Download presentation
Presentation is loading. Please wait.

1
Verified computation with probabilities Scott Ferson, Applied Biomathematics IFIP Working Conference on Uncetainty Quantification and Scientific Computing Boulder, Colorado, 2 August 2011 © 2011 Applied Biomathematics

2
Euclid Given a line in a plane, how many parallel lines can be drawn through a point not on the line? For over 20 centuries, the answer was ‘one’

3
Relax one axiom Around 1850, Riemann and others developed non-Euclidean gemetries in which the answer was either ‘zero’ or ‘many’ Controversial, but eventually accepted Mathematics richer and applications expanded Used by Einstein in general relativity

4
Variability = aleatory uncertainty Arises from natural stochasticity Variability arises from –spatial variation –temporal fluctuations –manufacturing or genetic differences Not reducible by empirical effort

5
Incertitude = epistemic uncertainty Arises from incomplete knowledge Incertitude arises from –limited sample size –mensurational limits (‘measurement uncertainty’) –use of surrogate data Reducible with empirical effort
 –use of surrogate data Reducible with empirical effort")
6
Suppose A is in [2, 4] B is in [3, 5] What can be said about the sum A+B? 46810 The right answer for risk analysis is [5,9] Propagating incertitude
![Suppose A is in [2, 4] B is in [3, 5] What can be said about the sum A+B.](http://images.slideplayer.com/8/1347333/slides/slide_6.jpg "The right answer for risk analysis is [5,9] Propagating incertitude.")
7
Simmer down… I’m not saying we should only use intervals Not all uncertainty is incertitude Maybe most uncertainty isn’t incertitude Sometimes incertitude is entirely negligible If so, probability theory is perfectly sufficient

8
What I am saying is… Some analysts face non-negligible incertitude Handling it with standard probability theory requires assumptions that may not be tenable –Unbiasedness, Uniformity, Independence Useful to know what difference it might make Can be discovered by bounding probabilities

9
Bounding probability is an old idea Boole and de Morgan Chebyshev and Markov Borel and Fréchet Kolmogorov and Keynes Dempster and Ellsberg Berger and Walley

10
Several closely related approaches Probability bounds analysis Imprecise probabilities Robust Bayesian analysis Second-order probability Bounding approaches Probability bounds analysis (PBA) –A rough and ready technology Imprecise probabilities –More comprehensive but also more difficult Robust Bayesian analysis –Handles updating rather than convolutions Second-order probability –More difficult and less comprehensive
 –A rough and ready technology Imprecise probabilities –More comprehensive but also more difficult Robust Bayesian analysis –Handles updating rather than convolutions Second-order probability –More difficult and less comprehensive")
11
Traditional uncertainty analyses Worst case analysis Taylor series approximations (delta method) Normal theory propagation (NIST; mean value method) Monte Carlo simulation Stochastic PDEs Two-dimensional Monte Carlo
 Normal theory propagation (NIST; mean value method) Monte Carlo simulation Stochastic PDEs Two-dimensional Monte Carlo")
12
Untenable assumptions Uncertainties are small Distribution shapes are known Sources of variation are independent Uncertainties cancel each other out Linearized models good enough Relevant science is known and modeled

13
Need ways to relax assumptions Hard to say what the distribution is precisely Non-independent, or unknown dependencies Uncertainties that may not cancel Possibly large uncertainties Model uncertainty

14
Probability bounds analysis (PBA) Sidesteps the major criticisms –Doesn’t force you to make any assumptions –Can use only whatever information is available Merges worst case and probabilistic analysis Distinguishes variability and incertitude Used by both Bayesians and frequentists
 Sidesteps the major criticisms –Doesn’t force you to make any assumptions –Can use only whatever information is available Merges worst case and probabilistic analysis Distinguishes variability and incertitude Used by both Bayesians and frequentists")
15
Probability box (p-box) 0 1 1.02.03.00.0 X Cumulative probability Interval bounds on a cumulative distribution function Envelope of ‘horsetail’ plots
 X Cumulative probability Interval bounds on a cumulative distribution function Envelope of ‘horsetail’ plots")
16
Uncertain numbers Not a uniform distribution Cumulative probability 010203040 0 1 10203040 0 1 102030 0 1 Probability distribution Probability box Interval

