Download presentation
Presentation is loading. Please wait.

1
Knowledge-based systems Sanaullah Manzoor CS&IT, Lahore Leads University sanaullahmanzoor1988@gmail.com https://sites.google.com/site/engrsanaullahmanzoor/home Lecture 3

2
Overview 2 What is “Machine Learning”? Learning Types Supervised learning Un-Supervised learning Data Pre-Processing Discretization Methods: Binning Classification Bayesian Classifier

3
Why “Learn”? l Machine learning is programming computers to optimize a performance criterion using example data or past experience. l There is no need to “learn” to calculate payroll l Learning is used when: n Human expertise does not exist (navigating on Mars), n Humans are unable to explain their expertise (speech recognition) n Solution changes in time (routing on a computer network) n Solution needs to be adapted to particular cases (user biometrics)
, n Humans are unable to explain their expertise (speech recognition) n Solution changes in time (routing on a computer network) n Solution needs to be adapted to particular cases (user biometrics).")
4
What is Machine Learning? l Machine Learning n Study of algorithms that n improve their performance n at some task n with experience l Optimize a performance criterion using example data or past experience. l Role of Computer science: Efficient algorithms to n Solve the optimization problem n Representing and evaluating the model for inference

5
Data Mining l Retail: Customer relationship management (CRM) l Finance: Credit scoring, fraud detection l Manufacturing: Optimization, troubleshooting l Medicine: Medical diagnosis l Telecommunications: Quality of service optimization l Web mining: Search engines Definition := “Data mining is the process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data” Applications:
 l Finance: Credit scoring, fraud detection l Manufacturing: Optimization, troubleshooting l Medicine: Medical diagnosis l Telecommunications: Quality of service optimization l Web mining: Search engines Definition := Data mining is the process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data Applications:")
6
Growth of Machine Learning l Machine learning is preferred approach to n Speech recognition, Natural language processing n Computer vision n Medical outcomes analysis n Robot control n Computational biology

7
Machine learning problems What high-level machine learning problems have you seen or heard of before?

8
Data examples Data

9
examples Data

10
examples Data

11
Supervised learning Supervised learning: given labeled examples label label 1 label 3 label 4 label 5 labeled examples examples

12
Supervised learning Supervised learning: given labeled examples model/ predictor label label 1 label 3 label 4 label 5

13
Supervised learning model/ predictor Supervised learning: learn to predict new example predicted label

14
Supervised learning: classification Supervised learning: given labeled examples label apple banana Classification: a finite set of labels

15
Classification Example Differentiate between low-risk and high-risk customers from their income and savings

16
Supervised learning: regression Supervised learning: given labeled examples label -4.5 10.1 3.2 4.3 Regression: label is real-valued

17
Regression Example Price of a used car x : car attributes (e.g. mileage) y : price y = wx+w 0
 y : price y = wx+w 0")
18
Supervised learning: ranking Supervised learning: given labeled examples label 1 4 2 3 Ranking: label is a ranking

19
Ranking example Given a query and a set of web pages, rank them according to relevance

20
Ranking Applications User preference, e.g. Netflix “My List” -- movie queue ranking iTunes flight search (search in general)
.")
21
Unsupervised learning Unupervised learning: given data, i.e. examples, but no labels

22
Approaches l Supervised Learning l Unsupervised Learning

23
Learning system model Input Samples Learning Method System Training Testing Prediction

24
Learning Types Supervised Learning: The computer is presented with example inputs and their desired outputs and the goal is to learn a general rule that maps inputs to outputs. Also known as Classification. Regression, also is a supervised problem, the outputs are continuous rather than discrete. Regression

25
l Supervised learning Machine learning structure

26
Learning Types Unsupervised Learning: no labels are given to the learning algorithm, leaving it on its own to find structure in its input. Unsupervised learning can be a goal in itself (discovering hidden patterns in data). Known as Clustering.
. Known as Clustering..")
27
l Unsupervised learning Machine learning structure

