Download presentation
Presentation is loading. Please wait.

1
Bigtable A Distributed Storage System for Structured Data

2
Abstract Distributed Storage System Petabytes of Structured Data Web indexing, Google Earth, Google Finance……

3
1. Introduction Goals: wide applicability, scalability, high performance, high availability Not full relational data model Row + Column Name Uninterpreted Strings

4
2. Data Model A sparse, distributed, persistent multi- dimensional sorted map (row: string, column: string, time:int64)--->string
--->string.")
5
Rows Row keys are arbitrary strings(up to 64KB) Atomic read and write Lexicographic order Tablet is the unit of distribution and balancing
 Atomic read and write Lexicographic order Tablet is the unit of distribution and balancing")
6
Column Families Column keys are grouped into sets called column families Same type data(compressed together) Column Key family:qualifier Access control and both disk and memory accounting are performed at the column- family level
 Column Key family:qualifier Access control and both disk and memory accounting are performed at the column- family level")
7
Timestamp 64-bit integer(us) Each cell can contain multiple versions of the same data Assigned by Bigtable or client Data are stored in decreasing timestamp order Garbage collect
 Each cell can contain multiple versions of the same data Assigned by Bigtable or client Data are stored in decreasing timestamp order Garbage collect")
8
3. API Create and delete tables and column families Change cluster, table and column family metadata, such as control rights Read and write values in Bigtable

9
Feature Single-row transaction Client-supplied scripts(Sawzall) for data processing(only reading)
 for data processing(only reading)")
10
4. Building Blocks Google File System(GFS) Operates in a shared pool of machines Depends on a cluster management system for scheduling jobs, managing resources, dealing with machine failures, and monitoring machine status
 Operates in a shared pool of machines Depends on a cluster management system for scheduling jobs, managing resources, dealing with machine failures, and monitoring machine status.")
11
SSTable and Chubby SSTable – Block – block index Chubby – distributed lock service – Paxos – dir and small files can be used as lock – session/session lease – callback

12
Chubby Bigtable use Chubby for a variety of tasks – ensure one active master at any time – store bootstrap location – discover tablet servers and finalize tablet server deaths – store schema information – store access control lists

13
5. Implementation Client library Master server Tablet server

14
5.1 Tablet Location Three level hierarchy

15
METADATA METADATA Table (table id, end row)---> (location of tablet, secondary information) Client library caches tablet location – incorrect, empty, stale – prefetch
---> (location of tablet, secondary information) Client library caches tablet location – incorrect, empty, stale – prefetch")
16
5.2 Tablet Assignment Master assigns tablet to tablet servers When tablet server starts, it creates and acquires an exclusive lock on, a uniquely- named file in specific Chubby directory(servers directory) A tablet server stops serving its tablets if it loses its exclusive lock(e.g. loses its session) Whenever a tablet server terminates, it attempts to release its lock.
 Whenever a tablet server terminates, it attempts to release its lock..")
17
When a master is started by the cluster management system – grabs a unique master lock in Chubby – scans the servers directory – communicates with every live tablet server to discover what tablets are already assigned to each server – scans the METADATA table – add unassigned tablet to a unassigned tablet set – first add root tablet

18
The master is responsible for detecting when a tablet server is no longer serving its tablets, and for reassigning those tablets as soon as possible The master periodically asks each tablet server for the status of its lock

19
The master initiates these tablets changes – when a table is created or deleted – when two tablets are merged A tablet server initiates tablet split – commit the split by recording in METADATA – notifies the master

20
5.3 Tablet Serving

21
Write Operation Check – well-formed – authorized Write to commit log(group commit) Insert into memtable
 Insert into memtable")
22
Read Operation Check – well-formed – authorized Merged view of SSTables and memtable – SSTables and memtable are lexicographic sorted data structures, the merged view can be formed efficiently

23
Recover Tablet Memtable – recently committed updates SSTables – older updates To recover a tablet – a tablet server read its metadata from METADATA – metadata contains the list of SSTables and a set of redo points – the tablet server read SSTables indices and reconstruct the memtable since the redo points

24
5.4 Compactions Minor compaction – when the memtable size reaches a threshold, the memtable is frozen, a new memtable is created, and the frozen memtable is converted to an SSTable and written to GFS Merging compaction – merge a few SSTables and the memtable and write out a new SSTable Major compaction – rewrites all SSTables into one SSTable – produces an SSTable contains no deleted data – Bigtable cycles through all of its tablets and regularly applies major compactions to them

25
6. Refinements The implementation described in the previous section required a number of refinements to achieve the high performance, availability, and reliability required by our users.

