Download presentation
Presentation is loading. Please wait.

1
Part II NoSQL Database (MapReduce) Yuan Xue (yuan.xue@vanderbilt.edu)
 Yuan Xue")
2
Outline Why MapReduce is needed What is MapReduce How to use MapReduce (Programming Model) How MapReduce works (Under the hood/Implementation) Best practice with MapReduce (Design Pattern) More on MapReduce MapReduce and NoSQL MapReduce and SQL (Hive/Pig) MapReduce for machine learning (Mahout)
 How MapReduce works (Under the hood/Implementation) Best practice with MapReduce (Design Pattern) More on MapReduce MapReduce and NoSQL MapReduce and SQL (Hive/Pig) MapReduce for machine learning (Mahout)")
3
Motivation Example Classical Example: Word Count large number of files of words, Count the number of times each distinct word appears How to do it if all documents are on the same machine? How to do it if documents are distributed across multiple machines? Computation Synchronization Failure handling Word Count

4
Knowing the field: Cluster Environment Cheap nodes fail, especially if you have many – Mean time between failures for 1 node = 3 years – MTBF for 1000 nodes = 1 day – Solution: Build fault-tolerance into system Commodity network = low bandwidth – Solution: Push computation to the data

5
Need for Programming Model and Execution Framework Programming Interface Execution Framework Distributed computing environment Coordinate computation Handles failures Simple APIs Program development with limited knowledge of execution platform

6
Need for Programming Model and Execution Framework Programming Interface Map() Reduce() Execution Framework Distributed computing environment Coordinate computation Handles failures Simple APIs Program development with limited knowledge of execution platform MapReduce
 Reduce() Execution Framework Distributed computing environment Coordinate computation Handles failures Simple APIs Program development with limited knowledge of execution platform MapReduce")
7
Outline Why MapReduce is needed What is MapReduce How to use MapReduce (Programming Model) How MapReduce works (Under the hood/Implementation) Best practice with MapReduce (Design Pattern) More on MapReduce MapReduce and NoSQL MapReduce and SQL (Hive/Pig) MapReduce for machine learning (Mahout)
 How MapReduce works (Under the hood/Implementation) Best practice with MapReduce (Design Pattern) More on MapReduce MapReduce and NoSQL MapReduce and SQL (Hive/Pig) MapReduce for machine learning (Mahout)")
8
MapReduce and Hadoop Pioneered by Google Popularized by open-source Hadoop project Used by Yahoo!, Facebook, Amazon AWS – EMR cloud service Applications At Google: Index building for Google Search Article clustering for Google News Statistical machine translation At Yahoo!: Index building for Yahoo! Search Spam detection for Yahoo! Mail At Facebook: Data mining Ad optimization Spam detection

9
MapReduce Overview Map/Reduce Programming Model model from Lisp (and other functional languages) Many problems can be phrased this way Easy to distribute across nodes Nice retry/failure semantics MapReduce Execution Framework Automatic parallelization & distribution Fault tolerance I/O scheduling Monitoring & status updates Large-Scale Data Processing Want to use 1000s of CPUs But don’t want hassle of managing things
 Many problems can be phrased this way Easy to distribute across nodes Nice retry/failure semantics MapReduce Execution Framework Automatic parallelization & distribution Fault tolerance I/O scheduling Monitoring & status updates Large-Scale Data Processing Want to use 1000s of CPUs But don’t want hassle of managing things")
10
MapReduce Programing Model (basic version) Input: a set of key/value pairs User supplies two functions: map(k,v) list(k1,v1) reduce(k1, list(v1)) v2 (k1,v1) is an intermediate key/value pair Output is the set of (k1,v2) pairs
 Input: a set of key/value pairs User supplies two functions: map(k,v) list(k1,v1) reduce(k1, list(v1)) v2 (k1,v1) is an intermediate key/value pair Output is the set of (k1,v2) pairs")
11
MapReduce Execution Semantic

