Download presentation
Presentation is loading. Please wait.

1
Structural Joins: A Primitive for Efficient XML Query Pattern Matching Shurug Al-Khalifa, H. V. Jagadish, Nick Koudas, Jignesh M. Patel, Divesh Srivastava, Yuqing Wu Modified from talk created by Sandhya Rani Are Prabhas Kumar Samanta

2
Introduction XML: Extensible Markup Language Documents have tags giving extra information about sections of the document E.g XML Introduction … Extensible, unlike HTML Users can add new tags, and separately specify how the tag should be handled for display

3
A-101 Downtown 500 A-101 Johnson Introduction

4
Comparison with Relational Data Inefficient: tags, which in effect represent schema information, are repeated Better than relational tuples as a data- exchange format. Unlike relational tuples, XML data is self- documenting due to presence of tags. Non-rigid format: tags can be added Allows nested structures Wide acceptance, not only in database systems, but also in browsers, tools, and applications

5
Structure of XML Data Tag: label for a section of data Element: section of data beginning with and ending with matching Elements must be properly nested Proper nesting … …. Improper nesting … …. Mixture of text with sub-elements is legal in XML. e.g: This account is seldom used any more. A-102

6
More features of XML Schema Attributes specified by xs:attribute tag: adding the attribute use = “required” means value must be specified Key constraint: “account numbers form a key for account elements under the root bank element: Foreign key constraint from depositor to account:

7
Querying and Transforming XML Data Translation of information from one XML schema to another Querying on XML data Standard XML querying/translation languages Xpath Simple language consisting of path expressions XSLT Simple language designed for translation from XML to XML and XML to HTML XQuery An XML query language with a rich set of features

8
Tree Model of XML Data Query and transformation languages are based on a tree model of XML data An XML document is modeled as a tree, with nodes corresponding to elements and attributes

9
XPath o XPath is used to address (select) parts of documents using path expressions o A path expression is a sequence of steps separated by “/” o Result of path expression: set of values that along with their containing elements/attributes match the specified path e.g /bank-2/customer/customer_name evaluated on the bank-2 data Joe Mary e.g. /bank-2/customer/customer_name/text( ) returns the same names, but without the enclosing tags
 returns the same names, but without the enclosing tags.")
10
XPath (Cont.) The initial “/” denotes root of the document (above the top- level tag) Path expressions are evaluated left to right Each step operates on the set of instances produced by the previous step Selection predicates may follow any step in a path, in [ ] E.g. /bank-2/account[balance > 400] returns account elements with a balance value greater than 400 /bank-2/account[balance] returns account elements containing a balance subelement
![XPath (Cont.) The initial / denotes root of the document (above the top- level tag) Path expressions are evaluated left to right Each step operates on the set of instances produced by the previous step Selection predicates may follow any step in a path, in [ ] E.g.](http://images.slideplayer.com/42/11324903/slides/slide_10.jpg "/bank-2/account[balance > 400] returns account elements with a balance value greater than 400 /bank-2/account[balance] returns account elements containing a balance subelement.")
11
XPath (Cont.) Attributes are accessed using “@” e.g /bank-2/account[balance > 400]@account_number returns the account numbers of accounts with balance > 400 Anna Smith
 Attributes are accessed e.g /bank-2/account[balance > returns the account numbers of accounts with balance > 400 Anna Smith")
12
More XPath Features “//” can be used to skip multiple levels of nodes E.g. /bank-2//customer_name finds any customer_name element anywhere under the /bank-2 element, regardless of the element in which it is contained. A step in the path can go to parents, siblings, ancestors and descendants of the nodes generated by the previous step, not just to the children “//”, described above, is a short from for specifying “all descendants” “..” specifies the parent doc(name) returns the root of a named document
 returns the root of a named document.")
13
FLWOR Syntax in XQuery find all accounts with balance > 400, with each result enclosed in an.. tag for $x in /bank-2/account let $acctno := $x/@account_number where $x/balance > 400 return { $acctno } Items in the return clause are XML text unless enclosed in {}, in which case they are evaluated Xpath as sub-expressions Allows joins, and complex aggregation (with group by using subqueries) which Xpath does not support
 which Xpath does not support.")
14
Efficient evaluation of Xpath PC/AD steps

