (PH) models
h(t) is separable into h0(t) and the effects of Xs h0(t)=‘baseline’ hazard that depends on t but not on individual characteristics h(t)=h0(t)exp(βX) Absolute differences in X proportional differences in h(t) ~scaling of h0(t)
 is separable into h0(t) and the effects of Xs. h0(t)=‘baseline’ hazard that depends on t but not on individual characteristics. h(t)=h0(t)exp(βX) Absolute differences in X proportional differences in h(t) ~scaling of h0(t)")
46
The Cox regression model

47
Cox regression model Regression model for survival analysis
Can model time invariant and time varying explanatory variables Produces estimated hazard ratios (sometimes called rate ratios or risk ratios) Regression coefficients are on a log scale Exponentiate to get hazard ratio Similar to odds ratios from logistic models
 Regression coefficients are on a log scale. Exponentiate to get hazard ratio. Similar to odds ratios from logistic models.")
48
Cox regression equation (i)
is the hazard function for individual i is the baseline hazard function and can take any form It is estimated from the data (non parametric) are the covariates are the regression coefficients estimated from the data PH assumption needed Estimate βs without estimating h0(t) semi parametric model
 are the covariates. are the regression coefficients estimated from the data. PH assumption needed. Estimate βs without estimating h0(t) semi parametric model.")
49
Cox regression equation (ii)
If we divide both sides of the equation on the previous slide by h0(t) and take logarithms, we obtain: We call h(t) / h0(t) the hazard ratio The coefficients bi...bn are estimated by Cox regression, and can be interpreted in a similar manner to that of multiple logistic regression exp(bi) is the instantaneous relative risk of an event
 and take logarithms, we obtain: We call h(t) / h0(t) the hazard ratio. The coefficients bi...bn are estimated by Cox regression, and can be interpreted in a similar manner to that of multiple logistic regression. exp(bi) is the instantaneous relative risk of an event.")
50
Cox regression in Stata
Will first model a time invariant covariate (sex) on risk of partnership ending Then will add a time dependent covariate (age) to the model
 on risk of partnership ending. Then will add a time dependent covariate (age) to the model.")
51
Cox regression in Stata

52
Interpreting output from Cox regression
Cox model has no intercept It is included in the baseline hazard In our example, the baseline hazard is when sex=1 (male) The hazard ratio is the ratio of the hazard for a unit change in the covariate HR = 1.3 for women vs. men The risk of partnership breakdown is increased by 30% for women compared with men Hazard ratio assumed constant over time At any time point, the hazard of partnership breakdown for a woman is 1.3 times the hazard for a man
 The hazard ratio is the ratio of the hazard for a unit change in the covariate. HR = 1.3 for women vs. men. The risk of partnership breakdown is increased by 30% for women compared with men. Hazard ratio assumed constant over time. At any time point, the hazard of partnership breakdown for a woman is 1.3 times the hazard for a man.")
53
Interpreting output from Cox regression (ii)
The hazard ratio is equivalent to the odds that a female has a partnership breakdown before a man The probability of having a partnership breakdown first is = (hazard ratio) / (1 + hazard ratio) So in our example, a HR of 1.30 corresponds to a probability of 0.57 that a woman will experience a partnership breakdown first The probability or risk of partnership breakdown can be different each year but the relative risk is constant So if we know that the probability of a man having a partnership breakdown in the following year is 1.5% then the probability of a woman having a partnership breakdown in the following year is 0.015*1.30 = 1.95%
 / (1 + hazard ratio) So in our example, a HR of 1.30 corresponds to a. probability of 0.57 that a woman will experience a partnership breakdown first. The probability or risk of partnership breakdown can be different each year but the relative risk is constant. So if we know that the probability of a man having a partnership breakdown in the following year is 1.5% then the probability of a woman having a partnership breakdown in the following year is *1.30 = 1.95%")
56
Time dependent covariates
Examples Current age group rather than age at baseline GHQ score may change over time and predict break-ups Will use age to predict duration of cohabitation Nonlinear relationship hypothesised Recode age into 8 equally spaced age groups

57
Cox regression with time dependent covariates

58
Cox regression assumptions
Assumption of proportional hazards No censoring patterns True starting time Plus assumptions for all modelling Sufficient sample size, proper model specification, independent observations, exogenous covariates, no high multicollinearity, random sampling, and so on