26
Locality Groups Clients can group multiple column families together into a locality group A separate SSTable is generated for each locality group Effect – efficient reads – tuning parameters based on locality group in-memory(read frequently, location column family in METADATA table)
")
27
Compression Clients can control whether or not the SSTables for a locality group are compressed, and if so, which compression format is used Many clients use a two-pass custom compression scheme When similar data ends up clustered, applications achieve very good compression ratios

28
Caching for Read Performance Scan Cache – higher level, key-value pairs – from SSTable interface – useful for repeatedly read Block Cache – lower-level, SSTable blocks – from GFS – useful for sequential reads

29
Bloom Filters A Bloom filter allows us to ask whether an SSTable might contain any data for a specfied row/column pair In tablet server memory Reduce disk seeks

30
Commit-log Implementation A single commit log per tablet server Parallelize sorting log on different tablet server; sequential reads To protect mutations from GFS latency spikes, each tablet server actually has two log writing threads, each writing to its own log file; only one of these two threads is actively in use at a time

31
Speeding Up Tablet Recovery When move a tablet Two minor compactions first-->stop serving-->second-->unload After this second minor compaction is complete, the tablet can be loaded on another tablet server without requiring any recovery of log entries

32
Exploiting Immutability All of the SSTables that we generate are immutable The only mutable data structure that is accessed by both reads and writes is the memtable Copy-on-write Mark-and-swap

33
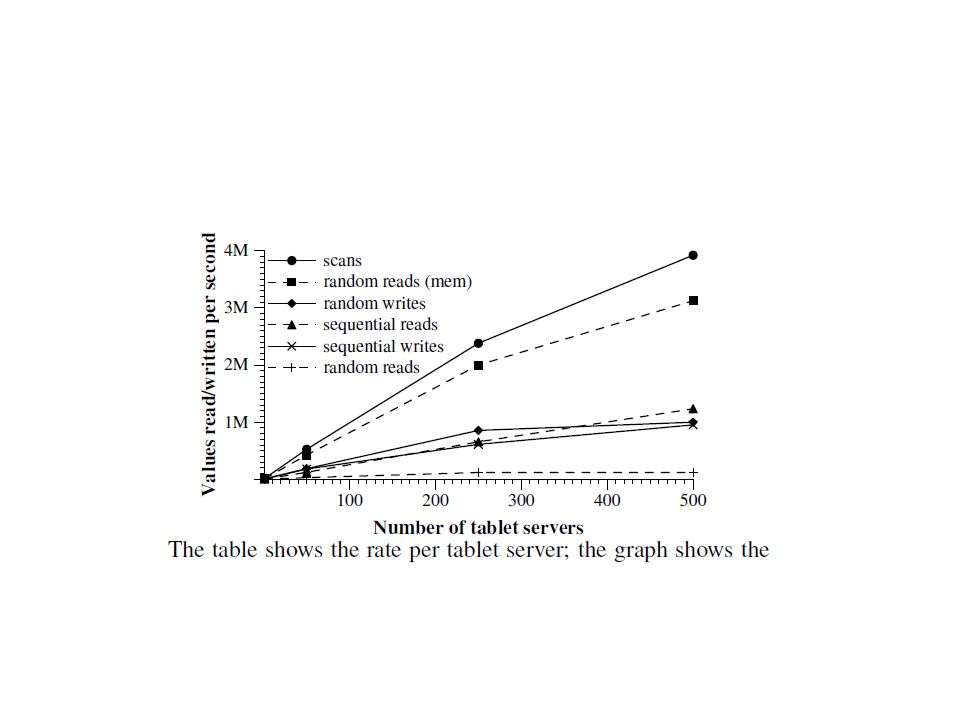
7. Performance Evaluation

Similar presentations



 Presenter: Kyungho Jeon 10/22/2012 Fall.>")






 CSE 490h – Introduction to Distributed Computing, Winter 2008 Except as otherwise noted, the content of this presentation.>")