15
Motivation Query : book[title='XML'] //author[. ='jane']
![Motivation Query : book[title= XML ] //author[. = jane ]](http://images.slideplayer.com/42/11324903/slides/slide_15.jpg "Motivation Query : book[title= XML ] //author[. = jane ]")
16
Query Tree book[title='XML'] //author[.='jane']
![Query Tree book[title= XML ] //author[.= jane ]](http://images.slideplayer.com/42/11324903/slides/slide_16.jpg "Query Tree book[title= XML ] //author[.= jane ]")
17
Decomposition Of Query Tree

18
Introduction XQuery Specify patterns of Selection Predicate having Tree Structural Relationship. e.g. book[title = ‘XML’] // author[. = ‘jane’] The primitive tree structured relationships Parent-child : (book, title), (title,XML), (author, jane) Ancestor-descendant : (book, author) Finding all occurrences of these relationships is a core operation for XML query processing.
, (title,XML), (author, jane) Ancestor-descendant : (book, author) Finding all occurrences of these relationships is a core operation for XML query processing..")
19
Different ways of matching structural relationships Tuple-at-a-time approach ➢ Tree traversal ➢ Using child & parent pointers ➢ Inefficient because complete pass through data Pointer based approach ➢ Maintain (Parent,Child) pairs & identifying (ancestor,descendants) : High time complexity ➢ Maintain (ancestor,descendant) pairs : High space complexity ➢ Either case is infeasible
 pairs & identifying (ancestor,descendants) : High time complexity ➢ Maintain (ancestor,descendant) pairs : High space complexity ➢ Either case is infeasible")
20
Solution: Set-at-a-time approach Uses mechanism ➢ Positional representation of occurrences of XML elements and string values ➢ Element 3 tuple (DocId, StartPos:EndPos, LevelNum) String 3 tuple (DocId, StartPos, LevelNum)
 String 3 tuple (DocId, StartPos, LevelNum)")
21
Positional Representation

22
Structural Relationship Test Element E1(D1,S1:E1,L1) Element E2(D2,S2:E2,L2) If D1=D2, S1<S2 and E2<E1 E1-E2 is ancestor-descendant If D1=D2, S1<S2, E2<E1 and L1+1=L2 E1-E2 is parent-child
 Element E2(D2,S2:E2,L2) If D1=D2, S1<S2 and E2<E1 E1-E2 is ancestor-descendant If D1=D2, S1<S2, E2<E1 and L1+1=L2 E1-E2 is parent-child")
23
Structural Joins Join Algorithms for matching Structural Relationship tree-merge and stack-tree Input: Lists of tree nodes sorted by (DocId, StartPos) Output: Lists of sorted results joined according desired structural relationship. Use in XML Query Pattern matching Query Tree Pattern decompose binary structural relationships. Match each relationship with XML database ‘Stitching’ together basic matches