12
Example Application – Word Count map(key, value): // key: document name; value: text of document for each word w in value: emit(w, 1) reduce(key, values): // key: a word; values: an iterator over counts result = 0 for each count v in values: result += v emit(key,result)
: // key: document name; value: text of document for each word w in value: emit(w, 1) reduce(key, values): // key: a word; values: an iterator over counts result = 0 for each count v in values: result += v emit(key,result)")
13
Check out the code in Hadoop https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html

14
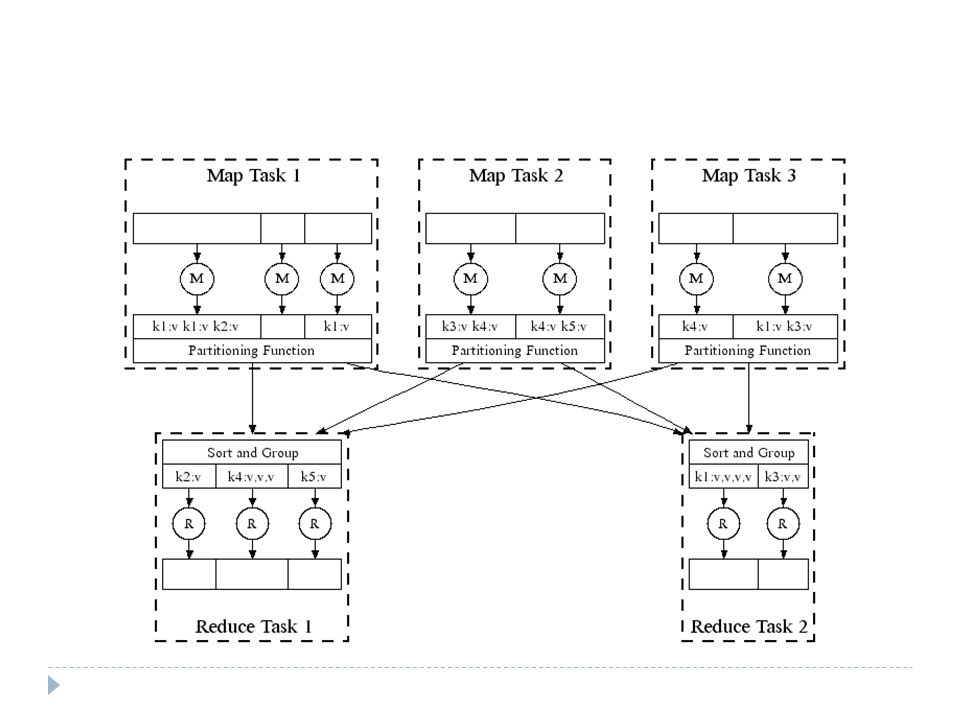
Example Execution Illustration

15
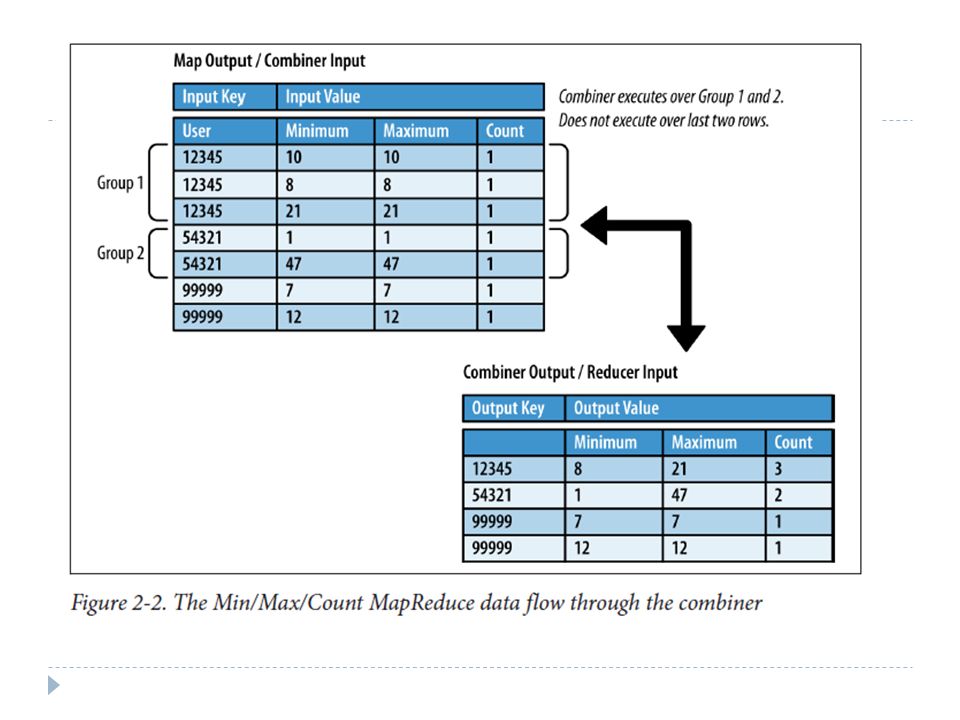
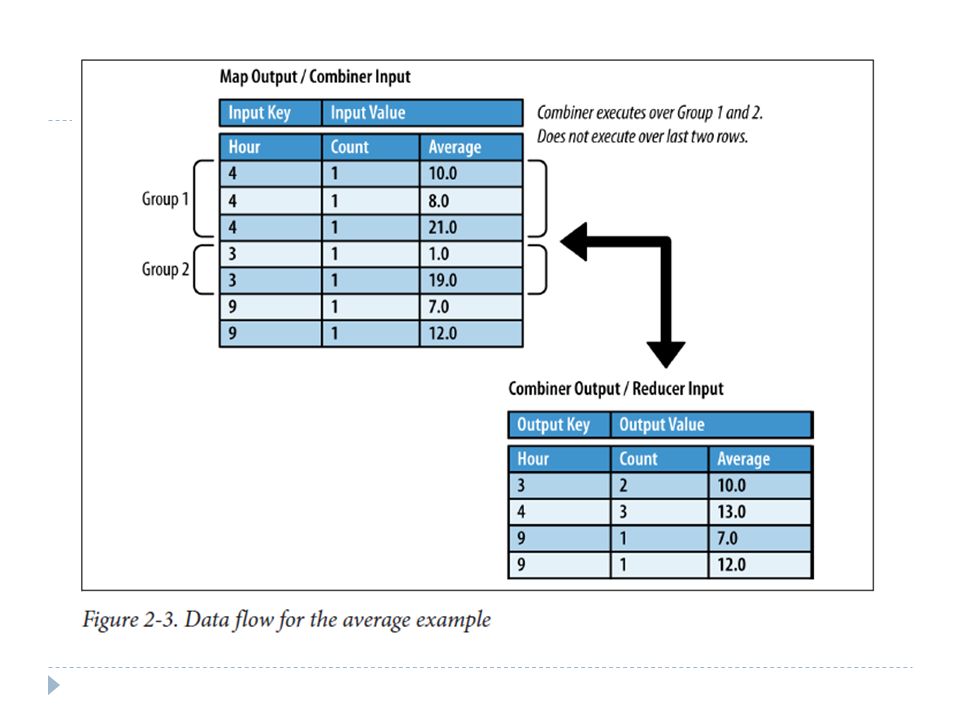
Programming Model Extended – Combiner Often a map task will produce many pairs of the form (k,v1), (k,v2), … for the same key k E.g., popular words in Word Count Can save network time by pre-aggregating at mapper combine(k1, list(v1)) v2 Usually same as reduce function Works only if reduce function is commutative and associative
, (k,v2), … for the same key k E.g., popular words in Word Count Can save network time by pre-aggregating at mapper combine(k1, list(v1)) v2 Usually same as reduce function Works only if reduce function is commutative and associative")
16
Outline Why MapReduce is needed What is MapReduce How to use MapReduce (Programming Model) How MapReduce works (Under the hood/Implementation) Best practice with MapReduce (Design Pattern) More on MapReduce MapReduce and NoSQL MapReduce and SQL (Hive/Pig) MapReduce for machine learning (Mahout)
 How MapReduce works (Under the hood/Implementation) Best practice with MapReduce (Design Pattern) More on MapReduce MapReduce and NoSQL MapReduce and SQL (Hive/Pig) MapReduce for machine learning (Mahout)")
17
Execution Workflow User Program Worker Master Worker fork assign map assign reduce read local write remote read, sort Output File 0 Output File 1 write Split 0 Split 1 Split 2 Input Data