17
Uncertainty arithmetic We can do math on p-boxes When inputs are distributions, the answers conform with probability theory When inputs are intervals, the results agree with interval (worst case) analysis
 analysis")
18
Calculations All standard mathematical operations –Arithmetic (+, , ×, ÷, ^, min, max) –Transformations (exp, ln, sin, tan, abs, sqrt, etc.) –Magnitude comparisons (, ≥, ) –Other operations (nonlinear ODEs, finite-element methods) Faster than Monte Carlo Guaranteed to bound the answer Optimal solutions often easy to compute envelope, mixture, –Backcalcul ation (deconvol utions, updating) –Logical operations (and, or, not, if, etc.)
 –Transformations (exp, ln, sin, tan, abs, sqrt, etc.) –Magnitude comparisons (, ≥, ) –Other operations (nonlinear ODEs, finite-element methods) Faster than Monte Carlo Guaranteed to bound the answer Optimal solutions often easy to compute envelope, mixture, –Backcalcul ation (deconvol utions, updating) –Logical operations (and, or, not, if, etc.)")
19
Probability bounds arithmetic P-box for random variable AP-box for random variable B What are the bounds on the distribution of the sum of A+B? 0 1 02468101214 Value of random variable B Cumulative Probability 0 1 0123456 Value of random variable A Cumulative Probability

20
Cartesian product A+B independence A [1,3] p 1 = 1/3 A [3,5] p 3 = 1/3 A [2,4] p 2 = 1/3 B [2,8] q 1 = 1/3 B [8,12] q 3 = 1/3 B [6,10] q 2 = 1/3 A+B [3,11] prob=1/9 A+B [5,13] prob=1/9 A+B [4,12] prob=1/9 A+B [7,13] prob=1/9 A+B [9,15] prob=1/9 A+B [8,14] prob=1/9 A+B [9,15] prob=1/9 A+B [11,17] prob=1/9 A+B [10,16] prob=1/9
![Cartesian product A+B independence A [1,3] p 1 = 1/3 A [3,5] p 3 = 1/3 A [2,4] p 2 = 1/3 B [2,8] q 1 = 1/3 B [8,12] q 3 = 1/3 B [6,10] q 2 = 1/3 A+B [3,11] prob=1/9 A+B [5,13] prob=1/9 A+B [4,12] prob=1/9 A+B [7,13] prob=1/9 A+B [9,15] prob=1/9 A+B [8,14] prob=1/9 A+B [9,15] prob=1/9 A+B [11,17] prob=1/9 A+B [10,16] prob=1/9](http://images.slideplayer.com/8/1347333/slides/slide_20.jpg "Cartesian product A+B independence A [1,3] p 1 = 1/3 A [3,5] p 3 = 1/3 A [2,4] p 2 = 1/3 B [2,8] q 1 = 1/3 B [8,12] q 3 = 1/3 B [6,10] q 2 = 1/3 A+B [3,11] prob=1/9 A+B [5,13] prob=1/9 A+B [4,12] prob=1/9 A+B [7,13] prob=1/9 A+B [9,15] prob=1/9 A+B [8,14] prob=1/9 A+B [9,15] prob=1/9 A+B [11,17] prob=1/9 A+B [10,16] prob=1/9")
21
A+B under independence 03691218 0.00 0.25 0.50 0.75 1.00 15 A+B Cumulative probability Rigorous Best-possible

22
X,Y ~ uniform(1,25) No assumptionsUncorrelated “Linear” correlation Positive dependence 10203040500 X + Y 0 1 CDF Particular dependence Imprecise Precise Perfect 10203040500 X + Y Opposite Independence
 No assumptionsUncorrelated Linear correlation Positive dependence X + Y 0 1 CDF Particular dependence Imprecise Precise Perfect X + Y Opposite Independence")
23
Fréchet dependence bounds Guaranteed to enclose results no matter what correlation or dependence there may be between the variables Best possible (couldn’t be any tighter without saying more about the dependence) Can be combined with independence assumptions between other variables
 Can be combined with independence assumptions between other variables")
24
Example: exotic pest establishment F = A & B & C & D Probability of arriving in the right season Probability of having both sexes present Probability there’s a suitable host Probability of surviving the next winter

25
Imperfect information Calculate A & B & C & D, with partial information: –A’s distribution is known, but not its parameters –B’s parameters known, but not its shape –C has a small empirical data set –D is known to be a precise distribution Bounds assuming independence? Without any assumption about dependence?

