Download presentation
Presentation is loading. Please wait.

1
De-Identification

2
Privacy in Organizational Processes
Patient medical bills Patient information Hospital Insurance Company Drug Company Aggregate anonymized patient information Advertising Complex Process within a Hospital PUBLIC Patient 2

3
Transfer and Use Between Organizations
Achieve organizational purpose while respecting privacy expectations in the transfer and use of personal information (individual and aggregate) within and across organizational boundaries
 within and across organizational boundaries.")
4
We Use the Health Data for
Research in Many Aspects

5
Two Swords in Health Research
Informed Consent Form De-Identification 目前臨床研究兩種方式,可以說服 IRB 和社會大衆,它們是有盡到人身和資料保護的方法 第一種方式,就是受試者簽署 ICF,讓受試者(被研究者)預先或有條件的放棄他們本應擁有權力的隱私。 第二種方式,是讓研究者無法透過資料的比對獲得受試者個人的病歷資料,進而傷害受試者的隱私。
預先或有條件的放棄他們本應擁有權力的隱私。 第二種方式,是讓研究者無法透過資料的比對獲得受試者個人的病歷資料,進而傷害受試者的隱私。")
6
HIPAA Background Commercial Healthcare Insurance
Pharmaceutical Benefit Maker (Intruder) Health Maintain Organization holding hospitals’ stock share or M&A hospitals Research Fraud and Scandal of Clinical Trials Who can market our medical record data?
 Health Maintain Organization holding hospitals’ stock share or M&A hospitals. Research Fraud and Scandal of Clinical Trials. Who can market our medical record data")
7
Health Insurance Portability and Accountability Act
HIPPA, enacted by US Congress in 1996 Title I: Health Care Access, Portability, and Renewability Title II: Preventing Health Care Fraud and Abuse; Administrative Simplification; Medical Liability Reform Privacy Rule Transactions and Code Sets Rule Security Rule Unique Identifiers Rule Enforcement Rule HITECH Act: Privacy Requirements

8
ICF 的範本(KUSO版) 願參加 XXX 藥品的臨床試驗 如有生死,各安天命 受試者 X X X
 願參加 XXX 藥品的臨床試驗 如有生死,各安天命 受試者 X X X")
9
De-Identification and Re-Identification
婦產科醫師 慈濟醫院 人體試驗審議委員會 企業管理博士 醫管系助理教授 林錦鴻

10
What items are prohibited for disclosure ?

11
HIPAA Privacy Rule and Research with De-identified Information (1)
(1) Names (2) All geographic subdivisions smaller than a State, including: street, city, county, precinct, zip code - the first three digits of the zip code can be used if this geocode includes more than 20,000 people. If such geocode is less than 20,000 persons, "000" must be used as the zip code. (3) All elements of dates (except year) related to an individual, including birth date, admission date, discharge date, date of death. For individuals > 89 years of age, year of birth cannot be used - all elements must be aggregated into a category of 90 and older.
 Names (2) All geographic subdivisions smaller than a State, including: street, city, county, precinct, zip code - the first three digits of the zip code can be used if this geocode includes more than 20,000 people. If such geocode is less than 20,000 persons, 000 must be used as the zip code. (3) All elements of dates (except year) related to an individual, including birth date, admission date, discharge date, date of death. For individuals > 89 years of age, year of birth cannot be used - all elements must be aggregated into a category of 90 and older.")
12
HIPAA Privacy Rule and Research with De-identified Information (2)
(4) Telephone numbers (5) FAX numbers (6) Electronic mail addresses (7) SSN (8) Medical record numbers (9) Health plan beneficiary numbers (10) Account numbers (11) Certificate/license numbers (12) Vehicle identifiers and serial numbers, including license plates (13) Device identifiers and serial numbers (14) Web universal resource locators (URLs) (15) Internet protocol (IP) address (16) Biometric identifiers, including finger and voice prints (17) Full face photos, and comparable images (18) Any unique identifying number, characteristic or code and
 Telephone numbers (5) FAX numbers (6) Electronic mail addresses (7) SSN (8) Medical record numbers (9) Health plan beneficiary numbers (10) Account numbers (11) Certificate/license numbers. (12) Vehicle identifiers and serial numbers, including license plates (13) Device identifiers and serial numbers (14) Web universal resource locators (URLs) (15) Internet protocol (IP) address (16) Biometric identifiers, including finger and voice prints (17) Full face photos, and comparable images (18) Any unique identifying number, characteristic or code and.")
13
Following the HIPAA Regulation
Is it really a safe procedure to “de-identification” ? ( Yes or No ) Are you sure that researchers can proceed their research after deleting these tags or codes ( Yes or No )
 Are you sure that researchers can proceed their research after deleting these tags or codes ( Yes or No )")
14
王 X 明 A 報紙