18
Data flow Input, final output are stored on a distributed file system Scheduler tries to schedule map tasks “close” to physical storage location of input data Push computation to data, minimize network use Intermediate results are stored on local FS of map and reduce workers Sync point Allows recovery if a reducer crashes Output is often input to another map reduce task

19
Partition Function Inputs to map tasks are created by contiguous splits of input file For reduce, we need to ensure that records with the same intermediate key end up at the same worker System uses a default partition function e.g., hash(key) mod R Sometimes useful to override E.g., hash(hostname(URL)) mod R ensures URLs from a host end up in the same output file
 mod R Sometimes useful to override E.g., hash(hostname(URL)) mod R ensures URLs from a host end up in the same output file")
20
Coordination and Failure Handling Master data structures Task status: (idle, in-progress, completed) Idle tasks get scheduled as workers become available When a map task completes, it sends the master the location and sizes of its R intermediate files Master pushes this info to reducers Master pings workers periodically to detect failures If a task crashes: – Retry on another node OK for a map because it had no dependencies OK for reduce because map outputs are on disk – If the same task repeatedly fails, fail the job or ignore that input block For fault tolerance to work, your map and reduce tasks must be side-effect-free If a node crashes: – Relaunch its current tasks on other nodes – Relaunch any maps the node previously ran Necessary because their output files were lost along with the crashed node
 Idle tasks get scheduled as workers become available When a map task completes, it sends the master the location and sizes of its R intermediate files Master pushes this info to reducers Master pings workers periodically to detect failures If a task crashes: – Retry on another node OK for a map because it had no dependencies OK for reduce because map outputs are on disk – If the same task repeatedly fails, fail the job or ignore that input block For fault tolerance to work, your map and reduce tasks must be side-effect-free If a node crashes: – Relaunch its current tasks on other nodes – Relaunch any maps the node previously ran Necessary because their output files were lost along with the crashed node")
21
Execution Illustration

22
How many Map and Reduce jobs? M map tasks, R reduce tasks Rule of thumb: Make M and R much larger than the number of nodes in cluster One DFS chunk per map is common Improves dynamic load balancing and speeds recovery from worker failure Usually R is smaller than M, because output is spread across R files

23
Execution Summary How is this distributed? Partition input key/value pairs into chunks, run map() tasks in parallel After all map()s are complete, consolidate all emitted values for each unique emitted key Now partition space of output map keys, and run reduce() in parallel If map() or reduce() fails, reexecute! Prasad 23 L06MapReduce
 tasks in parallel After all map()s are complete, consolidate all emitted values for each unique emitted key Now partition space of output map keys, and run reduce() in parallel If map() or reduce() fails, reexecute. Prasad 23 L06MapReduce.")
24
Announcement Lab 2 extension Lab 2 help session (NoSQL data modeling ) – March 20
 – March 20")
25
Outline Why MapReduce is needed What is MapReduce How to use MapReduce (Programming Model) How MapReduce works (Under the hood/Implementation) Best practice with MapReduce (Design Pattern) MapReduce and SQL (Hive/Pig) MapReduce and NoSQL MapReduce for machine learning (Mahout)
 How MapReduce works (Under the hood/Implementation) Best practice with MapReduce (Design Pattern) MapReduce and SQL (Hive/Pig) MapReduce and NoSQL MapReduce for machine learning (Mahout)")
26
References