24
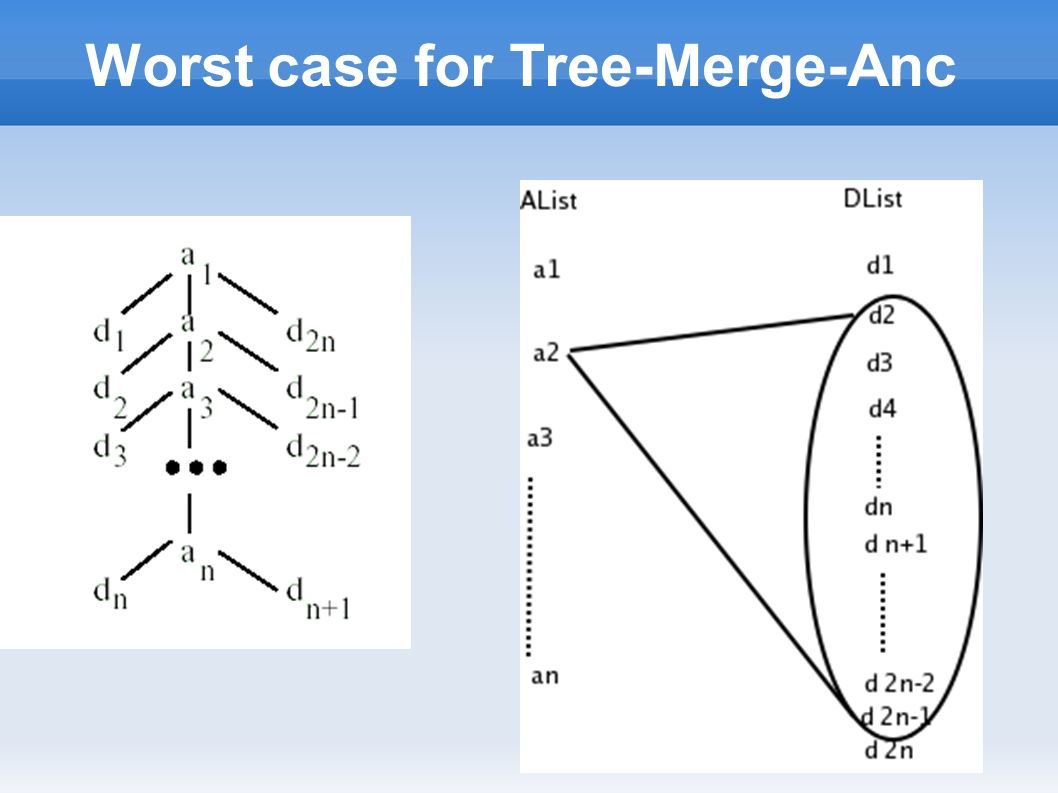
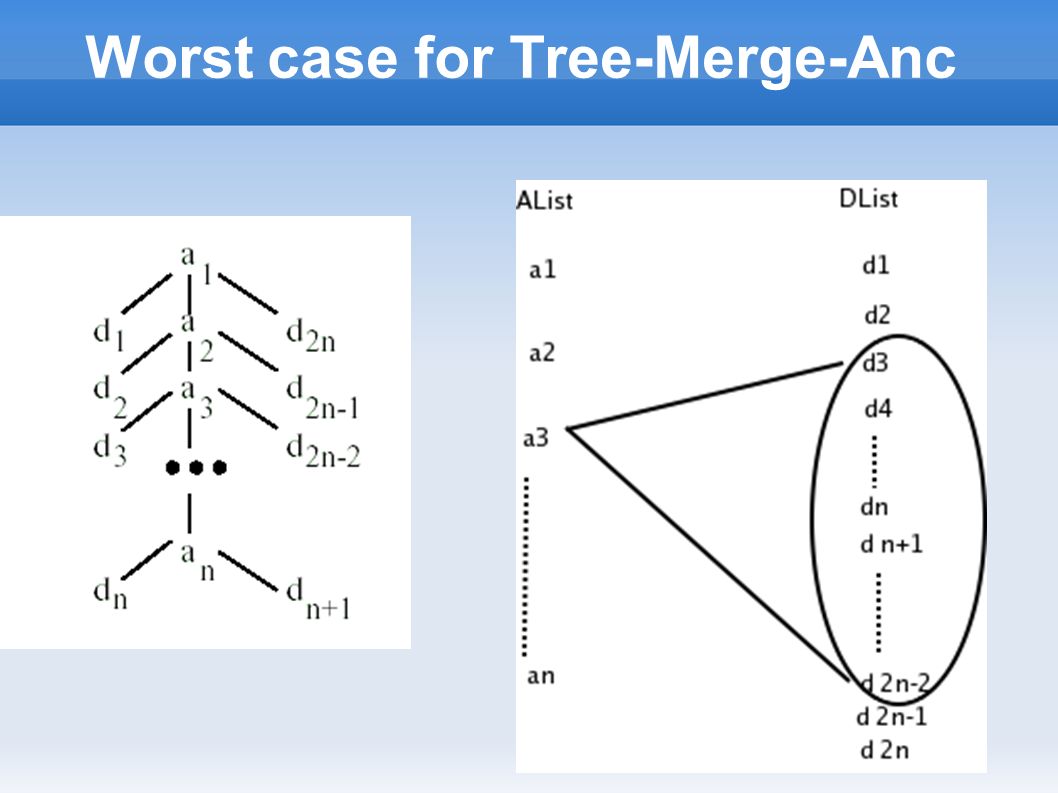
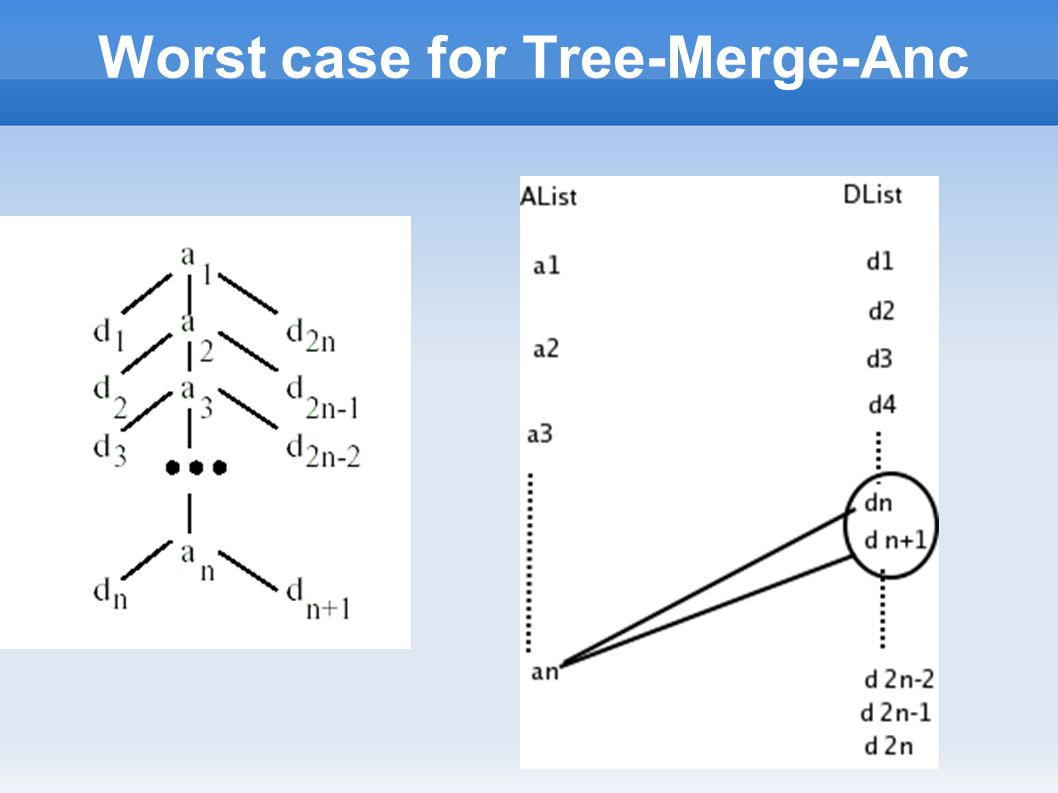
Algorithm Tree-Merge-Anc Output : ordered by ancestors Algorithm : Loop through list of ancestors in increasing order of startPos ➢ For each ancestor, skip over unmatchable descendants ➢ check for ancestor-descendant relationship ( or parent-child relationship ) ➢ Append result to output list
 ➢ Append result to output list")
25
Example Alist={Title_1} Dlist={Book_1, XML_1, Jane_1} Title_1 Skips Book_1 as it starts before Title_1. Pairs with XML_1 Do not consider Jane_1 as it ends after Title_1. Book Author Jane Title XML AList Title_1 DList Book_1 XML_1 Jane_1