28
Data Pre-processing

29
Forms of data preprocessing

30
Data Pre-processing l Data cleaning n Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies l Data integration n Integration of multiple databases, data cubes, or files l Data transformation n Normalization and aggregation l Data reduction n Obtains reduced representation in volume but produces the same or similar analytical results

31
Why Data Preprocessing? l Data in the real world is dirty n incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data n noisy: containing errors or outliers n inconsistent: containing discrepancies in codes or names l No quality data, no quality mining results! n Quality decisions must be based on quality data n Data warehouse needs consistent integration of quality data

32
Data Cleaning l Data cleaning tasks n Fill in missing values n Identify outliers and smooth out noisy data n Correct inconsistent data

33
Missing Data l Data is not always available n E.g., many tuples have no recorded value for several attributes, such as customer income in sales data l Missing data may be due to n equipment malfunction n inconsistent with other recorded data and thus deleted n data not entered due to misunderstanding n certain data may not be considered important at the time of entry n not register history or changes of the data l Missing data may need to be inferred.

34
How to Handle Missing Data? l Fill in the missing value manually: tedious + infeasible? l Use a global constant to fill in the missing value: e.g., “unknown”, a new class?! l Use the attribute mean to fill in the missing value l Use the most probable value to fill in the missing value: inference-based such as Bayesian formula or decision tree

35
Noisy Data l Noise: random error or variance in a measured variable l Incorrect attribute values may due to n faulty data collection instruments n data entry problems n data transmission problems n technology limitation n inconsistency in naming convention l Other data problems which requires data cleaning n duplicate records n incomplete data n inconsistent data

36
How to Handle Noisy Data? l Binning method: n first sort data and partition into (equi-depth) bins n then one can smooth by bin means, smooth by bin median, smooth by bin boundaries, etc. l Clustering n detect and remove outliers l Combined computer and human inspection n detect suspicious values and check by human l Regression n smooth by fitting the data into regression functions
 bins n then one can smooth by bin means, smooth by bin median, smooth by bin boundaries, etc. l Clustering n detect and remove outliers l Combined computer and human inspection n detect suspicious values and check by human l Regression n smooth by fitting the data into regression functions.")
37
Simple Discretization Methods: Binning l Equal-width (distance) partitioning: n It divides the range into N intervals of equal size: uniform grid n if A and B are the lowest and highest values of the attribute, the width of intervals will be: W = (B-A)/N. l Equal-depth (frequency) partitioning: n It divides the range into N intervals, each containing approximately same number of samples n Good data scaling n Managing categorical attributes can be tricky.
 partitioning: n It divides the range into N intervals, each containing approximately same number of samples n Good data scaling n Managing categorical attributes can be tricky..")
38
Binning Methods for Data Smoothing * Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34 * Partition into (equi-depth) bins: - Bin 1: 4, 8, 9, 15 - Bin 2: 21, 21, 24, 25 - Bin 3: 26, 28, 29, 34 Method 1: * Smoothing by bin means: - Bin 1: 9, 9, 9, 9 - Bin 2: 23, 23, 23, 23 - Bin 3: 29, 29, 29, 29 OR Method 2: * Smoothing by bin boundaries: - Bin 1: 4, 4, 4, 15 - Bin 2: 21, 21, 25, 25 - Bin 3: 26, 26, 26, 34
: 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34 * Partition into (equi-depth) bins: - Bin 1: 4, 8, 9, 15 - Bin 2: 21, 21, 24, 25 - Bin 3: 26, 28, 29, 34 Method 1: * Smoothing by bin means: - Bin 1: 9, 9, 9, 9 - Bin 2: 23, 23, 23, 23 - Bin 3: 29, 29, 29, 29 OR Method 2: * Smoothing by bin boundaries: - Bin 1: 4, 4, 4, 15 - Bin 2: 21, 21, 25, 25 - Bin 3: 26, 26, 26, 34")
39
Cluster Analysis

40
Regression x y y = x + 1 X1 Y1 Y1’

41
Data Integration l Data integration: n combines data from multiple sources into a coherent store l Schema integration n integrate metadata from different sources l Detecting and resolving data value conflicts n for the same real world entity, attribute values from different sources are different n possible reasons: different representations, different scales, e.g., metric vs. British units

