Download presentation
Presentation is loading. Please wait.

1
State Space Models

2
Let { x t :t T} and { y t :t T} denote two vector valued time series that satisfy the system of equations: y t = A t x t + v t (The observation equation) x t = B t x t-1 + u t (The state equation) The time series { y t :t T} is said to have state-space representation.
 x t = B t x t-1 + u t (The state equation) The time series { y t :t T} is said to have state-space representation.")
3
Note: { u t :t T} and { v t :t T} denote two vector valued time series that satisfying: 1.E(u t ) = E(v t ) = 0. 2.E(u t u s ˊ ) = E(v t v s ˊ ) = 0 if t s. 3.E(u t u t ˊ ) = u and E(v t v t ˊ ) = v. 4.E(u t v s ˊ ) = E(v t u s ˊ ) = 0 for all t and s.
 = E(v t v s ˊ ) = 0 if t s. 3.E(u t u t ˊ ) = u and E(v t v t ˊ ) = v. 4.E(u t v s ˊ ) = E(v t u s ˊ ) = 0 for all t and s..")
4
Example: One might be tracking an object with several radar stations. The process {x t :t T} gives the position of the object at time t. The process { y t :t T} denotes the observations at time t made by the several radar stations. As in the Hidden Markov Model we will be interested in determining position of the object, {x t :t T}, from the observations, {y t :t T}, made by the several radar stations

5
Example: Many of the models we have considered to date can be thought of a State- Space models Autoregressive model of order p:

6
Define Then andState equation Observation equation

7
Hidden Markov Model: Assume that there are m states. Also that there the observations Y t are discreet and take on n possible values. Suppose that the m states are denoted by the vectors:

8
Suppose that the n possible observations taken at each state are

9
Let and Note

10
Let So that The State Equation with

11
Also Hence and where diag(v) = the diagonal matrix with the components of the vector v along the diagonal
 = the diagonal matrix with the components of the vector v along the diagonal")
12
then Since and Thus

13
We have defined Hence Let

14
Then with The Observation Equation and

15
Hence with these definitions the state sequence of a Hidden Markov Model satisfies: with The Observation Equation and The State Equation with and The observation sequence satisfies:

16
Kalman Filtering

17
We are now interested in determining the state vector x t in terms of some or all of the observation vectors y 1, y 2, y 3, …, y T. We will consider finding the best linear predictor. We can include a constant term if in addition one of the observations (y 0 say) is the vector of 1s. We will consider estimation of x t in terms of 1.y 1, y 2, y 3, …, y t-1 (the prediction problem) 2.y 1, y 2, y 3, …, y t (the filtering problem) 3.y 1, y 2, y 3, …, y T (t < T, the smoothing problem)
 is the vector of 1s. We will consider estimation of x t in terms of 1.y 1, y 2, y 3, …, y t-1 (the prediction problem) 2.y 1, y 2, y 3, …, y t (the filtering problem) 3.y 1, y 2, y 3, …, y T (t < T, the smoothing problem).")
18
For any vector x define: where is the best linear predictor of x (i), the i th component of x, based on y 0, y 1, y 2, …, y s. The best linear predictor of x (i) is the linear function that of x, based on y 0, y 1, y 2, …, y s that minimizes
 is the linear function that of x, based on y 0, y 1, y 2, …, y s that minimizes.")
19
Remark: The best predictor is the unique vector of the form: Where C 0, C 1, C 2, …,C s, are selected so that:

20
Remark: If x, y 1, y 2, …,y s are normally distributed then:

21
Let u and v, be two random vectors than is the optimal linear predictor of u based on v if Remark

22
State Space Models

23
Let { x t :t T} and { y t :t T} denote two vector valued time series that satisfy the system of equations: y t = A t x t + v t (The observation equation) x t = B t x t-1 + u t (The state equation) The time series { y t :t T} is said to have state-space representation.
 x t = B t x t-1 + u t (The state equation) The time series { y t :t T} is said to have state-space representation.")
24
Note: { u t :t T} and { v t :t T} denote two vector valued time series that satisfying: 1.E(u t ) = E(v t ) = 0. 2.E(u t u s ˊ ) = E(v t v s ˊ ) = 0 if t s. 3.E(u t u t ˊ ) = u and E(v t v t ˊ ) = v. 4.E(u t v s ˊ ) = E(v t u s ˊ ) = 0 for all t and s.
 = E(v t v s ˊ ) = 0 if t s. 3.E(u t u t ˊ ) = u and E(v t v t ˊ ) = v. 4.E(u t v s ˊ ) = E(v t u s ˊ ) = 0 for all t and s..")
25
Let { x t :t T} and { y t :t T} denote two vector valued time series that satisfy the system of equations: y t = A t x t + v t x t = Bx t-1 + u t Let Kalman Filtering: and