26
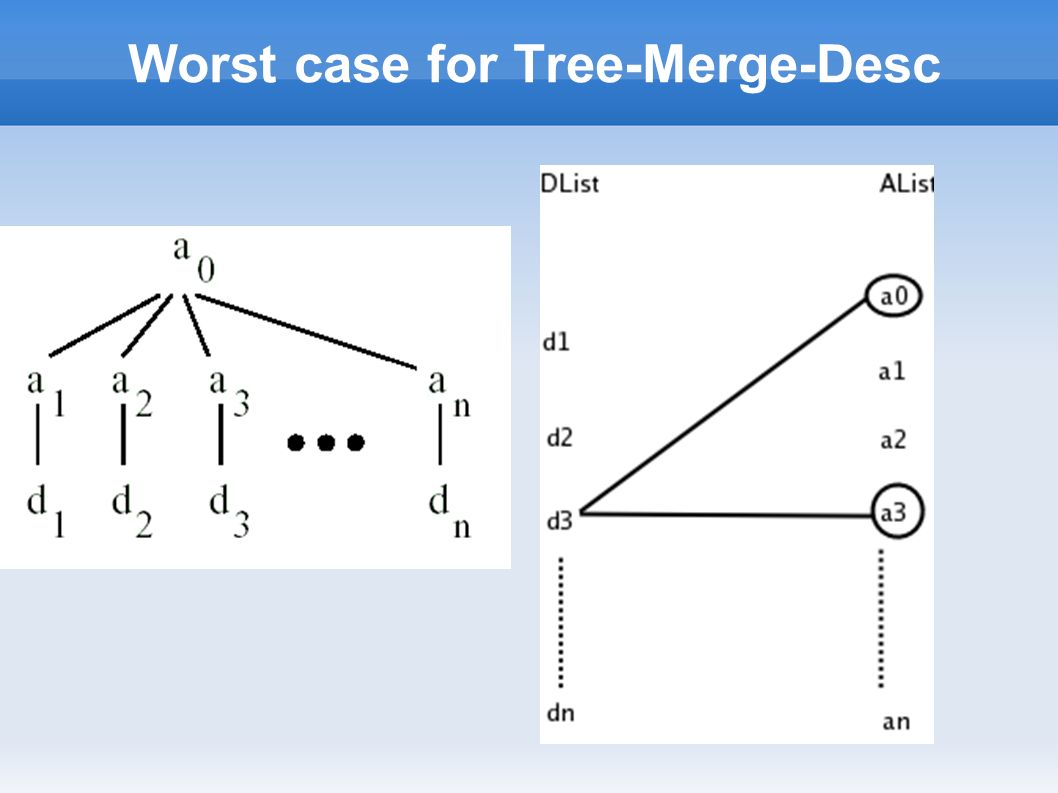
Worst case for Tree-Merge-Anc

30
Tree-Merge Join Detail Algorithm (O/p Sorted Ancestor/Parent order)
 ")
31
Time and Space Complexity The space and time complexity of Tree-Merge- Anc are O(|AList|+|Dlist|+|Outputlist|) for ancestor-descendant structural relationships Optimal But result sorted on ancestors Cost of resorting on descendants can be significant But for P-C relationship, Tree-Merge-Anc complexity is O(|AList|+|Dlist| 2 ) even if OutputList is linear in |Alist|,
 for ancestor-descendant structural relationships Optimal But result sorted on ancestors Cost of resorting on descendants can be significant But for P-C relationship, Tree-Merge-Anc complexity is O(|AList|+|Dlist| 2 ) even if OutputList is linear in |Alist|,")
32
