Download presentation
Presentation is loading. Please wait.

1
Web Application Development Instructor: Matthew Schurr

2
Parts of the World Wide Web Your browser makes requests over the internet to servers using a simple protocol called HTTP. The servers respond with files that your browser displays. Servers are computers (just like yours) that are optimized for sitting in data centers and hosting files.
 that are optimized for sitting in data centers and hosting files..")
3
What is a web browser? A web browser is a locally stored and executed software application used for retrieving, presenting, and traversing resources on the Internet (or some other network). A web browser retrieves resources from other computers using the HTTP protocol. A web browser combines HTML markup, CSS markup, JavaScript code, Images, and other assets to create an interactive visual display.
. A web browser retrieves resources from other computers using the HTTP protocol. A web browser combines HTML markup, CSS markup, JavaScript code, Images, and other assets to create an interactive visual display..")
4
What is a web server? A web server is a piece of software that allows a computer to deliver content to clients over the Internet using the HyperText Transfer Protocol (HTTP). Web servers may deliver static content or content dynamically that is generated dynamically by a server-side scripting language (PHP, Python, C++, Scala, etc.). Server-side scripting languages add interactivity to a website (forms, file uploads, etc.) and can be used to provide a unique experience to each user.
. Web servers may deliver static content or content dynamically that is generated dynamically by a server-side scripting language (PHP, Python, C++, Scala, etc.). Server-side scripting languages add interactivity to a website (forms, file uploads, etc.) and can be used to provide a unique experience to each user..")
5
Static vs. Dynamic Static Content (pre-written, re-usable files) (most) images Most content in ‘90s was static Examples: a logo, a PDF document Dynamic Response built on the fly by a program Most content today is dynamic Examples: Reddit, Facebook News Feed, Google Search Web Application A program that exists on a web server, speaks HTTP, and generates content dynamically
 (most) images Most content in ‘90s was static Examples: a logo, a PDF document Dynamic Response built on the fly by a program Most content today is dynamic Examples: Reddit, Facebook News Feed, Google Search Web Application A program that exists on a web server, speaks HTTP, and generates content dynamically.")
6
What makes up a web application? Model-View-Controller (MVC) MVC is a software design pattern that separates: Models: Information Views: Representations of information Controllers: ○ The user’s interaction with information ○ Interaction between models and views
 MVC is a software design pattern that separates: Models: Information Views: Representations of information Controllers: ○ The user’s interaction with information ○ Interaction between models and views.")
7
MVC Model Model – the application’s data and the functions that act on it This is the storage system that manages all of an application’s information. On Facebook: Users, Comments, Posts, Photos… Technologies: Relational Database Systems SQL (Structured Query Language) PHP ORM (Object-Relational Mapping) Classes
 PHP ORM (Object-Relational Mapping) Classes.")
8
MVC View View – any visual representation of application data This is what you see in your web browser. Technologies: HTML (HyperText Markup Language) Images, Graphs, Videos, etc. Javascript CSS (Cascading Style Sheets)
 Images, Graphs, Videos, etc. Javascript CSS (Cascading Style Sheets).")
9
MVC Controller Controller – mediates input so that it can be understood by the model. Converts data from the model to a format that can be understood by the view (and vice-versa). This is the software located on the webserver that processes your requests and builds an appropriate response, making changes to the model based on your inputs as needed. Technologies HTTP (HyperText Transfer Protocol) PHP Javascript
. This is the software located on the webserver that processes your requests and builds an appropriate response, making changes to the model based on your inputs as needed. Technologies HTTP (HyperText Transfer Protocol) PHP Javascript.")
10
How do browsers and servers interact? Browsers and Servers interact using HTTP. Hyper Text Transfer Protocol HTTP is a request-response protocol. The browser sends a request to the server, and the server sends a response back. In HTTP, servers are response only. They can only respond to requests initiated by browsers Can you see how this might be limiting?