15
王小 x B 報紙

16
X 小明 C 報紙

17
王 小 明 Re-Identification

18
Example To track those subjects of cervical cancer by comparing the ICD9 and SCC data ( Date, Tag and Result ) Age and Location (Place) are very important influencing factors. Will this data-link-decoding spoil your research?
 are very important influencing factors. Will this data-link-decoding spoil your research")
19
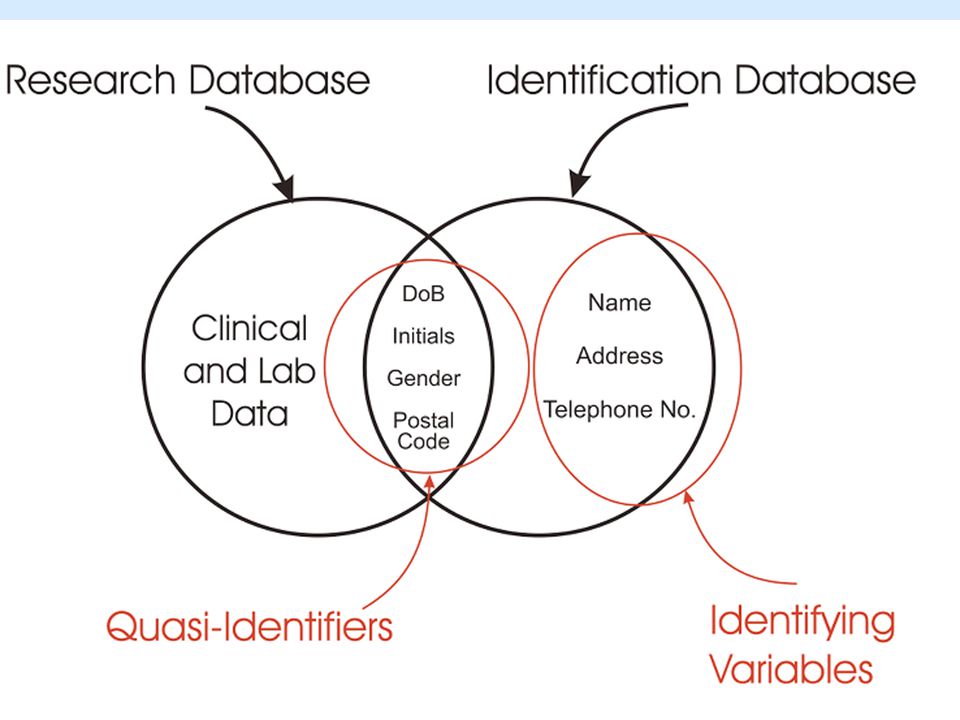
Categories of variables in a data set
Directly Identifying Variables Quasi-identifiers Sensitive variables Sensitive Variable : like the financial or health status of an individual. How many sensitive variables are allowed in a limited database ? 胡自強事件,選舉時病歷被公佈,來阻止胡自強當選一事

21
Direct Identifiers Direct Identifiers are which can directly link to a subject personal data by public data information infrastructure. Name, Account Number, Medical Record Number, ID Number …..

22
In-direct Identifier (Quasi)
Location (Address, Zip-Code) Communication Identifier ( Telephone, FAX) Internet Identifier ( IP, , Machine Code ) Any unique identifying number, characteristic or code
 Communication Identifier. ( Telephone, FAX) Internet Identifier. ( IP, , Machine Code ) Any unique identifying number, characteristic or code.")
23
Quasi-Identifier Date of Birth (DoB) DoB – Month and Year
Day, Month and Year of Admission, Discharge or Operation Gender Initials Address City Region Postal Code

24
The Difference Anonymous Confidential De-identified
The IRB often finds that the terms anonymous, confidential, and de-identified are used incorrectly. These terms are described below as they relate to an individual’s participation in the research and the way that their data are collected and maintained for analysis.