26
Then where One also assumes that the initial vector x 0 has mean and covariance matrix an that

27
The covariance matrices are updated with

28
Summary: The Kalman equations 1. 2. 3. 4. 5. with and

29
Now hence Proof: Note proving (4)
")
30
Let Given y 0, y 1, y 2, …, y t-1 the best linear predictor of d t using e t is:

31
Hence where and Now (5)
")
32
Also hence (2)
")
33
Thus where Also (4) (5) (2)
 (5) (2)")
34
The proof that will be left as an exercise. Hence (3) (1)
 (1)")
35
Example: What is observe is the time series Suppose we have an AR(2) time series {u t |t T} and {v t |t T} are white noise time series with standard deviations u and v.
 time series {u t |t T} and {v t |t T} are white noise time series with standard deviations u and v.")
36
then This model can be expressed as a state-space model by defining:

37
can be written The equation: Note:

38
The Kalman equations 1. 2. 3. 4. 5. Let

39
The Kalman equations 1.

40
2.

41
3.

42
4.

43
5.

45
Now consider finding These can be found by successive backward recursions for t = T, T – 1, …, 2, 1 Kalman Filtering (smoothing): where
: where")
46
The covariance matrices satisfy the recursions

47
1. The backward recursions 2. 3. In the example: - calculated in forward recursion

Similar presentations
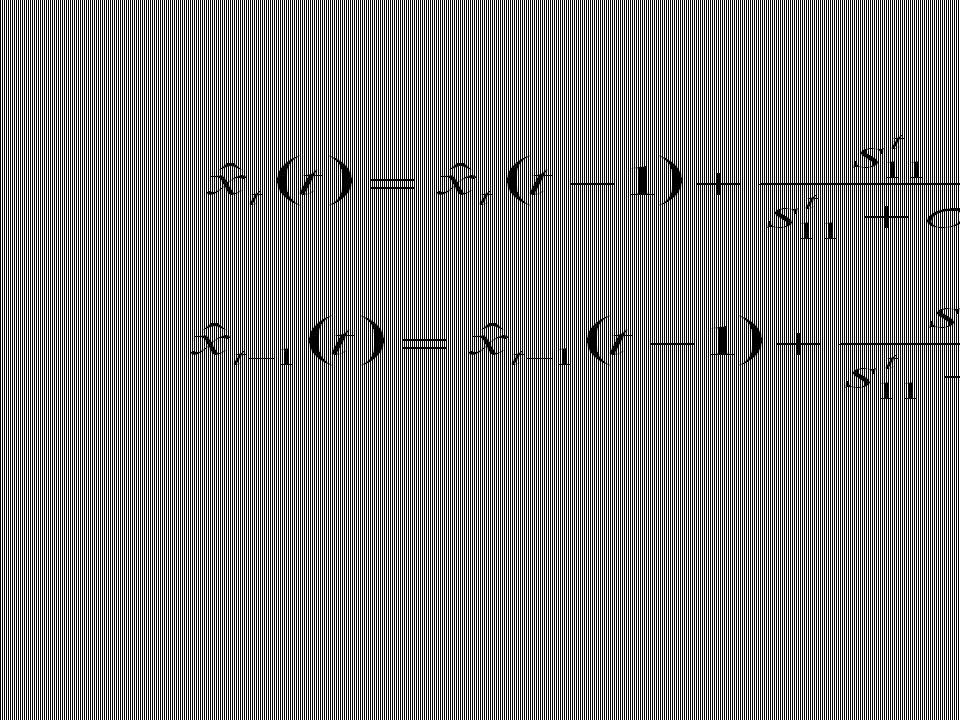






 – Observable.>")






 George Kantor presented to Sensor Based Planning Lab Carnegie Mellon University December 8, 2000.>")





 estimation of the (hidden) state of a linear dynamic process of which we obtain noisy (partial)>")