26
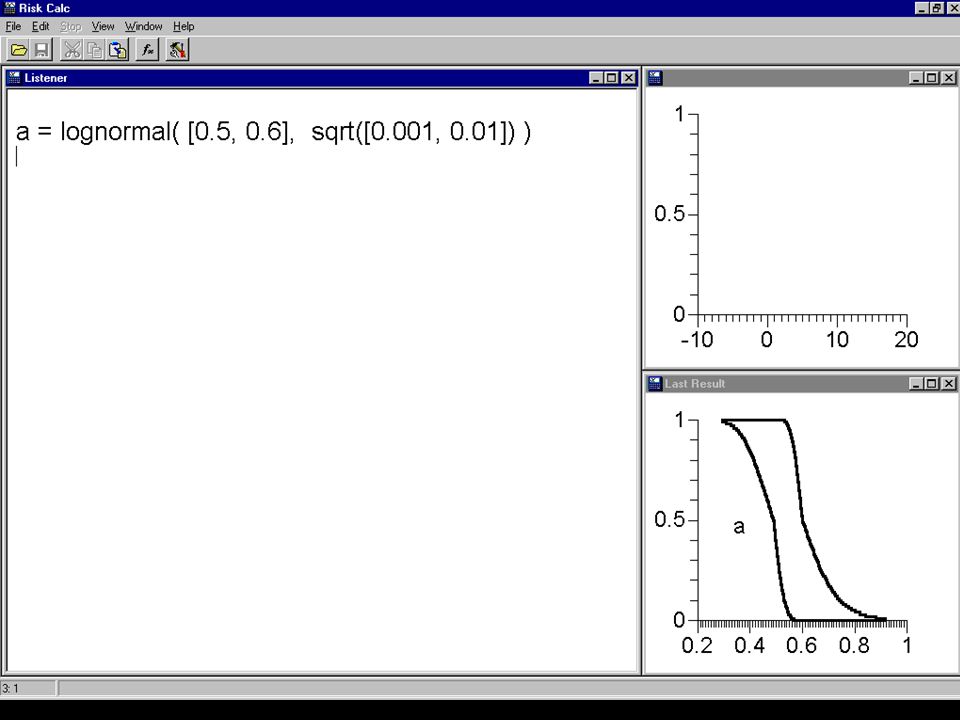
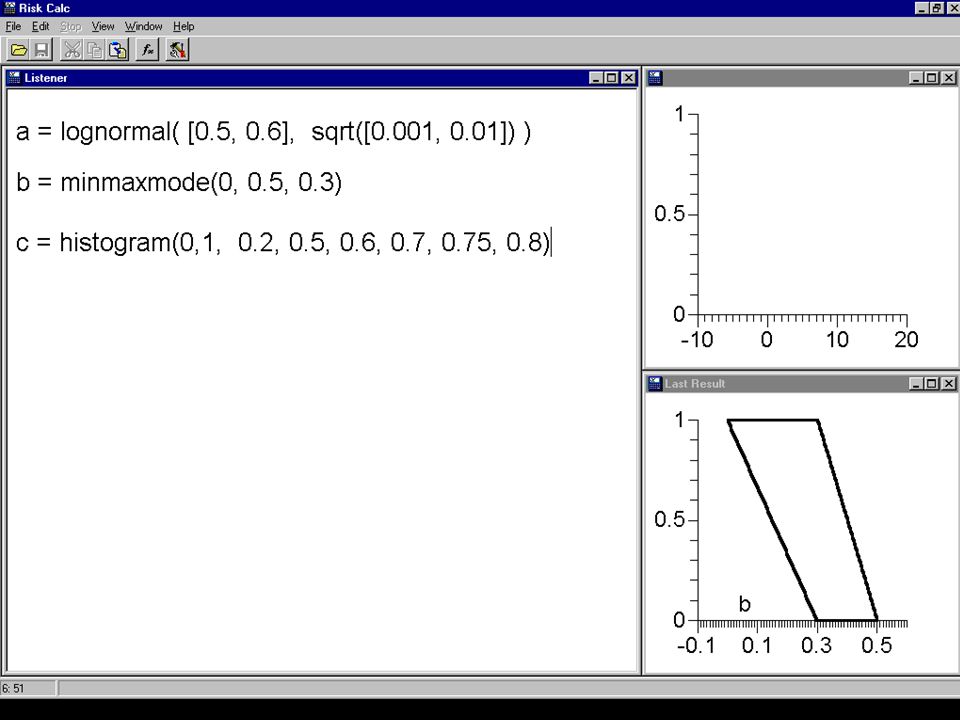
A = {lognormal, mean = [.05,.06], variance = [.0001,.001]) B = {min = 0, max = 0.05, mode = 0.03} C = {sample data = 0.2, 0.5, 0.6, 0.7, 0.75, 0.8} D = uniform(0, 1) A=lognormal([.05,.06],sqrt([.0001,.001])) B= minmaxmode(0,0.05,.03) B = max(B,0.000001) C = histogram(0.001,.9999,.2,.5,.6,.7,.75,.8) D = uniform(0.0001,.9999) f = A |&| B |&| C |&| D f ~(range=[9.48437e-14,0.0109203], mean=[0.00006,0.00119], var=[2.90243743e-09,0.00000208]) fi =A & B & C & D fi ~(range=[0,0.05], mean=[0,0.04], var=[0,0.00052]) show fi, f fi ~(range=[0,0.05], mean=[0,0.04], var=[0,0.00052]) f ~(range=[9.48437e-14,0.0109203], mean=[0.00006,0.00119], var=[2.90243743e-09,0.00000208]) 00.10.20.3 0 1 A 00.020.040.06 0 1 B 01 0 1 D 01 0 1 C CDF
![A = {lognormal, mean = [.05,.06], variance = [.0001,.001]) B = {min = 0, max = 0.05, mode = 0.03} C = {sample data = 0.2, 0.5, 0.6, 0.7, 0.75, 0.8} D = uniform(0, 1) A=lognormal([.05,.06],sqrt([.0001,.001])) B= minmaxmode(0,0.05,.03) B = max(B, ) C = histogram(0.001,.9999,.2,.5,.6,.7,.75,.8) D = uniform(0.0001,.9999) f = A |&| B |&| C |&| D f ~(range=[ e-14, ], mean=[ , ], var=[ e-09, ]) fi =A & B & C & D fi ~(range=[0,0.05], mean=[0,0.04], var=[0, ]) show fi, f fi ~(range=[0,0.05], mean=[0,0.04], var=[0, ]) f ~(range=[ e-14, ], mean=[ , ], var=[ e-09, ]) A B D C CDF](http://images.slideplayer.com/8/1347333/slides/slide_26.jpg "A = {lognormal, mean = [.05,.06], variance = [.0001,.001]) B = {min = 0, max = 0.05, mode = 0.03} C = {sample data = 0.2, 0.5, 0.6, 0.7, 0.75, 0.8} D = uniform(0, 1) A=lognormal([.05,.06],sqrt([.0001,.001])) B= minmaxmode(0,0.05,.03) B = max(B, ) C = histogram(0.001,.9999,.2,.5,.6,.7,.75,.8) D = uniform(0.0001,.9999) f = A |&| B |&| C |&| D f ~(range=[ e-14, ], mean=[ , ], var=[ e-09, ]) fi =A & B & C & D fi ~(range=[0,0.05], mean=[0,0.04], var=[0, ]) show fi, f fi ~(range=[0,0.05], mean=[0,0.04], var=[0, ]) f ~(range=[ e-14, ], mean=[ , ], var=[ e-09, ]) A B D C CDF")
27
Resulting probability 00.020.040.06 0 1 00.010.02 0 1 Cumulative probability All variables independent Makes no assumption about dependencies