25
Anonymous It is impossible to know whether or not an individual participated in the study directly. A study participant who is a member of a minority ethnic group might be identifiable from even a large data pool. Information regarding other unique individual characteristics (indirect identifiers) might make it possible to identify an individual from a pool of dataset.
 might make it possible to identify an individual from a pool of dataset.")
26
Example A Taiwan Health Insurance Claim Data Set for Physician Behavior of Prescription in Commercial Use (PBMs know which physician prescribed their medications)
")
27
Confidential The research team is obligated to protect the data from disclosure outside the research according to the terms of the research protocol and the informed consent document. In order to protect against accidental disclosure, the subject’s name or other identifiers should be stored separately from their research data and replaced with a unique code to create a new identity for the subject. Note that coded data are not anonymous.

28
Example B Use distrust or conflict mechanism between different individuals or branches Congressmen and Officers Accounting and Financial Branch Market and Sale IRB and Researcher

29
De-identified When any direct or indirect identifiers or codes linking the data to the individual subject’s identity are destroyed. Data have been de-identified. There were no risk to re-identify. However, in the research aspect, there were a lot of details and facts would be ignored and loosed.

30
Safe Limited De-Identified Confidential Anonymous

33
Re-Identification Re-Link with some identifier or quasi-identifier to access original identification. Evaluation the risk of re-identification is an attitude or consensus for a reviewer.

34
Limited or De-Identified
Contract or not ? (Non-Disclosure Agreement) Regulation or not ? Expiated or Full Board ? Preservation or Time Period Available ? Indefinite With Date to be Expired Database Access Committee ? Database Administrator ?
 Regulation or not Expiated or Full Board Preservation or Time Period Available Indefinite. With Date to be Expired. Database Access Committee Database Administrator")
35
A Perfect Data Security Management & Infrastructure
Heuristics A Perfect Data Security Management & Infrastructure IRB Role and Review FAQ

36
這張要整頁印

37
Are subjects identifiable by their age, gender, and residence ?
原住民、少數族群、特殊疾病,能夠透過不同資料庫的比對,讓受試者或被研究者的個人資料重新再被連結。 某些研究需要年紀、性別和居住地的資料,年紀可以限制在一定的 Interval,如 10年、5年為一個單位,ZIPCode 要重新編碼

38
Can a person be re-identified from their diagnosis code ?
Many data sets also include diagnosis codes (for example, ICD-10 codes). Hospital medical record abstract data is almost publicly available. A set of diagnosis codes can make an individual very unique. Some of the records in the disclosed data set have diagnosis codes for rare and visible diseases/conditions Icd10 比 ICD 9 更容易 Identifiable
. Hospital medical record abstract data is almost publicly available. A set of diagnosis codes can make an individual very unique. Some of the records in the disclosed data set have diagnosis codes for rare and visible diseases/conditions. Icd10 比 ICD 9 更容易 Identifiable.")
39
Can a claim database be used for re-identification ?
A lot of literature makes the point that claim database can be used for re-identification. However, the accuracy of this statement will depend on your jurisdiction. Other sources of public information they can still be very useful for re-identification.

40
Can individuals be re-identified from disease maps ?

41
Do these maps risk identifying any of the individuals ?
There are three questions that need to be answered to determine the risk: Is the disease visible ? Is the disease rare in the geography ? If I re-identify an individual, will I learn something new about them ?

42
Can postal codes re-identify individuals ?
5 codes are the smallest geographic unit that is used by Taiwan post to deliver mail. In a health care context they are the most common geographic unit because that is what patients know and are able to provide. The postal code is the only demographic information that is being disclosed in this data set. The smallest postal codes in all provinces and territories have very few people living there. Any information about the postal code would pertain to a very small number of individuals.

