Download presentation
Presentation is loading. Please wait.

1
Linked Data Profiling Andrejs Abele UNLP PhD Day Supervisor: Paul Buitelaar

2
Overview Motivation My approach Experiments Future work

3
Motivation Linked Data is hard to understand for humans Only a small number of datasets provide a human readable overview or comprehensive metadata When adding a new dataset to the LOD cloud, connections have to be identified to as many other relevant LOD datasets as possible LOD Cloud Diagram relays on human classification

4
Domain identification method using DBpedia Topic Extraction Domain Identification Domain

5
Experiments 1.Extract classes and properties and run SVM 2.Identify domain by using DBpedia category structure 3.Run SVM on extracted DBpedia concepts (terms that where linked to DBpedia) 4.Run SVM on extracted DBpedia categories 5.Run SVM on combination of classes and properties + DBpedia concepts 6.Run SVM on combination of classes and properties + DBpedia categories 7. Manually reclassify datasets based only on literals 8.Manually calculate best maximal accuracy

6
Datasets LOD cloud datasets (annotated in LOD Cloud Diagram) 342 datasets, 9 domains Media(8) Linguistics(13) Publication(88) Social_Networking(41) Geography(19) Government(65) Cross_domain (23) User_generated(53) Life_science(32)
 342 datasets, 9 domains Media(8) Linguistics(13) Publication(88) Social_Networking(41) Geography(19) Government(65) Cross_domain (23) User_generated(53) Life_science(32)")
7
1.Extract URIs of properties and classes from datasets 2.Use classes and properties as features 3.Classify using Support Vector Machine classifier (C-SVC) 4.Use Precision and Recall as metrics 1. Experiment

8
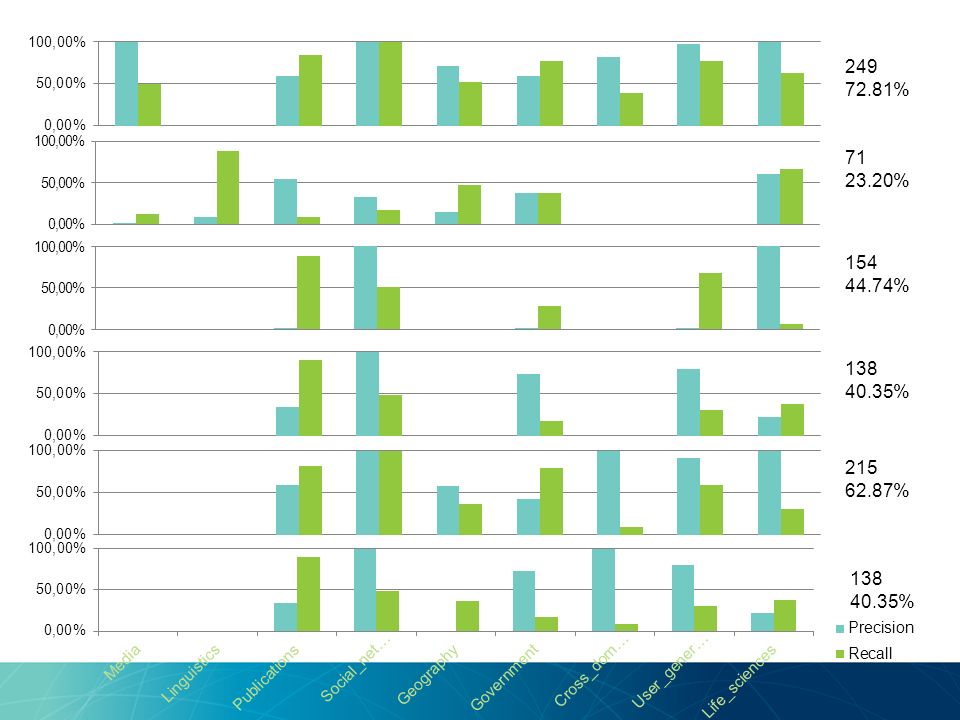
Precision and Recall for different domains using SVM Correctly classified: 249 Processed:342 Accuracy: 72.807%

9
1.Extract Literals 2.Calculate TF 3.Select literals containing top 100 terms (based on TF) 4.Extract topics 5.Get Categories 6.Calculate distance between top 50 categories and 7 predefined Domains (max distance 5 ) 7.Select domain with shortest distance 8.Use Precision and Recall as metrics 2. Experiment