28
Summary statistics Independent Range[0, 0.011] Median[0, 0.00113] Mean[0.00006, 0.00119] Variance[2.9 10 9, 2.1 10 6 ] Standard deviation[0.000054, 0.0014] No assumptions about dependence Range[0, 0.05] Median[0, 0.04] Mean[0, 0.04] Variance[0, 0.00052] Standard deviation[0, 0.023]
![Summary statistics Independent Range[0, 0.011] Median[0, ] Mean[ , ] Variance[2.9 10 9, 2.1 10 6 ] Standard deviation[ , ] No assumptions about dependence Range[0, 0.05] Median[0, 0.04] Mean[0, 0.04] Variance[0, ] Standard deviation[0, 0.023]](http://images.slideplayer.com/8/1347333/slides/slide_28.jpg "Summary statistics Independent Range[0, 0.011] Median[0, ] Mean[ , ] Variance[2.9 10 9, 2.1 10 6 ] Standard deviation[ , ] No assumptions about dependence Range[0, 0.05] Median[0, 0.04] Mean[0, 0.04] Variance[0, ] Standard deviation[0, 0.023]")
29
How to use the results When uncertainty makes no difference (because results are so clear), bounding gives confidence in the reliability of the decision When uncertainty swamps the decision (i) use results to identify inputs to study better, or (ii) use other criteria within probability bounds
, bounding gives confidence in the reliability of the decision When uncertainty swamps the decision (i) use results to identify inputs to study better, or (ii) use other criteria within probability bounds")
30
Justifying further empirical effort If incertitude is too wide for decisions, and bounds are best possible, more data is needed –Strong argument for collecting more data Planning empirical efforts can be improved by doing sensitivity analysis of the model –Sensitivity analysis can be done with p-boxes

31
Better than sensitivity studies Uncertainty about shape and dependence cannot be fully revealed by sensitivity studies –Because the problems are infinite-dimensional Probability bounding lets you be comprehensive Intermediate knowledge can be exploited Uncertainties can have large or small effects

32
Where do input p-boxes come from? Prior modeling –Uncertainty about dependence –Robust Bayes analysis Constraint information –Summary publications lacking original data Sparse or imprecise data –Shallow likelihood functions –Measurement uncertainty, censoring, missing data

33
Robust Bayes can make a p-box class of priors, class of likelihoods class of posteriors -505101520 Posteriors Posterior p-box Likelihoods Priors

34
Constraint propagation minmax 1 0 median.5 minmax mode 1 0 minmax 1 0 mean sd 1 0 mean, 1 0 minmaxmean=mode 1 0 symmetric, mean, sd 1 0 minmaxmedian=mode 1 0 minmaxmean, sd minmax 1 0 CDF

35
246810 0 1 -1001020 0 1 01020304050 0 1 246810 0 1 2468 0 1 2468 0 1 0 20304050 0 1 246810 0 1 2468 0 1 min, max, mode mean, std range, quantile min, max min, max, mean min, mean Comparing p-boxes with maximum entropy distributions sample data, range min,max, mean,std p-box Maximum entropy solutions When you knowUse this shape {minimum, maximum}uniform {mean, standard deviation}normal {minimum, maximum, mode}beta {minimum, mean}exponential {minimum, maximum, mean}beta {min, max, mean, stddev}beta {min, max, some quantiles}piecewise uniform {mean, geometric mean}gamma

36
Maximum entropy’s problem Depends on the choice of scale Range for degradation rate Range for half life Same information, but incompatible results P-boxes are the same whichever scale is used North interprets Jaynes as saying that “two states of information that are judged to be equivalent should lead to the same probability assignments”. Maxent doesn’t do this! But PBA does.