43
Definition of identifiable dataset if a person can find their record(s) in the dataset
Who is most sensitive to a data de-identification ? (Individual or reviewer) Best de-identification of dataset is that a individual cannot point out his/her record.
 Best de-identification of dataset is that a individual cannot point out his/her record.")
44
How can I de-identify longitudinal records ?
Time Series Record is just a DNA (unique)-sequential dataset. It can easily re-identified. It should be considered a limited database. Intervals are less likely to be unique than actual dates.
-sequential dataset. It can easily re-identified. It should be considered a limited database. Intervals are less likely to be unique than actual dates.")
45
How can I safely release data to multiple researchers?
Re-numbering Re-ranking Different Sampling Shuffle your data before disclosure Strong dis-incentive to match the two data sets Change (Say 0.4 to 40%, English style to metric)
")
46
Is sampling sufficient to de-identify a data set ?
Not only statistical significance but also risk re-identification would be taken into consideration. Intruder may not know their target within disclosure database Sampling fraction if it is higher ? (Similar as public database)
")
47
Is there a secondary use market for health information ?
Yes or No Pharmaceutical Benefit Maker Private Health Insurance Service Other service ( Women and Children)
")
48
Should de-identified data go through a research ethics review ?
In the first approach the IRB form has a checkbox question asking the investigator if the data is de- identified. (UM forms) If the investigator checks that box then the IRB does not review the protocol and it is automatically approved. The reasoning is that it is de-identified data and therefore there is no requirement to review the protocol.
 If the investigator checks that box then the IRB does not review the protocol and it is automatically approved. The reasoning is that it is de-identified data and therefore there is no requirement to review the protocol.")
49
Should IRBs decide if a data set is de-identified ?
Yes or No ? (No) We don’t have a privacy expert. Whether a particular data set is identifiable, and resolving any re-identification risk concerns is iterative. If these interactions are attempted they can be very slow and consequently frustrating. IRB 沒那麼厲害,管天管地又要管人…
 We don’t have a privacy expert. Whether a particular data set is identifiable, and resolving any re-identification risk concerns is iterative. If these interactions are attempted they can be very slow and consequently frustrating. IRB 沒那麼厲害,管天管地又要管人…")
50
Should we de-identify if technology is moving so fast ?
Re-Identification technology moves faster than De-Identification 道高一尺,魔高一丈 Educations for data security is cheaper than new technology. High technology stands for high risk

51
The difference between consenters and non-consenters
Secondary use of previous dataset which is contributed from previous consenter. (對原提供者有益) Should the data of drop out consenter would be included (Consenter 是否認同提供)? Were there any words of consent to use his/her personal information found in the ICF. (Usually, to agree specimen but no personal Information) Non-consenter would be reviewed by a data access center or the privacy expert. (沒有同意資料使用) 資料使用必須要對原提供者是有益的,如果是有害的呢 使用者是否認同後續的提供,如果他不贊同呢,在 ICF 內他無法表達,因為沒有不贊同的選項 通常他只有同意標本的使用,但是沒有同意他的個資,所以未來在 ICF上,PI 如果有資料使用的可能,記住要加以註明。 沒有同意個人資料使用的,一定要經過 Privacy Expert 或資料安全管理中心的 Review.
 Should the data of drop out consenter would be included (Consenter 是否認同提供) Were there any words of consent to use his/her personal information found in the ICF. (Usually, to agree specimen but no personal Information) Non-consenter would be reviewed by a data access center or the privacy expert. (沒有同意資料使用) 資料使用必須要對原提供者是有益的,如果是有害的呢. 使用者是否認同後續的提供,如果他不贊同呢,在 ICF 內他無法表達,因為沒有不贊同的選項. 通常他只有同意標本的使用,但是沒有同意他的個資,所以未來在 ICF上,PI 如果有資料使用的可能,記住要加以註明。 沒有同意個人資料使用的,一定要經過 Privacy Expert 或資料安全管理中心的 Review.")
52
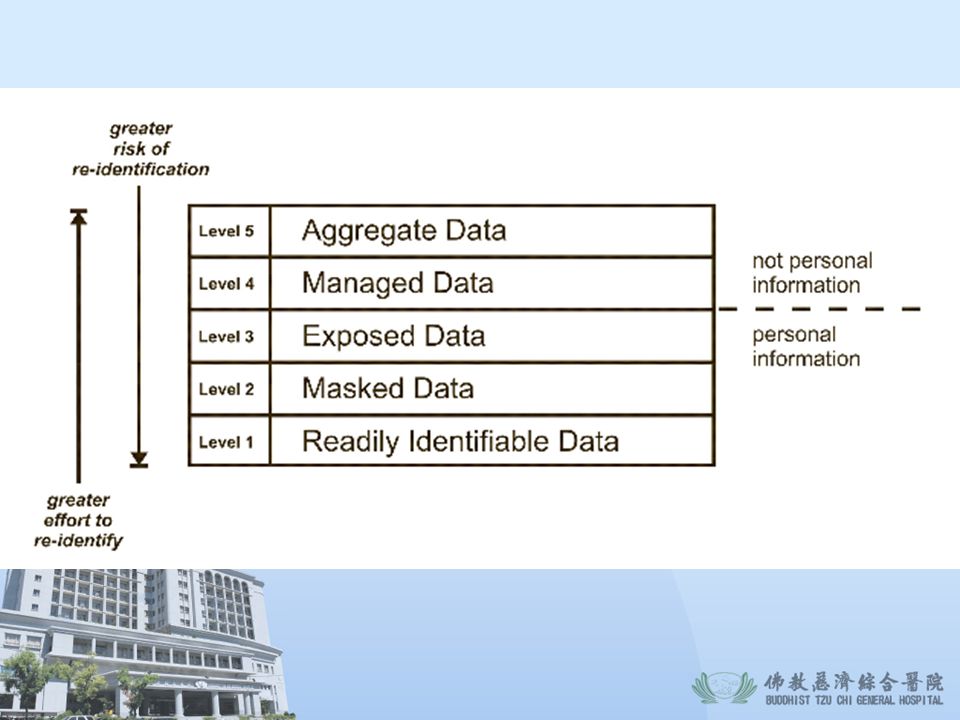
The five levels of identifiability
Level 1. The full data set as is. Level 2. The names are replaced by fake names, the health insurance number is replaced with a fake number, and the street address field is removed altogether. Level 3. The data set at Level 2 also has the postal code generalized from six characters to five characters. The risk at Level 3 is the same as Level 2, but the organization believes it has de-identified the data and discloses it. Therefore, the organization is exposed. 有其它的資料安全的分類方式 Level 只有改名字