27
MapReduce: Recap Programmers must specify: map (k, v) → * reduce (k’, v’) → * All values with the same key are reduced together Optionally, also: partition (k’, number of partitions) → partition for k’ Often a simple hash of the key, e.g., hash(k’) mod n Divides up key space for parallel reduce operations combine (k’, v’) → * Mini-reducers that run in memory after the map phase Used as an optimization to reduce network traffic The execution framework handles everything else…
 → * reduce (k’, v’) → * All values with the same key are reduced together Optionally, also: partition (k’, number of partitions) → partition for k’ Often a simple hash of the key, e.g., hash(k’) mod n Divides up key space for parallel reduce operations combine (k’, v’) → * Mini-reducers that run in memory after the map phase Used as an optimization to reduce network traffic The execution framework handles everything else…")
28
“Everything Else” The execution framework handles everything else… Scheduling: assigns workers to map and reduce tasks “Data distribution”: moves processes to data Synchronization: gathers, sorts, and shuffles intermediate data Errors and faults: detects worker failures and restarts Limited control over data and execution flow All algorithms must expressed in m, r, c, p You don’t know: Where mappers and reducers run When a mapper or reducer begins or finishes Which input a particular mapper is processing Which intermediate key a particular reducer is processing

30
Relational Algebra and SQL An algebra is a formal structure consisting of sets and operations on those sets. Relational algebra is a formal system for manipulating relations. Operands of this algebra are relations. Operations of this algebra include usual set operations (since relations are sets of tuples) Union, intersection, difference special operations defined for relations selection projection join Aggregate
 Union, intersection, difference special operations defined for relations selection projection join Aggregate.")
31
Union Mappers are fed by all records of two sets to be united. Reducer is used to eliminate duplicates.

32
Intersection Mappers are fed by all records of two sets to be intersected. Reducer emits only records that occurred twice. It is possible only if both sets contain this record because record includes primary key and can occur in one set only once.

33
Difference Let’s we have two sets of records – R and S. We want to compute difference R – S. Mapper emits all tuples and tag which is a name of the set this record came from. Reducer emits only records that came from R but not from S.

34
Select-project-join query in SQL IDNameEmailPassword Alice00Alicealice00@gmail.com Aadf1234 Bob2013Bobbob13@gmail. com qwer6789 Cathy123Cathycath@vandyTyuoa~!@ IDTimestampAuthorContent 00012013.12.20.11.20.2 Alice00Hello 00022013.12.20.11.23.6 Bob2013Nice weather 00032014.1.6.1.25. 2 Alice00@Bob Not sure.. User Tweet FolloweeFollowerTimestamp Alice00Bob20132011.1.1.3.6.6 Bob2013Cathy1232012.10.2.6.7.7 Alice00Cathy1232012.11.1.2.3.3 Cathy123Alice002012.11.1.2.6.6 Bob2013Alice002012.11.1.2.6.7 Follow SELECT content FROM Tweet, Follow WHERE Follower = ‘Alice00’ AND Author = Followee; Select condition Join condition

35
Relational Algebra Quick Overview http://www.databasteknik.se/webbkursen/relalg-lecture/ http://www.databasteknik.se/webbkursen/relalg-lecture/ https://www.cs.rochester.edu/~nelson/courses/csc_173/relations/algebra.ht ml https://www.cs.rochester.edu/~nelson/courses/csc_173/relations/algebra.ht ml Implementation in single machine Implementing Projection To implement projection we must process every tuple in the relation remove any duplicates that result To avoid duplicates we cansort the result and remove consecutive tuples that are equal requires time O(N log N) where N is the size of the original relation implement the result as a set set insertion guarantees no duplicates by using a hash table, insertion is O(1), so projection is O(N)
 where N is the size of the original relation implement the result as a set set insertion guarantees no duplicates by using a hash table, insertion is O(1), so projection is O(N)")
36
Projection in MapReduce Use a Reducer to eliminate possible duplicates.

37
Implementing Selection In the absence of an index we apply the predicate to every tuple in the relation insert matches in the resulting relation duplicates can't occur take O(N) time Given an index, and a predicate that uses the index key, we Lookup tuples using the key evaluate only those tuples with the predicate take O(K) time, where K tuples match the key
 time Given an index, and a predicate that uses the index key, we Lookup tuples using the key evaluate only those tuples with the predicate take O(K) time, where K tuples match the key")
38
Selection in MapReduce No Reducer is needed. Or Reducer function simply passes the key-value pairs to the output

39
Join implementation Implementing Join with Nested Loops A nested loop join on relations R1 (with N domains) and R2 (with M domains), considers all |R1| x |R2| pairs of tuples.
 and R2 (with M domains), considers all |R1| x |R2| pairs of tuples.")
40
Index Join An index join exploits the existence of an index for one of the domains used in the join to find matching tuples more quickly.