59
Proportional hazards assumption
Cox regression with time-invariant covariates assumes that the ratio of hazards for any two observations is the same across time periods This can be a false assumption, for example using age at baseline as a covariate If a covariate fails this assumption for hazard ratios that increase over time for that covariate, relative risk is overestimated for ratios that decrease over time, relative risk is underestimated standard errors are incorrect and significance tests are decreased in power

60
Testing the proportional hazards assumption
Graphical methods Comparison of Kaplan-Meier observed & predicted curves by group. Observed lines should be close to predicted Survival probability plots (cumulative survival against time for each group). Lines should not cross Log minus log plots (minus log cumulative hazard against log survival time). Lines should be parallel
. Lines should not cross. Log minus log plots (minus log cumulative hazard against log survival time). Lines should be parallel.")
61
Testing the proportional hazards assumption
Formal tests of proportional hazard assumption Include an interaction between the covariate and a function of time. Log time often used but could be any function. If significant then assumption violated Test the proportional hazards assumption on the basis of partial residuals. Type of residual known as Schoenfeld residuals.

62
When assumptions are not met
If categorical covariate, include the variable as a strata variable Allows underlying hazard function to differ between categories and be non proportional Estimates separate underlying baseline hazard for each stratum

63
When assumptions are not met
If a continuous covariate Consider splitting the follow-up time. For example, hazard may be proportional within first 5 years, next 5-10 years and so on Could covariate be included as time dependent covariate? There are different survival regression methods (e.g. parametric models) that do not assume PH
 that do not assume PH.")
64
Censoring assumptions
Censored cases must be independent of the survival distribution. There should be no pattern to these cases, which instead should be missing at random. If censoring is not independent, then censoring is said to be informative You have to judge this for yourself Usually don’t have any data that can be used to test the assumption Think carefully about start and end dates Always check a sample of records

65
True starting time The ideal model for survival analysis would be where there is a true zero time If the zero point is arbitrary or ambiguous, the data series will be different depending on starting point. The computed hazard rate coefficients could differ, sometimes markedly Conduct a sensitivity analysis to see how coefficients may change according to different starting points

66
Other extensions to survival analysis
Discrete (interval-censored) survival times Repeated events Multi-state models (more than 1 event type)- competing risks Transition from employment to unemployment or leaving labour market Modelling type of exit from cohabiting relationship- separation/divorce/widowhood Frailty (unobserved heterogeneity)
 survival times. Repeated events. Multi-state models (more than 1 event type)- competing risks. Transition from employment to unemployment or leaving labour market. Modelling type of exit from cohabiting relationship- separation/divorce/widowhood. Frailty (unobserved heterogeneity)")
67
Could you use logistic regression instead?
May produce similar results for short or fixed follow-up periods Examples everyone followed-up for 7 years maximum follow-up 5 years Results may differ if there are varying follow-up times If dates of entry and dates of events are available then better to use Cox regression

68
Finally…. This is just an introduction to survival/ event history analysis Only reviewed the Cox regression model Also parametric survival methods But Cox regression likely to suit type of analyses of interest to sociologists Consider an intensive course if you want to use survival analysis in your own work

69
Some Resources Stephen Jenkins’s course on survival analysis:
Allison, Paul D. (1984) Event History Analysis: Regression for Longitudinal Event Data, Sage Cleves, M., W. Gould, and R. Gutierrez An Introduction to Survival Analysis Using Stata. Rev. ed. Stata Press: College Station, Texas
 Event History Analysis: Regression for Longitudinal Event Data, Sage. Cleves, M., W. Gould, and R. Gutierrez An Introduction to Survival Analysis Using Stata. Rev. ed. Stata Press: College Station, Texas.")
Similar presentations






 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 Issue date National Student.>")







. Calculation of incidence Strategy #2 ANALYSIS BASED ON PERSON-TIME CALCULATION OF PERSON-TIME AND INCIDENCE RATES.>")






 regression.>")

![If we use a logistic model, we do not have the problem of suggesting risks greater than 1 or less than 0 for some values of X: E[1{outcome = 1} ] = exp(a+bX)/](/11/3248837/big_thumb.jpg "If we use a logistic model, we do not have the problem of suggesting risks greater than 1 or less than 0 for some values of X: E[1{outcome = 1} ] = exp(a+bX)/>")