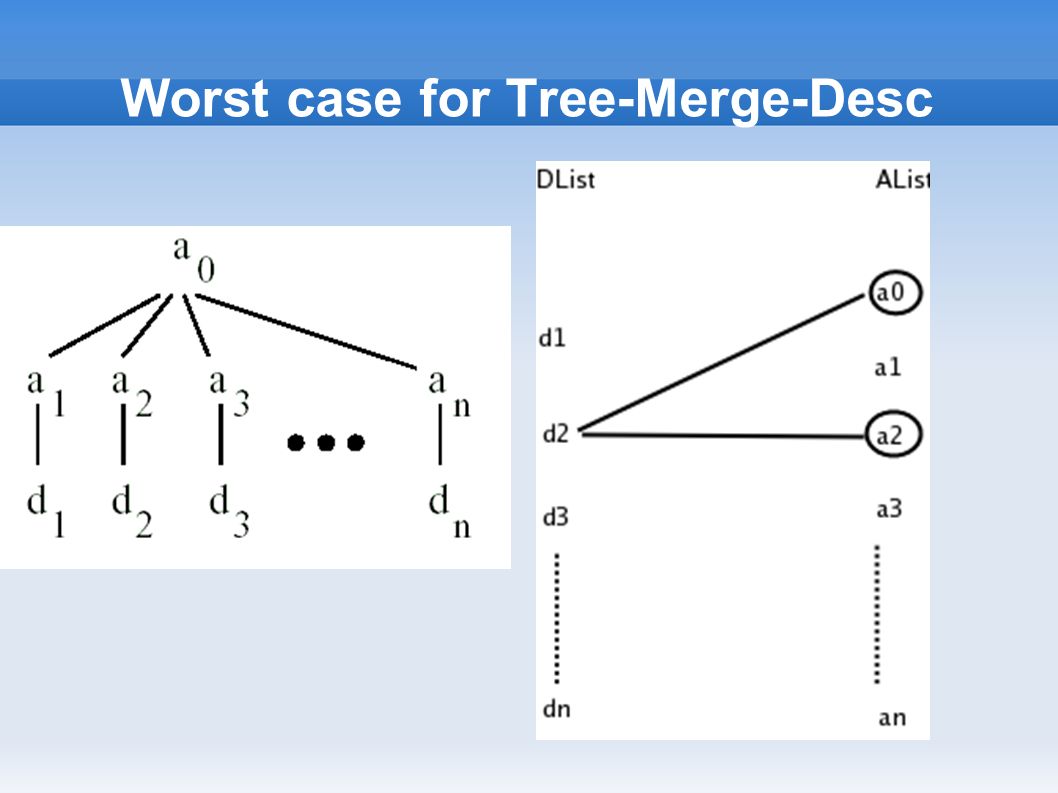
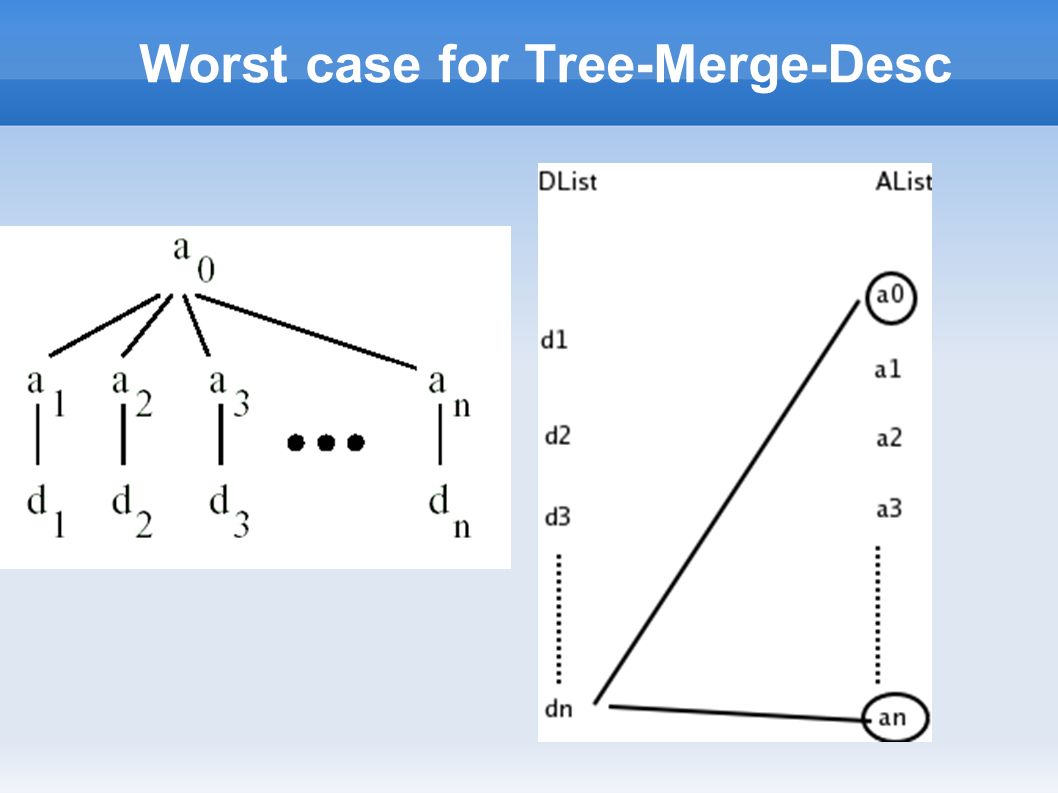
Tree-Merge-Desc Algorithm Output : ordered by descendants Algorithm : Loop over Descendants list in increasing order of startPos ➢ For each descendant, skip over unmatchable ancestors ➢ check for ancestor-descendant relationship ( or parent-child relationship ) ➢ Append result to output list
 ➢ Append result to output list")
33
Example Alist={Book_1, Title_1} Dlist={Book_1, XML_1, Jane_1} Book_1 doesn't have any matching a. XML_1 Pairs with Book_1, Title_1 Jane_1 Pairs with Book_1 Do not consider Title_1 (as Title_1 starts before Jane_1) Book Author Jane Title XML AList Book_1 Title_1 DList Book_1 XML_1 Jane_1
 Book Author Jane Title XML AList Book_1 Title_1 DList Book_1 XML_1 Jane_1.")
34
Worst case for Tree-Merge-Desc