37
Incertitude in data measurements Periodic observations When did the fish in my aquarium die during the night? Plus-or-minus measurement uncertainties Coarse measurements, measurements from digital readouts Non-detects and data censoring Chemical detection limits, studies prematurely terminated Privacy requirements Epidemiological or medical information, census data Theoretical constraints Concentrations, solubilities, probabilities, survival rates Bounding studies Presumed or hypothetical limits in what-if calculations

38
0246810 X 02468 X 02468 X 02468 X SkinnyPuffy Skinny data Puffy data [1.00, 2.00] [3.5, 6.4] [2.68, 2.98] [6.9, 8.8] [7.52, 7.67] [6.1, 8.4] [7.73, 8.35] [2.8, 6.7] [9.44, 9.99] [3.5, 9.7] [3.66, 4.58] [6.5, 9.9] [0.15, 3.8] [4.5, 4.9] [7.1, 7.9] Imprecise data
![X X X X SkinnyPuffy Skinny data Puffy data [1.00, 2.00] [3.5, 6.4] [2.68, 2.98] [6.9, 8.8] [7.52, 7.67] [6.1, 8.4] [7.73, 8.35] [2.8, 6.7] [9.44, 9.99] [3.5, 9.7] [3.66, 4.58] [6.5, 9.9] [0.15, 3.8] [4.5, 4.9] [7.1, 7.9] Imprecise data](http://images.slideplayer.com/8/1347333/slides/slide_38.jpg "X X X X SkinnyPuffy Skinny data Puffy data [1.00, 2.00] [3.5, 6.4] [2.68, 2.98] [6.9, 8.8] [7.52, 7.67] [6.1, 8.4] [7.73, 8.35] [2.8, 6.7] [9.44, 9.99] [3.5, 9.7] [3.66, 4.58] [6.5, 9.9] [0.15, 3.8] [4.5, 4.9] [7.1, 7.9] Imprecise data")
39
Empirical distribution of intervals Each side is cumulation of respective endpoints Represents both incertitude and variability 2468 Cumulative probability XX SkinnyPuffy 010 0 1 24680 Cumulative probability XX SkinnyPuffy

40
Uncertainty about the EDF 0 1 0246810 Cumulative probability Puffy X

41
Fitted to normals 01020 0 1 01020 Cumulative probability SkinnyPuffy XX Method of matching moments Regression approaches Maximum likelihood

42
Don’t have to specify the distribution Specifying distributions can be challenging Sensitivity analysis is very hard since it’s an infinite-dimensional problem Maximum entropy criterion erases uncertainty rather than propagates it Bounding is reasonable, but should reflect all available information

43
NOT interval or worst case analysis Yields fully probabilistic assessments Allows analysts to quantitatively describe –Means, Dispersions, Tail risks about output variables, but the descriptions may not be scalars if information is sparse Morally equivalent to sensitivity analysis

44
Heresies Independence should not be the default Maximum entropy criterion is obsolete Monte Carlo is partially obsolete Variability should be modeled with probability Incertitude should be modeled as intervals Imprecise probabilities can do both at once Sensitivity analysis is grossly insufficient

45
So is this really practical? Not only is it practical, it is essential Must distinguish incertitude and variability, otherwise the results are misleading and confusing to humans Consider some fundamental observations…

46
Neuroscience of risk perception

47
Risk aversion You’d get $1000 if a random ball from the urn is red, or you can just get $500 instead Which prize do you want? $500 EU is the same, but most people take the sure $500

48
Ambiguity aversion Two urns, both with red or blue balls But now one urn is opaque Get $1000 if a randomly drawn ball is red Which urn do you wanna draw from? A probabilist could explain your preference by saying your probability for red in the opaque urn is low Everyone chooses the transparent urn

49
Ambiguity (incertitude) Ambiguity aversion is ubiquitous in human decision making Ellsberg showed it is utterly incompatible with Bayesian norms Humans are wired to process incertitude separately and differently from variability
 Ambiguity aversion is ubiquitous in human decision making Ellsberg showed it is utterly incompatible with Bayesian norms Humans are wired to process incertitude separately and differently from variability")
50
Bayesian reasoning (poor) 12-18% correct If a test to detect a disease whose prevalence is 0.1% has a false positive rate of 5%, what is the chance that a person found to have a positive result actually has the disease, assuming that you know nothing about the person’s symptoms or signs? ___% Casscells et al. 1978 replicated in Cosmides and Tooby 1996