42
Handling Redundant Data l Redundant data occur often when integration of multiple databases n The same attribute may have different names in different databases n One attribute may be a “derived” attribute in another table, e.g., annual revenue l Redundant data may be able to be detected by correlational analysis (Similarity measures) l Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality
 l Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality")
43
Data Reduction Strategies l Warehouse may store terabytes of data: Complex data analysis/mining may take a very long time to run on the complete data set l Data reduction n Obtains a reduced representation of the data set that is much smaller in volume but yet produces the same (or almost the same) analytical results l Data reduction strategy n Dimensionality reduction
 analytical results l Data reduction strategy n Dimensionality reduction")
44
Dimensionality Reduction l Feature selection (i.e., attribute subset selection): n Select a minimum set of features such that the probability distribution of different classes given the values for those features is as close as possible to the original distribution given the values of all features n reduce # of patterns in the patterns, easier to understand l Heuristic methods (due to exponential # of choices): n step-wise forward selection n step-wise backward elimination n combining forward selection and backward elimination n decision-tree induction
: n Select a minimum set of features such that the probability distribution of different classes given the values for those features is as close as possible to the original distribution given the values of all features n reduce # of patterns in the patterns, easier to understand l Heuristic methods (due to exponential # of choices): n step-wise forward selection n step-wise backward elimination n combining forward selection and backward elimination n decision-tree induction")
45
Example of Decision Tree Induction Initial attribute set: {A1, A2, A3, A4, A5, A6} A4 ? A1? A6? Class 1 Class 2 Class 1 Class 2 > Reduced attribute set: {A1, A4, A6}

46
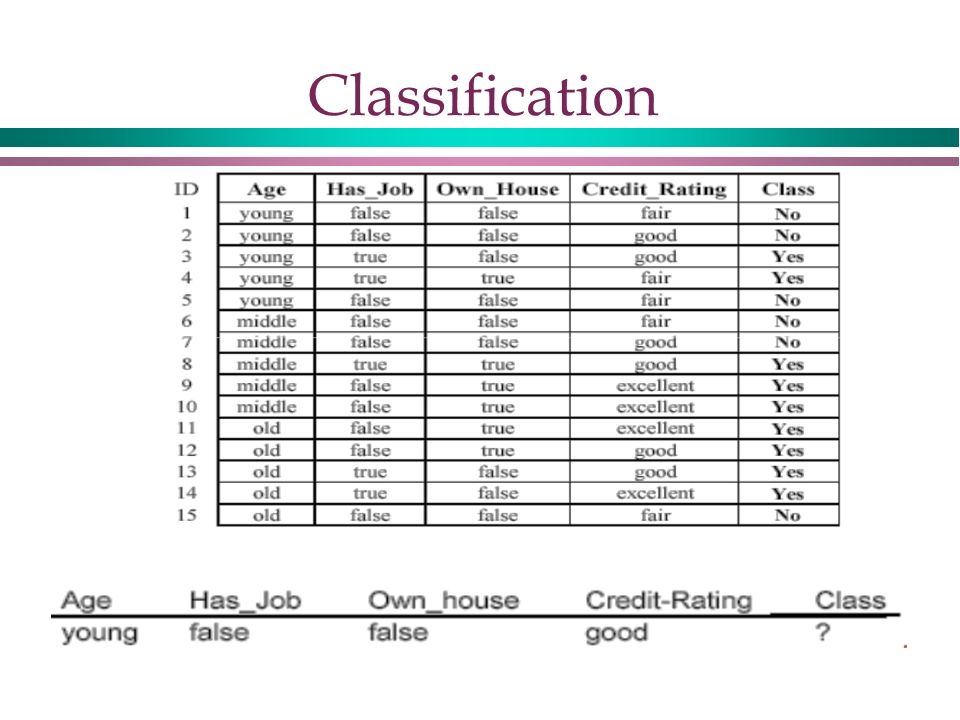
Classification

48
Sample case Classify fish in a fishery Manually employ labor to classify fish Use automated processing with the help of a camera