10
Precision and Recall for different domains using DBpedia classification Correctly classified: 71 Processed:342 Contained dataset information :306 Contains first 7 domains : 235 Accuracy: 23.20% Accuracy if counted only 7 domains: 30.21%

11
Domain mapping Publicationshttp://dbpedia.org/page/Category:Publications Life Scienceshttp://dbpedia.org/page/Category:Biology Cross-Domain Social Networkinghttp://dbpedia.org/page/Category:Social_networks Geographyhttp://dbpedia.org/page/Category:Geography Governmenthttp://dbpedia.org/page/Category:Government Mediahttp://dbpedia.org/page/Category:Digital_technology User-Generated Content Linguisticshttp://dbpedia.org/page/Category:Linguistics

12
1.Extract Literals 2.Calculate TF 3.Select literals containing top 100 terms (based on TF) 4.Extract topics 5.Use topics (DBpedia concepts) as features 6.Classify using Support Vector Machine classifier (C-SVC) 7.Use Precision and Recall as metrics 3. Experiment

13
Precision and Recall for different domains using SVM and DBpedia topics Correctly classified: 154 Processed:342 Accuracy: 44.7368% 34 datasets contain no identified topics: Cross_domain =1, Geography = 2 Government = 6, Life_sciences = 2 Linguistics = 5, Publications = 8 Social_networking = 6, User_generated = 4

14
1.Extract Literals 2.Calculate TF 3.Select literals containing top 100 terms (based on TF) 4.Extract topics 5.Get Categories 6.Use Categories (DBpedia Categories) as features 7.Classify using Support Vector Machine classifier (C-SVC) 8.Use Precision and Recall as metrics 4. Experiment

15
Precision and Recall for different domains using SVM and DBpedia categories Correctly classified: 138 Processed:342 Accuracy: 40.3509% 34 datasets contain no identified topics: Cross_domain =1, Geography = 2 Government = 6, Life_sciences = 2 Linguistics = 5, Publications = 8 Social_networking = 6, User_generated = 4

16
1.Extract URIs of properties and classes from datasets 2.Use classes and properties as features 3.Extract Literals 4.Calculate TF 5.Select literals containing top 100 terms (based on TF) 6.Extract topics 7.Use topics (DBpedia concepts) and classes, and properties as features 8.Classify using Support Vector Machine classifier (C-SVC) 9.Use Precision and Recall as metrics 5. Experiment

17
Precision and Recall for different domains using SVM and DBpedia concepts Correctly classified: 215 Processed:342 Accuracy: 62.8655%

18
1.Extract URIs of properties and classes from datasets 2.Use classes and properties as features 3.Extract Literals 4.Calculate TF 5.Select literals containing top 100 terms (based on TF) 6.Extract topics 7.Get Categories 8.Use Categories and classes, and properties as features 9.Classify using Support Vector Machine classifier (C-SVC) 10.Use Precision and Recall as metrics 6. Experiment

19
Precision and Recall for different domains using SVM and DBpedia categories Correctly classified: 138 Processed:342 Accuracy: 40.3509%

20
1.Extract Literals 2.Without any other information classify datasets based only on literals 7. Experiment

21
Data analysis There are dataset where algorithm agreed with original classification, but I as a human annotator, I had to little information: VULCAN VENTURES INC SEC (http://edgar.sec.gov/) via Linked Edgar (http://edgarwrap.ontologycentral.com/ No guarantee of correctness! USE AT YOUR OWN RISK! It was identified as government, but for me was to little information My annotation didn’t significantly improved results, but it was, because during annotation for many dataset I couldn’t assignee them to any of the predefined domains

22
1.Extract Literals 2.Without any other information classify datasets based only on literals 3.Manually analyse list of domain provided by my approach 4.Analyse if domain list provide any insight, connected to dataset Results Number of datasets: 336 Possibly correct answers: 261 Percentage: 77.68% 8. Experiment

23
Experiments 1.Extract classes and properties and run SVM 2.Identify domain by using DBpedia category structure 3.Run SVM on extracted DBpedia concepts (terms that where linked to DBpedia) 4.Run SVM on extracted DBpedia categories 5.Run SVM on combination of classes and properties + DBpedia concepts 6.Run SVM on combination of classes and properties + DBpedia categories 7. Manually reclassify datasets based only on literals 8.Manually calculate best maximal accuracy

25
Future work 1.Identify better categories Ontologies, Technology, People, … 2.Create Better domain mapping for my approach 3.Create hybrid approach (Identify type of dataset, identify domain of content )
")
26
Thank you!

Similar presentations






>")