11
HTTP Limitations Assume that each page view is a full request-response cycle. How would you implement a real-time chat app so that users do not need to manually reload the page to get new messages? Since there is no server-side push (servers can not initiate a connection), we must use polling. Polling - periodically making requests to the server to update our display, regardless of whether or not there is new information. This is inefficient because >99% of the time there will not be new info.
, we must use polling. Polling - periodically making requests to the server to update our display, regardless of whether or not there is new information. This is inefficient because >99% of the time there will not be new info..")
12
Internet Key Terms Internet Protocol Address (IP) – a unique numerical address assigned to each device connected to the Internet The “device” connected to the internet that receives an IP address may not necessarily be your computer, but rather your router. In this way, it is possible for two computers to have the same public IP address to the rest of the internet. An IP address looks like: ○ IPv4: 192.0.43.10 ○ IPv6: 2001:db8:85a3:8d3:1319:8a2e:370:7348 IPv6 is a newer version of the addressing system that provides a larger number of unique addresses to accommodate for the increasing number of devices connected to the internet today. Domain Name System (DNS) – a system that translates easily memorized hierarchical names (e.g. rice.edu) to numerical IP addresses
 – a system that translates easily memorized hierarchical names (e.g. rice.edu) to numerical IP addresses.")
13
URLs (Uniform Resource Locators) Let’s look at the structure of the following URL: https://duncan.rice.edu:443/committees/website.html?key=value#members Protocol – tells the browser what protocol should be used when sending requests (http, https, ftp, etc.). Subdomain(s) + Domain + Top Level Domain = HOSTNAME – used to determine where on the Internet to send your request. Can substitute with an IP address. References the machine containing the information we want to fetch.
 + Domain + Top Level Domain = HOSTNAME – used to determine where on the Internet to send your request. Can substitute with an IP address. References the machine containing the information we want to fetch..")
14
URLs (Uniform Resource Locators) https://duncan.rice.edu:443/committees/website.html?key=value#members Port – specifies the port to use on the remote server, optional - defaults to 80 for HTTP and 443 for HTTPS if left out. Path – refers to a file location or folder; used by the server when routing the request.

15
URLs (Uniform Resource Locators) https://duncan.rice.edu:443/committees/website.html?key=value#members Query String – a set of key-value pairs (also known as GET parameters) that can be used by the server when processing and/or routing the request. Fragment – refers to a particular scrolling point (anchor) on a web page. May also be used by JavaScript to indicate the state of an application. Not sent to server – client-side.
 on a web page. May also be used by JavaScript to indicate the state of an application. Not sent to server – client-side..")
16
What happens when we enter the URL into our browser? https://duncan.rice.edu:443/committees/website.html?key=value#members First, we need to know where to send the request. The browser takes the hostname and uses DNS to retrieve the IP address of the remote server. In Terminal: ~$ nslookup duncan.rice.edu Non-authoritative answer: Name: duncan.rice.edu Address: 74.220.215.225

17
Next, the browser looks at the provided protocol and determines what message to send to the remote server. For HTTP, it will send an HTTP request over the internet to the address resolved in step 1. For HTTPS, the browser will first establish a secure connection to the host using SSL and then send an encrypted version of the request. Only the intended recipient will be able to decrypt the request. This effectively prevents third parties from eavesdropping. We aren’t concerned with how this encryption works (look it up on your own if you’re interested). We only care that it prevents man-in-the-middle attacks.
. We only care that it prevents man-in-the-middle attacks..")
18
https://duncan.rice.edu/committees/website.html?key=value#member The following is the HTTP request we would expect our browser to send: HTTP/1.1 GET /committees/website.html?key=value User-Agent: Mozilla/5.0 Firefox/22.0 Host: duncan.rice.edu Connection: keep-alive Accept-Encoding: none Accept: */*

19
The general structure of an HTTP request: HTTP/1.1 METHOD PATH+QUERY_STRING Header: Value (Request Body *Optional) There are two main methods in HTTP: GET – you want to retrieve information from the server POST – you want to send information to the server (the request body) and get back a response. Used for file uploads and sending form data. The request contains the path and query string contained in our URL. The server uses this to route your request to the appropriate response. Notice the host and fragment are not included here.

20
The general structure of an HTTP request: HTTP/1.1 METHOD PATH+QUERY_STRING Header: Value (Request Body *Optional) The request contains some headers which provide the remote server with information about the capabilities of the client browser. Lastly, the request may contain a body. On POST requests where we are sending data to the server, the body contains the data (a set of key-value pairs).
..")
21
GET Parameters Key-value pairs passed in the URL string. The value is optional and will sometimes be left blank. These are available on both GET and POST requests as both types of requests can have a query string. You can pass more than one parameter. You are only limited by the maximum accepted URL length. Structure in URL: /path/to/file/?key=value&key2=value2… /path/to/file/?key&key2=value&key3…

22
Finally, the remote server takes the information provided in your request and processes it to the appropriate response. The server then sends back an HTTP response to your IP address. It will look similar to: HTTP/1.1 200 OK Vary: Accept-Encoding Server: Apache Connection: Keep-Alive Keep-Alive: timeout=10, max=30 Content-Type: text/html Content-Length: 3538 …

23
HTTP/1.1 CODE STATUS Header: Value (Response Body) Code – indicates the status of the response Status – standardized string describing the code Headers – describe the content and set rules for behavior between the client and browser Body – the content itself. May be an HTML document, an image, or some other binary data.