41
Sort Join If we don't have an index for a domain in the join, we can still improve on the nested-loop join using sort join. R3= join(R1,Ai,R2,Bj) Merge the tuples of both relations into a single list list elements must identify the original relation Sort the list based on the value in the join domains Ai and Bj all tuples on the sorted list with a common value for the join domains are consecutive Pair all (consecutive) tuples from the two relations with the same value in the join domains
 Merge the tuples of both relations into a single list list elements must identify the original relation Sort the list based on the value in the join domains Ai and Bj all tuples on the sorted list with a common value for the join domains are consecutive Pair all (consecutive) tuples from the two relations with the same value in the join domains.")
42
Projection in MapReduce 1 Repartition join—A reduce-side join for situations where you’re joining two or more large datasets together 2 Replication join—A map-side join that works in situations where one of the datasets is small enough to cache 3 Semi-join—Another map-side join where one dataset is initially too large to fit into memory, but after some filtering can be reduced down to a size that can fit in memory (details in Hadoop in Practice book)
")
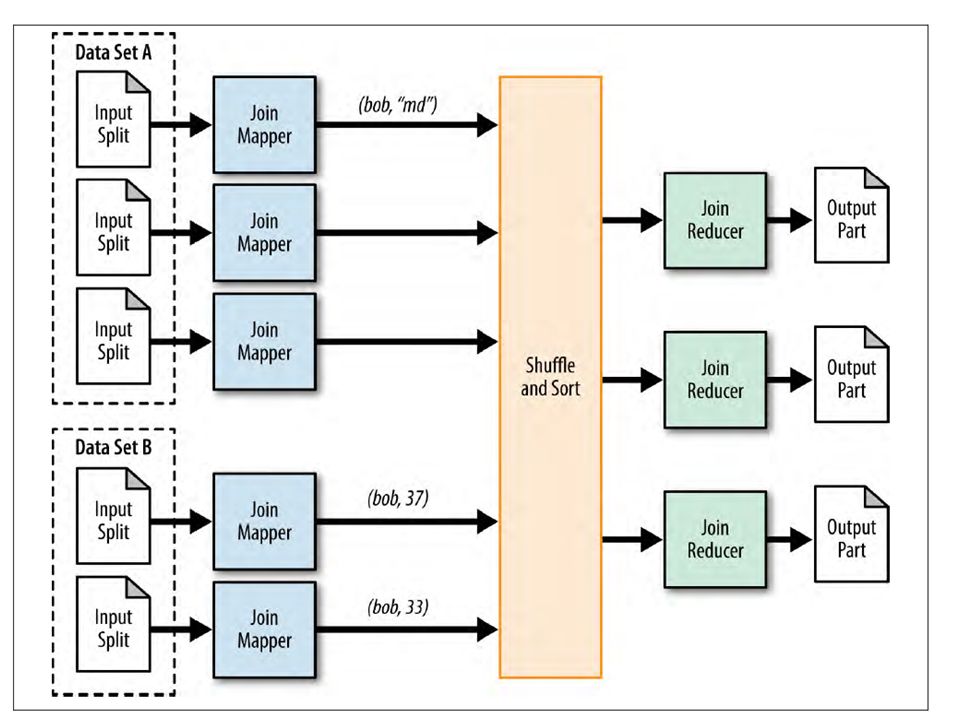
43
Repartition Join (Reduce Join, Sort-Merge Join) This algorithm joins of two sets R and L on some key k. Mapper goes through all tuples from R and L, extracts key k from the tuples, marks tuple with a tag that indicates a set this tuple came from (‘R’ or ‘L’), and emits tagged tuple using k as a key. Reducer receives all tuples for a particular key k and put them into two buckets – for R and for L. When two buckets are filled, Reducer runs nested loop over them and emits a cross join of the buckets. Each emitted tuple is a concatenation R-tuple, L- tuple, and key k. This approach has the following disadvantages: Mapper emits absolutely all data, even for keys that occur only in one set and have no pair in the other. Reducer should hold all data for one key in the memory. If data doesn’t fit the memory, its Reducer’s responsibility to handle this by some kind of swap. Repartition Join is a most generic technique Multiple large data sets are being joined by a foreign key. If all but one of the data sets can be fit into memory, try using the replicated join. Flexibility of being able to execute any join operation.
, and emits tagged tuple using k as a key. Reducer receives all tuples for a particular key k and put them into two buckets – for R and for L. When two buckets are filled, Reducer runs nested loop over them and emits a cross join of the buckets. Each emitted tuple is a concatenation R-tuple, L- tuple, and key k. This approach has the following disadvantages: Mapper emits absolutely all data, even for keys that occur only in one set and have no pair in the other. Reducer should hold all data for one key in the memory. If data doesn’t fit the memory, its Reducer’s responsibility to handle this by some kind of swap. Repartition Join is a most generic technique Multiple large data sets are being joined by a foreign key. If all but one of the data sets can be fit into memory, try using the replicated join. Flexibility of being able to execute any join operation..")
45
Repartition Join (Reduce Join, Sort-Merge Join)
")
46
Repartition Join Optimization the repartition join is not space efficient; it requires all of the output values for a given join value to be loaded into memory before it can perform the multiway join. It’s more efficient to load the smaller of the datasets into memory and then iterate over the larger of datasets, performing the join along the way.