51
Bayesian reasoning (good) If a test to detect a disease whose prevalence is 1/1000 has a false positive rate of 50/1000, what is the chance that a person found to have a positive result actually has the disease, assuming that you know nothing about the person’s symptoms or signs? ___ out of ___. 76-92% correct 1 51 Casscells et al. 1978 replicated in Cosmides and Tooby 1996

52
Neuroscience of risk perception Instead of being divided into rational and emotional sides, the human brain has many special-purpose calculators (Marr 1982; Barkow et al. 1992; Pinker 1997, 2002) Instead of being divided into rational and emotional sides, the human brain has many special-purpose calculators (Marr 1982; Barkow et al. 1992; Pinker 1997, 2002) The format of sensory data triggers a calculator (e.g. Cosmides & Tooby 1996; Gigerenzer 1991) Different calculators give competing solutions, or calculate different components of total risk (e.g. Glimcher & Rustichini 2004 and references therein)
 Instead of being divided into rational and emotional sides, the human brain has many special-purpose calculators (Marr 1982; Barkow et al. 1992; Pinker 1997, 2002) The format of sensory data triggers a calculator (e.g. Cosmides & Tooby 1996; Gigerenzer 1991) Different calculators give competing solutions, or calculate different components of total risk (e.g. Glimcher & Rustichini 2004 and references therein).")
53
A calculator must be triggered Humans have an innate probability sense, but it is triggered by natural frequencies This calculator kicked in for the medical students who got the question in terms of natural frequencies, and they mostly solved it The mere presence of the percent signs in the question hobbled the other group

54
Multiple calculators can fire There are distinct calculators associated with –Probabilities and risk (variability) medical students –Ambiguity and uncertainty (incertitude) Hsu et al. –Trust and fairness Ultimatum Game Brain processes them differently –Different parts of the brain –Different chemical systems They can give conflicting responses

55
Neuroimagery Functional brain imaging suggests there is a general neural circuit that processes incertitude –Localized in amygdala and orbitofrontal cortex People with brain lesions in these spots –Are insensitive to the degree of incertitude –Do not exhibit ambiguity aversion –Make decisions according to Bayesian norms Hsu et al. 2005

56
Ambiguity processing Neuroimagery and clinical psychometrics show humans distinguish incertitude and variability –Normal feature of the human brain –Especially focused on the worst case –Makes us ask how bad it could be and neglect probability Probabilists traditionally use equiprobability to model incertitude which confounds the two

57
Conclusions Probability has an inadequate model of ignorance Interval (worst case) analysis has an inadequate model of dependence Probability bounds analysis corrects both and does things sensitivity studies cannot PBA is much simpler computationally than IP
 analysis has an inadequate model of dependence Probability bounds analysis corrects both and does things sensitivity studies cannot PBA is much simpler computationally than IP")
58
Take-home messages You don’t have to make a lot of assumptions to get quantitative results PBA merges worst case and probabilistic analyses in a way that’s faithful to both Calculations are guaranteed (you can still be wrong, but the method won’t be the reason)
")
59
Many applications ODE dynamics in a chemostat Global climate change forecasts Engineering design Safety of engineered systems (e.g., bridges) Human health Superfund risk analyses Conservation biology extinction/reintroduction Wildlife contaminant exposure analyses Australia Belgium Canada Denmark France Germany India Sweden Switzerland United Kingdom United States Texas Georgia Florida New York Virginia New Mexico NASA, SNL, LANL, VT, UM, GT EPA PIK EPA, DEC
 Human health Superfund risk analyses Conservation biology extinction/reintroduction Wildlife contaminant exposure analyses Australia Belgium Canada Denmark France Germany India Sweden Switzerland United Kingdom United States Texas Georgia Florida New York Virginia New Mexico NASA, SNL, LANL, VT, UM, GT EPA PIK EPA, DEC")
60
Several software implementations UC add-in for Excel (NASA, beta 2011) RAMAS Risk Calc (EPRI, NIH, commercial) Statool (Dan Berleant, freeware) Constructor (Sandia and NIH, freeware) Pbox.r library for R PBDemo (freeware) Williamson and Downs (1990)
 RAMAS Risk Calc (EPRI, NIH, commercial) Statool (Dan Berleant, freeware) Constructor (Sandia and NIH, freeware) Pbox.r library for R PBDemo (freeware) Williamson and Downs (1990)")
61
Acknowledgments National Institutes of Health (NIH) Electric Power Research Institute (EPRI) Sandia National Laboratories National Aeronautics and Space Administration (NASA)
 Electric Power Research Institute (EPRI) Sandia National Laboratories National Aeronautics and Space Administration (NASA)")
62
End