53
The five levels of identifiability
Level 4. The data set at Level 3 is further modified by replacing the 5 digit postal code with a single character postal code, the date of birth is replaced by age, and the date of visit is replaced by the month of the visit. A re-identification risk assessment is then performed on this data set and the risk was found to be below a pre-specified threshold. Level 5. The number of individuals with a sexually transmitted disease.

56
What are the quasi-identifiers that I should use for managing risk
What are the quasi-identifiers that I should use for managing risk ? (Neighborhood) Address and telephone information about the target individual Household and dwelling information (number of children, value of property, type of property) Key dates (births, deaths, weddings, admissions, discharges) Visible characteristics: gender, race, ethnicity, language spoken at home, weight, height, physical disabilities Profession 除了 HIPAA 和前面所例出來的Quasi-Identifier 那些可能是 Sensitive Identifier, 也就是可能在道德和法律上 應該注意。 電訪的內容,或者訪問的情境。 …….
 Address and telephone information about the target individual. Household and dwelling information (number of children, value of property, type of property) Key dates (births, deaths, weddings, admissions, discharges) Visible characteristics: gender, race, ethnicity, language spoken at home, weight, height, physical disabilities. Profession. 除了 HIPAA 和前面所例出來的Quasi-Identifier. 那些可能是 Sensitive Identifier, 也就是可能在道德和法律上. 應該注意。 電訪的內容,或者訪問的情境。 …….")
57
What are the quasi-identifiers that I should use for managing prosecutor risk ? (Ex-Spouse)
The same things that a neighbor would know Basic medical history (allergies, chronic diseases) Income, Years of schooling 其它的如前妻,前夫的問題,包含…
 Income, Years of schooling. 其它的如前妻,前夫的問題,包含…")
58
What de-identification software tools are there ?
The PARAT tool from Privacy Analytics implements comprehensive risk management for three types of identity disclosure risk. mu-Argus, developed by the Netherlands national statistical agency. The Cornell Anonymization Toolkit (CAT) implements a k-anonymity algorithm. The University of Texas at Dallas Anonymization Toolbox 推薦一些 De-identification 的資訊產品。 但前面我已經表達我的意見了,不要迷信這種東東…
 implements a k-anonymity algorithm. The University of Texas at Dallas Anonymization Toolbox. 推薦一些 De-identification 的資訊產品。 但前面我已經表達我的意見了,不要迷信這種東東…")
59
Who cares about my medical records ? (Finance)
Some medical records have financial information in them (e.g. information used for billing purposes) For example, date of birth, address, and mother's maiden name. It is used as pin or password frequently. Even if medical records do not have information in them that is suitable for financial fraud, if your record has information about your health insurance then it can be very valuable. 醫療費用,使用項目,可以評估病人的經濟情況, 或許衣服的穿著不會完全反應他的財富,但是醫療的使用,是比較好的指標。 例如自費癌症藥品的使用。 密碼的來源 詐騙集團的來源,藥物王碌仙的
 For example, date of birth, address, and mother s maiden name. It is used as pin or password frequently. Even if medical records do not have information in them that is suitable for financial fraud, if your record has information about your health insurance then it can be very valuable. 醫療費用,使用項目,可以評估病人的經濟情況, 或許衣服的穿著不會完全反應他的財富,但是醫療的使用,是比較好的指標。 例如自費癌症藥品的使用。 密碼的來源. 詐騙集團的來源,藥物王碌仙的.")
60
Who cares about my medical records ? (Media)
If you ever become of interest to the media and they want to do a story on you or your family, then reporters may be interested in re-identifying records about you. Medical records are a good source of revenue if you are in the extortion business. Even if there is no financial impact, some people feel violated if there is a breach of privacy of their medical information and change their behavior by adopting privacy protective behaviors. There are a number of attempts to make your health information publicly (or at least very widely) available. 辜家的事件…. 認父親,爭遺產的 ….
 available. 辜家的事件…. 認父親,爭遺產的 ….")
61
Other researchers’ questions
What genes predict better prognosis or response to treatment? Can study these questions using cancer registries, claims data 如果你的employee 癌症的資料,在你的手上。 61