38
Tree-Merge Join Algorithm (O/p Sorted Descendent/Child order)
")
39
Time and Space Complexity The time complexity of Tree-Merge-Desc are O(|AList|+|Dlist|+|Outputlist| 2 ) for ancestor- descendant structural relationships But not so bad in practice
 for ancestor- descendant structural relationships But not so bad in practice")
40
Stack-Tree Algorithm Basic idea: depth first traversal of XML tree – takes linear time with stack size = depth of tree – all ancestor-descendant relationships appear on stack during traversal Main problem: do not want to traverse the whole database, just nodes in A-list/D- list

41
Stack-Tree-Desc. (O/p sorted by Descendants) Stack Contains Elements that can be ancestor of remaining Dlist elements Consider elements from Alist and Dlist one by one If top can not be ancestors, POP it out. If new 'a' has potential to be ancestor add to Stack Else new 'd' will pair with all elements for Stack (Bottom to Top )
 Stack Contains Elements that can be ancestor of remaining Dlist elements Consider elements from Alist and Dlist one by one If top can not be ancestors, POP it out. If new a has potential to be ancestor add to Stack Else new d will pair with all elements for Stack (Bottom to Top ).")
42
Example a1a1 a2a2 a3a3 d1d1 d6d6 d3d3 d2d2 d5d5 d4d4 AList DList a1a1 a1a1 a3a3 a2a2 a1a1 d2d2 d5d5 d4d4 d3d3 d1d1 d6d6 a1 a2a2 a3a3 d1d1 a3a3 d2d2 a2a2 a1a1 d3d3 Order d4d4 d6d6 d5d5 Output a1,d1 a1,d2 a2,d2 a1,d3 a2,d3 a3,d3 a1,d4 a2,d4 a3,d4 Pop a3 a1,d5 a2,d5 Pop a2 a1,d6

43
Stack-Tree Desc. (O/p sorted by Descendants)
")
44
Time and Space Complexity The time complexity of Stack-Tree-Desc is O(|AList|+|Dlist|+|Outputlist|) for ancestor- descendant as well as parent-child structural relationships IO complexity of Stack-Tree-Desc is O(|AList|/B + |Dlist|/B + |Outputlist|/B) where B is the blocking factor, for AD and PC relationships
 for ancestor- descendant as well as parent-child structural relationships IO complexity of Stack-Tree-Desc is O(|AList|/B + |Dlist|/B + |Outputlist|/B) where B is the blocking factor, for AD and PC relationships")
45
Stack-Tree-Asc Output ordered by ancestors Basic problem: Results from a particular descendant cannot be output immediately - Later descendants may match earlier ancestor Solution: keep lists of matching descendant nodes with each stack node Self-list Descendants that match this node Add descendant node to self-lists of all matching ancestor nodes Inherit list Inherited from descendants already popped from stack, to be output after self-list matches are output

46
Example a1a1 a2a2 a3a3 d1d1 d6d6 d3d3 d2d2 d5d5 d4d4 AList DList a1a1 a1a1 a3a3 a2a2 a1a1 d2d2 d5d5 d4d4 d3d3 d1d1 d6d6 a1 a2a2 a3a3 a2,d 2 a1,d 2 a1,d 1 a3,d 3 a2,d 3 a1,d 3 a3,d 4 a1,d 4 a2,d 4 Pop a3 a3,d 3 a3,d 4 a2,d 5 a1,d 5 Pop a2 a2,d2|a2,d3|a2,d4|a2,d5|a3,d3|a3, d4 OUTPUT: (a1,d1),(a1,d2),(a1,d3),(a1,d4),(a1,d5),(a1,d6), a1,d 6 (a2,d2),(a2,d3),(a2,d4),(a2,d5),(a3,d3),(a3,d4) SELFLIST INHERIT-LIST
,(a1,d2),(a1,d3),(a1,d4),(a1,d5),(a1,d6), a1,d 6 (a2,d2),(a2,d3),(a2,d4),(a2,d5),(a3,d3),(a3,d4) SELFLIST INHERIT-LIST")
47
Algorithm