63
Relax one axiom IP satisfies all the Kolmogorov axioms Avoid sure loss and are ‘rational’ in the Bayesian sense (except that agents are not forced to either buy or sell any offered gamble) Relaxes one decision theory axiom: assumption that we can always compare any two gambles Richer mathematics, wider array of applications
 Relaxes one decision theory axiom: assumption that we can always compare any two gambles Richer mathematics, wider array of applications")
64
Comparing IP to Bayesian approach “Uncertainty of probability” is meaningful Operationalized as the difference between the max buying price and min selling price If you know all the probabilities (and utilities) perfectly, then IP reduces to Bayes Axioms identical except IP doesn’t use completeness Bayesian rationality implies not only avoidance of sure loss & coherence, but also the idea that an agent must agree to buy or sell any bet at one price
 perfectly, then IP reduces to Bayes Axioms identical except IP doesn’t use completeness Bayesian rationality implies not only avoidance of sure loss & coherence, but also the idea that an agent must agree to buy or sell any bet at one price")
65
Bayes fails incertitude Traditional probability theory doesn’t account for gross uncertainty correctly Output precision depends strongly on the number inputs and not so much on their shapes The more inputs, the tighter the answer

66
Uniform Probability A few grossly uncertain inputs

67
Uniform A lot of grossly uncertain inputs... Where does this surety come from? What justifies it? Probability

68
“Smoke and mirrors” certainty Probability makes certainty out of nothing It has an inadequate model of ignorance Probability bounds analysis gives a vacuous answer if all you give it are vacuous inputs

69
Wishful thinking Risk analysts often make assumptions that are convenient but are not really justified: 1.All variables are independent of one another 2.Uniform distributions model incertitude 3.Distributions are stationary (unchanging) 4.Specifications are perfectly precise 5.Measurement uncertainty is negligible
 4.Specifications are perfectly precise 5.Measurement uncertainty is negligible")
70
You don’t have to do this Removing wishful thinking creates a p-box 1. Don’t have to assume any dependence at all 2. An interval can be a better model of incertitude 3. P-boxes can enclose non-stationary distributions 4. Can handle imprecise specifications 5. Measurement data with plus-minus, censoring

71
Uncertainties expressible with p-boxes Sampling uncertainty –Confidence bands, confidence structures Measurement incertitude –Intervals Uncertainty about distribution shape –Constraints (non-parametric p-boxes) Surrogacy uncertainty –Modeling
 Surrogacy uncertainty –Modeling")
72
Can uncertainty swamp the answer? Sure, if uncertainty is huge This should happen (it’s not “unhelpful”) If you think the bounds are too wide, then put in whatever information is missing If there is no more information, what justifies your belief? Who are you trying to fool?
 If you think the bounds are too wide, then put in whatever information is missing If there is no more information, what justifies your belief. Who are you trying to fool .")
73
Software demonstration