62
Ethical questions May you share (coded genome-wide) data with other researchers? May you use (coded genome-wide) data for additional research without consent? May you do whole genome sequencing on existing coded samples without consent? 三個答案都是 (不可以) 62
 data for additional research without consent May you do whole genome sequencing on existing coded samples without consent 三個答案都是 (不可以) 62.")
63
Ethical concerns May you follow participants as prospective cohort using medical records without consent? With identifiers can link to cancer registry, Medicare claims databases 第四個是醫療工作的大忌,尤其是癌症或者是健保資料庫 63

64
Federal regulations on human subjects research
IRB review Informed consent Not apply if Researcher not interact with participant AND Information not “identifiable” 研究者沒有和參加者互動,或者是這些資訊己經去連結 64

65
What are de-identified data?
18 HIPAA specific identifiers Overt identifiers, including SSN, medical record number Geographic data more precise than first 3 digits of zip code Dates except for year Biometric identifiers Any other unique identifying characteristic Stricter than Common Rule Need these data elements to carry out research Limited Data Set allows dates and zip code 65

66
Ethical issues Informed consent
When giving broad permission for future research, do donors appreciate Whole genome sequencing? Very sensitive downstream research? 什麼都可以的 同意書,萬用的同意書 我的是我的,你的也是我的。 66

67
Sensitive research projects
Some donors may object to research Genetics of antisocial behavior Human evolution Beliefs about group ancestry 不屬於 IRB 的查審範圍,精神病,進化,族群 67

68
Ethical issues Privacy and confidentiality
Heightened concerns, particularly about whole genome sequencing 不認為可以審查的部份 68

69
Special concerns about genetic confidentiality
Information considered particularly sensitive About relatives and groups Highly predictive of future illness “Future diaries” Annas, JAMA 1993. 69

70
Genetic Information Nondiscrimination Act (2008)
Remove barriers to genetic testing Health insurers may not Use genetic information to set eligibility or premiums Require or request genetic testing 不可以用基因檢查來作的研究 70

71
Genetic Information Nondiscrimination Act (2008)
Employers may not Use genetic information in employment or promotion decisions Require or request genetic testing 71

72
Limitations of GINA After job offer, employer may request medical records Impractical to delete genetic information Not apply to disability, life, long-term care insurance Adverse selection if individual rating 72

73
HIPAA fails to protect privacy
Weak security protections Applies only to “covered entities” Protection does not follow information technology advancing IRBs not oversee once research is initiated 73

74
Thanks for Your Attention

Similar presentations