24
HTTP Status Codes 200 OK 301 Moved Permanently 302 Found 307 Temporary Redirect 400 Bad Request 401 Unauthorized 403 Forbidden 404 Not Found 405 Method Not Allowed 408 Request Timeout 412 Precondition Failed 413 Request Entity Too Large 414 Request URI Too Long 500 Internal Server Error 501 Not Implemented 503 Service Unavailable 505 HTTP Version Not Supported These are predefined integer codes that let the browser know the status of the request. For example, was it successful? Does it contain the correct file? Generally, 2xx – Success 4xx – Browser Error 5xx – Server Error YOU DO NOT NEED TO MEMORIZE THESE! Example Status Codes:

25
Important Headers Content-Type – describes the content by its mime type (a short, standardized string). Lets the browser know what type of data the file contains so that it can properly display it. Required. Content-Length – describes the length of the content in bytes. Not required; the browser can determine the length of the content automatically after the connection closes. It is a courtesy to include this because it allows the browser to calculate the time remaining on large downloads.

26
MIME Types Mime types are short, standardized strings that describe the content contained in a response. These are sent in the Content- Type header. Remember that the response body (content) is just a sequence of binary data. The computer system needs to know how it should interpret these bits to create a visual display. Is it an image? A PDF file? Plain text? When you open a file locally on your computer, your operating system does this by looking at the file extension. However, in HTTP, there are not necessarily file extensions. The URL duncan.rice.edu/content may respond with ANY TYPE OF BINARY DATA.duncan.rice.edu/content This may be an image, plain text, etc. To let the browser know what type of data it is sending, the server includes a Content-Type header in the response.
 is just a sequence of binary data. The computer system needs to know how it should interpret these bits to create a visual display. Is it an image. A PDF file. Plain text. When you open a file locally on your computer, your operating system does this by looking at the file extension. However, in HTTP, there are not necessarily file extensions. The URL duncan.rice.edu/content may respond with ANY TYPE OF BINARY DATA.duncan.rice.edu/content This may be an image, plain text, etc. To let the browser know what type of data it is sending, the server includes a Content-Type header in the response..")
27
Common Mime Types text/plain text/html text/css application/xml application/zip application/javascript image/jpeg image/png image/gif application/pdf application/x-python application/json