47
Replicated Join (Map Join, Hash Join) Scenario: Join a small set with a large one (say, a list of users with a list of log records). Two sets – R and L, R is relative small. Method R can be distributed to all Mappers and each Mapper can load it and index by the join key– using a hash table. Mapper goes through tuples of the set L and joins them with the corresponding tuples from R that are stored in the hash table. Advantage No need in sorting or transmission of the set L over the network

48
Replicated Join

49
Aggregate Functions in SQL Aggregate function: summarize information from multiple tuples Basic aggregate operations in SQL COUNT, SUM, MAX, MIN, AVG SELECT COUNT(*) FROM Follow WHERE Follower = ‘Alice00’; Retrieve the number of people that “Alice00” is following SELECT COUNT(*) FROM Follow WHERE Followee = ‘Alice00’; Retrieve the number of people who are following “Alice00”
 FROM Follow WHERE Follower = ‘Alice00’; Retrieve the number of people that Alice00 is following SELECT COUNT(*) FROM Follow WHERE Followee = ‘Alice00’; Retrieve the number of people who are following Alice00")
50
Aggregation Aggregation can be performed in one MapReduce job as follows. Mapper extract from each tuple values to group by and aggregate and emits them. Reducer receives values to be aggregated already grouped and calculates an aggregation function.

51
More on Design Pattern – Summarization Pattern numerical summarizations, inverted index, and counting with counters.

54
Design Patterns Summarization Filtering Data Organization Joins Metapatterns Input and output

55
Filtering patterns Extract interesting subsets Filtering Bloom filtering Top ten Distinct Summarization patterns top-down summaries Numerical summarizations Inverted index Counting with counters I only want some of my data! I only want a top-level view of my data!

56
Data organization patterns Reorganize, restructure Structured to hierarchical Partitioning Binning Total order sorting Shuffling Join patterns Bringing data sets together Reduce-side join Replicated join Composite join Cartesian product I want to change the way my data is organized! I want to mash my different data sources together!

57
Metapatterns Patterns of patterns Job chaining Chain folding Job merging Input and output patterns Custom input and output Generating data External source output External source input Partition pruning I want to solve a complex problem with multiple patterns! I want to get data or put data in an unusual place!

58
Summary Mapper object map state one object per task Reducer object reduce state one call per input key-value pair one call per intermediate key (Key, Value) Check point, global state
 Check point, global state")
59
MapReduce and HBase Hbase as a source

60
MapReduce and HBase Hbase as a sink

61
MapReduce and Hbase Hbase as a shared resource Join with Hbase

Similar presentations
>")















 INTERESTS: SYSTEMS, WEB.>")

 2007 Google and are licensed under.>")
