Download presentation
Presentation is loading. Please wait.

1
Document Clustering with Prior Knowledge Xiang Ji et al. Document Clustering with Prior Knowledge. SIGIR 2006 Presenter: Suhan Yu

2
Traditional Clustering Methods Methods –K-Means –Ratio Cut –Average Association –Normalized Cut –Min-Max Cut Important question: –For each given data set, there are always many possible ways of partitioning the data set.

3
Traditional Clustering Methods Related Work on Semi-Supervised Learning: –Wagstaff et al. introduced two types of constraints: “must link”, “cannot link” –Basu, et al. developed a semi-supervised K-means that make use of labeled data to generate initial seed cluster, and to guide the clustering process.

4
Normalized Cut J. Shi and J. Malik. Normalized cuts and image segmentation. IEEE Transaction on Pattern Analysis and Machine Intelligence, 2000. Model the given document set using a undirected graph G(V,E,W) –V: vertex set, represents a document vector –E: edge set, assigned a weight to reflect the similarity between the two documents. –W: graph affinity matrix
 –V: vertex set, represents a document vector –E: edge set, assigned a weight to reflect the similarity between the two documents. –W: graph affinity matrix.")
5
Normalized Cut Measures how tightly the cluster S is connected with the rest of the data set. Measures how compact the entire data set is.

6
Normalized Cut Let be the indicator vector of the cluster,and each element takes a binary value {1,0} Then we get: 1 3 2 D=diagonal matrix

7
Normalized Cut 1 3 2 4 1 3 2 4 Minimize the cost function

8
Normalized Cut

10
Incorporating Prior Knowledge The prior knowledge is provided in the form of indicating several pairs of documents which the user whishes to be grouped into the same cluster. –Constraint vector:

11
The flow path of CNC Create the graph affinity matrix in which each element represents the similarity between the two documents. Compute the diagonal matrix D Form the constraint matrix U by the user Form the matrix and compute its K smallest eigenvalues and the corresponding eigenvectors. Project each document into the eigen-space spanned by the K eigenvectors. Apply K-means algorithm to find the K document clusters within this eigen-space

12
Data description This paper evaluated the performance of their document clustering model using two data set: Reuters-21578 and 20 Newsgroups document corpora. –Newsgroups data set contains 20000 documents that were collected from 20 newsgroups in the public domain.

13
Evaluation Given the two set of document clusters C, C’, their mutual information metric is defined as: 0: two sets are independent 1: two sets are identical

14
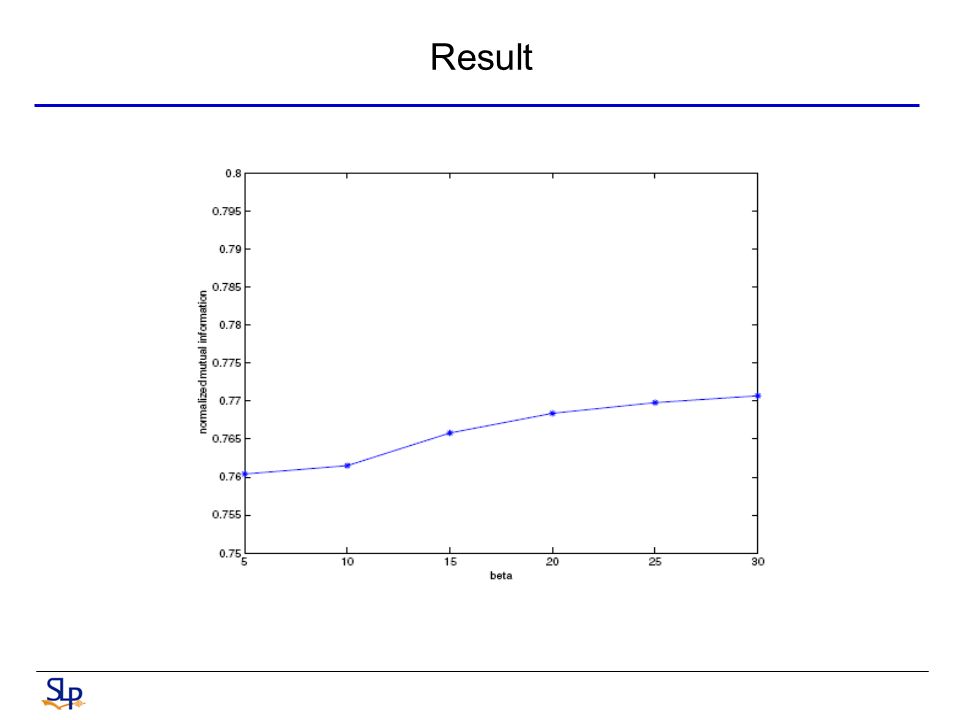
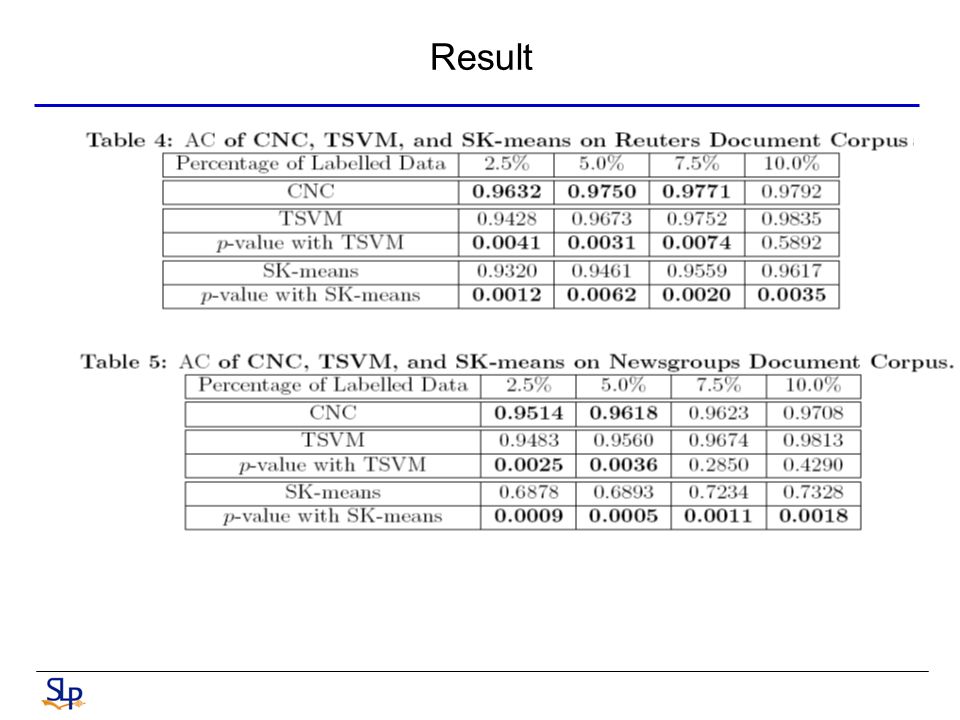
Result

17
Conclusion This paper proposed a constrained spectral clustering method (CNC) to incorporate user’s prior knowledge during the document cluster analysis. CNC model is a very effective semi-supervised document clustering tool, especially with very low amount of training samples. CNC model did not form constraints for prior knowledge related to cannot-link constraint.

Similar presentations




 edge (u,v) denotes similarity between u and v weighted.>")