28
What else are headers for? Headers can be used to set rules for the behavior between browser and server. e.g. the “Connection” header Headers can send information to the browser or server, including information about the capabilities of the browser and/or server. Date User-Agent (browser, operating system, robots/search engine crawlers) Server (software) Headers can save bandwidth by facilitating caching and compression. When you request an asset over HTTP, you may cache the response locally on your disk. The next time you request the asset, your browser will load the local one instead of the remote one. This saves time, bandwidth, and processing power. If-None-Match, Etag, Last-Modified, Expires, Cache-Control, Compression You can use headers to reliably redirect users. Location: http://www.google.com/http://www.google.com/
 Server (software) Headers can save bandwidth by facilitating caching and compression. When you request an asset over HTTP, you may cache the response locally on your disk. The next time you request the asset, your browser will load the local one instead of the remote one. This saves time, bandwidth, and processing power. If-None-Match, Etag, Last-Modified, Expires, Cache-Control, Compression You can use headers to reliably redirect users. Location:")
29
What else are headers for? You can send custom headers for debugging. Custom headers can be named anything but cannot contain spaces in their names (values can). Why do we send the host header? Isn’t that redundant? Multiple domains can be hosted by the same server on the same IP address. The server needs a way to differentiate between them when routing requests. Consider my server, which hosts the website for both Duncan College and my personal website. Recall that the host is not included in the request by default. Sending the host header provides my server with a way to differentiate between requests meant for my website and requests meant for Duncan’s website. For this reason, including the host header is mandatory in HTTP/1.1. Requests not containing this header will not be serviced by HTTP/1.1 servers.
. Why do we send the host header. Isn’t that redundant. Multiple domains can be hosted by the same server on the same IP address. The server needs a way to differentiate between them when routing requests. Consider my server, which hosts the website for both Duncan College and my personal website. Recall that the host is not included in the request by default. Sending the host header provides my server with a way to differentiate between requests meant for my website and requests meant for Duncan’s website. For this reason, including the host header is mandatory in HTTP/1.1. Requests not containing this header will not be serviced by HTTP/1.1 servers..")
30
Stateless Protocols HTTP is a stateless protocol. Each request and response cycle is treated as an independent transaction, unrelated to any previous transaction(s). The server does not retain session information or status about communication partners for the duration of several requests. Every single HTTP request must contain all of the information necessary to properly service the request. Example: SSH (stateful) vs. HTTP (stateless)
. The server does not retain session information or status about communication partners for the duration of several requests. Every single HTTP request must contain all of the information necessary to properly service the request. Example: SSH (stateful) vs. HTTP (stateless).")
31
Cookies and Client-Side Storage The HTTP specification allows for the server to store small pieces of data (<4kb) with the client (browser). These pieces of data are called cookies. After a server stores a cookie with a client, the client transmits the cookie back to the server on each subsequent request. The server can then access the value. The setting and sending of cookies occurs using HTTP headers. In this way, the protocol remains stateless. Cookies are stored on a domain basis. Web applications running on one domain cannot access cookies on another domain. Subdomains can access cookies for parent domains if explicitly declared when setting the cookie. This prevents google.com (or any other domain) from accessing your cookies for facebook.com. This security measure prevents one web application from stealing your credentials to another.
 from accessing your cookies for facebook.com. This security measure prevents one web application from stealing your credentials to another..")
32
Cookies (cont.) Properties of Cookies: Name – the name of the cookie Value – the data you want to store Expire – the time at which the cookie should be automatically purged Path – the path(s) on the server at which the cookie should be accessible Domain – the domain(s) at which the cookie should be accessible Secure – whether the cookie should only be sent over https connections HTTP Only – whether the cookie should only be sent over HTTP (no JavaScript access)
 Properties of Cookies: Name – the name of the cookie Value – the data you want to store Expire – the time at which the cookie should be automatically purged Path – the path(s) on the server at which the cookie should be accessible Domain – the domain(s) at which the cookie should be accessible Secure – whether the cookie should only be sent over https connections HTTP Only – whether the cookie should only be sent over HTTP (no JavaScript access)")
33
Cookies (cont.) Uses of Cookies: Tracking visits Identifying a user’s session or login Storing small pieces of information specific to the user that will persist for a set amount of time Important Limitations: Cookies are stored completely client-side. This means that a malicious user can tamper with their values. They can also delete cookies or create cookies with any properties on a whim. We will discuss ways to work around this, as well as additional uses for cookies, later. Although most web browsers support cookies, it is not a requirement of the HTTP protocol. Additionally, the user may have intentionally disabled them. As such, there is no guarantee that a cookie you set will be available on subsequent requests.