86
Assumes independence Makes no dependence assumption

88
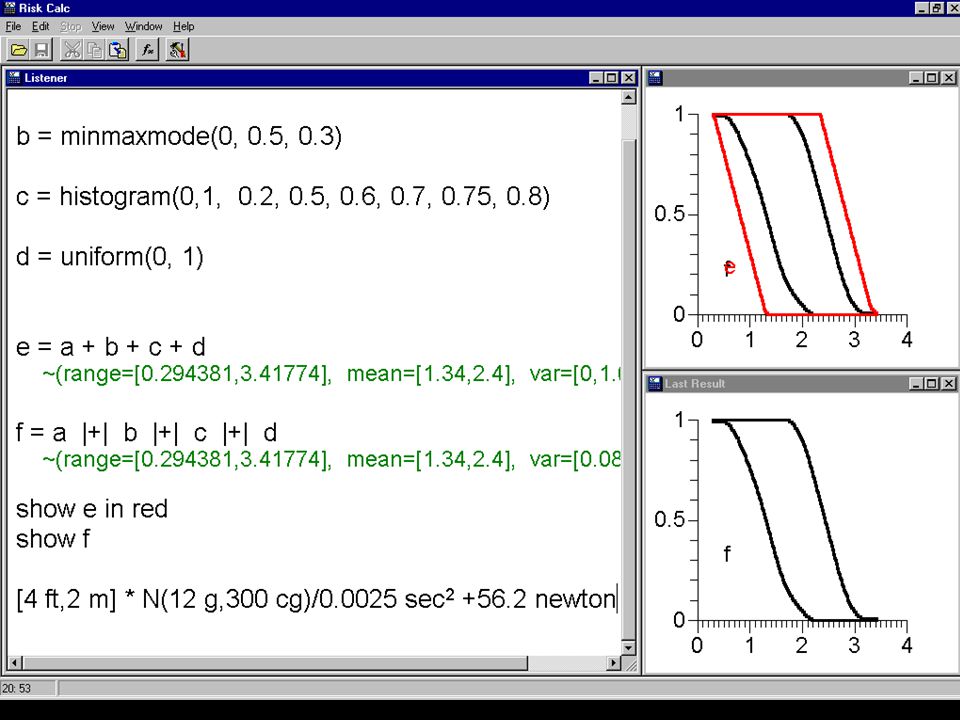
Risk Calc finds unit mistakes Given the input [2 m, 4 ft] * N(12 g, 300 cm) / 0.0025 sec + 56.2 N Risk Calc detects all three errors –inverted interval –[mass] and [length] don't conform –[length] [mass] [time] -1 and [force] don't conform
![Risk Calc finds unit mistakes Given the input [2 m, 4 ft] * N(12 g, 300 cm) / sec N Risk Calc detects all three errors –inverted interval –[mass] and [length] don t conform –[length] [mass] [time] -1 and [force] don t conform](http://images.slideplayer.com/8/1347333/slides/slide_88.jpg "Risk Calc finds unit mistakes Given the input [2 m, 4 ft] * N(12 g, 300 cm) / sec N Risk Calc detects all three errors –inverted interval –[mass] and [length] don t conform –[length] [mass] [time] -1 and [force] don t conform")
89
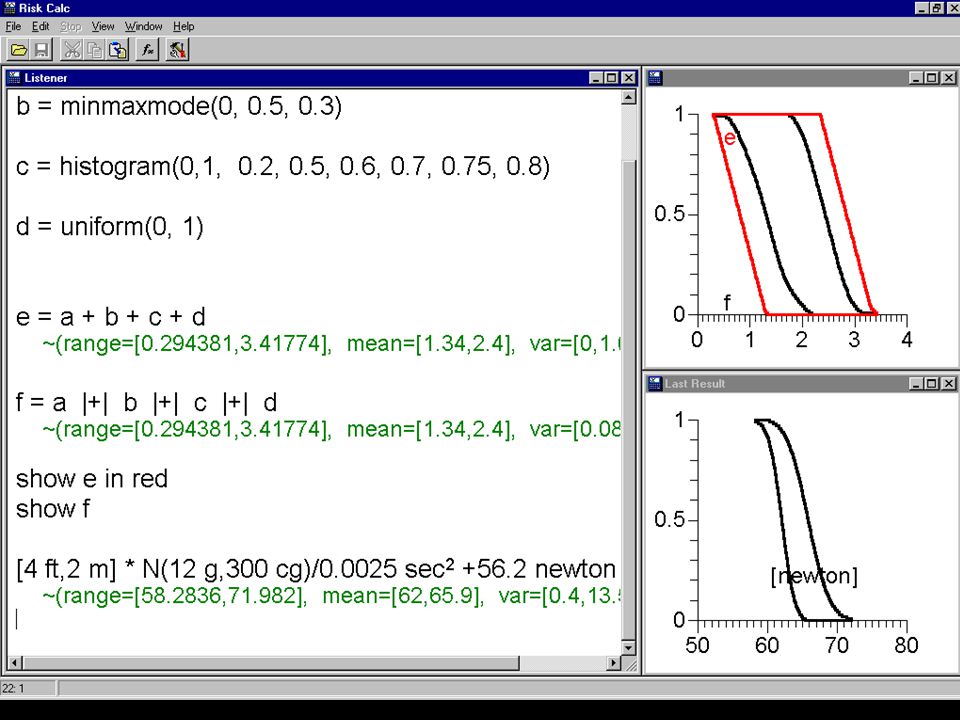
Risk Calc finishes calculations Given 2 ft + 4 m, Risk Calc computes 4.61 m Given [4 ft, 2 m]*2 wids * N(12 g, 300 cg) /0.0025 sec 2 wid +56.2 N Risk Calc computes the right answer because it knows –feet can be converted to meters –distance mass time 2 can be converted to newtons –N means both “normal distribution” and “newtons” –a “wid” and “wids” can cancel –centigrams can be converted to grams
![Risk Calc finishes calculations Given 2 ft + 4 m, Risk Calc computes 4.61 m Given [4 ft, 2 m]*2 wids * N(12 g, 300 cg) / sec 2 wid N Risk Calc computes the right answer because it knows –feet can be converted to meters –distance mass time 2 can be converted to newtons –N means both normal distribution and newtons –a wid and wids can cancel –centigrams can be converted to grams](http://images.slideplayer.com/8/1347333/slides/slide_89.jpg "Risk Calc finishes calculations Given 2 ft + 4 m, Risk Calc computes 4.61 m Given [4 ft, 2 m]*2 wids * N(12 g, 300 cg) / sec 2 wid N Risk Calc computes the right answer because it knows –feet can be converted to meters –distance mass time 2 can be converted to newtons –N means both normal distribution and newtons –a wid and wids can cancel –centigrams can be converted to grams")
Similar presentations























 is sufficient for >")