49
Sample case Classification based on light and darkness in skin tone

50
A Simple Classification Problem A classification problem: The grades for students taking this course Key Steps : 1. Data (what past experience can we rely on?) 2. Assumptions (what can we assume about the students or the course?) 3. Representation (how do we “summarize” a student?) 4. Estimation (how do we construct a map from students to grades?) 5. Evaluation (how well are we predicting?) 6. Model Selection (perhaps we can do even better?)
 2. Assumptions (what can we assume about the students or the course ) 3. Representation (how do we summarize a student ) 4. Estimation (how do we construct a map from students to grades ) 5. Evaluation (how well are we predicting ) 6. Model Selection (perhaps we can do even better ).")
51
Classification Approaches Bayesian networks Artificial Neural Network Genetic Algorithm Decision Trees Support Vector Machine

52
What is Feature selection ? l Feature selection: Problem of selecting some subset of a learning algorithm’s input variables upon which it should focus attention, while ignoring the rest. Also known as DIMENSIONALITY REDUCTION.

53
Filter Methods Select subsets of variables as a pre-processing step, independently of the used classifier!! Feature Subset Selection

54
Bayesian Classifier

55
Classification!!!! Lets start with simple classification form (General Problem) Problem statement: Given features X 1,X 2,…,X n Predict a label Y
 Problem statement: Given features X 1,X 2,…,X n Predict a label Y.")
56
Example :Digit Recognition Features : X 1,…,X n {0,1} (Black vs. White pixels) Lables : Y {5,6} (predict whether a digit is a 5 or a 6) Classifier 5 Classification!!!!
 Lables : Y {5,6} (predict whether a digit is a 5 or a 6) Classifier 5 Classification!!!!.")
57
Example :Digit Recognition Our Problem can be stated as : “what is the probability that the image represents a 5 given its pixels?” Classifier 5 Classification!!!!

58
Bayesian Classification!!!! Lets Solve our Problem with “Bayesian Rule” (Thomas Bayes 1702 – 1761) Bayesian classification is Probabilistic approach.
 Bayesian classification is Probabilistic approach..")
59
Bayesian rules : Normalization Constant LikelihoodPrior Bayesian Classification!!!!

63
Solution of our Example : If class is 5. If class is 6. Which one class is with greater probability that ’ s our solution Bayesian Classification!!!!