34
Firefox Developer Tools

35
Firefox Web Console

36
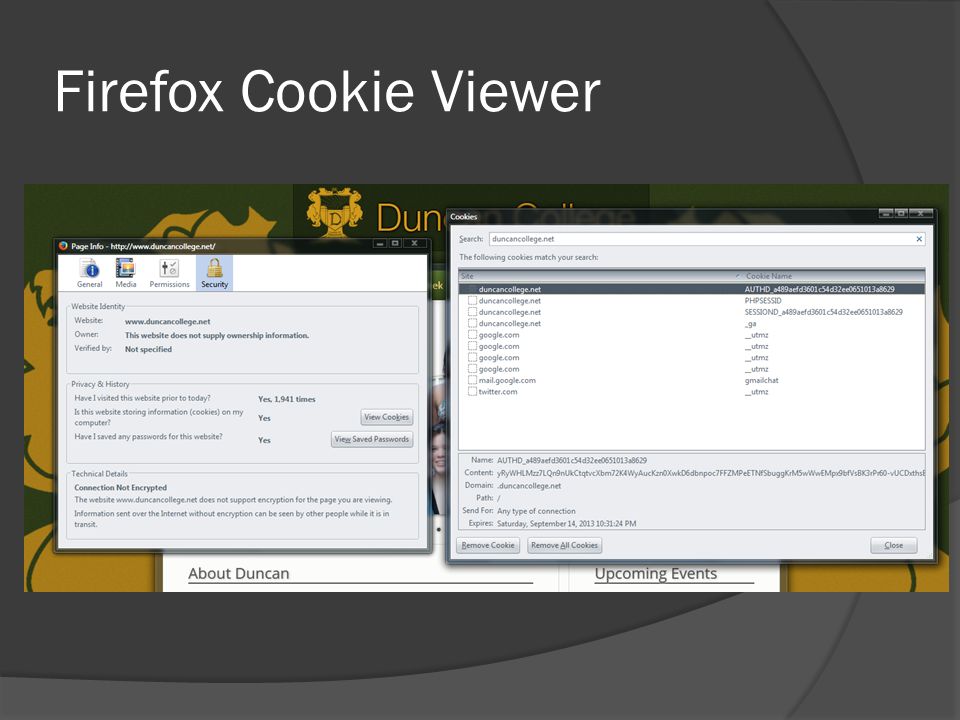
Firefox Cookie Viewer

38
Firefox Network Tool You should also take a look at the Network tab on the web developer tools console.

39
Understanding HTTPS When our browser makes an HTTPS request, it assembles the HTTP request packet just as it would if we were making a normal HTTP request. The browser then encrypts the entire HTTP request packet using SSL before sending it over the public internet. SSL works because only the intended recipient (the web server) will have the information required to decrypt the request. ○ We are not interested in understanding exactly how this works. ○ Any third parties that intercept your request will not be able to decrypt it and extract passwords, credit card info, etc. Upon receiving the encrypted packet, the web server software will be able to decrypt it. The web server software will then forward the decrypted packet to the code that processes the request.
 will have the information required to decrypt the request. ○ We are not interested in understanding exactly how this works. ○ Any third parties that intercept your request will not be able to decrypt it and extract passwords, credit card info, etc. Upon receiving the encrypted packet, the web server software will be able to decrypt it. The web server software will then forward the decrypted packet to the code that processes the request..")
40
Understanding HTTPS (cont). To both our users and us, the protocol is transparent; the encryption/decryption process occurs in the background and requires no additional interaction from the user or programmer. We do not need to do anything differently in our server-side code when we are using HTTPS instead of HTTP. We will obviously need to make any links contained in our page point to HTTPS URLs instead of HTTP URLs. Our server-side language does provide us with a function to check whether or not the request was sent securely (over HTTPS). In order for a response to be considered truly encrypted, all assets (images, videos, javascript, css) loaded by the page must also be sent over HTTPS. If this is not the case, then most browsers will not consider the page secure (we won’t see a lock in the URL bar).
. In order for a response to be considered truly encrypted, all assets (images, videos, javascript, css) loaded by the page must also be sent over HTTPS. If this is not the case, then most browsers will not consider the page secure (we won’t see a lock in the URL bar)..")
41
How does email work? Email is not sent over HTTP; email has it’s own protocols, but the general principle is the same. For Outbound Messages: SMTP/SMTPS For Inbound Messages: POP3/POP3S, IMAP/IMAPS When we send an email, we send an SMTP packet to the email server for our domain, which will then forward it on to the server for the recipient’s domain. For our emails @rice.edu, we use DNS to resolve the Mail eXchange (MX) record for rice.edu and we then send the packet to that IP. For the secure version of the protocols (like SMTPS), we simply encrypt the packet before we send it and the server decrypts it when it receives the packet (just like HTTP vs. HTTPS). When we are downloading emails, we use IMAP or POP3 to transfer messages from the server to our mail application.
 record for rice.edu and we then send the packet to that IP. For the secure version of the protocols (like SMTPS), we simply encrypt the packet before we send it and the server decrypts it when it receives the packet (just like HTTP vs. HTTPS). When we are downloading s, we use IMAP or POP3 to transfer messages from the server to our mail application..")
42
What about Gmail (and other web mail)? Gmail acts as an intermediary between us and Google’s IMAP / POP3 / SMTP server. When we view messages, the server-side software at Gmail downloads the messages over IMAP, formats them into HTML (which our browser can display), and sends us the HTML as a response to our HTTP GET request. When we send a message in Gmail, we make a POST request to the Gmail server over HTTP. The server-side software that processes our POST request will then send our email by copying our message from the POST request into an SMTP packet and sending it to Google’s SMTP server. If we access Gmail over HTTPS and Gmail then sends our message using SMTPS, our message will have been transmitted securely all the way from start to finish.
, and sends us the HTML as a response to our HTTP GET request. When we send a message in Gmail, we make a POST request to the Gmail server over HTTP. The server-side software that processes our POST request will then send our by copying our message from the POST request into an SMTP packet and sending it to Google’s SMTP server. If we access Gmail over HTTPS and Gmail then sends our message using SMTPS, our message will have been transmitted securely all the way from start to finish..")
43
Next Week: HyperText Markup Language (HTML)
")
44
HOMEWORK: Assignment 1 You can view the assignment on the course website (or in the syllabus). Complete the assignment and turn it in on Owl-Space before the next class.

Similar presentations

>")









 Problem – Want to go to www.google.com, but don’t know the IP addresswww.google.com Solution.>")





>")
 TCP allows programs running.>")