48
Time and Space Complexity of Stack-Tree-Anc The time complexity of Stack-Tree-Anc is O(|AList|+|Dlist|+|OutputList|) for ancestor- descendant as well as parent-child structural relationships IO complexity of Stack-Tree-Desc is O(|AList|/B + |Dlist|/B + |Outputlist|/B) where B is the blocking factor, for AD and PC relationships Requires proper handling of list operations
 for ancestor- descendant as well as parent-child structural relationships IO complexity of Stack-Tree-Desc is O(|AList|/B + |Dlist|/B + |Outputlist|/B) where B is the blocking factor, for AD and PC relationships Requires proper handling of list operations")
49
Experimental Evaluation Implemented the join algorithms in the TIMBER XML query engine. TIMBER is an native XML query engine that is built on top of SHORE Data set consist of 6.3m element node 800MB of XML document in text format Resuts are avg. of multiple run (warm cache)
.")
51
Query used QS1 to QS6 are simple structural relationship queries QC1 and QC2 are complex chain queries evaluated using pipeline

52
performance

53
contd..

54
Holistic Twig Joins: Optimal XML Pattern Matching Author: Nicolas Bruno, Nick Koudas, Divesh Srivastava Source: ACM SIGMOD '2002 June4-6, Madison, Wisconsin, USA

55
Introduction XML Query: matching XML data with a tree structured pattern Previous attempts decompose query into small pieces and solve them separately complex optimization problem Intermediate results can be large This paper propose a novel holistic twig join approach for matching XML query twig patterns, where no large intermediate results are created - ((book title) XML) (year 2000) - (((book year) 2000) title) XML many other possibilities…
 XML) (year 2000) - (((book year) 2000) title) XML many other possibilities…")
56
Twig Pattern Query twig patterns author fn ln janedoe Given a query twig pattern Q and an XML database D, compute the set of all matches for Q on D.

57
Holistic Join It also uses a chain of linked stacks to compactly represent partial results to individual query root-to-leaf paths. Path Stack Twig Stack Each node q in query has associated: A stream T q, with the positions of the elements corresponding to node q, in increasing “left” order. A stack S q with a compact encoding of partial solutions (chained). XML fragment Query Matches Stacks
. XML fragment Query Matches Stacks.")
58
PathStack: Holistic Path Queries Repeatedly constructs stack encodings of partial solutions by iterating through the streams T q. Stacks encode the set of partial solutions from the current element in T q to the root of the XML tree. WHILE (!eof) qN = “getMin(q)” clean stacks push T qN ’s first element to S qN IF qN is a leaf node, expand solutions
 qN = getMin(q) clean stacks push T qN ’s first element to S qN IF qN is a leaf node, expand solutions.")
59
59 PathStack Example

60
Twig Queries Naive adaptation of PathStack. Solve each root-to-leaf path independently. Merge-join each intermediate result. Problem: Many intermediate results might not be part of the final answer.

61
Twig-Stack Compute only partial solutions that are guaranteed to extend to a final solution. Before pushing N in stack Sn, it ensure – N has a descendant present in each of the stream Tn for n ∈ children(N) Merge partial solutions to obtain all matches.
 Merge partial solutions to obtain all matches..")
62
Example author fn ln janedoe

63
Questions ? Thank You

64
ORDPATHs: Insert-Friendly XML Node Labels Author : Patrick O’Neil, Elizabeth O’Neil1, Shankar Pal, Istvan Cseri, Gideon Schaller, Nigel Westbury Source : ACM SIGMOD 2004, June 13–18, 2004, Paris, France

65
Labelling schemes for XML trees Global order Each node is assigned a number that represents the node’s absolute position in the document. Dewey Order Each node is assigned a vector that represents the path from the document’s root to the node.

66
Problems ?? Works well for static XML data Poor performance for arbitrary insert and deletion Relabelling of many nodes is necessary

67
ORDPATHs Hierarchical labelling scheme like Dewey Provides efficient structural modification in xml data 1 1.11.31.5 Insert node from left and right 1 1.11.31.51.-1 1.7

68
More Insertion Example 1 1.11.31.5 Arbitrary Insert node 1 1.1 1.2.1 1.3 1.5 1 1.11.2.11.3 1.5 Arbitrary Insert node 1 1.2.-11.2.11.3 1.5 1.1

Similar presentations












 Uma Sawant (05305903)>")