64
Example 2: Bayesian Classification!!!!

65
Solution: Bayesian Classification!!!! 1.Calaculate total Yes and No Probability

66
Bayesian Classification!!!! 2. Calculate Yes and No probability in the feature “Outlook”

67
Bayesian Classification!!!! 3. Calculate Yes and No probability in the feature “Temperature”

68
Bayesian Classification!!!! 4. Calculate Yes and No probability in the feature “Humidity and Wind”

69
Solution: Bayesian Classification!!!!

70
Given a new instance (Testing phase) x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) Using our calculations: Bayesian Classification!!!!
 x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) Using our calculations: Bayesian Classification!!!!")
71
x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(Outlook=Sunny|Play=No) = 3/5 P(Temperature=Cool|Play==No) = 1/5 P(Huminity=High|Play=No) = 4/5 P(Wind=Strong|Play=No) = 3/5 P(Play=No) = 5/14 Bayesian Classification!!!!
 P(Outlook=Sunny|Play=No) = 3/5 P(Temperature=Cool|Play==No) = 1/5 P(Huminity=High|Play=No) = 4/5 P(Wind=Strong|Play=No) = 3/5 P(Play=No) = 5/14 Bayesian Classification!!!!")
72
x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(Outlook=Sunny|Play=Yes) = 2/9 P(Temperature=Cool|Play=Yes) = 3/9 P(Huminity=High|Play=Yes) = 3/9 P(Wind=Strong|Play=Yes) = 3/9 P(Play=Yes) = 9/14 Bayesian Classification!!!!
 P(Outlook=Sunny|Play=Yes) = 2/9 P(Temperature=Cool|Play=Yes) = 3/9 P(Huminity=High|Play=Yes) = 3/9 P(Wind=Strong|Play=Yes) = 3/9 P(Play=Yes) = 9/14 Bayesian Classification!!!!")
73
x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(No|x’): [P(Sunny|No) P(Cool|No)P(High|No)P(Strong|No)]P(Play=No) = 0.01176 P(Yes|x’): [P(Sunny|Yes)P(Cool|Yes)P(High|Yes)P(Strong|Yes)]P(Play=Yes) = 0.0051 Bayesian Classification!!!!
![x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(No|x’): [P(Sunny|No) P(Cool|No)P(High|No)P(Strong|No)]P(Play=No) = P(Yes|x’): [P(Sunny|Yes)P(Cool|Yes)P(High|Yes)P(Strong|Yes)]P(Play=Yes) = Bayesian Classification!!!!](http://images.slideplayer.com/37/10706074/slides/slide_73.jpg "x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(No|x’): [P(Sunny|No) P(Cool|No)P(High|No)P(Strong|No)]P(Play=No) = P(Yes|x’): [P(Sunny|Yes)P(Cool|Yes)P(High|Yes)P(Strong|Yes)]P(Play=Yes) = Bayesian Classification!!!!")
74
x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(Outlook=Sunny|Play=No) = 3/5 P(Temperature=Cool|Play==No) = 1/5 P(Huminity=High|Play=No) = 4/5 P(Wind=Strong|Play=No) = 3/5 P(Play=No) = 5/14 P(Outlook=Sunny|Play=Yes) = 2/9 P(Temperature=Cool|Play=Yes) = 3/9 P(Huminity=High|Play=Yes) = 3/9 P(Wind=Strong|Play=Yes) = 3/9 P(Play=Yes) = 9/14 P(No|x’): [P(Sunny|No) P(Cool|No)P(High|No)P(Strong|No)]P(Play=No) = 0.01176 P(Yes|x’): [P(Sunny|Yes)P(Cool|Yes)P(High|Yes)P(Strong|Yes)]P(Play=Yes) = 0.0051 Bayesian Classification!!!!
![x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(Outlook=Sunny|Play=No) = 3/5 P(Temperature=Cool|Play==No) = 1/5 P(Huminity=High|Play=No) = 4/5 P(Wind=Strong|Play=No) = 3/5 P(Play=No) = 5/14 P(Outlook=Sunny|Play=Yes) = 2/9 P(Temperature=Cool|Play=Yes) = 3/9 P(Huminity=High|Play=Yes) = 3/9 P(Wind=Strong|Play=Yes) = 3/9 P(Play=Yes) = 9/14 P(No|x’): [P(Sunny|No) P(Cool|No)P(High|No)P(Strong|No)]P(Play=No) = P(Yes|x’): [P(Sunny|Yes)P(Cool|Yes)P(High|Yes)P(Strong|Yes)]P(Play=Yes) = Bayesian Classification!!!!](http://images.slideplayer.com/37/10706074/slides/slide_74.jpg "x’=(Outlook=Sunny, Temperature=Cool, Humidity=High, Wind=Strong) P(Outlook=Sunny|Play=No) = 3/5 P(Temperature=Cool|Play==No) = 1/5 P(Huminity=High|Play=No) = 4/5 P(Wind=Strong|Play=No) = 3/5 P(Play=No) = 5/14 P(Outlook=Sunny|Play=Yes) = 2/9 P(Temperature=Cool|Play=Yes) = 3/9 P(Huminity=High|Play=Yes) = 3/9 P(Wind=Strong|Play=Yes) = 3/9 P(Play=Yes) = 9/14 P(No|x’): [P(Sunny|No) P(Cool|No)P(High|No)P(Strong|No)]P(Play=No) = P(Yes|x’): [P(Sunny|Yes)P(Cool|Yes)P(High|Yes)P(Strong|Yes)]P(Play=Yes) = Bayesian Classification!!!!")
Similar presentations